
Cursus
Apprentissage automatique supervisé en Python
25 h
Les méthodes de régression classiques minimisent l’erreur totale sur l’ensemble des points de données. Autrement dit, chaque résidu, même minime, tire le modèle dans une direction. Au final, vous obtenez un modèle sensible au bruit et aux valeurs aberrantes.
La Support Vector Regression, elle, ajuste une fonction à l’intérieur d’une marge de tolérance et ignore les erreurs qui s’y trouvent. Cette marge change la façon d’optimiser. Plutôt que d’optimiser chaque point, la SVR se concentre sur la structure globale des données, ce qui la rend, comme j’espère vous le montrer, robuste face aux données réelles.
Besoin d’une remise à niveau avant de commencer ? Consultez notre article Linear Regression in Python pour une introduction à la modélisation prédictive.
La Support Vector Regression est une méthode de régression fondée sur les mêmes principes que les Support Vector Machines (SVM), une famille de modèles initialement conçus pour la classification (détection de spam, reconnaissance d’images, etc.).
L’idée clé est simple : au lieu de chercher à minimiser chaque erreur de prédiction, la SVR ajuste une fonction tout en autorisant une marge de tolérance autour de celle-ci. Les erreurs situées à l’intérieur de cette marge ne comptent pas. Le modèle cherche à bien saisir la forme générale, pas à corriger chaque petite déviation.
C’est ce qui distingue la SVR de la plupart des autres modèles de régression.
Les méthodes classiques considèrent chaque résidu comme un signal. La SVR traite la plupart d’entre eux comme du bruit. Vous obtenez ainsi un modèle moins obsédé par la précision point par point et davantage focalisé sur la structure sous-jacente des données.
Au cœur de la SVR se trouve ce que l’on appelle le tube epsilon : une marge de tolérance qui entoure la fonction ajustée de part et d’autre.
Tout point à l’intérieur du tube est jugé suffisamment proche. La SVR ignore ces points pendant l’apprentissage. Seuls les points à l’extérieur du tube comptent : ce sont eux qui façonnent la frontière décision.
Exemple de tube epsilon
Voici comment l’interpréter :
C’est là que la SVR se différencie d’une régression linéaire. En régression linéaire, chaque point “tire” le modèle – y compris les points bruyants. En SVR, la plupart des points sont indifférents. Le résultat est un ajustement guidé par une bonne structure d’ensemble.
La SVR poursuit deux objectifs antagonistes.
Le premier est de garder le modèle aussi « plat » que possible. Une fonction plus plate est plus simple et généralise mieux. Le second est de minimiser les erreurs sur les points hors du tube epsilon – ceux que la SVR ne peut pas ignorer.
Ces deux objectifs tirent en sens opposé, d’où le rôle du paramètre de régularisation C. Il contrôle l’importance accordée aux erreurs hors du tube par rapport à la simplicité du modèle :
Vous arbitrez sans cesse entre simplicité du modèle et tolérance à l’erreur. La bonne valeur de C dépend de vos données et du niveau de bruit attendu. Se tromper dans un sens comme dans l’autre dégradera la performance en généralisation.
C’est un problème d’optimisation résolu itérativement : rien d’inquiétant.
En SVR, seuls les points de données situés hors du tube epsilon comptent vraiment.
Ce sont les vecteurs de support : les points au-delà de la marge qui déterminent la fonction ajustée. Tout ce qui est à l’intérieur du tube est ignoré pendant l’apprentissage. Le modèle ne « voit » pas vraiment ces points.
Vecteurs de support
Conséquence utile : la parcimonie. En pratique, seule une petite partie des données d’apprentissage devient vecteurs de support. Le reste n’apporte rien au modèle final, ce qui rend la SVR économe en mémoire et rapide à l’évaluation une fois entraînée, puisque les prédictions ne dépendent que de ces quelques points influents.
La SVR ne se limite pas à des droites. Elle gère les relations non linéaires via la technique du kernel trick.
Plutôt que d’ajuster une fonction dans l’espace d’entrée initial, la SVR projette les données dans un espace de dimension supérieure où un ajustement linéaire devient possible. Cet ajustement linéaire se traduit ensuite par une courbe non linéaire dans l’espace d’origine.
Les noyaux les plus courants sont :
Le choix du noyau dépend de vos données. RBF est un excellent point de départ en cas de doute.
La différence tient à l’objectif poursuivi par chaque modèle.
La régression linéaire minimise l’erreur totale sur tous les points. Chaque résidu compte, même minuscule. Un point bruyant peut dévier le modèle et tout l’ajustement se déplace pour compenser.
