Tracks
教師あり機械学習 Pythonで
25時間
標準的な回帰手法は、すべてのデータ点にわたる誤差の合計を最小化します。つまり、どんなに小さな残差でも、必ずどこかの方向にモデルを引っ張ります。その結果、ノイズや外れ値に敏感なモデルになりがちです。
一方、サポートベクター回帰(SVR)は、許容誤差のマージン内に関数を当てはめ、マージン内に収まる誤差は無視します。このマージンが最適化の考え方を変えます。すべてのデータ点を最適化しようとするのではなく、SVRはデータ全体の構造に焦点を当てます。これにより、実データに対して堅牢になることを、これからお見せしたいと思います。
始める前に基礎を確認したい場合は、予測モデリングの入門として Linear Regression in Python の記事をお読みください。
サポートベクター回帰は、サポートベクターマシン(SVM)と同じ基盤の上に構築された回帰手法です。SVM は元々スパム検出や画像認識といった分類タスクのために設計されたモデル群です。
核となる考え方は理解しやすいでしょう。すべての予測誤差を最小化しようとするのではなく、SVR は許容誤差のマージンを設けて関数を当てはめます。マージン内の誤差は勘定に入れません。モデルは、小さなズレを一つずつ正すのではなく、全体として適切にフィットすることに集中します。
それが、多くの回帰モデルと SVR を分ける点です。
標準的な回帰は、あらゆる残差を信号として扱います。SVR はその多くをノイズとして扱います。結果として、あらゆる点での厳密な正確さよりも、データの潜在的な構造を正しく捉えることを重視するモデルになります。
SVR の中心には、イプシロンチューブ(epsilon tube) と呼ばれるものがあります。これは、当てはめた関数の両側を包み込む許容誤差のマージンです。
チューブ内に収まるデータ点は十分に近いと見なされます。SVR はそれらの点を当てはめの際に無視します。重要なのはチューブの外側にある点で、これらが実際に境界(決定関数)の形状を決めます。
イプシロンチューブの例
次のように解釈できます:
これが SVR を標準的な回帰と分けるものです。線形回帰では、ノイズを含む点も含め、すべてのデータ点がモデルを引っ張ります。SVR では、ほとんどの点は無関係です。結果として、全体の良好な構造によって生まれる当てはめになります。
SVR は同時に満たそうとする2つの相反する目標を持ちます。
1つ目は、モデルをできるだけ平坦(フラット)に保つことです。平坦な関数はより単純で、単純なモデルは新しいデータへの汎化性能が高い傾向にあります。2つ目は、イプシロンチューブの外にある点での誤差(SVR が無視できない誤差)を最小化することです。
この2つの目標は互いに反するため、そこで正則化パラメータのCが登場します。C は、モデルの単純さに対して、チューブ外の誤差をどれだけ重視するかを制御します。
常に、モデルの単純さと誤差許容のトレードオフになります。適切な C の値はデータと想定するノイズ量に依存します。どちらの方向にも外すと、新しいデータでの性能は低下します。
これは反復的に解ける最適化問題なので、過度に心配する必要はありません。
SVR では、実際に重要なのはイプシロンチューブの外にあるデータ点だけです。
これらがサポートベクターであり、マージンの外側に位置して当てはめられた関数の形状を決めます。チューブ内のものは学習時には無視されます。モデルはその点を本質的には「見て」いません。
サポートベクター
このことによる有益な副作用が、スパース性です。実際には、学習データのごく一部だけがサポートベクターになります。残りは最終モデルに寄与しないため、学習後の SVR はメモリ効率が高く、予測も高速です。予測は少数の影響力の大きい点にのみ依存するからです。
