
Tracks
Học máy có giám sát trong Python
25 giờ
Các phương pháp hồi quy tiêu chuẩn tối thiểu hóa tổng sai số trên mọi điểm dữ liệu. Điều đó có nghĩa là mọi phần dư, dù nhỏ đến đâu, cũng kéo mô hình theo một hướng nào đó. Kết quả là bạn có một mô hình nhạy với nhiễu và ngoại lệ.
Ngược lại, mô hình hồi quy vectơ hỗ trợ phù hợp một hàm trong phạm vi dung sai và bỏ qua các lỗi nằm bên trong phạm vi đó. Khoảng này thay đổi quan niệm về tối ưu hóa. Thay vì cố gắng tối ưu từng điểm dữ liệu, SVR tập trung vào cấu trúc tổng thể của dữ liệu, nhờ vậy, như tôi hy vọng sẽ cho bạn thấy, nó vững vàng trên dữ liệu thực tế.
Nếu bạn cần kiến thức nhập môn trước khi bắt đầu, hãy đọc bài Hồi quy tuyến tính trong Python của chúng tôi để có phần giới thiệu về mô hình dự đoán.
Hồi quy Vectơ Hỗ trợ là một phương pháp hồi quy xây dựng trên cùng nền tảng với Máy Vectơ Hỗ trợ (SVM), một họ mô hình ban đầu được thiết kế cho các tác vụ phân loại như phát hiện thư rác hoặc nhận dạng hình ảnh.
Ý tưởng then chốt rất dễ hiểu - thay vì cố gắng tối thiểu hóa mọi sai số dự đoán, SVR khớp một hàm đồng thời cho phép một biên dung sai xung quanh nó. Các lỗi nằm trong biên đó không được tính. Mô hình tập trung vào việc có độ khớp tổng thể đúng, không phải sửa mọi sai lệch nhỏ.
Đó là điểm khác biệt của SVR so với hầu hết các mô hình hồi quy khác.
Các phương pháp hồi quy tiêu chuẩn xem mọi phần dư là tín hiệu. SVR xem phần lớn chúng là nhiễu. Kết quả là bạn có một mô hình ít bận tâm đến việc chính xác tại từng điểm và quan tâm nhiều hơn đến việc nắm đúng cấu trúc nền tảng của dữ liệu.
Trung tâm của SVR là cái gọi là ống epsilon - một biên dung sai bao quanh hàm đã khớp ở cả hai phía.
Bất kỳ điểm dữ liệu nào nằm trong ống đều được xem là đủ gần. SVR bỏ qua các điểm này khi huấn luyện mô hình. Chỉ những điểm nằm ngoài ống mới quan trọng, vì chúng thực sự định hình biên quyết định.
Ví dụ về ống Epsilon
Bạn có thể diễn giải như sau:
Đây là điều khiến SVR khác với hồi quy tiêu chuẩn. Ở hồi quy tuyến tính, mọi điểm dữ liệu đều kéo mô hình - kể cả những điểm nhiễu. Với SVR, hầu hết các điểm là không liên quan. Kết quả là một độ khớp được tạo bởi cấu trúc tổng thể tốt.
SVR có hai mục tiêu cạnh tranh cần thỏa mãn đồng thời.
Thứ nhất là giữ cho mô hình càng phẳng càng tốt. Một hàm phẳng hơn thì đơn giản hơn, và các mô hình đơn giản có xu hướng khái quát hóa tốt hơn cho dữ liệu mới. Thứ hai là giảm thiểu lỗi trên các điểm ngoài ống epsilon - những điểm mà SVR không thể bỏ qua.
Hai mục tiêu này kéo theo hai hướng ngược nhau, và đó là lúc tham số điều chuẩn C phát huy tác dụng. Nó kiểm soát mức độ SVR coi trọng các lỗi ngoài ống so với độ đơn giản của mô hình:
Bạn luôn đánh đổi giữa độ đơn giản của mô hình và khả năng chấp nhận sai số. Giá trị C phù hợp phụ thuộc vào dữ liệu và mức độ nhiễu bạn kỳ vọng. Chọn sai theo bất kỳ hướng nào sẽ làm giảm hiệu suất của mô hình trên dữ liệu mới.
Đây là một bài toán tối ưu có thể giải lặp, nên không có gì phải lo lắng.
Với SVR, chỉ các điểm dữ liệu nằm ngoài ống epsilon mới thực sự quan trọng.
