
Program
Denetimli Makine Öğrenimi Python'da
25 sa
Standart regresyon yöntemleri, tüm veri noktalarındaki toplam hatayı en aza indirir. Bu da, ne kadar küçük olursa olsun her artık değerin modeli bir yöne çektiği anlamına gelir. Sonuç olarak, gürültüye ve aykırı değerlere duyarlı bir modelle baş başa kalırsınız.
Öte yandan, bir destek vektör regresyon modeli bir tolerans marjı içinde bir fonksiyon uydurur ve bu marjın içinde kalan hataları yok sayar. Bu marj, optimizasyon fikrini değiştirir. SVR, her veri noktasını optimize etmeye çalışmak yerine verinin genel yapısına odaklanır; bu da, size göstermeyi umduğum üzere, gerçek dünya verilerinde dayanıklı olmasını sağlar.
Başlamadan önce kısa bir özet gerekiyorsa, öngörücü modellemeye giriş için Python ile Doğrusal Regresyon makalemizi okuyun.
Destek Vektör Regresyonu, temeli Destek Vektör Makineleri (SVM) ile aynı olan bir regresyon yöntemidir; SVM, aslen spam tespiti veya görüntü tanıma gibi sınıflandırma görevleri için tasarlanmış bir model sınıfıdır.
Temel fikir anlaşılması kolaydır - her tahmin hatasını en aza indirmeye çalışmak yerine, SVR etrafında bir tolerans marjına izin vererek bir fonksiyon uydurur. Bu marjın içinde kalan hatalar sayılmaz. Model, her küçük saplamayı düzeltmekten ziyade genel uyumu doğru yapmaya odaklanır.
SVR’yi çoğu diğer regresyon modelinden ayıran şey budur.
Standart regresyon yöntemleri her artık değeri bir sinyal olarak görür. SVR ise çoğunu gürültü olarak görür. Sonuç olarak, her noktada tam isabetten ziyade verinin temel yapısını doğru yakalamaya daha çok önem veren bir model elde edersiniz.
SVR’nin merkezinde epsilon tüpü olarak adlandırılan bir şey vardır - uydurulan fonksiyonun her iki yanını saran bir tolerans marjı.
Tüpün içine düşen herhangi bir veri noktası yeterince yakın kabul edilir. SVR, modeli uydururken bu noktaları yok sayar. Yalnızca tüpün dışındaki noktalar önemlidir; çünkü kararı şekillendiren sınırı aslında onlar belirler.
Epsilon tüpü örneği
Bunu şöyle yorumlayabilirsiniz:
SVR’yi standart regresyondan ayıran şey budur. Doğrusal regresyonda, gürültülü olanlar da dâhil her veri noktası modeli çeker. SVR’de ise çoğu nokta ilgisizdir. Sonuç, genel iyi yapı tarafından belirlenen bir uyumdur.
SVR’nin aynı anda tatmin etmeye çalıştığı iki rakip hedefi vardır.
İlki, modeli olabildiğince düz tutmaktır. Daha düz bir fonksiyon daha basittir ve basit modeller yeni verilere daha iyi genellenme eğilimindedir. İkincisi ise epsilon tüpünün dışındaki noktalardaki hataları en aza indirmektir - SVR’nin yok sayamayacağı noktalar bunlardır.
Bu iki hedef zıt yönlere çeker ve işte burada düzenlileştirme parametresi C devreye girer. C, SVR’nin tüp dışındaki hatalara, model basitliğine kıyasla ne kadar ağırlık verdiğini kontrol eder:
Her zaman model basitliği ile hata toleransı arasında bir ödünleşim yaparsınız. Doğru C değeri, verinize ve beklediğiniz gürültü miktarına bağlıdır. Her iki yönde de yanlış seçmek, modelinizin yeni verilerdeki performansını düşürecektir.
Bu, yinelemeli olarak çözülebilen bir optimizasyon problemidir; dolayısıyla endişe edilecek bir şey yok.
SVR’de, yalnızca epsilon tüpünün dışına düşen veri noktaları gerçekte önemlidir.
