Tracks
การเรียนรู้ของเครื่องแบบมีผู้สอน ใน Python
25 ชม.
วิธีรีเกรสชันมาตรฐานจะทำให้ผลรวมของความคลาดเคลื่อนทั่วทั้งชุดข้อมูลมีค่าน้อยที่สุด นั่นหมายความว่าค่าเรสิดวลแต่ละตัว ไม่ว่าจะเล็กแค่ไหน ก็จะดึงแบบจำลองให้เอียงไปในทิศทางใดทิศทางหนึ่ง ผลลัพธ์คือได้แบบจำลองที่ไวต่อสัญญาณรบกวนและค่าอยู่นอกกลุ่ม (outliers)
ขณะที่ซัพพอร์ตเวกเตอร์รีเกรสชันจะฟิตฟังก์ชันภายในขอบเขตค่าผิดพลาดที่ยอมรับได้ และมองข้ามข้อผิดพลาดที่อยู่ภายในขอบเขตนั้นระยะขอบนี้เปลี่ยนแนวคิดเรื่องการทำให้เหมาะที่สุด จากที่พยายามทำให้ทุกจุดข้อมูลเหมาะที่สุด SVR จะโฟกัสที่โครงสร้างโดยรวมของข้อมูล ซึ่งทำให้มัน—ดังที่หวังจะชี้ให้เห็น—มีความทนทานกับข้อมูลโลกจริง
ถ้าต้องการทบทวนพื้นฐานก่อนเริ่มต้น โปรดอ่านบทความ Linear Regression in Python เพื่อปูพื้นการทำโมเดลพยากรณ์
ซัพพอร์ตเวกเตอร์รีเกรสชันเป็นวิธีรีเกรสชันที่สร้างบนรากฐานเดียวกับ ซัพพอร์ตเวกเตอร์แมชชีน (SVM) ซึ่งเป็นตระกูลของแบบจำลองที่ออกแบบมาเพื่อการจัดหมวดหมู่ เช่น การตรวจจับสแปมหรือการรู้จำภาพ
แนวคิดสำคัญเข้าใจไม่ยาก—แทนที่จะพยายามทำให้ข้อผิดพลาดของการพยากรณ์ทุกจุดต่ำที่สุด SVR จะฟิตฟังก์ชันโดยยอมให้มีระยะขอบความคลาดเคลื่อนรอบ ๆ ฟังก์ชันนั้น ข้อผิดพลาดที่อยู่ในขอบเขตนี้จะไม่ถูกนับ แบบจำลองจึงมุ่งทำให้การฟิตโดยรวมถูกต้อง แทนที่จะไล่แก้ไขความเบี่ยงเบนเล็ก ๆ น้อย ๆ ทุกจุด
นั่นแหละคือสิ่งที่ทำให้ SVR แตกต่างจากแบบจำลองรีเกรสชันส่วนใหญ่
วิธีรีเกรสชันมาตรฐานมองว่าเรสิดวลทุกตัวเป็นสัญญาณ ขณะที่ SVR มองว่าส่วนใหญ่เป็นสัญญาณรบกวน ผลลัพธ์คือได้แบบจำลองที่ไม่หมกมุ่นกับการให้ถูกต้องเป๊ะในทุกจุด แต่สนใจทำให้โครงสร้างพื้นฐานของข้อมูลถูกต้องมากกว่า
หัวใจของ SVR คือสิ่งที่เรียกว่า epsilon tube — ระยะขอบความคลาดเคลื่อนที่พันรอบฟังก์ชันที่ฟิตไว้ทั้งสองด้าน
จุดข้อมูลใดก็ตามที่อยู่ในท่อจะถือว่าใกล้พอ SVR จะมองข้ามจุดเหล่านี้ระหว่างการฟิตแบบจำลอง มีเพียงจุดที่อยู่นอกท่อเท่านั้นที่สำคัญ เพราะเป็นจุดที่กำหนดขอบเขตการตัดสินใจจริง ๆ
