
programa
Aprendizaje automático supervisado en Python
25 h
Los métodos de regresión estándar minimizan el error total en todos los puntos de datos. Eso significa que cada residual, por pequeño que sea, tira del modelo en alguna dirección. El resultado es un modelo sensible al ruido y a los valores atípicos.
Un modelo de Support Vector Regression, en cambio, ajusta una función dentro de un margen de tolerancia e ignora los errores que caen dentro de él. Ese margen cambia el enfoque de la optimización: en lugar de intentar optimizar cada punto, SVR se centra en la estructura global de los datos, lo que lo hace, como espero mostrarte, muy robusto en datos reales.
Si necesitas un repaso antes de empezar, lee nuestro artículo Linear Regression in Python para una introducción al modelado predictivo.
Support Vector Regression es un método de regresión construido sobre la misma base que las Support Vector Machines (SVM), una clase de modelos diseñada originalmente para tareas de clasificación como detección de spam o reconocimiento de imágenes.
La idea clave es sencilla: en lugar de intentar minimizar cada error de predicción, SVR ajusta una función permitiendo un margen de tolerancia a su alrededor. Los errores que caen dentro de ese margen no cuentan. El modelo prioriza acertar el ajuste global, no corregir cada pequeña desviación.
Eso es lo que diferencia a SVR de la mayoría de modelos de regresión.
Los métodos estándar tratan cada residual como una señal. SVR considera la mayoría como ruido. Así, obtienes un modelo menos preocupado por clavar cada punto y más por capturar la estructura subyacente de los datos.
En el centro de SVR está lo que se conoce como el tubo épsilon: un margen de tolerancia que envuelve a la función ajustada por ambos lados.
Cualquier punto de datos que caiga dentro del tubo se considera suficientemente cercano. SVR los ignora al ajustar el modelo. Solo importan los puntos fuera del tubo, porque son los que realmente dan forma a la frontera de decisión.
Ejemplo del tubo épsilon
Así es como puedes interpretarlo:
Esto es lo que separa SVR de la regresión estándar. En la regresión lineal, cada punto tira del modelo, incluidos los ruidosos. En SVR, la mayoría de puntos son irrelevantes. El resultado es un ajuste guiado por una buena estructura global.
SVR intenta satisfacer a la vez dos objetivos contrapuestos.
El primero es mantener el modelo lo más plano posible. Una función más plana es más simple, y los modelos simples suelen generalizar mejor. El segundo es minimizar los errores en los puntos fuera del tubo épsilon: aquellos que SVR no puede ignorar.
Estos dos objetivos tiran en direcciones opuestas, y ahí entra el parámetro de regularización C. Controla cuánto peso da SVR a los errores fuera del tubo frente a la simplicidad del modelo:
Siempre estás equilibrando simplicidad del modelo y tolerancia al error. El valor adecuado de C depende de tus datos y del nivel de ruido esperado. Si te equivocas en cualquier dirección, el rendimiento en datos nuevos caerá.
Es un problema de optimización que puede resolverse de forma iterativa, así que no es algo para preocuparse.
En SVR, solo importan los puntos de datos que quedan fuera del tubo épsilon.
Estos son los vectores de soporte: los puntos que sobrepasan el margen y dan forma a la función ajustada. Todo lo que queda dentro del tubo se ignora durante el entrenamiento. El modelo nunca “ve” esos puntos de forma significativa.
Vectores de soporte
La consecuencia útil es la esparsidad. En la práctica, solo un pequeño subconjunto de tus datos de entrenamiento acaba siendo vectores de soporte. El resto no aporta nada al modelo final, lo que hace que SVR sea eficiente en memoria y rápido de evaluar una vez entrenado, ya que las predicciones dependen solo de esos pocos puntos influyentes.
SVR no se limita a rectas. Puede manejar relaciones no lineales mediante la técnica conocida como kernel trick.
En lugar de ajustar una función en el espacio de entrada original, SVR mapea los datos a un espacio de mayor dimensión donde un ajuste lineal es posible. Ese ajuste lineal en el espacio de mayor dimensión se traduce de vuelta en una curva no lineal en tus datos originales.
Los kernels más comunes que usarás son:
La elección del kernel depende de tus datos. RBF es un buen punto de partida si no lo tienes claro.
La diferencia se reduce a qué intenta hacer cada modelo.
La regresión lineal minimiza el error total en cada punto. Cada residual cuenta, por pequeño que sea. Si un punto ruidoso saca el modelo de su sitio, todo el ajuste se desplaza para compensarlo.