Bunlar, destek vektörleridir - marjın ötesinde yer alan ve uydurulan fonksiyonu şekillendiren veri noktaları. Tüpün içindeki her şey eğitim sırasında yok sayılır. Model bu noktaları anlamlı bir şekilde asla "görmez".
Destek vektörleri
Bunun faydalı bir yan etkisi de seyrekliktir. Pratikte, eğitim verilerinizin yalnızca küçük bir altkümesi destek vektörü olur. Geri kalanı nihai modele hiçbir şey katmaz; bu da SVR’yi, eğitim tamamlandıktan sonra bellek açısından verimli ve değerlendirmesi hızlı kılar; çünkü tahminler yalnızca bu az sayıdaki etkili noktaya bağlıdır.
SVR sadece düzgün çizgiler uydurmakla sınırlı değildir. çekirdek hilesi adı verilen bir teknikle doğrusal olmayan ilişkileri ele alabilir.
Yani, orijinal girdi uzayında bir fonksiyon uydurmak yerine, SVR veriyi doğrusal uyumun mümkün olduğu daha yüksek boyutlu bir uzaya eşler. Daha yüksek boyutlu uzaydaki bu doğrusal uyum, orijinal verinizde doğrusal olmayan bir eğriye karşılık gelir.
En sık kullanacağınız iki çekirdek şunlardır:
Çekirdek seçiminiz verinize bağlıdır. Emin olmadığınızda RBF iyi bir başlangıç noktasıdır.
Fark, her modelin neyi amaçladığına dayanır.
Doğrusal regresyon tüm veri noktaları boyunca toplam hatayı en aza indirir. Her artık değer, ne kadar küçük olursa olsun hesaba katılır. Gürültülü bir nokta modeli rotasından saptırırsa, tüm uyum bunu telafi etmek için kayar.
SVR, epsilon tüpü içindeki hataları yok sayar. Yalnızca marjın dışına düşen noktalara tepki verir - ve o zaman bile tepkinin şiddetini C belirler. Model, her bir noktadaki doğruluğa değil, yapıya göre optimize edilir.
Bu fark, SVR’yi aykırı değerlere karşı daha dayanıklı kılar. Tek bir gürültülü nokta, doğrusal regresyonda olduğu gibi uyumu raydan çıkaramaz; çünkü SVR en başta onu kovalamaya çalışmıyordu.
Farkların tümü şunlardır:

Doğrusal regresyon ve SVR karşılaştırması
SVR’yi optimize etmeye başlamadan önce anlamanız gereken üç parametre vardır.
Epsilon, uydurulan fonksiyon etrafındaki tolerans marjının genişliğini tanımlar. Daha büyük ε daha geniş bir tüp anlamına gelir - daha fazla nokta yok sayılır ve model basitleşir. Daha küçük ε tüpü daraltır ve modelin veriye daha yakından uymasını zorlar.