ตัวอย่าง Epsilon tube
ตีความได้ดังนี้:
นี่เองที่ทำให้ SVR แตกต่างจากรีเกรสชันมาตรฐาน ในรีเกรสชันเชิงเส้น ทุกจุดข้อมูลจะดึงแบบจำลอง—including จุดที่มีสัญญาณรบกวน—ขณะที่ใน SVR จุดส่วนใหญ่ไม่มีความเกี่ยวข้อง ส่งผลให้ได้การฟิตที่ให้โครงสร้างโดยรวมที่ดี
SVR มีสองเป้าหมายที่แข่งขันกันซึ่งพยายามสนองไปพร้อม ๆ กัน
หนึ่งคือทำให้แบบจำลองแบนที่สุดเท่าที่จะทำได้ ฟังก์ชันที่แบนกว่านั้นเรียบง่ายกว่า และแบบจำลองที่เรียบง่ายมักทั่วไปได้ดีกับข้อมูลใหม่ อีกหนึ่งคือทำให้ข้อผิดพลาดของจุดที่อยู่นอก epsilon tube น้อยที่สุด — จุดที่ SVR มองข้ามไม่ได้
สองเป้าหมายนี้ดึงกันคนละทิศ ซึ่งนี่เองที่พารามิเตอร์การทำให้เป็นปกติ C เข้ามามีบทบาท มันควบคุมว่าน้ำหนักที่ SVR ให้กับข้อผิดพลาดนอกท่อนั้นมากน้อยเพียงใดเมื่อเทียบกับความเรียบง่ายของแบบจำลอง:
คุณกำลังแลกเปลี่ยนระหว่างความเรียบง่ายของแบบจำลองกับความทนต่อข้อผิดพลาด ค่า C ที่เหมาะขึ้นกับข้อมูลและระดับสัญญาณรบกวนที่คาดไว้ เลือกผิดไม่ว่าทางใดจะทำให้ประสิทธิภาพบนข้อมูลใหม่ลดลง
นี่เป็นปัญหาการทำให้เหมาะที่สุดที่แก้แบบวนซ้ำได้ จึงไม่ใช่เรื่องที่ต้องกังวล
ใน SVR มีเพียงจุดข้อมูลที่อยู่นอก epsilon tube เท่านั้นที่มีความหมายจริง
จุดเหล่านี้คือ support vectors — จุดข้อมูลที่อยู่นอกขอบและกำหนดรูปทรงของฟังก์ชันที่ฟิตไว้ ทุกอย่างในท่อจะถูกมองข้ามระหว่างการฝึก แบบจำลองแทบไม่ได้ “เห็น” จุดเหล่านั้นอย่างมีนัยสำคัญ
ซัพพอร์ตเวกเตอร์
ผลข้างเคียงที่มีประโยชน์คือความเบาบาง (sparsity) ในทางปฏิบัติ มีเพียงส่วนย่อยเล็ก ๆ ของข้อมูลฝึกเท่านั้นที่กลายเป็นซัพพอร์ตเวกเตอร์ ส่วนที่เหลือไม่ส่งผลใด ๆ ต่อแบบจำลองสุดท้าย ทำให้ SVR ใช้หน่วยความจำอย่างมีประสิทธิภาพและประเมินผลได้รวดเร็วหลังฝึกเสร็จ เพราะการพยากรณ์ขึ้นกับเพียงจุดที่มีอิทธิพลไม่กี่จุดนั้น
SVR ไม่ได้จำกัดอยู่แค่การฟิตเส้นตรง มันจัดการความสัมพันธ์ที่ไม่เป็นเชิงเส้นได้ด้วยเทคนิคที่เรียกว่า kernel trick.