La SVR ignore les erreurs à l’intérieur du tube epsilon. Elle ne réagit qu’aux points hors marge – et encore, la force de réaction est pilotée par C. Le modèle optimise la structure, pas la justesse point par point.
Cette différence rend la SVR plus robuste aux valeurs aberrantes. Un point bruyant isolé n’entraîne pas l’ajustement comme en régression linéaire, car la SVR ne cherche pas à le suivre.
Voici toutes les différences :

Régression linéaire vs SVR
Trois paramètres sont à maîtriser avant d’optimiser le modèle.
Epsilon définit la largeur de la marge de tolérance autour de la fonction ajustée. Un ε plus grand → tube plus large : davantage de points sont ignorés et le modèle se simplifie. Un ε plus petit resserre le tube et contraint le modèle à coller de plus près aux données.
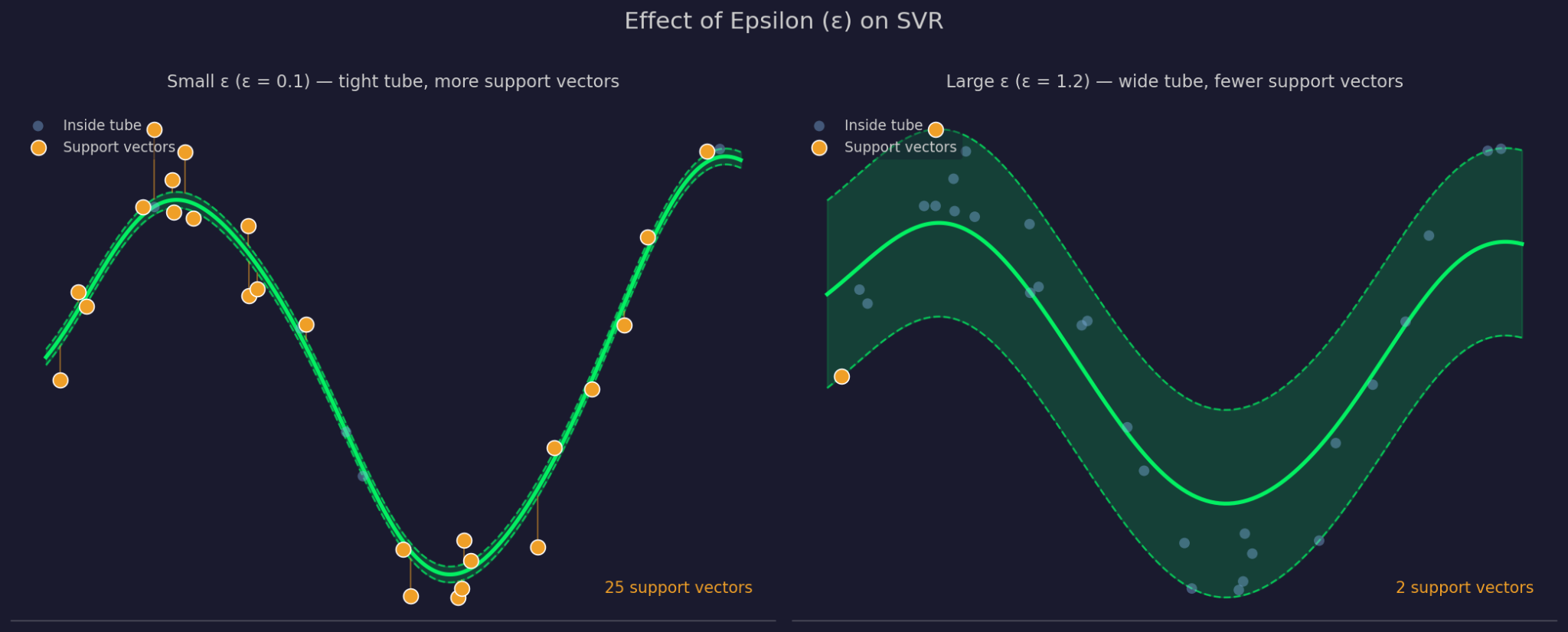
Petit vs grand epsilon
C contrôle la pénalisation des erreurs sur les points hors du tube. Un C élevé resserre l’ajustement. Un C faible accepte plus d’écarts en échange d’une fonction plus simple et plus plate. C et ε interagissent : modifier l’un influe sur le comportement de l’autre.
