
Program
Pembelajaran Mesin Terawasi dalam Python
25 Hr
Metode regresi standar meminimalkan total galat pada semua titik data. Artinya setiap residual, sekecil apa pun, menarik model ke suatu arah. Akibatnya, Anda mendapatkan model yang peka terhadap noise dan outlier.
Sebaliknya, model support vector regression memasangkan fungsi di dalam margin toleransi dan mengabaikan galat yang berada di dalamnya. Margin tersebut mengubah gagasan optimasi. Alih-alih mencoba mengoptimalkan setiap titik data, SVR berfokus pada struktur keseluruhan data, yang membuatnya, seperti yang akan saya tunjukkan, tangguh pada data dunia nyata.
Jika Anda memerlukan pengantar sebelum mulai, baca artikel Linear Regression in Python kami untuk pengenalan pemodelan prediktif.
Support Vector Regression adalah metode regresi yang dibangun di atas fondasi yang sama dengan Support Vector Machines (SVM), yaitu kelas model yang awalnya dirancang untuk tugas klasifikasi seperti deteksi spam atau pengenalan gambar.
Gagasan utamanya mudah dipahami — alih-alih mencoba meminimalkan setiap galat prediksi, SVR memasangkan fungsi sambil mengizinkan margin toleransi di sekitarnya. Galat yang berada dalam margin tersebut tidak diperhitungkan. Model berfokus untuk mendapatkan kecocokan keseluruhan yang baik, bukan membetulkan setiap penyimpangan kecil.
Itulah yang membedakan SVR dari sebagian besar model regresi lainnya.
Metode regresi standar memperlakukan setiap residual sebagai sinyal. SVR menganggap sebagian besarnya sebagai noise. Akibatnya, Anda mendapatkan model yang kurang peduli untuk tepat pada setiap titik dan lebih peduli untuk menangkap struktur mendasar data.
Pusat SVR adalah sesuatu yang disebut epsilon tube — margin toleransi yang menyelimuti fungsi terpasang di kedua sisinya.
Setiap titik data yang berada di dalam tabung dianggap cukup dekat. SVR mengabaikan titik-titik tersebut saat memasangkan model. Hanya titik-titik di luar tabung yang penting, karena merekalah yang benar-benar membentuk batas keputusan.
Contoh Epsilon tube
Begini cara menafsirkannya:
Inilah yang membedakan SVR dari regresi standar. Pada regresi linear, setiap titik data menarik model — termasuk yang bising. Pada SVR, sebagian besar titik tidak relevan. Hasilnya adalah kecocokan yang dibentuk oleh struktur keseluruhan yang baik.
SVR memiliki dua tujuan yang saling bersaing yang coba dipenuhi sekaligus.
Pertama, menjaga model tetap serata mungkin. Fungsi yang lebih rata lebih sederhana, dan model yang lebih sederhana cenderung lebih mampu melakukan generalisasi pada data baru. Kedua, meminimalkan galat pada titik-titik di luar epsilon tube — titik-titik yang tidak bisa diabaikan oleh SVR.
Kedua tujuan ini saling tarik-menarik, dan di situlah parameter regularisasi C berperan. Ia mengendalikan seberapa besar bobot yang diberikan SVR pada galat di luar tabung relatif terhadap kesederhanaan model:
Anda selalu menukar kesederhanaan model dengan toleransi galat. Nilai C yang tepat bergantung pada data Anda dan seberapa banyak noise yang diharapkan. Salah memilih ke salah satu arah akan menurunkan kinerja model pada data baru.
Ini adalah masalah optimasi yang dapat diselesaikan secara iteratif, jadi tidak perlu dikhawatirkan.
Dengan SVR, hanya titik data yang berada di luar epsilon tube yang benar-benar penting.
Inilah yang disebut support vector — titik data yang berada di luar margin dan membentuk fungsi terpasang. Semua yang ada di dalam tabung diabaikan saat pelatihan. Model tidak pernah “melihat” titik-titik tersebut dengan cara yang bermakna.
