
Programma
Apprendimento automatico supervisionato in Python
25 h
I metodi di regressione standard minimizzano l’errore totale su tutti i punti dati. Ciò significa che ogni residuo, per quanto piccolo, tira il modello in una direzione. Di conseguenza, ti ritrovi con un modello sensibile al rumore e agli outlier.
Un modello di support vector regression, invece, adatta una funzione all’interno di un margine di tolleranza e ignora gli errori che vi ricadono. Quel margine cambia l’idea di ottimizzazione. Invece di cercare di ottimizzare ogni singolo punto dati, SVR si concentra sulla struttura complessiva dei dati, il che lo rende, come spero di mostrarti, robusto sui dati del mondo reale.
Se ti serve un ripasso prima di iniziare, leggi il nostro articolo Linear Regression in Python per un’introduzione al predictive modeling.
La Support Vector Regression è un metodo di regressione costruito sulle stesse basi delle Support Vector Machines (SVM), una classe di modelli originariamente pensata per compiti di classificazione come il rilevamento dello spam o il riconoscimento di immagini.
L’idea chiave è semplice da capire: invece di cercare di minimizzare ogni errore di previsione, SVR adatta una funzione consentendo un margine di tolleranza attorno ad essa. Gli errori che rientrano in quel margine non contano. Il modello punta a centrare l’andamento complessivo, non a correggere ogni piccola deviazione.
È questo che distingue SVR dalla maggior parte degli altri modelli di regressione.
I metodi di regressione standard trattano ogni residuo come un segnale. SVR considera la maggior parte come rumore. Il risultato è un modello meno preoccupato di essere esatto su ogni punto e più interessato a cogliere la struttura sottostante dei dati.
Al centro di SVR c’è qualcosa chiamato epsilon tube: un margine di tolleranza che avvolge la funzione adattata su entrambi i lati.
Qualsiasi punto dati che cade all’interno del tubo è considerato sufficientemente vicino. SVR ignora questi punti durante l’adattamento del modello. Contano solo i punti fuori dal tubo, perché sono quelli che effettivamente plasmano il confine decisionale.
Esempio di Epsilon tube
Ecco come interpretarlo:
Questo è ciò che separa SVR dalla regressione standard. Nella regressione lineare, ogni punto dati tira il modello, compresi quelli rumorosi. In SVR, la maggior parte dei punti è irrilevante. Il risultato è un adattamento guidato da una buona struttura complessiva.
SVR ha due obiettivi in competizione che cerca di soddisfare contemporaneamente.
Il primo è mantenere il modello il più piatto possibile. Una funzione più piatta è più semplice e i modelli semplici tendono a generalizzare meglio su nuovi dati. Il secondo è minimizzare gli errori sui punti fuori dall’epsilon tube, quelli che SVR non può ignorare.
Questi due obiettivi tirano in direzioni opposte, ed è qui che entra in gioco il parametro di regolarizzazione C. Controlla quanto peso SVR attribuisce agli errori fuori dal tubo rispetto alla semplicità del modello:
Stai sempre bilanciando la semplicità del modello con la tolleranza all’errore. Il valore giusto di C dipende dai tuoi dati e da quanto rumore ti aspetti. Sbagliare in un senso o nell’altro ridurrà le prestazioni del modello su nuovi dati.
È un problema di ottimizzazione risolvibile in modo iterativo, quindi non c’è nulla di cui preoccuparsi.
Con SVR, contano solo i punti dati che cadono fuori dall’epsilon tube.
Questi sono i support vector: i punti che stanno oltre il margine e plasmano la funzione adattata. Tutto ciò che è dentro il tubo viene ignorato durante l’addestramento. Il modello non “vede” mai davvero quei punti in modo significativo.
Support vector
L’effetto collaterale utile è la sparsezza. In pratica, solo un sottoinsieme ridotto dei dati di training finisce per essere support vector. Il resto non contribuisce al modello finale, il che rende SVR efficiente in memoria e veloce da valutare una volta addestrato, poiché le previsioni dipendono solo da quei pochi punti influenti.
SVR non è limitato ad adattare linee rette. Può gestire relazioni non lineari tramite una tecnica chiamata kernel trick.
Quindi, invece di adattare una funzione nello spazio di input originale, SVR mappa i dati in uno spazio a dimensionalità superiore dove un adattamento lineare diventa possibile. Quell’adattamento lineare nello spazio a dimensionalità superiore si traduce in una curva non lineare nei dati originali.
I due kernel più comuni che userai sono:
La scelta del kernel dipende dai tuoi dati. RBF è un buon punto di partenza quando non sei sicuro.
La differenza si riduce a cosa cerca di fare ciascun modello.
