track
Învățare automată supravegheată în Python
25 oră
Metodele standard de regresie minimizează eroarea totală pe toate punctele de date. Asta înseamnă că fiecare rezidual, oricât de mic, trage modelul într-o anumită direcție. Drept rezultat, ajungi cu un model sensibil la zgomot și valori aberante (outliers).
Un model de regresie cu vectori de suport, pe de altă parte, potrivește o funcție în interiorul unei marje de toleranță și ignoră erorile care se încadrează în ea. Acea marjă schimbă ideea de optimizare. În loc să încerce să optimizeze fiecare punct de date, SVR se concentrează pe structura de ansamblu a datelor, ceea ce îl face, așa cum sper să îți arăt, robust pe date reale.
Dacă ai nevoie de un scurt intro înainte să începem, citește articolul nostru Regresie liniară în Python pentru o introducere în modelarea predictivă.
Support Vector Regression este o metodă de regresie construită pe aceeași bază ca Support Vector Machines (SVM), o clasă de modele proiectată inițial pentru sarcini de clasificare, cum ar fi detectarea spamului sau recunoașterea imaginilor.
Ideea-cheie e ușor de înțeles – în loc să încerce să minimizeze fiecare eroare de predicție, SVR potrivește o funcție permițând o marjă de toleranță în jurul ei. Erorile care cad în acea marjă nu contează. Modelul se concentrează pe a obține potrivirea generală corectă, nu pe corectarea fiecărei mici deviații.
Asta diferențiază SVR de majoritatea celorlalte modele de regresie.
Metodele standard de regresie tratează fiecare rezidual ca pe un semnal. SVR tratează majoritatea drept zgomot. Drept urmare, ajungi cu un model mai puțin preocupat să fie exact pe fiecare punct și mai preocupat să surprindă corect structura de bază a datelor.
În centrul SVR se află așa-numitul tub epsilon – o marjă de toleranță care înconjoară funcția potrivită pe ambele părți.
Orice punct de date care cade în interiorul tubului este considerat suficient de aproape. SVR ignoră aceste puncte la potrivirea modelului. Doar punctele din afara tubului contează, pentru că acelea sunt cele care formează de fapt frontiera de decizie.
Exemplu de tub Epsilon
Iată cum îl poți interpreta:
Asta separă SVR de regresia standard. În regresia liniară, fiecare punct de date trage de model – inclusiv cele zgomotoase. În SVR, majoritatea punctelor sunt irelevante. Rezultatul este o potrivire ghidată de o structură generală bună.
SVR are două obiective concurente pe care încearcă să le satisfacă simultan.
Primul este să mențină modelul cât mai plat posibil. O funcție mai plată este mai simplă, iar modelele mai simple tind să generalizeze mai bine pe date noi. Al doilea este să minimizeze erorile pe punctele din afara tubului epsilon – cele pe care SVR nu le poate ignora.
Aceste două obiective trag în direcții opuse, iar aici intervine parametrul de regularizare C. El controlează câtă greutate pune SVR pe erorile din afara tubului în raport cu simplitatea modelului:
Întotdeauna faci un compromis între simplitatea modelului și toleranța la eroare. Valoarea corectă a lui C depinde de datele tale și de cât zgomot te aștepți. O alegere greșită în oricare direcție va scădea performanța modelului pe date noi.
Este o problemă de optimizare care poate fi rezolvată iterativ, deci nu e ceva de speriat.
În SVR, doar punctele de date care cad în afara tubului epsilon contează cu adevărat.
Acestea sunt vectorii de suport – punctele de date care stau dincolo de margine și modelează funcția potrivită. Tot ce e în interiorul tubului este ignorat în timpul antrenării. Modelul nu „vede” acele puncte într-un mod semnificativ.
Vectori de suport
Efectul secundar util este sparitatea. În practică, doar un subset mic din datele tale de antrenare ajunge vectori de suport. Restul nu contribuie la modelul final, ceea ce face SVR eficient în memorie și rapid de evaluat după antrenare, deoarece predicțiile depind doar de acele câteva puncte influente.
SVR nu este limitat la potrivirea unor linii drepte. Poate gestiona relații neliniare printr-o tehnică numită kernel trick.
Așadar, în loc să potrivească o funcție în spațiul inițial al intrărilor, SVR mapează datele într-un spațiu de dimensionalitate mai mare, unde o potrivire liniară devine posibilă. Acea potrivire liniară din spațiul de dimensionalitate mai mare se traduce înapoi într-o curbă neliniară în datele tale originale.
Cele mai frecvente două kerneluri pe care le vei folosi sunt:
Alegerea kernelului depinde de datele tale. RBF este un punct de plecare bun când nu ești sigur.
Diferența se reduce la ceea ce încearcă fiecare model să facă.
Regresia liniară minimizează eroarea totală pe fiecare punct de date. Fiecare rezidual contează, oricât de mic ar fi. Dacă tragi modelul de pe traseu cu un punct zgomotos, întreaga potrivire se deplasează pentru a compensa.