Support vector
Efek samping yang bermanfaat dari ini adalah kelangkaan (sparsity). Dalam praktiknya, hanya sebagian kecil dari data pelatihan yang berakhir sebagai support vector. Sisanya tidak menyumbang apa pun ke model akhir, yang membuat SVR hemat memori dan cepat dievaluasi setelah dilatih, karena prediksi hanya bergantung pada sedikit titik yang berpengaruh tersebut.
SVR tidak terbatas pada pemodelan garis lurus. Ia dapat menangani hubungan nonlinier melalui teknik yang disebut kernel trick.
Jadi, alih-alih memasangkan fungsi di ruang masukan asli, SVR memetakan data ke ruang berdimensi lebih tinggi di mana kecocokan linear menjadi mungkin. Kecocokan linear di ruang berdimensi lebih tinggi tersebut diterjemahkan kembali menjadi kurva nonlinier pada data asli Anda.
Dua kernel yang paling umum Anda gunakan adalah:
Pemilihan kernel bergantung pada data Anda. RBF adalah titik awal yang baik ketika Anda belum yakin.
Perbedaannya terletak pada apa yang coba dilakukan masing-masing model.
Regresi linear meminimalkan total galat pada setiap titik data. Setiap residual dihitung, sekecil apa pun. Jika Anda menarik model keluar jalur dengan titik yang bising, seluruh kecocokan bergeser untuk mengompensasi.
SVR mengabaikan galat di dalam epsilon tube. Ia hanya bereaksi terhadap titik yang berada di luar margin — dan bahkan saat itu, C mengendalikan seberapa kuat reaksinya. Model mengoptimalkan struktur, bukan akurasi pada setiap titik secara individual.
Perbedaan itu membuat SVR lebih tangguh terhadap outlier. Satu titik bising tidak akan merusak kecocokan seperti pada regresi linear, karena SVR memang tidak mencoba mengejarnya sejak awal.
Berikut semua perbedaannya:

Regresi linear dibandingkan dengan SVR
SVR memiliki tiga parameter yang perlu Anda pahami sebelum mulai mengoptimalkan model.
Epsilon mendefinisikan lebar margin toleransi di sekitar fungsi terpasang. ε yang lebih besar berarti tabung yang lebih lebar — lebih banyak titik diabaikan dan model menjadi lebih sederhana. ε yang lebih kecil mempersempit tabung dan memaksa model lebih rapat mengikuti data.