แทนที่จะฟิตฟังก์ชันในปริภูมิป้อนเข้าดั้งเดิม SVR จะทำการแมปข้อมูลไปยังปริภูมิที่มิติสูงกว่า ซึ่งการฟิตเชิงเส้นทำได้ ในปริภูมิที่มิติสูงกว่านั้นเส้นเชิงเส้นจะย้อนแปลกลับมาเป็นเส้นโค้งไม่เชิงเส้นในปริภูมิดั้งเดิมของคุณ
เคอร์เนลที่ใช้กันมากที่สุดสองชนิดได้แก่:
การเลือกเคอร์เนลขึ้นกับข้อมูลของคุณ RBF เป็นจุดเริ่มต้นที่ดีเมื่อยังไม่แน่ใจ
ความแตกต่างอยู่ที่สิ่งที่แบบจำลองแต่ละตัวพยายามทำ
รีเกรสชันเชิงเส้น ลดผลรวมของข้อผิดพลาดให้ต่ำสุดในทุกจุดข้อมูล เรสิดวลทุกตัวถูกนับ ไม่ว่าจะเล็กเพียงใด หากมีจุดที่มีสัญญาณรบกวนดึงแบบจำลองออกนอกเส้นทาง การฟิตทั้งหมดจะขยับเพื่อชดเชย
SVR มองข้ามข้อผิดพลาดภายใน epsilon tube มันจะตอบสนองเฉพาะจุดที่อยู่นอกขอบเท่านั้น—และแม้กระทั่งในกรณีนั้น C ก็จะควบคุมความแรง แบบจำลองจึงทำให้เหมาะเพื่อโครงสร้าง ไม่ใช่เพื่อความแม่นยำในทุกจุดรายตัว
ความแตกต่างนี้ทำให้ SVR ทนต่อ outliers ได้ดีกว่า จุดที่มีสัญญาณรบกวนเพียงจุดเดียวจะไม่ทำให้การฟิตเพี้ยนเหมือนในรีเกรสชันเชิงเส้น เพราะ SVR ไม่เคยพยายามไล่ตามมันตั้งแต่แรก
สรุปความแตกต่างทั้งหมดดังภาพ:

รีเกรสชันเชิงเส้นเทียบกับ SVR
SVR มีสามพารามิเตอร์ที่ควรเข้าใจก่อนเริ่มปรับแต่งแบบจำลอง
Epsilon กำหนดความกว้างของระยะขอบความคลาดเคลื่อนรอบฟังก์ชันที่ฟิตไว้ ε ที่ใหญ่ขึ้นหมายถึงท่อที่กว้างขึ้น — มองข้ามจุดได้มากขึ้นและแบบจำลองเรียบง่ายขึ้น ε ที่เล็กลงทำให้ท่อแคบลงและบังคับให้แบบจำลองฟิตใกล้กับข้อมูลมากขึ้น
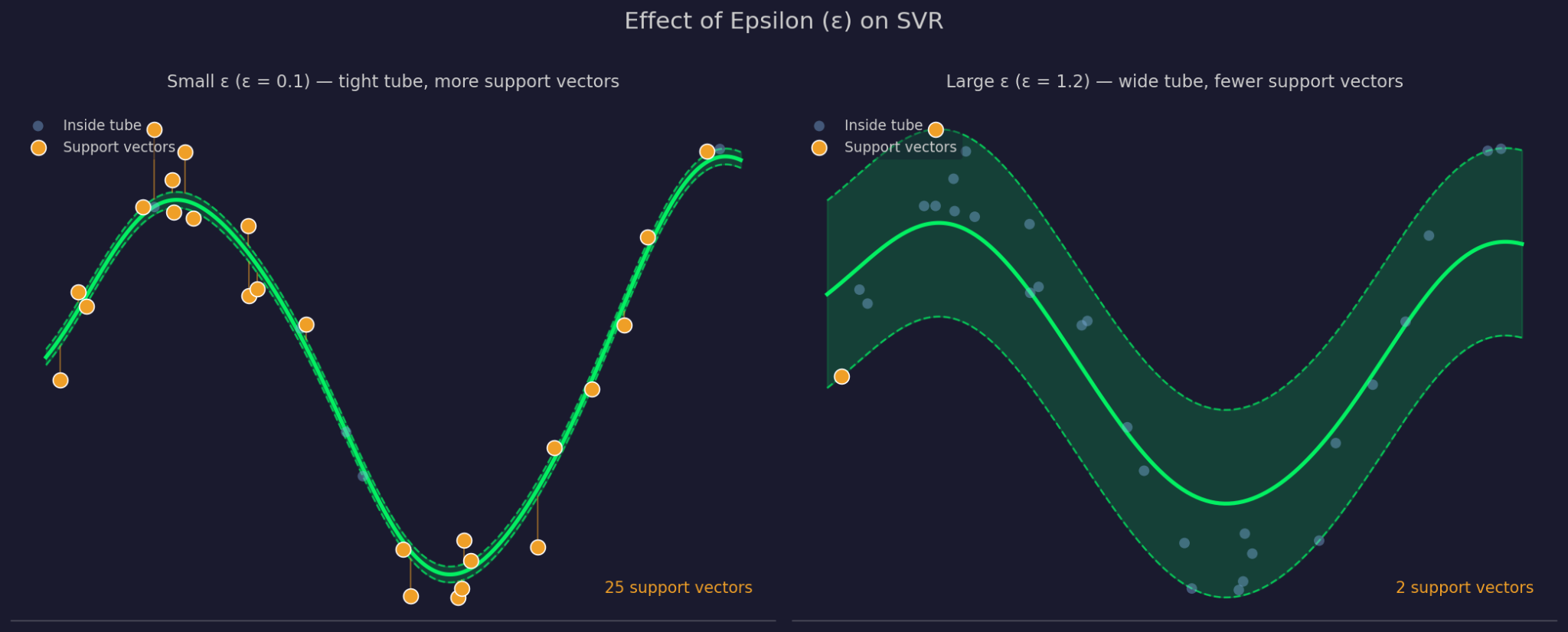
Epsilon เล็กเทียบกับใหญ่