Petit vs grand C
Le noyau détermine la gestion des motifs non linéaires. RBF est le choix le plus courant et un bon défaut. Les noyaux polynômiaux conviennent à des formes spécifiques. Un noyau linéaire ramène la SVR à une régression linéaire à marge, utile si vos données sont déjà bien comportées.
Bien faire fonctionner la SVR suppose quelques prérequis et étapes. Voici lesquels.
Le flux de travail type :
Mettez vos données à l’échelle : la SVR est sensible aux échelles des variables. Si vos variables sont sur des échelles différentes, le modèle se comportera mal. Utilisez StandardScaler sur X et y avant l’ajustement
Choisissez un noyau : RBF convient à la plupart des cas. Passez à un polynôme si vous avez une raison de penser que la relation suit cette forme
Ajustez les hyperparamètres : définissez C, epsilon et gamma avant l’apprentissage. Grid search ou validation croisée sont les approches standards
Entraînez le modèle : appelez .fit() sur les données d’apprentissage mises à l’échelle. Une fois entraîné, appliquez l’inverse transform pour revenir à l’échelle d’origine
Voici un exemple complet avec scikit-learn :
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE sur le jeu de test
Deux points à noter. D’abord, StandardScaler est appliqué séparément à X et à y. Ne mettre à l’échelle que les caractéristiques est une erreur fréquente qui dégrade les résultats avec la SVR. Ensuite, on applique une inverse transform aux prédictions pour revenir à l’échelle d’origine avant l’évaluation.
Les deux graphiques ci-dessous illustrent le modèle ajusté. Le premier montre la courbe SVR avec le tube epsilon sur les données d’apprentissage et de test :
Tube epsilon sur données d’apprentissage et de test
Le second compare valeurs prédites et réelles sur le jeu de test :
Valeurs prédites vs réelles
Des points proches de la diagonale indiquent de bonnes prédictions.
La SVR a des atouts qui en font l’outil idéal dans certaines situations, et des faiblesses qui la rendent inadaptée dans d’autres.
La SVR fonctionne au mieux dans certaines conditions. Optez pour la SVR lorsque :
Évitez la SVR lorsque :
Si votre jeu est à la fois volumineux et bruyant, les méthodes de gradient boosting sont à privilégier. La SVR excelle avec des données propres, de taille modérée, dont la structure met en défaut des modèles plus simples.
La plupart des soucis tiennent aux mêmes erreurs : considérez cette liste comme un aide-mémoire de ce qu’il ne faut pas faire.
Ne pas mettre les variables à l’échelle. La SVR est basée sur des distances : des variables non standardisées domineront. Appliquez toujours StandardScaler à X et à y avant l’ajustement.
Mal comprendre epsilon. Epsilon est le paramètre le plus important. Trop grand → sous-apprentissage en ignorant trop d’informations. Trop petit → comportement proche d’une régression classique, à « poursuivre » chaque point. Faites toujours une grille de recherche pour trouver ce qui fonctionne le mieux sur votre jeu de test.
Faire l’impasse sur le tuning. Lancer une SVR avec les paramètres par défaut et espérer de bons résultats fonctionne rarement – comme pour la plupart des modèles de ML. C, epsilon et gamma doivent être réglés ensemble. Utilisez une grille avec validation croisée.
Utiliser la SVR sur de très grands jeux. Au-delà de quelques milliers d’échantillons, la SVR devient lente. Privilégiez des modèles plus scalables, comme le gradient boosting ou un réseau de neurones.
Notez bien : réussir ces quatre points ne garantit pas un excellent modèle, mais en rater un garantit presque un mauvais résultat.
Retenez que la SVR ne résout pas le même problème que la régression classique. Au lieu de minimiser chaque erreur, elle ajuste une fonction avec une marge et ignore le bruit à l’intérieur – ce qui est précieux lorsque vos données ne sont ni propres ni parfaitement linéaires.
Elle n’est pas réputée pour sa rapidité ou sa simplicité. Mais elle est robuste. Si vos données présentent des relations non linéaires et des outliers que vous ne souhaitez pas modéliser, la SVR vous permet de vous concentrer sur la structure sans courir après chaque point.
Souvenez-vous : mettez à l’échelle, ajustez les paramètres, choisissez le bon noyau et restez raisonnable sur le volume de données. En appliquant ces bonnes pratiques, la SVR vous offrira un modèle robuste, fiable en production.
La SVR n’est qu’un outil parmi d’autres que tout data scientist doit connaître. Inscrivez-vous à notre parcours Machine Learning Engineer pour maîtriser les autres et être opérationnel en 2026.
Formez-vous avec DataCamp
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Samuel Shaibu
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Aditya Sharma

