Tracks
监督机器学习 在 Python 中
25小时
标准回归方法会在所有数据点上最小化总误差。这意味着每一个残差——无论多小——都会把模型往某个方向拉。结果,您会得到一个对噪声和离群点很敏感的模型。
而支持向量回归模型则不同,它会在一个容差边界内拟合函数,并忽略落在该边界内的误差。这个边界改变了优化的思路。SVR并不试图优化每一个数据点,而是关注数据的整体结构,这也使它——正如我希望向您展示的——在真实世界数据上更稳健。
如果在开始之前您需要预备知识,请阅读我们的Python 线性回归文章以了解预测建模入门。
支持向量回归建立在与支持向量机(SVM)相同的基础之上,SVM最初是一类用于分类任务(如垃圾邮件检测或图像识别)的模型。
其核心思想很容易理解——SVR并不是试图最小化每一个预测误差,而是在允许一定容差的前提下拟合一个函数。落在该容差内的误差不计入损失。模型更关注整体拟合是否正确,而不是纠正每一个小偏差。
这正是SVR有别于大多数其他回归模型之处。
标准回归方法把每一个残差都当作信号;SVR则把大多数残差当作噪声。结果,您得到的模型不再拘泥于每个点都精确无误,而更重视把数据的底层结构抓准。
SVR 的中心概念是所谓的epsilon 管——一个围绕拟合函数两侧的容差边界。
任何落在该管道内的数据点都被视为足够接近。SVR 在拟合模型时会忽略这些点。只有管道之外的点才重要,因为它们才是真正塑造决策边界的点。
Epsilon 管示例
您可以这样理解:
这就是 SVR 与标准回归的分野。在线性回归中,每个数据点都会拉扯模型——包括那些噪声点;在 SVR 中,大多数点与训练无关。最终得到的拟合更注重整体结构是否合理。
SVR 同时要满足两个相互竞争的目标。
第一是让模型尽可能平坦。更平坦的函数更简单,而简单模型往往在新数据上泛化更好。第二是尽量减小 epsilon 管外点的误差——那些 SVR 无法忽略的点。
这两个目标相互拉扯,于是就引出了正则化参数C。它控制 SVR 对管外误差相对于模型简洁性的重视程度:
您始终在模型简洁性与误差容忍度之间权衡。合适的 C 值取决于数据以及您预期的噪声水平。两端走偏都会降低模型在新数据上的表现。
这是一个可迭代求解的优化问题,因此不必过于担心。
在 SVR 中,只有落在 epsilon 管之外的数据点才真正重要。
这些点称为支持向量——它们超出边界,进而塑造拟合函数。管内的一切在训练中都会被忽略。模型在任何有意义的层面上都“看不见”这些点。
支持向量
一个有用的副作用是稀疏性。在实践中,只有一小部分训练数据最终会成为支持向量。其余数据对最终模型没有贡献,这使得 SVR 在训练完成后内存占用较小、预测评估更快,因为预测只依赖于少数这些关键点。