C ควบคุมว่าซัพพอร์ตเวกเตอร์รีเกรสชันจะลงโทษข้อผิดพลาดของจุดที่อยู่นอกท่อมากน้อยเพียงใด ค่า C สูงหมายถึงแบบจำลองให้ความสำคัญกับข้อผิดพลาดเหล่านั้นและฟิตแน่นขึ้น ค่า C ต่ำหมายถึงแบบจำลองยอมรับการละเมิดมากขึ้นเพื่อแลกกับฟังก์ชันที่ง่ายและแบนกว่า C และ ε ทำงานร่วมกัน เพราะการเปลี่ยนค่าหนึ่งจะส่งผลต่ออีกค่าหนึ่งในทางปฏิบัติ
C เล็กเทียบกับใหญ่
เคอร์เนลกำหนดว่า SVR จะจัดการแพตเทิร์นที่ไม่เป็นเชิงเส้นอย่างไร RBF เป็นตัวเลือกที่พบบ่อยและใช้ได้ดีเป็นค่าเริ่มต้น เคอร์เนลพหุนามมีประโยชน์สำหรับรูปทรงเส้นโค้งเฉพาะ ส่วนเคอร์เนลเชิงเส้นทำให้ SVR ลดรูปเป็นรีเกรสชันเชิงเส้นแบบใช้ระยะขอบ ซึ่งมีประโยชน์เมื่อข้อมูลของคุณมีพฤติกรรมดีอยู่แล้ว
การทำให้ SVR ทำงานได้ดีคือการผ่านขั้นตอนและข้อกำหนดเบื้องต้นไม่กี่อย่าง มาดูกันว่ามีอะไรบ้าง
เวิร์กโฟลว์ทั่วไปมีดังนี้:
ปรับสเกลข้อมูล: SVR ไวต่อสเกลของฟีเจอร์ หากฟีเจอร์อยู่คนละสเกล แบบจำลองจะทำงานไม่เป็นไปตามคาด ใช้ StandardScaler กับทั้ง X และ y ก่อนทำการฟิต
เลือกเคอร์เนล: RBF เป็นตัวเลือกที่เหมาะสำหรับปัญหาส่วนใหญ่ สลับไปใช้พหุนามเมื่อมีเหตุผลเฉพาะเจาะจงว่าความสัมพันธ์เป็นรูปแบบนั้น
ปรับแต่งพารามิเตอร์: ตั้งค่า C, epsilon และ gamma ก่อนการฟิต ใช้การค้นหาแบบกริดหรือวัดข้ามชุด (cross-validation) เป็นแนวทางมาตรฐาน
ฟิตแบบจำลอง: เรียก .fit() กับข้อมูลฝึกที่ปรับสเกลแล้ว เมื่อฝึกเสร็จ ให้แปลงกลับการพยากรณ์ไปยังสเกลดั้งเดิมก่อนการประเมินผล
นี่คือตัวอย่างสมบูรณ์ด้วย scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE บนชุดทดสอบ
มีสองจุดที่ควรสังเกตในโค้ดนี้ ประการแรก ใช้ StandardScaler กับทั้ง X และ y แยกกัน การปรับสเกลเฉพาะฟีเจอร์เป็นความผิดพลาดที่พบได้บ่อยและนำไปสู่ผลลัพธ์ที่ไม่ดีใน SVR ประการที่สอง ต้องแปลงกลับค่าพยากรณ์ในตอนท้ายเพื่อให้กลับสู่สเกลดั้งเดิมก่อนประเมินผล