SVR ignora los errores dentro del tubo épsilon. Solo reacciona a los puntos que caen fuera del margen —y aun así, C controla cuán fuerte—. El modelo optimiza la estructura, no la exactitud en cada punto individual.
Esa diferencia hace que SVR sea más robusto ante valores atípicos. Un único punto ruidoso no arruinará el ajuste como puede ocurrir en la regresión lineal, porque SVR nunca intentó perseguirlo.
Aquí tienes todas las diferencias:

Regresión lineal frente a SVR
SVR tiene tres parámetros que debes entender antes de empezar a optimizar el modelo.
Epsilon define la anchura del margen de tolerancia alrededor de la función ajustada. Un ε mayor significa un tubo más ancho: se ignoran más puntos y el modelo se simplifica. Un ε menor estrecha el tubo y fuerza al modelo a ajustarse más a los datos.
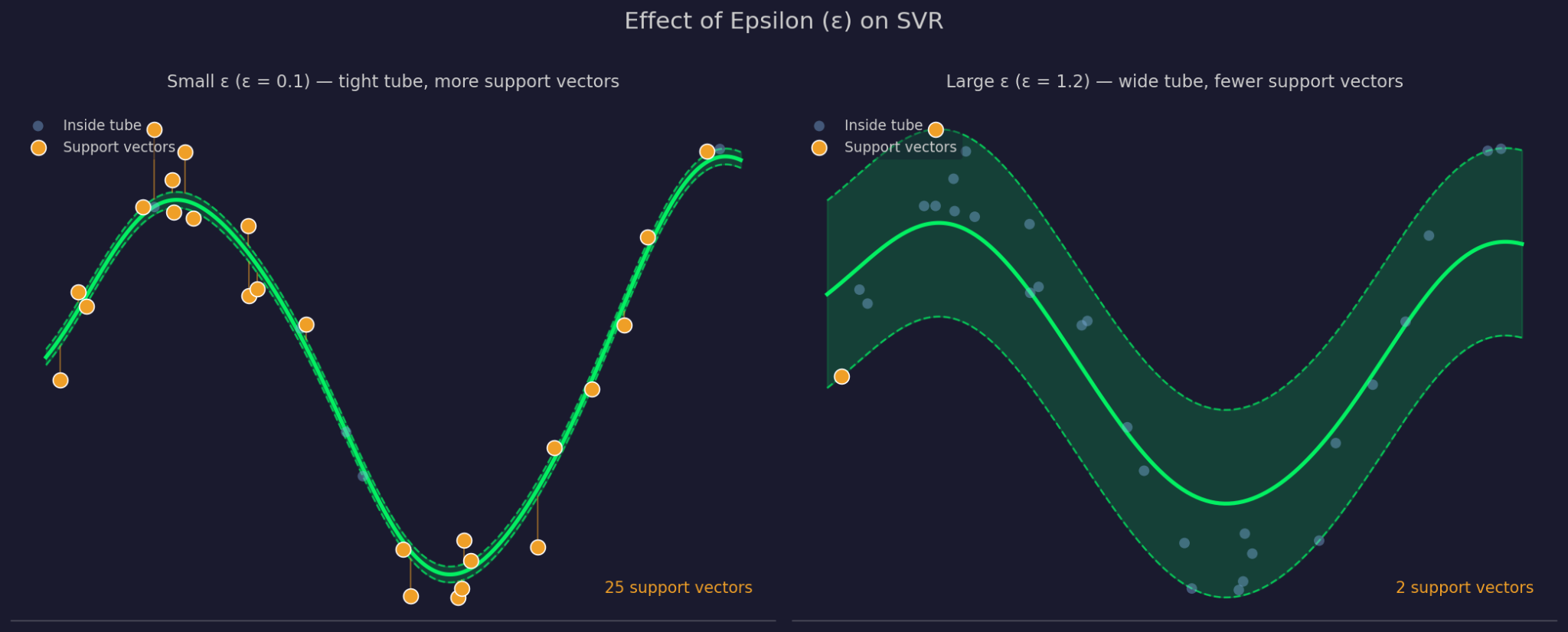
Epsilon pequeño frente a grande
C controla cuánto penaliza SVR los errores de los puntos fuera del tubo. Un C alto hace que el modelo tome en serio esos errores y se ajuste con más fuerza. Un C bajo permite más violaciones a cambio de una función más simple y plana. C y ε trabajan en conjunto: cambiar uno afecta a cómo se comporta el otro en la práctica.
C pequeño frente a grande
El kernel determina cómo maneja SVR los patrones no lineales. RBF es la opción más habitual y funciona bien por defecto. Los kernels polinómicos son útiles para formas de curva concretas. Un kernel lineal reduce SVR a una regresión lineal basada en márgenes, útil cuando tus datos ya se comportan bien.
