track
Övervakad maskininlärning i Python
25 timmar
Standardmetoder för regression minimerar den totala felmängden över alla datapunkter. Det betyder att varje residual, oavsett hur liten, drar modellen i någon riktning. Resultatet blir en modell som är känslig för brus och avvikare.
En supportvektorregressionsmodell å andra sidan anpassar en funktion inom en toleransmarginal och ignorerar fel som faller inom den. Den marginalen förändrar idén om optimering. I stället för att försöka optimera varje datapunkt fokuserar SVR på den övergripande strukturen i data, vilket gör den, som jag hoppas visa dig, robust på data från verkligheten.
Om du behöver en introduktion innan vi börjar, läs vår artikel Linear Regression in Python för en introduktion till prediktiv modellering.
Support Vector Regression är en regressionsmetod byggd på samma grund som Support Vector Machines (SVM), som är en modellklass ursprungligen utformad för klassificeringsuppgifter som spamdetektion eller bildigenkänning.
Grundidén är lätt att förstå – i stället för att försöka minimera varje prediktionsfel anpassar SVR en funktion samtidigt som den tillåter en toleransmarginal runt den. Fel som faller inom den marginalen räknas inte. Modellen fokuserar på att få den övergripande passformen rätt, inte på att korrigera varje liten avvikelse.
Det är det som skiljer SVR från de flesta andra regressionsmodeller.
Standardmetoder för regression behandlar varje residual som en signal. SVR betraktar de flesta som brus. Som resultat får du en modell som mindre bryr sig om att vara exakt rätt på varje punkt och mer om att få den underliggande datastrukturen rätt.
I centrum av SVR finns något som kallas epsilonröret – en toleransmarginal som omsluter den anpassade funktionen på båda sidor.
Alla datapunkter som faller innanför röret anses tillräckligt nära. SVR ignorerar dessa punkter när modellen anpassas. Endast punkterna utanför röret spelar roll, eftersom det är de som faktiskt formar beslutsgränsen.
Exempel på epsilonröret
Så här kan du tolka det:
Detta är vad som skiljer SVR från standardregression. I linjär regression drar varje datapunkt i modellen – även de brusiga. I SVR är de flesta punkter irrelevanta. Resultatet är en passform driven av en god övergripande struktur.
SVR har två motstridiga mål som den försöker uppfylla samtidigt.
Det första är att hålla modellen så platt som möjligt. En plattare funktion är enklare, och enklare modeller tenderar att generalisera bättre till ny data. Det andra är att minimera fel på punkter utanför epsilonröret – de som SVR inte kan ignorera.
Dessa två mål drar åt motsatta håll, och det är där regulariseringsparametern C kommer in. Den styr hur mycket vikt SVR lägger på fel utanför röret relativt till modelsimplahet:
Du gör alltid en avvägning mellan modelsimplahet och feltolerans. Rätt värde på C beror på dina data och hur mycket brus du förväntar dig. Blir det fel åt något håll minskar prestandan på ny data.
Det är ett optimeringsproblem som kan lösas iterativt, så det är inget att oroa sig för.
Med SVR är det bara datapunkterna som faller utanför epsilonröret som faktiskt spelar roll.
Dessa är supportvektorerna – datapunkterna som ligger bortom marginalen och formar den anpassade funktionen. Allt inuti röret ignoreras under träningen. Modellen "ser" aldrig de punkterna på något meningsfullt sätt.
Supportvektorer
Den nyttiga bieffekten av detta är gleshet. I praktiken blir det bara en liten delmängd av din träningsdata som hamnar som supportvektorer. Resten bidrar inte till den slutliga modellen, vilket gör SVR minnesnål och snabb att utvärdera när den väl är tränad, eftersom prediktioner bara beror på de få inflytelserika punkterna.
SVR är inte begränsad till att anpassa räta linjer. Den kan hantera icke-linjära samband genom en teknik som kallas kerneltricket.
Så i stället för att anpassa en funktion i det ursprungliga indatautrymmet mappar SVR datan till ett högre dimensionellt utrymme där en linjär anpassning blir möjlig. Den linjära anpassningen i det högre dimensionella utrymmet översätts tillbaka till en icke-linjär kurva i dina ursprungliga data.
De två vanligaste kärnorna du kommer att använda är:
Vilken kärna du väljer beror på dina data. RBF är en bra startpunkt när du är osäker.
Skillnaden handlar om vad varje modell försöker göra.
Linjär regression minimerar den totala felmängden över varje datapunkt. Varje residual räknas, oavsett hur liten den är. Om du drar modellen ur kurs med en brusig punkt skiftar hela passformen för att kompensera.