Đó là các vectơ hỗ trợ - các điểm dữ liệu vượt ngoài biên và định hình hàm đã khớp. Mọi thứ trong ống đều bị bỏ qua trong quá trình huấn luyện. Mô hình không bao giờ “nhìn thấy” các điểm đó theo cách có ý nghĩa.
Các vectơ hỗ trợ
Tác dụng phụ hữu ích của điều này là tính thưa. Trên thực tế, chỉ một tập con nhỏ dữ liệu huấn luyện của bạn trở thành vectơ hỗ trợ. Phần còn lại không đóng góp gì cho mô hình cuối cùng, giúp SVR tiết kiệm bộ nhớ và đánh giá nhanh sau khi huấn luyện, vì dự đoán chỉ phụ thuộc vào vài điểm có ảnh hưởng đó.
SVR không bị giới hạn ở việc khớp các đường thẳng. Nó có thể xử lý quan hệ phi tuyến thông qua kỹ thuật gọi là mẹo kernel.
Vì vậy, thay vì khớp một hàm trong không gian đầu vào gốc, SVR ánh xạ dữ liệu vào một không gian chiều cao hơn, nơi một độ khớp tuyến tính trở nên khả thi. Độ khớp tuyến tính trong không gian chiều cao hơn đó sẽ chuyển thành một đường cong phi tuyến trong dữ liệu gốc của bạn.
Hai kernel phổ biến nhất bạn sẽ dùng là:
Cách chọn kernel phụ thuộc vào dữ liệu của bạn. RBF là điểm khởi đầu tốt khi bạn chưa chắc chắn.
Khác biệt cốt lõi nằm ở mục tiêu mà mỗi mô hình theo đuổi.
Hồi quy tuyến tính tối thiểu hóa tổng sai số trên mọi điểm dữ liệu. Mọi phần dư đều được tính, dù nhỏ đến đâu. Nếu bạn kéo mô hình chệch hướng bởi một điểm nhiễu, toàn bộ độ khớp sẽ dịch chuyển để bù trừ.
SVR bỏ qua lỗi trong ống epsilon. Nó chỉ phản ứng với các điểm nằm ngoài biên - và ngay cả khi đó, C cũng kiểm soát mức độ phản ứng. Mô hình tối ưu cho cấu trúc, không phải cho độ chính xác tại từng điểm riêng lẻ.
Sự khác biệt đó khiến SVR bền vững hơn với ngoại lệ. Một điểm nhiễu đơn lẻ sẽ không làm hỏng độ khớp như trong hồi quy tuyến tính, vì SVR vốn dĩ không cố đuổi theo nó ngay từ đầu.
Dưới đây là tất cả khác biệt:

Hồi quy tuyến tính so với SVR
SVR có ba tham số bạn cần hiểu trước khi bắt đầu tối ưu mô hình.
Epsilon xác định bề rộng của biên dung sai quanh hàm đã khớp. ε lớn hơn đồng nghĩa ống rộng hơn - nhiều điểm bị bỏ qua hơn và mô hình trở nên đơn giản hơn. ε nhỏ hơn sẽ siết chặt ống và buộc mô hình khớp sát dữ liệu hơn.