SVR は直線当てはめに限定されません。 カーネルトリックと呼ばれる手法で非線形関係を扱えます。
元の入力空間で関数を当てはめる代わりに、SVR はデータをより高次元の空間に写像し、そこで線形当てはめを可能にします。高次元空間での線形フィットは、元のデータ空間では非線形の曲線として表れます。
よく使うカーネルは次の2つです。
どのカーネルを選ぶかはデータ次第です。迷ったら RBF から始めるのがよいでしょう。
違いは、各モデルが何を目指しているかに尽きます。
線形回帰は、すべてのデータ点にわたる誤差の合計を最小化します。どんなに小さな残差も勘定に入ります。ノイズの多い点に引っ張られると、全体の当てはめが補正のためにずれてしまいます。
SVR はイプシロンチューブ内の誤差を無視します。反応するのはマージン外の点だけで、その強さも C が制御します。モデルは、個々の点での精度ではなく、構造に最適化します。
この違いにより、SVR は外れ値に対して頑健です。線形回帰のように単一のノイズ点が当てはめを台無しにすることはありません。SVR はそもそもそれを追いかけようとしていないからです。
主な違いは以下のとおりです。

線形回帰と SVR の比較
SVR を最適化する前に理解しておくべきパラメータが3つあります。
イプシロンは当てはめた関数の周りの許容マージンの幅を定義します。ε が大きいほどチューブは広くなり、より多くの点が無視され、モデルは単純になります。ε が小さいほどチューブは狭まり、データにより厳密にフィットすることを強いられます。
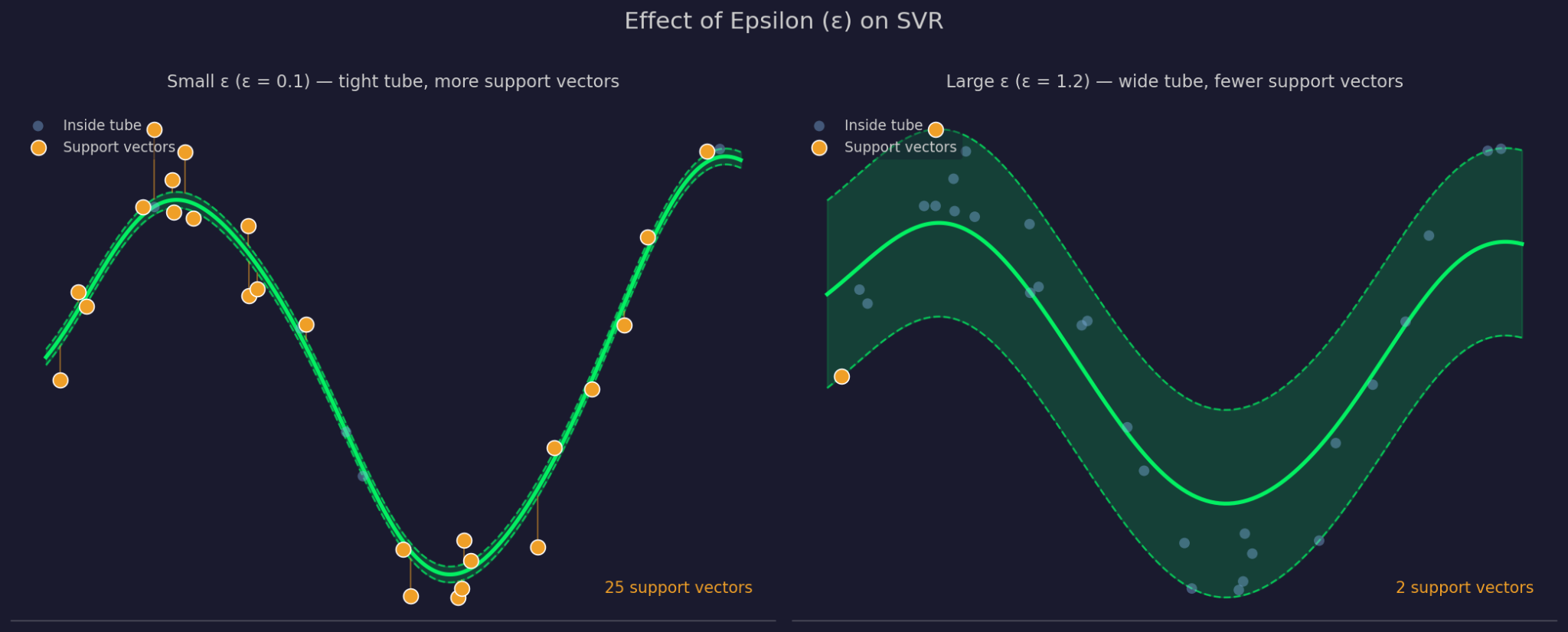
小さいイプシロン vs 大きいイプシロン
C は、チューブ外の点での誤差に対する SVR のペナルティの強さを制御します。C が大きいと、それらの誤差を重く扱い、よりタイトにフィットします。C が小さいと、より単純で平坦な関数と引き換えに、違反を多めに受け入れます。C と ε は連動しており、一方を変えると他方の実質的な挙動にも影響します。
小さい C vs 大きい C
カーネルは、SVR が非線形パターンをどのように扱うかを決めます。RBF は最も一般的な選択で、デフォルトとして有効に機能します。多項式カーネルは特定の曲線形状に有用です。線形カーネルは SVR をマージンベースの線形回帰に近づけ、データがすでに素直な場合に有用です。
SVR をうまく機能させるには、いくつかのステップと前提条件を踏むことが重要です。以下で手順を示します。
典型的なワークフローは次のとおりです。
データをスケーリングする: SVR は特徴量のスケールに敏感です。特徴量のスケールが異なると、モデルは期待どおりに振る舞いません。学習前に X と y の両方に StandardScaler を適用してください
カーネルを選ぶ: ほとんどの問題では RBF が適切なデフォルトです。関係がその形に従うと考える明確な理由がある場合は多項式に切り替えます
パラメータをチューニングする: 学習前に C、epsilon、gamma を設定します。グリッドサーチや交差検証が標準的なアプローチです
モデルを学習する: スケーリングした学習データに対して .fit() を呼び出します。学習後は、評価前に予測値を逆変換して元のスケールに戻します
以下は scikit-learn を用いた完全な例です。
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
テストセットの RMSE