La regressione lineare minimizza l’errore totale su ogni punto dati. Ogni residuo conta, per quanto piccolo. Se un punto rumoroso tira il modello fuori rotta, l’intero adattamento si sposta per compensare.
SVR ignora gli errori all’interno dell’epsilon tube. Reagisce solo ai punti che cadono fuori dal margine e, anche in quel caso, C controlla quanto fortemente. Il modello ottimizza per la struttura, non per l’accuratezza su ogni singolo punto.
Questa differenza rende SVR più robusto agli outlier. Un singolo punto rumoroso non rovinerà l’adattamento come può accadere nella regressione lineare, perché SVR non stava cercando di inseguirlo fin dall’inizio.
Ecco tutte le differenze:

Regressione lineare a confronto con SVR
SVR ha tre parametri che devi comprendere prima di iniziare a ottimizzare il modello.
Epsilon definisce la larghezza del margine di tolleranza attorno alla funzione adattata. Un ε più grande significa un tubo più ampio: più punti vengono ignorati e il modello diventa più semplice. Un ε più piccolo restringe il tubo e costringe il modello ad aderire maggiormente ai dati.
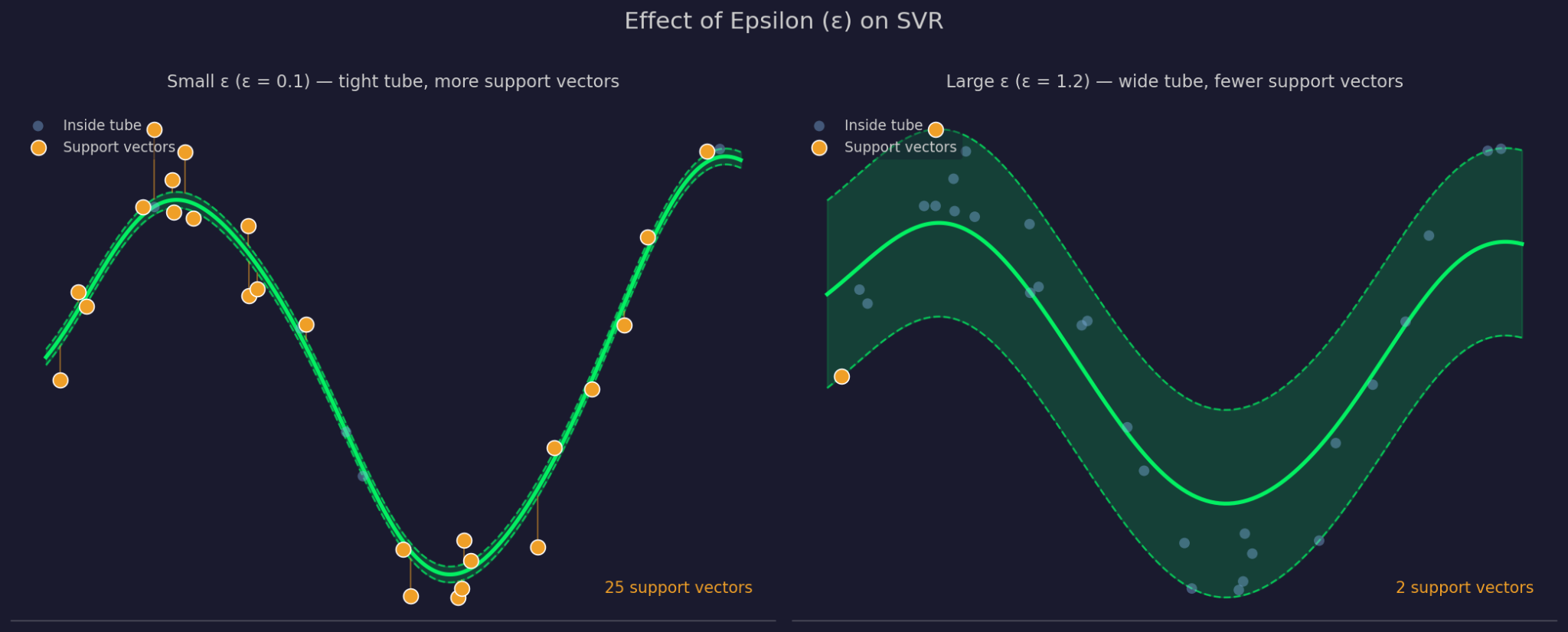
Epsilon piccolo contro grande
C controlla quanto severamente SVR penalizza gli errori sui punti fuori dal tubo. Un C alto significa che il modello prende molto sul serio quegli errori e si adatta più strettamente. Un C basso significa che il modello accetta più violazioni in cambio di una funzione più semplice e piatta. C ed ε lavorano insieme, perché modificare uno influisce sul comportamento dell’altro nella pratica.