SVR ignorerar fel inom epsilonröret. Den reagerar bara på punkter som faller utanför marginalen – och även då styr C hur starkt. Modellen optimerar för struktur, inte för noggrannhet på varje enskild punkt.
Den skillnaden gör SVR mer robust mot avvikare. En enstaka brusig punkt kommer inte att styra passformen som i linjär regression, eftersom SVR aldrig försökte jaga den från första början.
Här är alla skillnaderna:

Linjär regression jämfört med SVR
SVR har tre parametrar du behöver förstå innan du börjar optimera modellen.
Epsilon definierar bredden på toleransmarginalen runt den anpassade funktionen. Ett större ε betyder ett bredare rör – fler punkter ignoreras och modellen blir enklare. Ett mindre ε stramar åt röret och tvingar modellen att anpassa sig närmare datan.
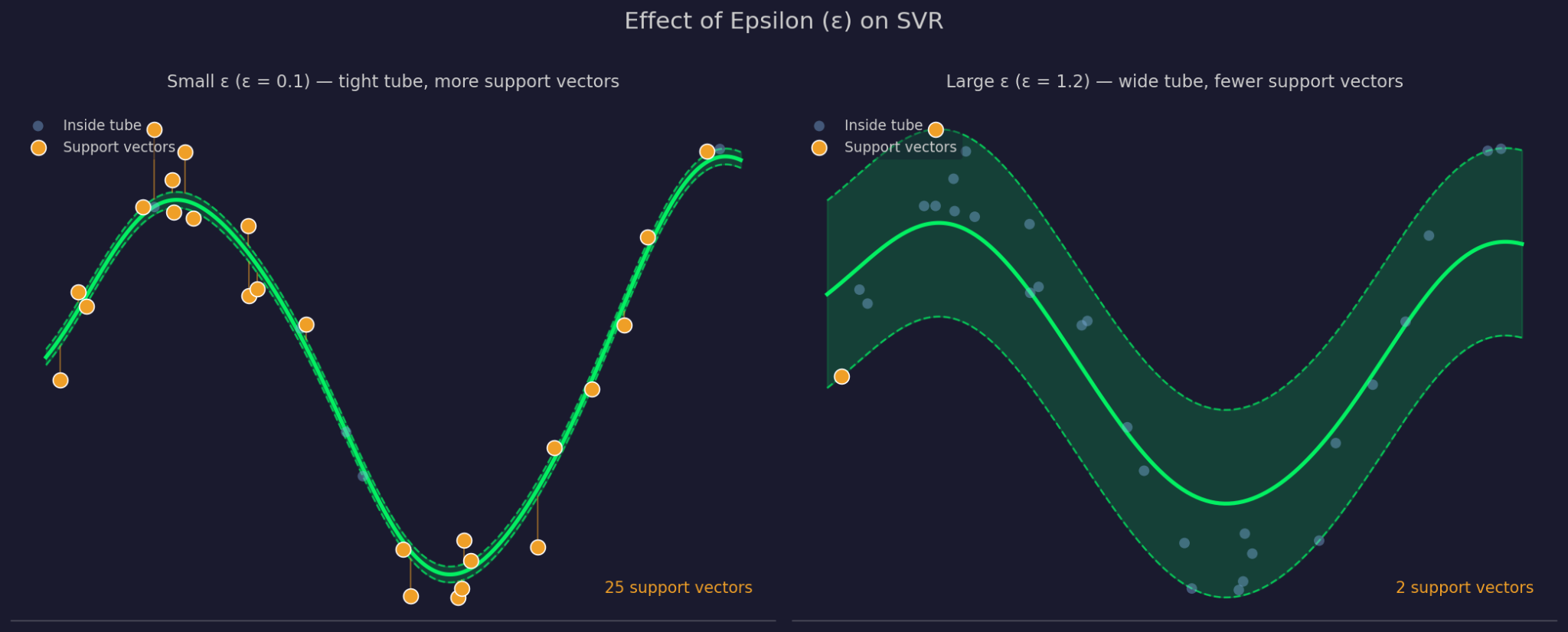
Litet kontra stort epsilon
C styr hur mycket SVR straffar fel på punkter utanför röret. Högt C innebär att modellen tar dessa fel på stort allvar och anpassar sig hårdare. Lågt C innebär att modellen accepterar fler överträdelser i utbyte mot en enklare, plattare funktion. C och ε samverkar, eftersom en förändring i den ena påverkar hur den andra beter sig i praktiken.