このコードで注目すべき点がいくつかあります。まず、StandardScaler は X と y の両方に個別に適用しています。特徴量だけをスケーリングするのは、SVR で結果が悪化する一般的なミスです。次に、評価の前に予測値を逆変換して元のスケールに戻しています。
下の2つのプロットは、当てはめられたモデルの様子を示します。最初の図は、学習データとテストデータに対する SVR の曲線とイプシロンチューブです。
学習データとテストデータ上のイプシロンチューブ
2つ目は、テストセットでの予測値と実測値の比較です。
予測値と実測値の比較
対角線に近い点が多いほど、モデルの予測は良好です。
SVR には、適切な状況で最適となる明確な強みがあります。同時に、他の状況では不向きとなる弱点もあります。
SVR は特定の条件下で最も効果を発揮します。次のような場合に SVR を使ってください。
次のような場合は SVR を避けてください。
データセットが大規模でノイズが多い場合は、まず勾配ブースティング系の手法を検討する価値があります。SVR は、単純なモデルではうまく当てはめられない構造を持つ、クリーンで中規模のデータに最適です。
SVR に関する多くの問題は、同じ種類のミスに集約されます。以下を「やってはいけないこと」のチートシートとして扱ってください。
特徴量をスケーリングしない。 SVR は距離に基づくアルゴリズムです。スケールされていない特徴量がモデルを支配します。学習前に必ず X と y の両方に StandardScaler を適用してください。
イプシロンの誤解。 イプシロンは最も重要なパラメータです。大きすぎると、無視しすぎてアンダーフィットします。小さすぎると、標準的な回帰のように各データ点を追いかけてしまいます。グリッドサーチを行い、テストセットで最も良いものを探してください。
パラメータ調整を省略する。 既定値のまま SVR を走らせて良い結果を期待するのは、他の多くの機械学習モデルと同様に、まずうまくいきません。C、イプシロン、ガンマは一緒に調整する必要があります。交差検証つきのグリッドサーチを使いましょう。
非常に大きなデータセットに SVR を使う。 数千サンプルを超えると、SVR は遅くなりがちです。他のアルゴリズムのようにはスケールしません。勾配ブースティングやニューラルネットワークなど、大規模データに適したモデルに切り替えましょう。
また、ここで挙げた4点を正しく行っても必ずしも優れたモデルが得られるとは限りませんが、いずれかを誤ると確実に悪い結果に繋がることも覚えておいてください。
結論として、SVR は標準的な回帰とは異なる問題を解きます。すべての誤差を最小化するのではなく、マージン内で関数を当てはめ、その内側に収まるノイズを無視します。これこそが、データがクリーンでも完全に線形でもないときに役立つ理由です。
SVR は速度や単純さで知られているわけではありません。しかし堅牢です。非線形関係や、モデリングしたくない外れ値がある場合、SVR はすべてのデータ点を追いかけるのではなく、構造に注目する方法を提供してくれます。
特徴量のスケーリング、パラメータのチューニング、適切なカーネルの選択、そしてデータ量を控えめに保つことを忘れないでください。これらを適切に行えば、SVR は本番環境でも破綻しにくい堅牢なモデルを提供してくれます。
SVR はデータサイエンティストなら知っておくべきツールの一つにすぎません。2026年の就業準備に向けて、Machine Learning Engineer トラックに登録し、他の手法も学びましょう。
DataCamp で学ぶ
Tracks
Courses
Courses