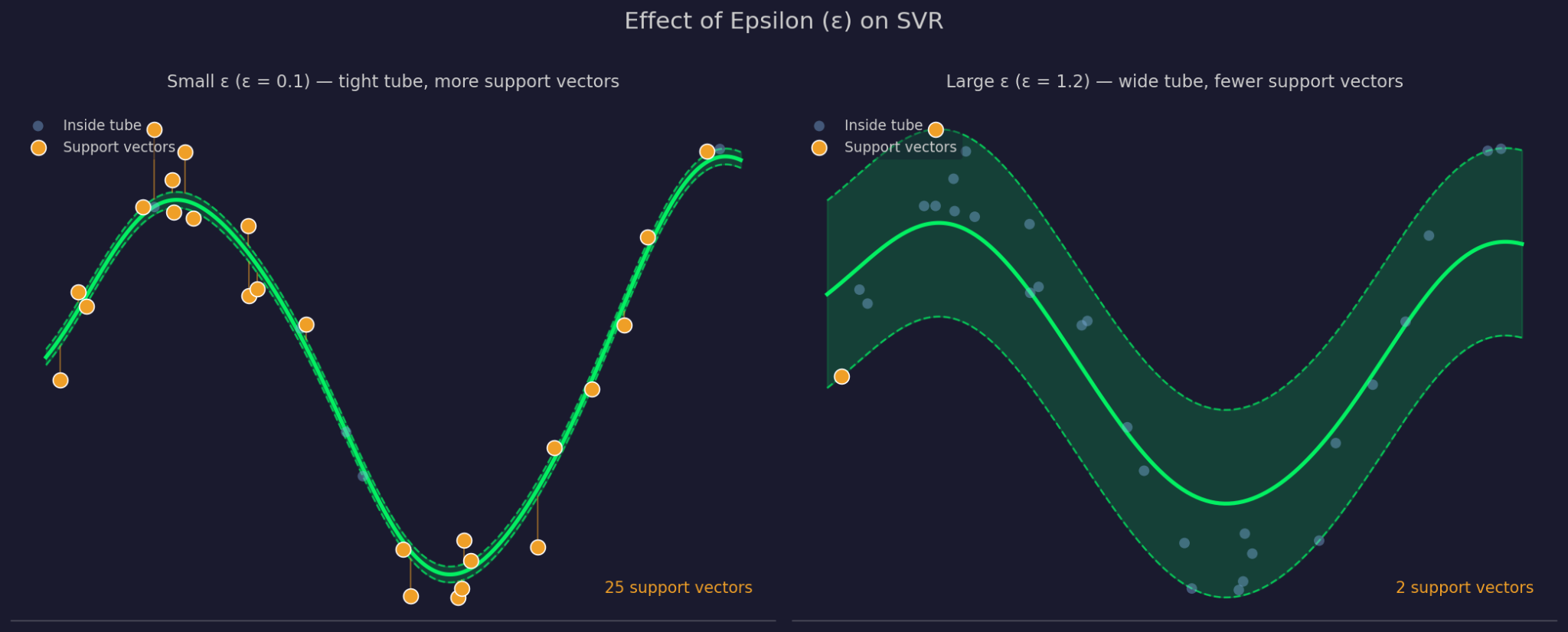
Epsilon kecil versus besar
C mengendalikan seberapa besar SVR menghukum galat pada titik di luar tabung. C tinggi berarti model menanggapi galat tersebut dengan serius dan memasangkan lebih ketat. C rendah berarti model menerima lebih banyak pelanggaran demi fungsi yang lebih sederhana dan rata. C dan ε bekerja bersama, karena mengubah salah satunya memengaruhi perilaku yang lain dalam praktik.
C kecil versus besar
Kernel menentukan bagaimana SVR menangani pola nonlinier. RBF adalah pilihan paling umum dan bekerja baik sebagai default. Kernel polinomial berguna untuk bentuk kurva tertentu. Kernel linear mereduksi SVR menjadi regresi linear berbasis margin, yang bisa berguna ketika data Anda sudah tertata baik.
Membuat SVR bekerja dengan baik melibatkan beberapa langkah dan prasyarat. Berikut yang perlu Anda lakukan.
Berikut alur kerja yang umum:
Skalakan data Anda: SVR peka terhadap skala fitur. Jika fitur Anda berada pada skala yang berbeda, model tidak akan berperilaku seperti yang diharapkan. Gunakan StandardScaler pada X dan y sebelum melakukan fitting
Pilih kernel: RBF adalah default yang tepat untuk sebagian besar masalah. Beralihlah ke polinomial jika Anda punya alasan spesifik untuk percaya hubungan mengikuti bentuk tersebut
Setel parameter Anda: Tetapkan C, epsilon, dan gamma sebelum fitting. Grid search atau cross-validation adalah pendekatan standar di sini
Latih model: Panggil .fit() pada data pelatihan yang telah diskalakan. Setelah dilatih, lakukan inverse-transform pada prediksi ke skala asli
Berikut contoh lengkap menggunakan scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE pada set uji
Beberapa hal yang perlu diperhatikan pada kode ini. Pertama, StandardScaler diterapkan secara terpisah pada X dan y. Hanya menskalakan fitur adalah kesalahan umum yang menyebabkan hasil buruk dengan SVR. Kedua, prediksi di-inverse-transform di akhir untuk mengembalikannya ke skala asli sebelum evaluasi.