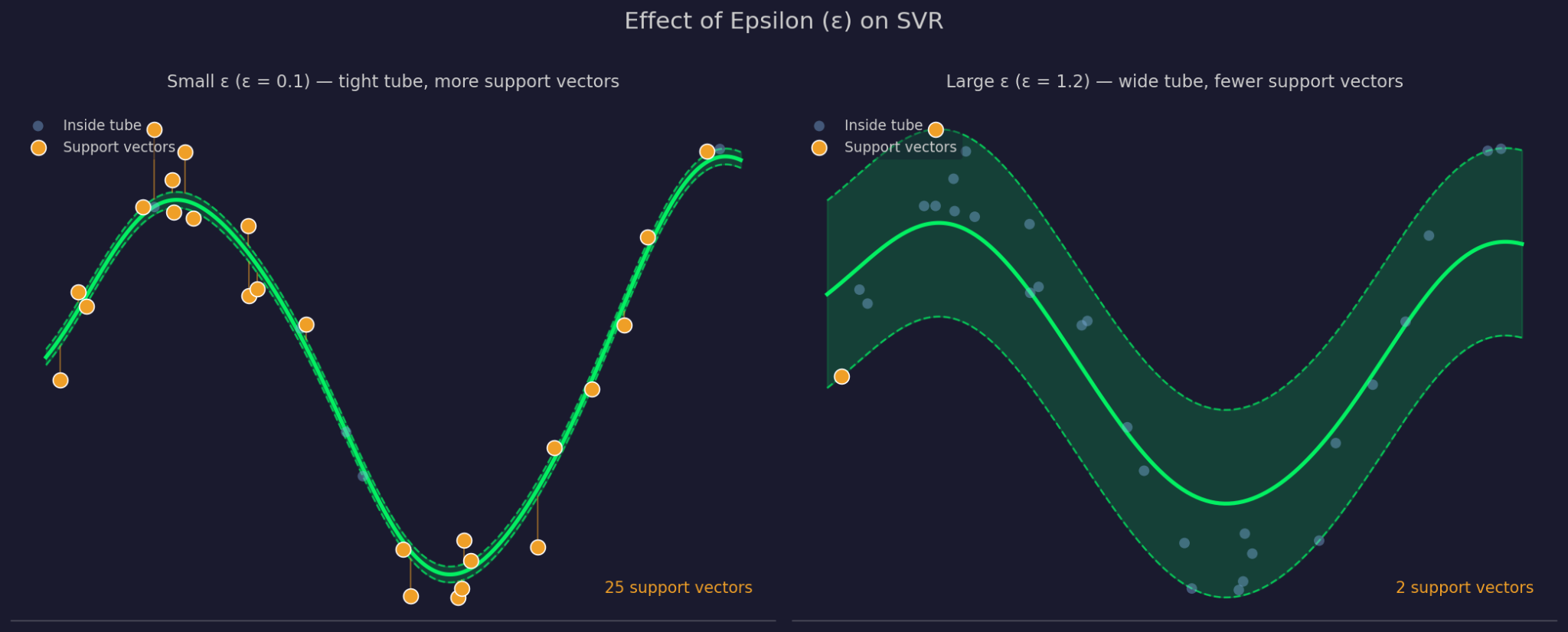
Küçük ve büyük Epsilon
C, SVR’nin tüp dışındaki noktalardaki hataları ne kadar cezalandırdığını kontrol eder. Yüksek C, modelin bu hataları ciddiye alması ve daha sıkı uyum yapması demektir. Düşük C, daha basit ve daha düz bir fonksiyon karşılığında modelin daha fazla ihlali kabul etmesi demektir. C ve ε birlikte çalışır; birini değiştirmek diğerinin pratikteki davranışını etkiler.
Küçük ve büyük C
Çekirdek, SVR’nin doğrusal olmayan desenleri nasıl ele alacağını belirler. RBF en yaygın tercihtir ve varsayılan olarak iyi çalışır. Polinom çekirdekler belirli eğri şekilleri için kullanışlıdır. Doğrusal çekirdekler, SVR’yi marj temelli bir doğrusal regresyona indirger; veriniz zaten düzgün davranıyorsa faydalı olabilir.
SVR’yi iyi çalıştırmak, birkaç adımı ve ön koşulu takip etmekle ilgilidir. Bunların neler olduğuna bakalım.
Tipik iş akışı şöyledir:
Verinizi ölçekleyin: SVR, özellik ölçeğine duyarlıdır. Özellikleriniz farklı ölçeklerdeyse model beklediğiniz gibi davranmaz. Uydurmadan önce hem X hem de y için StandardScaler kullanın
Bir çekirdek seçin: Çoğu problem için RBF doğru varsayılandır. İlişkinin o şekli izlediğine özel bir nedeniniz varsa polinoma geçin
Parametrelerinizi ayarlayın: Uydurmadan önce C, epsilon ve gamma değerlerini belirleyin. Grid araması veya çapraz doğrulama burada standart yaklaşımlardır
Modeli uydurun: Ölçeklenmiş eğitim verisi üzerinde .fit() çağırın. Eğitim tamamlandığında, değerlendirmeden önce tahminlerinizi orijinal ölçeğe geri döndürün (inverse-transform)
İşte scikit-learn ile tam bir örnek:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
Test kümesinde RMSE
Bu kodda dikkat edilmesi gereken birkaç nokta var. İlk olarak, StandardScaler hem X hem de y için ayrı ayrı uygulanır. Yalnızca özellikleri ölçeklemek, SVR ile zayıf sonuçlara yol açan yaygın bir hatadır. İkincisi, değerlendirmeden önce tahminler orijinal ölçeğe geri döndürülür.