SVR ignoră erorile din interiorul tubului epsilon. Reacționează doar la punctele care cad în afara marginii – și chiar și atunci, C controlează cât de puternic. Modelul optimizează pentru structură, nu pentru acuratețe pe fiecare punct în parte.
Această diferență face SVR mai robust la outlieri. Un singur punct zgomotos nu va deraia potrivirea cum se poate întâmpla în regresia liniară, pentru că SVR nici măcar nu a încercat să-l urmărească din start.
Iată toate diferențele:

Regresia liniară comparată cu SVR
SVR are trei parametri pe care trebuie să îi înțelegi înainte să începi optimizarea modelului.
Epsilon definește lățimea marjei de toleranță în jurul funcției potrivite. Un ε mai mare înseamnă un tub mai larg – mai multe puncte sunt ignorate și modelul devine mai simplu. Un ε mai mic strânge tubul și forțează modelul să se potrivească mai atent pe date.
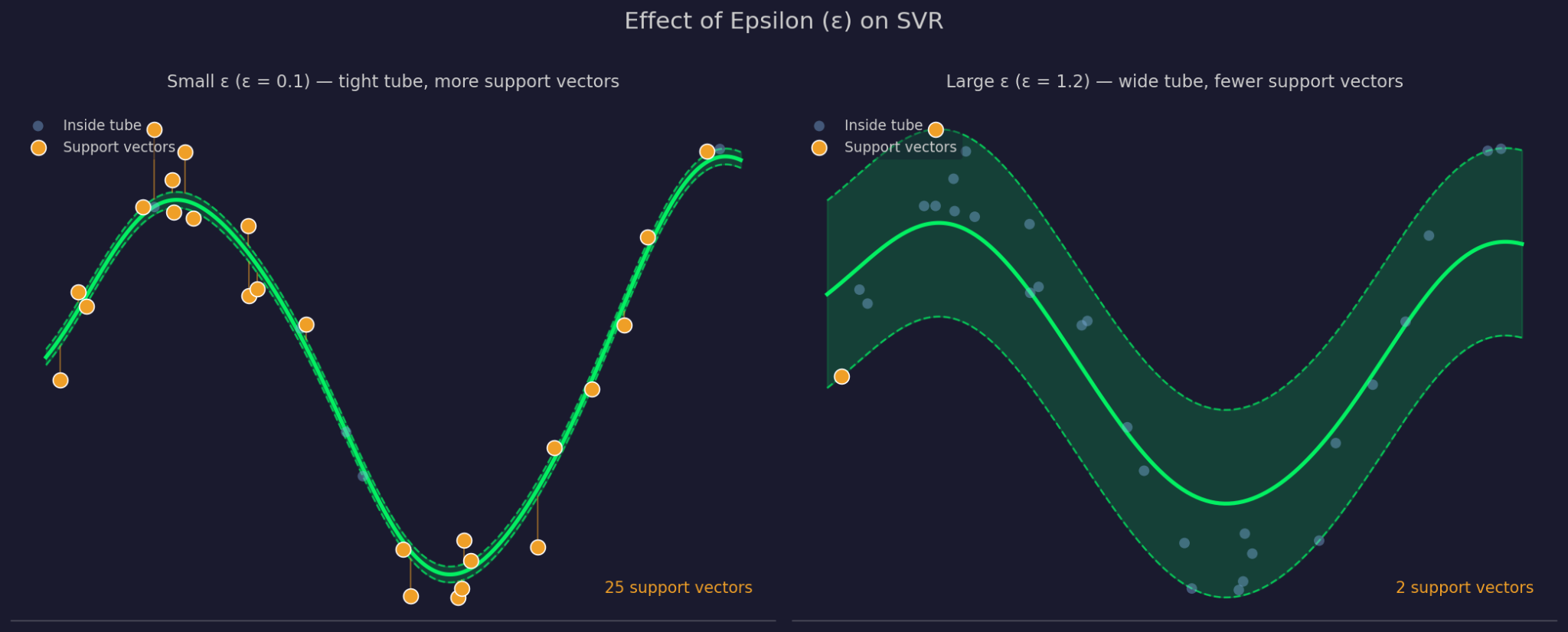
Epsilon mic versus mare
C controlează cât de mult penalizează SVR erorile pe punctele din afara tubului. Un C mare înseamnă că modelul ia acele erori în serios și potrivește mai strâns. Un C mic înseamnă că modelul acceptă mai multe încălcări în schimbul unei funcții mai simple, mai plate. C și ε lucrează împreună, deoarece schimbarea unuia îi afectează practic comportamentul celuilalt.
C mic versus mare
Kernelul determină cum gestionează SVR tiparele neliniare. RBF este cea mai comună alegere și funcționează bine ca implicit. Kernelurile polinomiale sunt utile pentru forme de curbe specifice. Kernelurile liniare reduc SVR la o regresie liniară bazată pe marjă, utilă când datele tale sunt deja bine comportate.
Să faci SVR să funcționeze bine înseamnă să treci prin câțiva pași și prerechizite. Hai să ți le arăt.
Iată fluxul de lucru tipic:
Scalează-ți datele: SVR este sensibil la scara trăsăturilor. Dacă trăsăturile sunt pe scări diferite, modelul nu va funcționa cum te aștepți. Folosește StandardScaler atât pe X, cât și pe y înainte de potrivire
Alege un kernel: RBF este alegerea corectă implicită pentru majoritatea problemelor. Treci pe un polinomial dacă ai motive specifice să crezi că relația urmează acea formă
Reglează-ți parametrii: Setează C, epsilon și gamma înainte de potrivire. Grid search sau cross-validation sunt abordările standard aici
Potrivește modelul: Apelează .fit() pe datele de antrenare scalate. După antrenare, inversează transformarea predicțiilor înapoi la scara originală
Iată un exemplu complet folosind scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE pe setul de testare
Câteva lucruri de observat în acest cod. Mai întâi, StandardScaler este aplicat separat atât pe X, cât și pe y. Să scalezi doar trăsăturile este o greșeală comună care duce la rezultate slabe cu SVR. În al doilea rând, predicțiile sunt inverse-transformate la final pentru a le readuce la scara originală înainte de evaluare.
Cele două grafice de mai jos arată cum arată modelul potrivit. Primul arată curba SVR cu tubul epsilon peste datele de antrenare și testare:
Tubul Epsilon peste datele de antrenare și testare
Al doilea compară valorile prezise cu cele reale pe setul de testare:
Valori prezise versus reale
Punctele aproape de diagonală înseamnă că modelul prezice bine.
SVR are un set specific de puncte forte care îl fac instrumentul potrivit în situația potrivită. În mod similar, are și puncte slabe care îl fac nepotrivit în altele.
SVR funcționează cel mai bine într-un set specific de condiții. Ar trebui să folosești SVR când:
Ar trebui să eviți SVR când:
Dacă setul tău de date este mare și zgomotos, metodele de gradient boosting merită analizate mai întâi. SVR e grozav când ai date curate, de dimensiune moderată, cu o structură pe care modelele mai simple nu o pot potrivi bine.
Majoritatea problemelor cu SVR se reduc la același set de erori – tratează asta ca pe un mini-ghid despre ce să nu faci.
Ne-scalarea trăsăturilor. SVR este un algoritm bazat pe distanță, ceea ce înseamnă că trăsăturile ne-scalate vor domina modelul. Aplică întotdeauna StandardScaler atât pe X, cât și pe y înainte de potrivire.
Neînțelegerea lui epsilon. Epsilon este de departe cel mai important parametru. Prea mare și modelul sub-potrivește, pentru că ignoră prea mult. Prea mic și se comportă ca o regresie standard, urmărind fiecare punct de date. Fă întotdeauna un grid search ca să vezi ce performează cel mai bine pe setul tău de testare.
Sărirea peste reglarea parametrilor. Să rulezi SVR cu parametrii impliciți și să te aștepți la rezultate bune rareori funcționează – la fel ca în majoritatea modelelor de machine learning. C, epsilon și gamma trebuie reglate împreună. Folosește grid search cu cross-validation.
Folosirea SVR pe seturi de date foarte mari. Dacă ai mai mult de câteva mii de eșantioane, SVR va fi lent. Pur și simplu nu scalează ca alte algoritmi. Treci la un model care funcționează mai bine cu seturi mari, cum ar fi gradient boosting sau o rețea neuronală.
Este important de notat și că să faci bine aceste patru lucruri nu îți garantează un model grozav, dar să greșești la oricare dintre ele îți garantează aproape sigur unul slab.
În concluzie, amintește-ți că SVR rezolvă o problemă diferită de regresia standard. În loc să minimizeze fiecare eroare, potrivește o funcție în interiorul unei marje și ignoră zgomotul care cade în ea – exact asta îl face util când datele tale nu sunt curate sau perfect liniare.
Nu este renumit pentru viteză sau simplitate. Dar este robust. Dacă datele tale au relații neliniare și outlieri pe care nu vrei să îi modelezi, SVR îți oferă o modalitate de a te concentra pe structură, în loc să urmărești fiecare punct de date.
Doar amintește-ți să scalezi trăsăturile, să îți reglezi parametrii, să alegi kernelul potrivit și să rămâi conservator cu cantitatea de date. Dacă faci acestea corect, SVR îți va oferi un model robust, puțin probabil să eșueze în producție.
SVR este doar un instrument pe care orice data scientist trebuie să îl cunoască. Înscrie-te în traseul nostru Machine Learning Engineer ca să le înveți pe celelalte și să fii pregătit pentru job în 2026.
Învață cu DataCamp
track
course
course