Dua plot di bawah menunjukkan seperti apa model terpasang. Yang pertama menunjukkan kurva SVR dengan epsilon tube pada data pelatihan dan uji:
Epsilon tube pada data pelatihan dan uji
Yang kedua membandingkan nilai prediksi versus aktual pada set uji:
Nilai prediksi versus aktual
Titik-titik yang dekat dengan diagonal berarti model memprediksi dengan baik.
SVR memiliki serangkaian kekuatan spesifik yang membuatnya tepat pada situasi yang tepat. Demikian pula, ia memiliki kelemahan yang membuatnya kurang tepat pada situasi lain.
SVR bekerja paling baik dalam kondisi tertentu. Anda sebaiknya menggunakan SVR ketika:
Anda sebaiknya menghindari SVR ketika:
Jika dataset Anda besar dan bising, metode gradient boosting patut dipertimbangkan terlebih dahulu. SVR sangat baik ketika Anda memiliki data yang bersih, berukuran sedang, dengan struktur yang tidak dapat dipasangkan dengan baik oleh model yang lebih sederhana.
Sebagian besar masalah dengan SVR bermuara pada serangkaian kesalahan yang sama — jadi anggap ini sebagai daftar ringkas hal-hal yang tidak boleh dilakukan.
Tidak menskalakan fitur Anda. SVR adalah algoritma berbasis jarak, yang berarti fitur yang tidak diskalakan akan mendominasi model. Selalu terapkan StandardScaler pada X dan y sebelum fitting.
Salah paham tentang epsilon. Epsilon adalah parameter terpenting. Terlalu besar dan model Anda underfit karena terlalu banyak mengabaikan. Terlalu kecil dan ia berperilaku seperti regresi standar, mengejar setiap titik data. Selalu lakukan grid search untuk melihat mana yang paling baik pada set uji Anda.
Melewatkan penyetelan parameter. Menjalankan SVR dengan parameter default dan mengharapkan hasil yang baik jarang berhasil — seperti sebagian besar model pembelajaran mesin. C, epsilon, dan gamma perlu disetel bersama. Gunakan grid search dengan cross-validation.
Menggunakan SVR pada dataset yang sangat besar. Jika Anda memiliki lebih dari beberapa ribu sampel, SVR akan lambat. Ia memang tidak berskala seperti algoritma lain. Beralihlah ke model yang lebih cocok untuk dataset besar, seperti gradient boosting atau jaringan saraf.
Penting juga untuk dicatat bahwa melakukan empat hal ini dengan benar tidak menjamin model yang hebat, tetapi salah satunya hampir pasti menjamin hasil yang buruk.
Sebagai penutup, ingat bahwa SVR menyelesaikan masalah yang berbeda dari regresi standar. Alih-alih meminimalkan setiap galat, ia memasangkan fungsi di dalam margin dan mengabaikan noise yang berada di dalamnya — yang membuatnya berguna saat data Anda tidak bersih atau tidak sepenuhnya linear.
SVR tidak dikenal karena kecepatan atau kesederhanaannya. Namun ia tangguh. Jika data Anda memiliki hubungan nonlinier dan outlier yang tidak ingin Anda modelkan, SVR memberi cara untuk berfokus pada struktur alih-alih mengejar setiap titik data.
Ingatlah untuk menskalakan fitur, menyetel parameter, memilih kernel yang tepat, dan tetap konservatif dengan jumlah data. Jika Anda melakukan ini dengan benar, SVR akan memberi model yang tangguh dan kecil kemungkinannya gagal di produksi.
SVR hanyalah salah satu alat yang harus diketahui setiap data scientist. Daftar di jalur Machine Learning Engineer kami untuk mempelajari yang lain dan siap kerja pada 2026.
Belajar dengan DataCamp
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
