
Lernpfad
Überwachtes Machine Learning in Python
25 Std.
Klassische Regressionsmethoden minimieren den Gesamtsatz an Fehlern über alle Datenpunkte. Das bedeutet: Jeder Residualfehler, egal wie klein, zieht das Modell in eine Richtung. Das Ergebnis ist ein Modell, das empfindlich auf Rauschen und Ausreißer reagiert.
Ein Support-Vector-Regression-Modell hingegen passt eine Funktion innerhalb eines Toleranzbereichs an und ignoriert Fehler, die darin liegen. Dieser Rand verändert das Optimierungsziel. Statt jeden einzelnen Punkt zu optimieren, konzentriert sich SVR auf die Gesamtstruktur der Daten – und ist dadurch, wie ich dir zeigen werde, robust bei echten, verrauschten Datensätzen.
Wenn du vorab eine Auffrischung brauchst, lies unseren Artikel Linear Regression in Python als Einführung ins Predictive Modeling.
Support Vector Regression basiert auf derselben Grundlage wie Support Vector Machines (SVM) – einer Modellfamilie, die ursprünglich für Klassifikationsaufgaben wie Spam-Erkennung oder Bilderkennung entwickelt wurde.
Die Kernidee ist leicht zu verstehen: Statt jeden Vorhersagefehler zu minimieren, passt SVR eine Funktion an und erlaubt dabei einen Toleranzrand. Fehler innerhalb dieses Rands zählen nicht. Das Modell achtet darauf, die Gesamttendenz richtig zu erfassen, anstatt jede kleine Abweichung zu korrigieren.
Genau das unterscheidet SVR von den meisten anderen Regressionsmodellen.
Standardregression wertet jeden Residualfehler als Signal. SVR behandelt die meisten davon als Rauschen. Das Ergebnis ist ein Modell, dem es weniger darum geht, an jedem Punkt exakt richtig zu liegen, sondern die zugrunde liegende Struktur der Daten korrekt zu treffen.
Im Zentrum von SVR steht das sogenannte Epsilon-Rohr – ein Toleranzbereich, der die angepasste Funktion auf beiden Seiten umhüllt.
Jeder Datenpunkt innerhalb des Rohrs gilt als „nah genug“. SVR ignoriert diese Punkte beim Fitten. Nur Punkte außerhalb des Rohrs zählen, denn sie bestimmen die Entscheidungsgrenze.
Beispiel für das Epsilon-Rohr
So lässt sich das interpretieren:
Das ist der Hauptunterschied zu Standardregression. In der linearen Regression zieht jeder Datenpunkt am Modell – auch die verrauschten. Bei SVR sind die meisten Punkte irrelevant. Das Ergebnis ist ein Fit, der von guter Gesamtstruktur geprägt ist.
SVR verfolgt zwei konkurrierende Ziele gleichzeitig.
Erstens soll das Modell so flach wie möglich bleiben. Eine flachere Funktion ist einfacher und generalisiert besser auf neue Daten. Zweitens sollen die Fehler bei Punkten außerhalb des Epsilon-Rohrs minimiert werden – jene, die SVR nicht ignorieren kann.
Diese Ziele ziehen in entgegengesetzte Richtungen – hier kommt der Regularisierungsparameter C ins Spiel. Er steuert, wie stark SVR Fehler außerhalb des Rohrs im Verhältnis zur Modellschlichtheit gewichtet:
Du balancierst also stets Modellschlichtheit gegen Fehlertoleranz. Der richtige C-Wert hängt von deinen Daten und dem erwarteten Rauschen ab. In beide Richtungen falsch gewählt, verschlechtert er die Generalisierung auf neue Daten.
Das ist ein Optimierungsproblem, das sich iterativ lösen lässt – also kein Grund zur Sorge.
Bei SVR zählen nur die Datenpunkte, die außerhalb des Epsilon-Rohrs liegen.
Das sind die Support-Vektoren – jene Punkte, die den Rand überschreiten und die angepasste Funktion formen. Alles innerhalb des Rohrs wird beim Training ignoriert. Das Modell „sieht“ diese Punkte nicht wirklich.
Support-Vektoren
Der nützliche Nebeneffekt ist Sparsamkeit. In der Praxis wird nur ein kleiner Teil der Trainingsdaten zu Support-Vektoren. Der Rest trägt nichts zum endgültigen Modell bei. Dadurch ist SVR speichereffizient und nach dem Training schnell in der Auswertung, weil Vorhersagen nur von wenigen einflussreichen Punkten abhängen.
SVR ist nicht auf Gerade beschränkt. Nichtlineare Zusammenhänge lassen sich über die sogenannte Kernel-Trick-Technik handhaben.
Statt die Funktion im ursprünglichen Merkmalsraum zu fitten, projiziert SVR die Daten in einen höherdimensionalen Raum, in dem ein linearer Fit möglich wird. Dieser lineare Fit im höherdimensionalen Raum entspricht im Originalraum einer nichtlinearen Kurve.
Die zwei gebräuchlichsten Kernel sind:
Die Kernel-Wahl hängt von deinen Daten ab. RBF ist eine gute erste Wahl, wenn du unsicher bist.
Der Unterschied liegt im Ziel, das jedes Modell verfolgt.
Lineare Regression minimiert die Gesamtfehler über alle Punkte. Jeder Residualfehler zählt, egal wie klein. Zieht ein verrauschter Punkt das Modell aus der Bahn, verschiebt sich der gesamte Fit, um zu kompensieren.
SVR ignoriert Fehler innerhalb des Epsilon-Rohrs. Es reagiert nur auf Punkte außerhalb des Rands – und selbst dann steuert C, wie stark. Das Modell optimiert auf Struktur, nicht auf Genauigkeit bei jedem einzelnen Punkt.
Dieser Unterschied macht SVR robuster gegenüber Ausreißern. Ein einzelner verrauschter Punkt verdirbt den Fit nicht so leicht wie bei linearer Regression, weil SVR ihm gar nicht erst hinterherläuft.
Hier sind alle Unterschiede auf einen Blick:

Lineare Regression im Vergleich zu SVR
SVR hat drei Parameter, die du verstehen solltest, bevor du optimierst.
Epsilon definiert die Breite des Toleranzbereichs um die angepasste Funktion. Ein größeres ε bedeutet ein breiteres Rohr – mehr Punkte werden ignoriert und das Modell wird einfacher. Ein kleineres ε verengt das Rohr und zwingt das Modell zu engerem Fit.
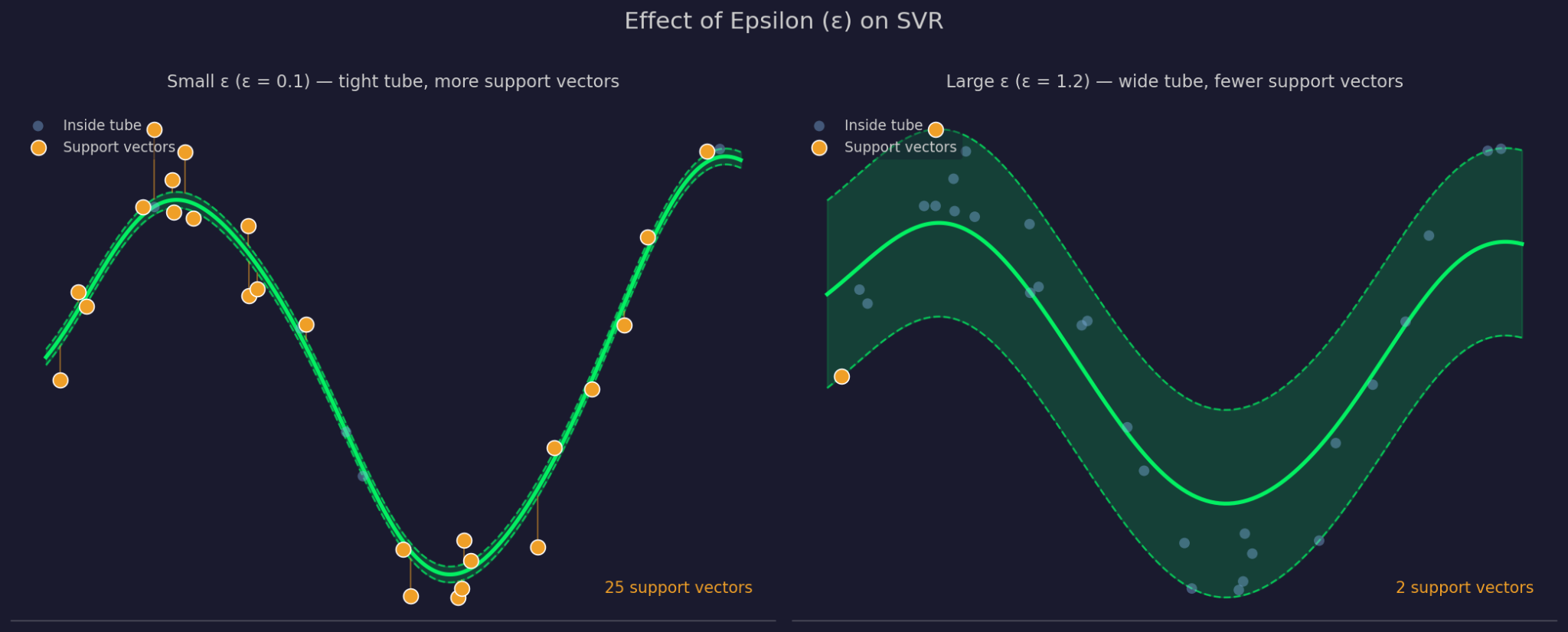
Kleines vs. großes Epsilon
C steuert, wie stark SVR Fehler bei Punkten außerhalb des Rohrs bestraft. Hohes C bedeutet, dass das Modell diese Fehler ernst nimmt und enger fitten will. Niedriges C akzeptiert mehr Verletzungen zugunsten einer einfacheren, flacheren Funktion. C und ε wirken zusammen – die Änderung des einen beeinflusst das Verhalten des anderen.
Kleines vs. großes C
Der Kernel bestimmt, wie SVR nichtlineare Muster abbildet. RBF ist die gängigste Wahl und ein guter Standard. Polynomiell ist hilfreich für bestimmte Kurvenformen. Ein linearer Kernel reduziert SVR auf eine randbasierte lineare Regression – sinnvoll, wenn deine Daten bereits „gutartig“ sind.
Damit SVR gut funktioniert, gehst du ein paar Schritte und Voraussetzungen durch. Hier ist, worauf es ankommt.
Der typische Workflow:
Skaliere deine Daten: SVR ist empfindlich für Merkmalsmaßstäbe. Liegen Features auf unterschiedlichen Skalen, verhält sich das Modell unerwartet. Verwende StandardScaler für X und y vor dem Fitten
Wähle einen Kernel: RBF ist für die meisten Probleme die richtige Voreinstellung. Wechsle zu Polynom, wenn du gute Gründe für diese Kurvenform hast
Tuning der Parameter: Setze C, epsilon und gamma vor dem Fitten. Grid Search oder Cross-Validation sind hier Standard
Modell fitten: Rufe .fit() auf den skalierten Trainingsdaten auf. Nach dem Training die Vorhersagen per Inverse-Transformation auf die Originalskala zurückführen
Hier ein komplettes Beispiel mit scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE auf dem Testset
Ein paar Dinge fallen im Code auf. Erstens wird StandardScaler getrennt auf X und y angewendet. Nur die Features zu skalieren ist ein häufiger Fehler, der mit SVR zu schlechten Ergebnissen führt. Zweitens werden die Vorhersagen am Ende invers transformiert, um sie vor der Evaluation auf die Originalskala zurückzubringen.
Die beiden folgenden Plots zeigen den Fit. Der erste zeigt die SVR-Kurve samt Epsilon-Rohr über Trainings- und Testdaten:
Epsilon-Rohr über Trainings- und Testdaten
Der zweite vergleicht vorhergesagte mit tatsächlichen Werten im Testset:
Vorhergesagt vs. tatsächlich
Punkte nahe der Diagonalen bedeuten, dass das Modell gut vorhersagt.
SVR hat spezifische Stärken, die es in den richtigen Situationen zur besten Wahl machen – und Schwächen, die es in anderen unpassend machen.
SVR spielt seine Stärken unter bestimmten Bedingungen aus. Du solltest SVR einsetzen, wenn:
Du solltest SVR meiden, wenn:
Wenn dein Datensatz groß und verrauscht ist, sind Methoden wie Gradient Boosting oft die bessere erste Wahl. SVR ist top, wenn du saubere, mittelgroße Daten mit Strukturen hast, die einfachere Modelle nicht gut treffen.
Die meisten Probleme mit SVR lassen sich auf denselben Fehlerkatalog zurückführen – hier deine Spickliste, was du vermeiden solltest.
Keine Skalierung der Features. SVR ist abstands-basiert. Unskalierte Features dominieren das Modell. Setze immer StandardScaler auf X und y vor dem Fitten ein.
Epsilon falsch verstehen. Epsilon ist der mit Abstand wichtigste Parameter. Zu groß – und das Modell underfittet, weil es zu viel ignoriert. Zu klein – und es verhält sich wie Standardregression und jagt jedem Punkt nach. Mach immer eine Grid Search und prüfe, was auf deinem Testset am besten läuft.
Kein Parametertuning. Mit Default-Werten gute Ergebnisse zu erwarten, funktioniert selten – wie bei den meisten ML-Modellen. C, Epsilon und Gamma müssen zusammen getunt werden. Nutze Grid Search mit Cross-Validation.
SVR auf sehr großen Datensätzen nutzen. Ab mehr als ein paar Tausend Samples wird SVR langsam. Es skaliert schlicht nicht so gut wie andere Algorithmen. Wechsle zu Modellen, die große Datensätze besser handhaben – z. B. Gradient Boosting oder ein neuronales Netz.
Wichtig: Diese vier Dinge richtig zu machen, garantiert dir kein perfektes Modell – aber wenn du eines davon falsch machst, ist ein schlechtes Ergebnis fast sicher.
Merke dir zum Abschluss: SVR löst ein anderes Problem als Standardregression. Statt jeden Fehler zu minimieren, passt es eine Funktion innerhalb eines Randes an und ignoriert das Rauschen darin – genau deshalb ist es hilfreich, wenn deine Daten nicht sauber oder nicht perfekt linear sind.
SVR ist nicht für Tempo oder Einfachheit bekannt. Aber es ist robust. Wenn deine Daten nichtlineare Beziehungen und Ausreißer enthalten, die du nicht modellieren willst, hilft dir SVR, dich auf Struktur zu konzentrieren statt jedem Punkt hinterherzulaufen.
Denk daran: Features skalieren, Parameter tunen, den richtigen Kernel wählen und bei der Datenmenge konservativ bleiben. Wenn du das beherzigst, liefert SVR ein robustes Modell, das in der Produktion selten böse überrascht.
SVR ist nur ein Werkzeug, das jede Data Scientist kennen sollte. Melde dich für unseren Machine Learning Engineer-Lernpfad an und mach dich fit für den Job in 2026.
Lerne mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Tutorial
Allan Ouko
Tutorial
Matt Crabtree
Tutorial
Aditya Sharma
Tutorial
Allan Ouko
Tutorial
Allan Ouko