SVR 并不局限于拟合直线。它可以通过一种称为核技巧的技术来处理非线性关系。
因此,SVR 不是在原始输入空间中拟合函数,而是将数据映射到更高维空间,使得在线性可分的高维空间中进行线性拟合成为可能。该高维空间中的线性拟合再映射回原空间,就对应于您原始数据中的一条非线性曲线。
最常用的两种核是:
核的选择取决于您的数据。不确定时,RBF 是一个不错的起点。
区别在于每个模型试图实现的目标不同。
线性回归会在每一个数据点上最小化总误差。每个残差都计入,无论多小。如果一个噪声点把模型拉偏,整体拟合就会随之调整以补偿。
SVR 会忽略 epsilon 管内的误差。它只对落在边界之外的点作出反应——即便如此,反应强度也由 C 控制。模型优化的是结构,而不是每个个体点的准确性。
这种差异使 SVR 对离群点更具鲁棒性。单个噪声点不会像在线性回归中那样主导拟合,因为 SVR 从一开始就没有试图追逐它。
以下是所有差异:

线性回归与 SVR 对比
在开始优化模型之前,您需要理解 SVR 的三个参数。
Epsilon 定义了拟合函数周围的容差边界宽度。更大的ε意味着更宽的管道——会忽略更多数据点,模型也更简单。更小的ε会收紧管道,迫使模型更贴合数据。
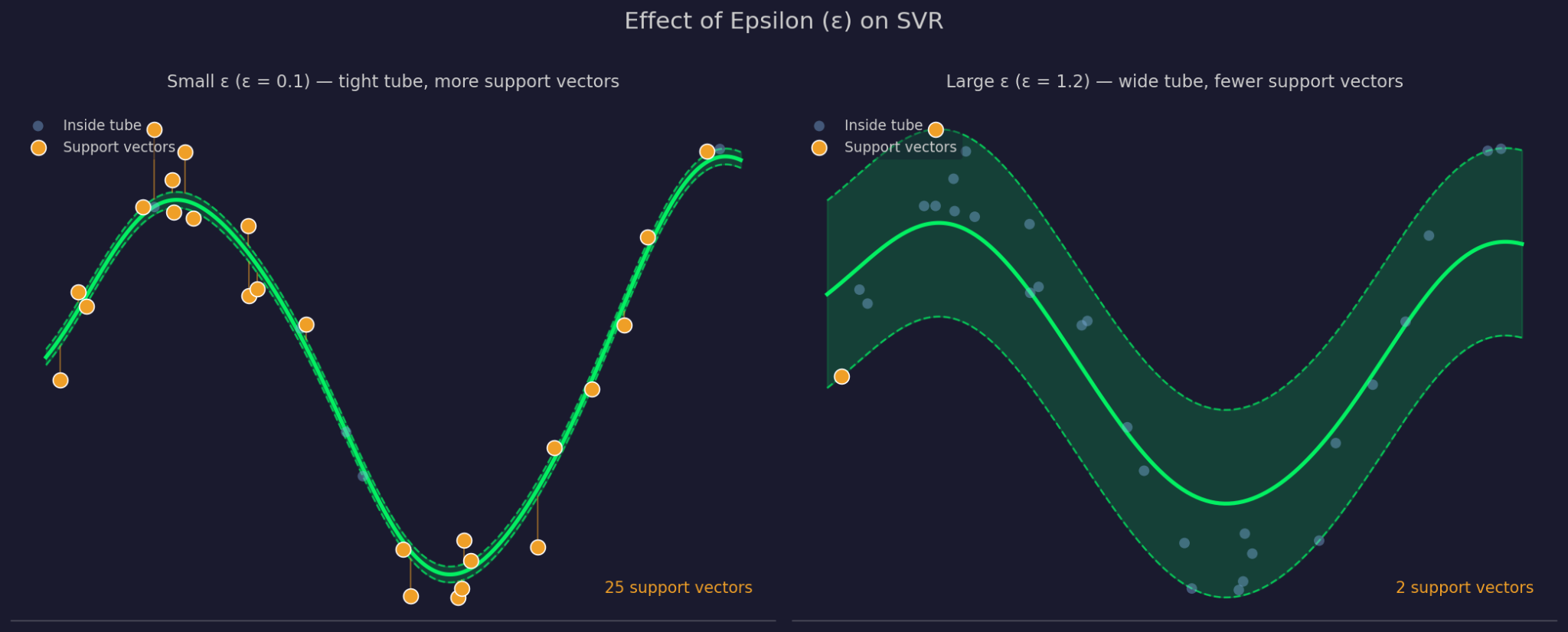
小 Epsilon 与大 Epsilon 对比
C控制 SVR 对管外点误差的惩罚力度。较高的C表示模型会更加严肃地对待这些误差并拟合得更紧。较低的C则表示模型会接受更多违反,以换取更简单、更平坦的函数。C与ε相互作用,改变其中一个都会影响另一个在实践中的表现。
小 C 与大 C 对比
核函数决定 SVR 如何处理非线性模式。RBF 是最常见的选择,作为默认通常表现良好。多项式核适用于特定曲线形状。线性核会将 SVR 简化为基于边界的线性回归,当您的数据已相对“乖巧”时会有用。
要让 SVR 表现良好,需要经过几个步骤和前提条件。让我来介绍一下。
典型工作流程如下:
对数据进行缩放:SVR 对特征尺度很敏感。如果特征处在不同量纲上,模型将不会如预期运行。拟合前请同时对X与y使用StandardScaler
选择核函数:对于大多数问题,RBF 是正确的默认选择。如果您有充分理由认为关系遵循那种形状,再切换到多项式核
调参:在拟合前设置C、epsilon和gamma。网格搜索或交叉验证是标准方法
拟合模型:在缩放后的训练数据上调用.fit()。训练完成后,将预测结果逆变换回原始尺度
以下是一个使用 scikit-learn 的完整示例:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
测试集上的 RMSE
在这段代码中有两点需要注意。首先,StandardScaler分别应用于X和y。只对特征缩放是一个常见错误,会导致 SVR 表现不佳。其次,在评估之前,对预测结果进行了逆变换,以将其带回原始尺度。
下方两张图展示了拟合模型的外观。第一张展示了训练与测试数据上的 SVR 曲线及 epsilon 管:
训练与测试数据上的 Epsilon 管
第二张比较了测试集上的预测值与真实值:
预测值与真实值
越接近对角线的点,说明模型预测得越好。
SVR 有一组特定优势,使其在合适场景下成为正确的工具。同样,它也有在其他场景下不合适的弱点。
SVR 在一组特定条件下表现最佳。以下情况建议使用 SVR:
以下情况应避免使用 SVR:
如果您的数据集既大又嘈杂,先考虑梯度提升方法。SVR 在数据干净、规模适中且结构超出简单模型拟合能力时尤为出色。
SVR 的多数问题都归结为同一组错误——把这部分当作一份“避坑清单”。
未对特征进行缩放。SVR 是基于距离的算法,这意味着未缩放的特征会主导模型。拟合前务必同时对X与y应用StandardScaler。
误解 epsilon。Epsilon 是最重要的参数。过大则模型欠拟合,因为忽略过多;过小则表现得像标准回归,追逐每个数据点。务必进行网格搜索,找出在测试集上表现最佳的取值。
跳过参数调优。像大多数机器学习模型一样,仅用默认参数运行 SVR 很难得到好结果。C、epsilon 与 gamma 需要联合调优。使用带交叉验证的网格搜索。
在超大数据集上使用 SVR。如果样本超过几千个,SVR 会很慢。它的扩展性确实不如其他算法。请改用更适合大数据集的模型,如梯度提升或神经网络。
同样需要注意的是,把上述四点都做好并不保证模型优秀,但其中任何一点做错几乎都能保证结果不佳。
总之,请记住 SVR 解决的问题与标准回归不同。它不是最小化每一个误差,而是在一个边界内拟合函数,并忽略落在边界内的噪声——这正是当数据不干净或并非完美线性时它的用武之地。
它并不以速度或简洁著称,但胜在稳健。如果您的数据存在非线性关系且有不想去拟合的离群点,SVR 能让您关注结构本身,而不是追逐每一个数据点。
只需记住对特征进行缩放、调好参数、选对核函数,并在数据量上保持克制。若这些做到位,SVR 会给您一个在生产中不易“翻车”的稳健模型。
SVR 只是每位数据科学家都应掌握的工具之一。报名我们的Machine Learning Engineer 课程路径,学习其他方法,并在 2026 年为求职做好准备。
与 DataCamp 一起学习
Tracks
Courses
Courses