Litet kontra stort C
Kärnan avgör hur SVR hanterar icke-linjära mönster. RBF är det vanligaste valet och fungerar bra som standard. Polynomiella kärnor är användbara för specifika kurvformer. Linjära kärnor reducerar SVR till en marginalbaserad linjär regression, vilket kan vara användbart när dina data redan är välbeteende.
Att få SVR att fungera bra handlar om att gå igenom ett par steg och förutsättningar. Låt mig visa vad dessa är.
Här är det typiska arbetsflödet:
Skala dina data: SVR är känsligt för skalning av variabler. Om dina variabler ligger på olika skalor beter sig modellen inte som förväntat. Använd StandardScaler på både X och y innan anpassning
Välj en kärna: RBF är rätt standardval för de flesta problem. Byt till polynom om du har en specifik anledning att tro att sambandet följer den formen
Finjustera dina parametrar: Sätt C, epsilon och gamma innan anpassning. Rutnätssökning eller korsvalidering är standardmetoder här
Anpassa modellen: Anropa .fit() på de skalade träningsdatan. När den är tränad, invertera-transformera dina prediktioner tillbaka till ursprunglig skala
Här är ett komplett exempel med scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE på testmängden
Några saker att notera i den här koden. För det första tillämpas StandardScaler separat på både X och y. Att bara skala variablerna är ett vanligt misstag som leder till dåliga resultat med SVR. För det andra inverteras prediktionerna i slutet för att föra tillbaka dem till ursprunglig skala innan utvärdering.
De två diagrammen nedan visar hur den anpassade modellen ser ut. Det första visar SVR-kurvan med epsilonröret över tränings- och testdata:
Epsilonröret över tränings- och testdata
Det andra jämför predikterade mot faktiska värden på testmängden:
Predikterade kontra faktiska värden
Punkter nära diagonalen betyder att modellen predikterar väl.
SVR har en uppsättning styrkor som gör den rätt verktyg i rätt situation. Likaså har den svagheter som gör den fel val i andra.
SVR fungerar bäst under en specifik uppsättning förhållanden. Du bör använda SVR när:
Du bör undvika SVR när:
Om ditt dataset är stort och brusigt är metoder för gradient boosting värda att titta på först. SVR är utmärkt när du har rena, måttligt stora data med struktur som enklare modeller inte kan fånga väl.
De flesta problem med SVR handlar om samma uppsättning fel – så se detta som en fusklapp över vad du inte ska göra.
Att inte skala dina variabler. SVR är en avståndsbaserad algoritm, vilket betyder att oskalade variabler kommer att dominera modellen. Applicera alltid StandardScaler på både X och y innan anpassning.
Missförstå epsilon. Epsilon är den i särklass viktigaste parametern. För stort och din modell underanpassar då den ignorerar för mycket. För litet och den beter sig som standardregression och jagar varje datapunkt. Gör alltid en rutnätssökning för att se vad som fungerar bäst på din testmängd.
Att hoppa över parameterinställning. Att köra SVR med standardvärden och förvänta sig bra resultat fungerar sällan – precis som med de flesta maskininlärningsmodeller. C, epsilon och gamma behöver finjusteras tillsammans. Använd rutnätssökning med korsvalidering.
Att använda SVR på mycket stora dataset. Om du har mer än några tusen prover blir SVR långsam. Den skalar helt enkelt inte som andra algoritmer. Byt till en modell som fungerar bättre på stora dataset, som gradient boosting eller ett neuralt nätverk.
Det är också viktigt att notera att att få dessa fyra saker rätt inte garanterar en fantastisk modell, men att få någon av dem fel kommer nästan säkert att garantera en dålig.
Sammanfattningsvis: SVR löser ett annat problem än standardregression. I stället för att minimera varje fel anpassar den en funktion inom en marginal och ignorerar bruset som faller innanför – vilket är precis det som gör den användbar när dina data inte är rena eller perfekt linjära.
Den är inte känd för sin hastighet eller enkelhet. Men den är robust. Om dina data har icke-linjära samband och avvikare du inte vill modellera, ger SVR dig ett sätt att fokusera på struktur i stället för att jaga varje datapunkt.
Kom bara ihåg att skala dina variabler, ställa in dina parametrar, välja rätt kärna och vara konservativ med datamängden. Om du gör detta rätt får du med SVR en robust modell som sannolikt inte fallerar i produktion.
SVR är bara ett av de verktyg varje data scientist måste kunna. Gå vår Machine Learning Engineer-väg för att lära dig de andra och bli jobbklar 2026.
Lär dig med DataCamp
track
course
course