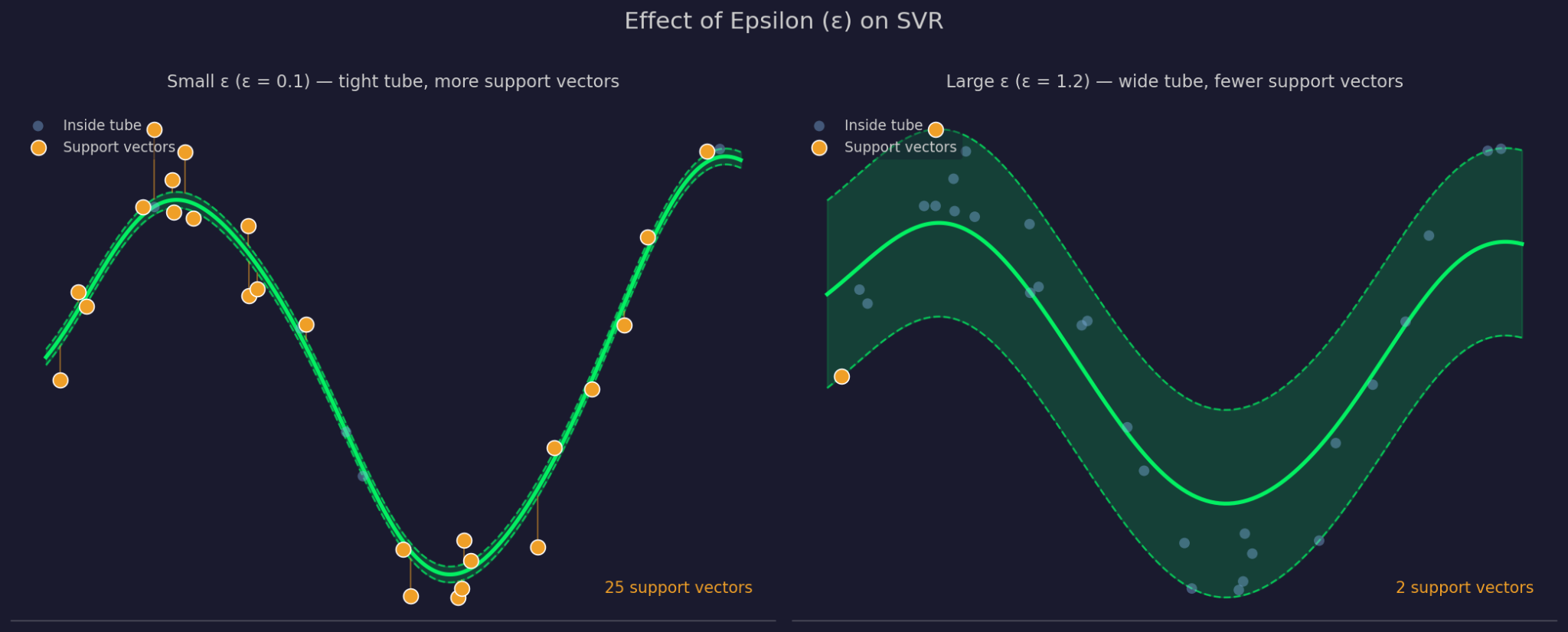
Epsilon nhỏ so với lớn
C kiểm soát mức phạt SVR áp cho các lỗi tại các điểm ngoài ống. C cao nghĩa là mô hình coi trọng các lỗi đó và khớp chặt hơn. C thấp nghĩa là mô hình chấp nhận nhiều vi phạm hơn để đổi lấy một hàm đơn giản, phẳng hơn. C và ε phối hợp với nhau, vì thay đổi một bên sẽ ảnh hưởng cách bên kia ứng xử trên thực tế.
C nhỏ so với lớn
Kernel quyết định cách SVR xử lý các mẫu phi tuyến. RBF là lựa chọn phổ biến nhất và hoạt động tốt như mặc định. Kernel đa thức hữu ích cho các dạng đường cong cụ thể. Kernel tuyến tính biến SVR thành một hồi quy tuyến tính dựa trên biên, hữu ích khi dữ liệu của bạn vốn đã “ngoan”.
Khiến SVR hoạt động tốt là đi qua một vài bước và điều kiện tiên quyết. Để tôi chỉ cho bạn chúng là gì.
Quy trình điển hình như sau:
Chuẩn hóa dữ liệu của bạn: SVR nhạy với thang đo đặc trưng. Nếu các đặc trưng có thang đo khác nhau, mô hình sẽ không hoạt động như mong đợi. Hãy dùng StandardScaler cho cả X và y trước khi khớp
Chọn kernel: RBF là mặc định phù hợp cho hầu hết bài toán. Chuyển sang đa thức nếu bạn có lý do cụ thể tin rằng quan hệ tuân theo dạng đó
Tinh chỉnh tham số: Thiết lập C, epsilon và gamma trước khi khớp. Grid search hoặc cross-validation là các cách tiếp cận tiêu chuẩn
Huấn luyện mô hình: Gọi .fit() trên dữ liệu huấn luyện đã chuẩn hóa. Sau khi huấn luyện, đảo chuẩn hóa dự đoán về thang đo gốc
Dưới đây là ví dụ hoàn chỉnh dùng scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE trên tập kiểm tra
Một vài điều đáng chú ý trong đoạn mã này. Thứ nhất, StandardScaler được áp dụng riêng cho cả X và y. Chỉ chuẩn hóa đặc trưng là lỗi thường gặp dẫn đến kết quả kém với SVR. Thứ hai, dự đoán được đảo chuẩn hóa ở cuối để đưa chúng về thang đo gốc trước khi đánh giá.