Hacer que SVR funcione bien consiste en seguir un par de pasos y cumplir algunos requisitos previos. Te los muestro.
Este es el flujo de trabajo típico:
Escala tus datos: SVR es sensible a la escala de las variables. Si están en escalas distintas, el modelo no se comportará como esperas. Usa StandardScaler tanto en X como en y antes de ajustar
Elige un kernel: RBF es la opción adecuada por defecto en la mayoría de problemas. Cambia a polinómico si tienes motivos para creer que la relación sigue esa forma
Ajusta los parámetros: Define C, epsilon y gamma antes de ajustar. Grid search o validación cruzada son los enfoques estándar
Ajusta el modelo: llama a .fit() sobre los datos de entrenamiento escalados. Una vez entrenado, aplica el inverse transform a tus predicciones para volver a la escala original
Aquí tienes un ejemplo completo con scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE en el conjunto de prueba
Un par de cosas a tener en cuenta en este código. Primero, StandardScaler se aplica por separado tanto a X como a y. Escalar solo las variables explicativas es un error habitual que lleva a malos resultados con SVR. Segundo, las predicciones se invierten al final para devolverlas a la escala original antes de evaluarlas.
Las dos gráficas siguientes muestran el aspecto del modelo ajustado. La primera enseña la curva de SVR con el tubo épsilon sobre los datos de entrenamiento y prueba:
Tubo épsilon sobre los datos de entrenamiento y prueba
La segunda compara valores predichos frente a reales en el conjunto de prueba:
Valores predichos frente a reales
Los puntos cercanos a la diagonal indican que el modelo predice bien.
SVR tiene un conjunto específico de fortalezas que lo hacen la herramienta adecuada en determinadas situaciones. Del mismo modo, tiene debilidades que lo hacen inadecuado en otras.
SVR funciona mejor bajo ciertas condiciones. Úsalo cuando:
Evita SVR cuando:
Si tu conjunto es grande y ruidoso, merece la pena mirar primero los métodos de gradient boosting. SVR es ideal cuando tienes datos limpios, de tamaño moderado y con estructuras que los modelos más simples no capturan bien.
La mayoría de problemas con SVR se reducen al mismo conjunto de fallos, así que toma esto como una chuleta de lo que no debes hacer.
No escalar tus variables. SVR es un algoritmo basado en distancias, lo que significa que las variables sin escalar dominarán el modelo. Aplica siempre StandardScaler tanto a X como a y antes de ajustar.
No entender epsilon. Epsilon es, con diferencia, el parámetro más importante. Si es demasiado grande, tu modelo infraajusta porque ignora demasiado. Si es demasiado pequeño, se comporta como una regresión estándar, persiguiendo cada punto. Haz siempre una grid search para ver qué funciona mejor en tu conjunto de prueba.
Saltarte el ajuste de parámetros. Ejecutar SVR con valores por defecto y esperar buenos resultados rara vez funciona —como con la mayoría de modelos de machine learning—. C, epsilon y gamma deben ajustarse conjuntamente. Usa grid search con validación cruzada.
Usar SVR en conjuntos muy grandes. Si tienes más de unos pocos miles de muestras, SVR será lento. Simplemente no escala como otros algoritmos. Pásate a un modelo que funcione mejor con grandes volúmenes, como gradient boosting o una red neuronal.
También es importante señalar que acertar con estos cuatro puntos no garantiza un gran modelo, pero fallar en cualquiera de ellos casi seguro garantiza uno malo.
Para terminar, recuerda que SVR resuelve un problema distinto al de la regresión estándar. En lugar de minimizar cada error, ajusta una función dentro de un margen e ignora el ruido que cae dentro de él, lo que resulta muy útil cuando tus datos no son limpios o perfectamente lineales.
No destaca por su velocidad o sencillez. Pero sí por su robustez. Si tus datos tienen relaciones no lineales y valores atípicos que no quieres modelar, SVR te permitirá centrarte en la estructura en lugar de perseguir cada punto.
Solo recuerda escalar las variables, ajustar los parámetros, elegir el kernel adecuado y ser conservador con la cantidad de datos. Si haces esto bien, SVR te dará un modelo robusto que es poco probable que falle en producción.
SVR es solo una de las herramientas que todo data scientist debe conocer. Inscríbete en nuestro itinerario Machine Learning Engineer para aprender las demás y estar listo para trabajar en 2026.
Aprende con DataCamp
programa
Curso
Curso
blog
Moez Ali
8 min
blog
Zoumana Keita
14 min
Tutorial
Avinash Navlani
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