Aşağıdaki iki grafik, uydurulan modelin nasıl göründüğünü gösterir. İlki, eğitim ve test verileri üzerinde epsilon tüpü ile birlikte SVR eğrisini gösterir:
Eğitim ve test verileri üzerinde Epsilon tüpü
İkincisi, test kümesinde tahmin edilen değerlerle gerçek değerleri karşılaştırır:
Tahmin edilen ve gerçek değerler
Köşegenin yakınındaki noktalar, modelin iyi tahmin yaptığını gösterir.
SVR’nin, doğru durumda doğru araç olmasını sağlayan belirli güçlü yönleri vardır. Benzer şekilde, yanlış olduğu durumlar için de zayıf yönleri vardır.
SVR belirli koşullar altında en iyi sonucu verir. SVR’yi şu durumlarda kullanmalısınız:
SVR’den kaçınmalısınız:
Veri kümeniz büyük ve gürültülüyse, önce gradyan artırma yöntemlerine bakmaya değerdir. SVR, daha basit modellerin iyi uyduramadığı yapı içeren, temiz ve orta büyüklükte veriniz olduğunda harikadır.
SVR ile ilgili sorunların çoğu aynı hata setine dayanır - bu yüzden bunu yapılmaması gerekenlerin bir kopya kâğıdı olarak görün.
Özelliklerinizi ölçeklememek. SVR bir mesafe temelli algoritmadır; bu da ölçeklenmemiş özelliklerin modeli domine edeceği anlamına gelir. Uydurmadan önce her zaman hem X hem de y için StandardScaler uygulayın.
Epsilon’ı yanlış anlamak. Epsilon açık ara en önemli parametredir. Çok büyükse model aşırı geneller çünkü çok şeyi yok sayar. Çok küçükse standart regresyon gibi davranır ve her veri noktasını kovalar. Test kümeniz üzerinde en iyi performansı neyin verdiğini görmek için mutlaka grid araması yapın.
Parametre ayarlamasını atlamak. SVR’yi varsayılan parametrelerle çalıştırıp iyi sonuç beklemek nadiren işe yarar - tıpkı çoğu makine öğrenmesi modelinde olduğu gibi. C, epsilon ve gamma birlikte ayarlanmalıdır. Çapraz doğrulama ile grid araması kullanın.
SVR’yi çok büyük veri kümelerinde kullanmak. Birkaç bin örnekten fazlanız varsa SVR yavaş olacaktır. Diğer algoritmalar gibi iyi ölçeklenmez. Gradyan artırma veya bir sinir ağı gibi büyük veri kümeleriyle daha iyi çalışan bir modele geçin.
Ayrıca şunu da not etmek önemlidir: Bu dört şeyi doğru yapmak harika bir modeli garanti etmez, ancak bunlardan herhangi birini yanlış yapmak neredeyse kesinlikle kötü bir modeli garanti eder.
Sonuç olarak, SVR’nin standart regresyondan farklı bir problemi çözdüğünü unutmayın. Her hatayı en aza indirmek yerine, bir marj içinde bir fonksiyon uydurur ve bu marjın içine düşen gürültüyü yok sayar - ki bu, veriniz temiz veya mükemmel doğrusal olmadığında onu faydalı kılan şeydir.
Hız veya sadelikle ünlü değildir. Ama dayanıklıdır. Verinizde modellemek istemediğiniz doğrusal olmayan ilişkiler ve aykırı değerler varsa, SVR size her veri noktasını kovalamak yerine yapıya odaklanmanın bir yolunu sunar.
Yalnızca özelliklerinizi ölçeklemeyi, parametrelerinizi ayarlamayı, doğru çekirdeği seçmeyi ve veri miktarında temkinli olmayı unutmayın. Bunları doğru yaparsanız, SVR üretimde başarısız olma olasılığı düşük, dayanıklı bir model sunar.
SVR, her veri bilimcisinin bilmesi gereken araçlardan yalnızca biridir. Diğerlerini öğrenmek ve 2026’da işe hazır olmak için Makine Öğrenimi Mühendisi yoluna kaydolun.
DataCamp ile öğrenin
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