Hai biểu đồ dưới đây cho thấy mô hình đã khớp trông như thế nào. Biểu đồ đầu tiên hiển thị đường cong SVR với ống epsilon trên dữ liệu huấn luyện và kiểm tra:
Ống Epsilon trên dữ liệu huấn luyện và kiểm tra
Biểu đồ thứ hai so sánh giá trị dự đoán với giá trị thực trên tập kiểm tra:
Giá trị dự đoán so với thực tế
Các điểm gần đường chéo nghĩa là mô hình dự đoán tốt.
SVR có một tập thế mạnh cụ thể khiến nó phù hợp trong đúng bối cảnh. Tương tự, nó có điểm yếu khiến nó không phù hợp trong những trường hợp khác.
SVR phát huy tốt nhất trong một tập điều kiện cụ thể. Bạn nên dùng SVR khi:
Bạn nên tránh SVR khi:
Nếu tập dữ liệu của bạn lớn và nhiễu, các phương pháp gradient boosting đáng để xem trước. SVR rất hữu ích khi bạn có dữ liệu sạch, kích thước vừa, với cấu trúc mà các mô hình đơn giản hơn không khớp tốt.
Hầu hết vấn đề với SVR đều quy về cùng một nhóm lỗi - hãy coi đây là bảng “đừng làm gì”.
Không chuẩn hóa đặc trưng. SVR là thuật toán dựa trên khoảng cách, nghĩa là các đặc trưng chưa chuẩn hóa sẽ lấn át mô hình. Luôn áp dụng StandardScaler cho cả X và y trước khi khớp.
Hiểu sai về epsilon. Epsilon là tham số quan trọng nhất. Quá lớn và mô hình underfit vì bỏ qua quá nhiều. Quá nhỏ và nó hành xử như hồi quy tiêu chuẩn, đuổi theo từng điểm dữ liệu. Luôn thực hiện grid search để xem giá trị nào hiệu quả nhất trên tập kiểm tra của bạn.
Bỏ qua tinh chỉnh tham số. Chạy SVR với tham số mặc định và kỳ vọng kết quả tốt hiếm khi hiệu quả - như đa số mô hình học máy khác. C, epsilon và gamma cần được tinh chỉnh cùng nhau. Hãy dùng grid search với cross-validation.
Dùng SVR trên tập dữ liệu rất lớn. Nếu bạn có hơn vài nghìn mẫu, SVR sẽ chậm. Nó đơn giản là không mở rộng như các thuật toán khác. Hãy chuyển sang mô hình phù hợp với tập dữ liệu lớn hơn, như gradient boosting hoặc mạng nơ-ron.
Cũng cần lưu ý rằng làm đúng bốn điều này không đảm bảo một mô hình tuyệt vời, nhưng làm sai bất kỳ điều nào gần như chắc chắn sẽ cho kết quả tệ.
Tóm lại, hãy nhớ rằng SVR giải quyết một bài toán khác so với hồi quy tiêu chuẩn. Thay vì tối thiểu hóa mọi sai số, nó khớp một hàm trong một biên và bỏ qua nhiễu nằm trong đó - chính điều này khiến nó hữu ích khi dữ liệu của bạn không sạch hoặc không hoàn toàn tuyến tính.
Nó không nổi tiếng về tốc độ hay sự đơn giản. Nhưng nó vững vàng. Nếu dữ liệu của bạn có quan hệ phi tuyến và ngoại lệ mà bạn không muốn mô hình hóa, SVR sẽ cho bạn cách tập trung vào cấu trúc thay vì đuổi theo từng điểm dữ liệu.
Chỉ cần nhớ chuẩn hóa đặc trưng, tinh chỉnh tham số, chọn đúng kernel và giữ quy mô dữ liệu ở mức vừa phải. Nếu làm đúng, SVR sẽ mang lại một mô hình vững vàng, ít có khả năng thất bại khi đưa vào sản xuất.
SVR chỉ là một trong những công cụ mà mọi nhà khoa học dữ liệu cần biết. Hãy ghi danh vào lộ trình Kỹ sư Máy học của chúng tôi để học các công cụ khác và sẵn sàng cho công việc vào năm 2026.
Học cùng DataCamp
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút