Track
Uczenie maszynowe nadzorowane w Pythonie
25 godz.
Standardowe metody regresji minimalizują łączny błąd we wszystkich punktach danych. To oznacza, że każdy resztowy błąd, nawet najmniejszy, ciągnie model w jakimś kierunku. W efekcie otrzymujesz model wrażliwy na szum i wartości odstające.
Model regresji wektorów nośnych dopasowuje natomiast funkcję w obrębie marginesu tolerancji i ignoruje błędy, które się w nim mieszczą. Taki margines zmienia sposób myślenia o optymalizacji. Zamiast próbować optymalizować każdy punkt danych, SVR skupia się na ogólnej strukturze danych, co — jak mam nadzieję pokazać — czyni go odpornym w zderzeniu z danymi ze świata rzeczywistego.
Jeśli potrzebujesz wprowadzenia przed startem, przeczytaj nasz artykuł Regresja liniowa w Pythonie jako wstęp do modelowania predykcyjnego.
Support Vector Regression to metoda regresji oparta na tych samych podstawach co Support Vector Machines (SVM), czyli klasa modeli pierwotnie zaprojektowanych do zadań klasyfikacji, takich jak wykrywanie spamu czy rozpoznawanie obrazów.
Kluczowa idea jest prosta — zamiast próbować minimalizować każdy błąd predykcji, SVR dopasowuje funkcję, dopuszczając margines tolerancji wokół niej. Błędy mieszczące się w tym marginesie się nie liczą. Model skupia się na dobrym dopasowaniu całościowym, a nie na korygowaniu każdej drobnej odchyłki.
To właśnie odróżnia SVR od większości innych modeli regresji.
Standardowe metody regresji traktują każdy błąd resztowy jako sygnał. SVR uznaje większość za szum. W rezultacie dostajesz model mniej skupiony na byciu dokładnym w każdym punkcie, a bardziej na uchwyceniu leżącej u podstaw struktury danych.
W centrum SVR znajduje się tzw. rura epsilon — margines tolerancji otaczający dopasowaną funkcję z obu stron.
Każdy punkt danych, który mieści się w rurze, jest uznawany za wystarczająco bliski. SVR ignoruje te punkty podczas dopasowania modelu. Liczą się tylko punkty spoza rury, bo to one faktycznie kształtują granicę decyzyjną.
Przykład rury epsilon
Jak to interpretować:
To odróżnia SVR od standardowej regresji. W regresji liniowej każdy punkt danych „ciągnie” model — także te zaszumione. W SVR większość punktów jest nieistotna. Efektem jest dopasowanie zbudowane dzięki dobrej strukturze ogólnej.
SVR stara się jednocześnie zaspokoić dwa sprzeczne cele.
Pierwszy to utrzymać model możliwie płaskim. Płaska funkcja jest prostsza, a prostsze modele zwykle lepiej uogólniają na nowe dane. Drugi to minimalizować błędy dla punktów poza rurą epsilon — tych, których SVR nie może zignorować.
Te dwa cele ciągną w przeciwnych kierunkach i tu wchodzi w grę parametr regularyzacji C. Kontroluje on, jaką wagę SVR przykłada do błędów poza rurą względem prostoty modelu:
Zawsze balansujesz między prostotą modelu a tolerancją błędów. Odpowiednia wartość C zależy od twoich danych i oczekiwanego poziomu szumu. Zły wybór w którąkolwiek stronę obniży wydajność modelu na nowych danych.
To problem optymalizacyjny, który można rozwiązać iteracyjnie, więc nie ma się czym martwić.
W SVR liczą się tylko te punkty danych, które wypadają poza rurę epsilon.
To są wektory nośne — punkty leżące poza marginesem, które kształtują dopasowaną funkcję. Wszystko wewnątrz rury jest ignorowane w trakcie uczenia. Model w żaden istotny sposób „nie widzi” tych punktów.
Wektory nośne
Przydatnym skutkiem ubocznym jest rzadkość (sparsity). W praktyce tylko niewielka część danych treningowych staje się wektorami nośnymi. Reszta nie wnosi nic do finalnego modelu, co sprawia, że SVR jest oszczędny pamięciowo i szybki w ewaluacji po treningu, ponieważ predykcje zależą tylko od tych kilku wpływowych punktów.
SVR nie jest ograniczony do prostych linii. Potrafi obsłużyć nieliniowe zależności dzięki technice zwanej sztuczką z jądrem (kernel trick).
Zamiast dopasowywać funkcję w oryginalnej przestrzeni wejściowej, SVR odwzorowuje dane do przestrzeni o wyższym wymiarze, gdzie możliwe staje się dopasowanie liniowe. To liniowe dopasowanie w przestrzeni wyższowymiarowej przekłada się z powrotem na krzywą nieliniową w twoich oryginalnych danych.
Dwa najczęściej używane jądra to:
Wybór jądra zależy od danych. RBF to dobry punkt wyjścia, gdy nie masz pewności.
Różnica sprowadza się do tego, co każdy model stara się osiągnąć.
Regresja liniowa minimalizuje łączny błąd we wszystkich punktach danych. Liczy się każdy błąd resztowy, nawet najmniejszy. Jeśli zaszumiony punkt wytrąci model z kursu, całe dopasowanie przesuwa się, by to skompensować.
SVR ignoruje błędy w obrębie rury epsilon. Reaguje tylko na punkty wypadające poza margines — i nawet wtedy siłę reakcji kontroluje C. Model optymalizuje strukturę, a nie dokładność na każdym pojedynczym punkcie.
Ta różnica sprawia, że SVR jest bardziej odporny na wartości odstające. Pojedynczy zaszumiony punkt nie zdominuje dopasowania tak jak w regresji liniowej, bo SVR od początku nie próbuje go „gonić”.
Oto wszystkie różnice:

Regresja liniowa w porównaniu z SVR
SVR ma trzy parametry, które musisz zrozumieć, zanim zaczniesz optymalizować model.
Epsilon definiuje szerokość marginesu tolerancji wokół dopasowanej funkcji. Większe ε oznacza szerszą rurę — więcej punktów jest ignorowanych, a model staje się prostszy. Mniejsze ε zwęża rurę i zmusza model do ściślejszego dopasowania do danych.
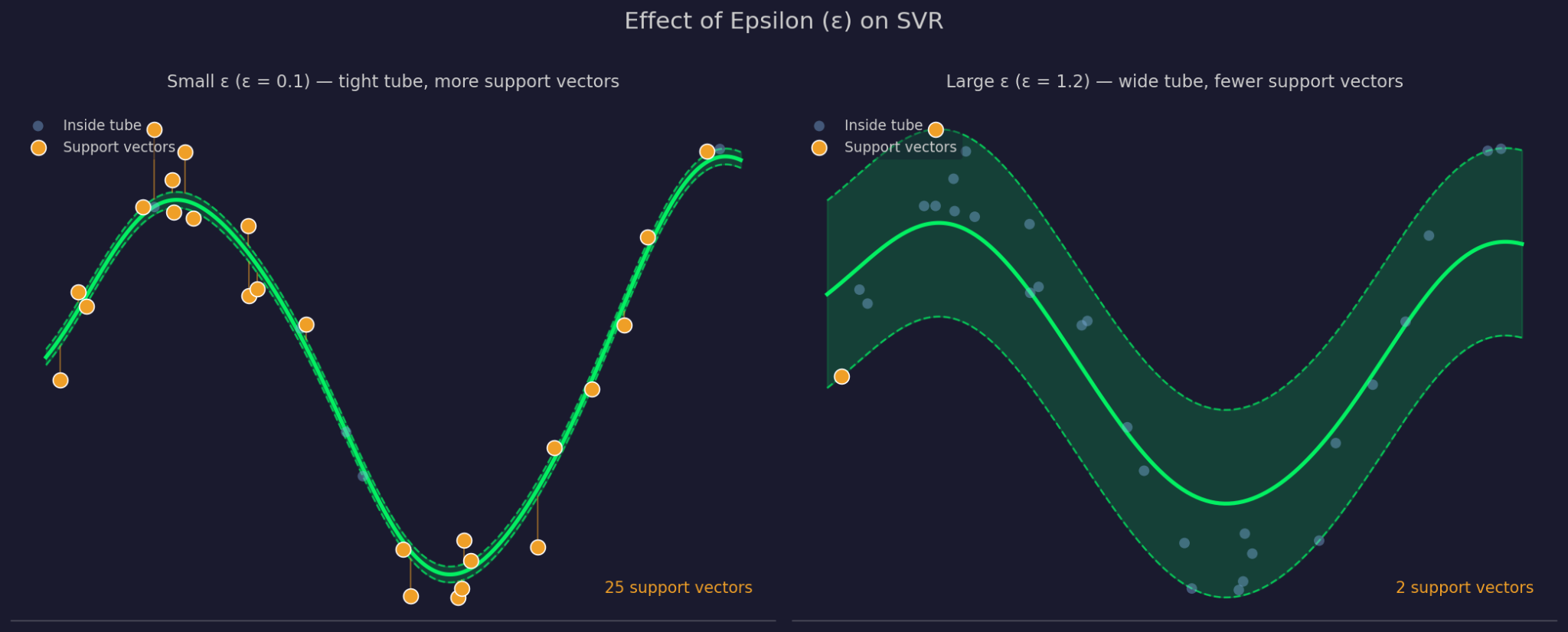
Małe vs duże Epsilon
C kontroluje, jak silnie SVR karze błędy dla punktów poza rurą. Wysokie C oznacza, że model traktuje te błędy poważnie i dopasowuje się ciaśniej. Niskie C oznacza, że model akceptuje więcej naruszeń w zamian za prostszą, bardziej płaską funkcję. C i ε działają razem, bo zmiana jednego wpływa w praktyce na zachowanie drugiego.
Małe vs duże C
Jądro determinuje, jak SVR obsługuje nieliniowe wzorce. RBF to najczęstszy wybór i dobrze sprawdza się jako domyślny. Jądra wielomianowe są przydatne dla określonych kształtów krzywych. Jądro liniowe sprowadza SVR do opartej na marginesie regresji liniowej, co bywa przydatne, gdy twoje dane są już „grzeczne”.
Skuteczne zastosowanie SVR to przejście przez kilka kroków i spełnienie pewnych warunków wstępnych. Pokażę ci, jakie.
Typowy workflow wygląda tak:
Skaluj dane: SVR jest wrażliwy na skalę cech. Jeśli twoje cechy są w różnych skalach, model nie będzie zachowywał się zgodnie z oczekiwaniami. Użyj StandardScaler zarówno na X, jak i y przed dopasowaniem
Wybierz jądro: RBF to odpowiednie domyślne ustawienie dla większości problemów. Przełącz na wielomian, jeśli masz konkretny powód sądzić, że zależność ma taki kształt
Strojenie parametrów: Ustaw C, epsilon i gamma przed dopasowaniem. Standardowe podejścia to grid search lub walidacja krzyżowa
Dopasuj model: Wywołaj .fit() na skalowanych danych treningowych. Po treningu odwróć transformację predykcji do oryginalnej skali
Oto kompletny przykład z użyciem scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE na zbiorze testowym
Kilka rzeczy, na które warto zwrócić uwagę w tym kodzie. Po pierwsze, StandardScaler jest zastosowany oddzielnie do X i y. Skalowanie wyłącznie cech to częsty błąd prowadzący do słabych wyników z SVR. Po drugie, predykcje są na końcu odwracane do oryginalnej skali przed ewaluacją.
Dwa poniższe wykresy pokazują, jak wygląda dopasowany model. Pierwszy przedstawia krzywą SVR z rurą epsilon na danych treningowych i testowych:
Rura epsilon na danych treningowych i testowych
Drugi porównuje wartości przewidziane z rzeczywistymi na zbiorze testowym:
Wartości przewidziane vs rzeczywiste
Punkty blisko przekątnej oznaczają, że model dobrze przewiduje.
SVR ma określone mocne strony, które czynią go właściwym narzędziem w odpowiedniej sytuacji. Ma też słabości, które czynią go złym wyborem w innych.
SVR najlepiej sprawdza się w określonych warunkach. Powinieneś używać SVR, gdy:
Unikaj SVR, gdy:
Jeśli twój zbiór danych jest duży i zaszumiony, metody gradient boosting warto rozważyć w pierwszej kolejności. SVR jest świetny, gdy masz czyste, średniej wielkości dane ze strukturą, której prostsze modele nie potrafią dobrze dopasować.
Większość problemów z SVR sprowadza się do tego samego zestawu błędów — potraktuj to jako ściągę, czego nie robić.
Brak skalowania cech. SVR to algorytm oparty na odległościach, więc nieskalowane cechy będą dominować w modelu. Zawsze stosuj StandardScaler zarówno do X, jak i y przed dopasowaniem.
Niezrozumienie epsilon. Epsilon to zdecydowanie najważniejszy parametr. Zbyt duży — model niedopasowuje, bo za dużo ignoruje. Zbyt mały — zachowuje się jak standardowa regresja, goniąc każdy punkt danych. Zawsze rób grid search, by sprawdzić, co działa najlepiej na twoim zbiorze testowym.
Pominięcie strojenia parametrów. Uruchamianie SVR z wartościami domyślnymi i oczekiwanie dobrych wyników rzadko działa — tak jak w większości modeli uczenia maszynowego. C, epsilon i gamma trzeba stroić razem. Użyj grid search z walidacją krzyżową.
Używanie SVR na bardzo dużych zbiorach. Jeśli masz więcej niż kilka tysięcy próbek, SVR będzie wolny. Po prostu nie skaluje się jak inne algorytmy. Przełącz się na model lepiej działający na dużych zbiorach, jak gradient boosting lub sieć neuronowa.
Warto też zauważyć, że dopilnowanie tych czterech kwestii nie gwarantuje świetnego modelu, ale zaniedbanie którejkolwiek niemal na pewno gwarantuje słaby.
Podsumowując, pamiętaj, że SVR rozwiązuje inny problem niż standardowa regresja. Zamiast minimalizować każdy błąd, dopasowuje funkcję w obrębie marginesu i ignoruje szum, który się w nim mieści — co czyni go szczególnie użytecznym, gdy twoje dane nie są czyste ani idealnie liniowe.
Nie słynie z szybkości ani prostoty. Ale jest odporny. Jeśli twoje dane mają nieliniowe zależności i wartości odstające, których nie chcesz modelować, SVR pozwoli ci skupić się na strukturze zamiast gonić każdy punkt danych.
Pamiętaj tylko, by skalować cechy, stroić parametry, dobrać właściwe jądro i zachować umiar w wielkości danych. Jeśli zrobisz to dobrze, SVR zapewni ci odporny model, który raczej nie zawiedzie w produkcji.
SVR to tylko jedno z narzędzi, które każdy data scientist powinien znać. Zapisz się na ścieżkę Machine Learning Engineer, aby poznać pozostałe i być gotowym do pracy w 2026 roku.
Ucz się z DataCamp
Track
course
course