C piccolo contro grande
Il kernel determina come SVR gestisce i pattern non lineari. RBF è la scelta più comune e funziona bene come predefinita. I kernel polinomiali sono utili per forme di curva specifiche. I kernel lineari riducono SVR a una regressione lineare basata su margini, utile quando i tuoi dati sono già ben comportati.
Far funzionare bene SVR richiede di seguire alcuni passaggi e prerequisiti. Ti mostro quali sono.
Ecco il flusso di lavoro tipico:
Scala i dati: SVR è sensibile alla scala delle feature. Se le feature sono su scale diverse, il modello non si comporterà come previsto. Usa StandardScaler sia su X che su y prima dell’adattamento
Scegli un kernel: RBF è la scelta giusta per la maggior parte dei problemi. Passa a un polinomiale se hai un motivo specifico per credere che la relazione segua quella forma
Ottimizza i parametri: imposta C, epsilon e gamma prima del fitting. Grid search o cross-validation sono gli approcci standard
Adatta il modello: chiama .fit() sui dati di training scalati. Una volta addestrato, applica l’inverse transform alle previsioni per riportarle alla scala originale
Ecco un esempio completo con scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE sul set di test
Un paio di cose da notare in questo codice. Per prima cosa, StandardScaler è applicato separatamente sia a X che a y. Scalare solo le feature è un errore comune che porta a scarsi risultati con SVR. In secondo luogo, le previsioni vengono riportate alla scala originale alla fine tramite inverse transform prima della valutazione.
I due grafici seguenti mostrano come appare il modello adattato. Il primo mostra la curva SVR con l’epsilon tube sui dati di training e di test:
Epsilon tube sui dati di training e test
Il secondo confronta valori previsti e reali sul set di test:
Valori previsti contro reali
Punti vicini alla diagonale indicano che il modello sta prevedendo bene.
SVR ha un insieme specifico di punti di forza che lo rendono lo strumento giusto nella situazione giusta. Allo stesso modo, ha debolezze che lo rendono quello sbagliato in altre.
SVR funziona al meglio in un insieme specifico di condizioni. Dovresti usare SVR quando:
Dovresti evitare SVR quando:
Se il tuo dataset è grande e rumoroso, i metodi di gradient boosting meritano di essere valutati prima. SVR è ottimo quando hai dati puliti, di dimensioni moderate, con una struttura che i modelli più semplici non riescono a catturare bene.
La maggior parte dei problemi con SVR deriva dallo stesso insieme di errori: consideralo un promemoria di cosa non fare.
Non scalare le feature. SVR è un algoritmo basato sulle distanze, quindi le feature non scalate domineranno il modello. Applica sempre StandardScaler sia a X che a y prima del fitting.
Fraintendere l’epsilon. Epsilon è di gran lunga il parametro più importante. Troppo grande e il modello underfitta perché ignora troppo. Troppo piccolo e si comporta come la regressione standard, inseguendo ogni punto. Fai sempre una grid search per capire cosa funziona meglio sul tuo set di test.
Saltare l’ottimizzazione dei parametri. Eseguire SVR con i parametri di default e aspettarsi buoni risultati funziona raramente, come per la maggior parte dei modelli di machine learning. C, epsilon e gamma vanno ottimizzati insieme. Usa grid search con cross-validation.
Usare SVR su dataset molto grandi. Se hai più di qualche migliaio di campioni, SVR sarà lento. Semplicemente non scala come altri algoritmi. Passa a un modello che gestisce meglio grandi dataset, come gradient boosting o una rete neurale.
È anche importante notare che fare bene queste quattro cose non garantisce un ottimo modello, ma sbagliarne anche solo una garantisce quasi certamente un risultato scadente.
In conclusione, ricorda che SVR risolve un problema diverso rispetto alla regressione standard. Invece di minimizzare ogni errore, adatta una funzione entro un margine e ignora il rumore che vi rientra, ed è proprio questo che lo rende utile quando i tuoi dati non sono puliti o perfettamente lineari.
Non è noto per velocità o semplicità. Ma è robusto. Se i tuoi dati hanno relazioni non lineari e outlier che non vuoi modellare, SVR ti permette di concentrarti sulla struttura invece di inseguire ogni punto dati.
Ricorda solo di scalare le feature, ottimizzare i parametri, scegliere il kernel giusto e restare prudente con la quantità di dati. Se fai bene queste cose, SVR ti darà un modello robusto, poco incline a fallire in produzione.
SVR è solo uno degli strumenti che ogni data scientist deve conoscere. Iscriviti al nostro percorso Machine Learning Engineer per imparare gli altri e prepararti al lavoro nel 2026.
Impara con DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