กราฟสองรูปด้านล่างแสดงหน้าตาแบบจำลองที่ฟิตแล้ว รูปแรกแสดงเส้นโค้ง SVR พร้อม epsilon tube ทับบนข้อมูลฝึกและทดสอบ:
Epsilon tube บนข้อมูลฝึกและทดสอบ
รูปที่สองเปรียบเทียบค่าที่พยากรณ์กับค่าจริงบนชุดทดสอบ:
ค่าพยากรณ์เทียบกับค่าจริง
จุดที่อยู่ใกล้เส้นทแยงมุมหมายถึงแบบจำลองพยากรณ์ได้ดี
SVR มีจุดแข็งเฉพาะที่ทำให้เหมาะกับบางสถานการณ์ และมีจุดอ่อนที่ทำให้ไม่เหมาะกับสถานการณ์อื่น
SVR เหมาะที่สุดภายใต้เงื่อนไขชุดหนึ่ง ควรใช้ SVR เมื่อ:
ควรหลีกเลี่ยง SVR เมื่อ:
ถ้าชุดข้อมูลมีขนาดใหญ่และมีสัญญาณรบกวน วิธีการแบบเกรเดียนต์บูสต์ติ้ง ควรพิจารณาก่อน SVR เหมาะเมื่อมีข้อมูลที่สะอาด ขนาดปานกลาง และมีโครงสร้างที่แบบจำลองเรียบง่ายฟิตได้ไม่ดี
ปัญหาส่วนใหญ่ของ SVR มักมาจากชุดข้อผิดพลาดเดิม ๆ — ให้ใช้ส่วนนี้เป็นชีตโกงของสิ่งที่ไม่ควรทำ
ไม่ปรับสเกลฟีเจอร์: SVR เป็นอัลกอริทึมที่อาศัยระยะทาง ซึ่งหมายความว่าฟีเจอร์ที่ไม่ปรับสเกลจะครอบงำแบบจำลอง เสมอไปให้ใช้ StandardScaler กับทั้ง X และ y ก่อนฟิต
เข้าใจ epsilon ผิด: Epsilon เป็นพารามิเตอร์ที่สำคัญที่สุด หากใหญ่เกินไป แบบจำลองจะอันเดอร์ฟิตเพราะมองข้ามมากเกินไป หากเล็กเกินไป จะมีพฤติกรรมคล้ายรีเกรสชันมาตรฐานที่ไล่ตามทุกจุดข้อมูล ควรทำ grid search เสมอเพื่อดูว่าค่าชุดใดให้ผลดีที่สุดบนชุดทดสอบ
ข้ามการปรับพารามิเตอร์: การรัน SVR ด้วยค่าดีฟอลต์แล้วคาดหวังผลลัพธ์ที่ดีมักไม่เกิดขึ้น — เช่นเดียวกับแบบจำลองแมชชีนเลิร์นนิงส่วนใหญ่ C, epsilon และ gamma ต้องปรับแต่งร่วมกัน ใช้การค้นหาแบบกริดร่วมกับการวัดข้ามชุด
ใช้ SVR กับชุดข้อมูลขนาดใหญ่มาก: หากมีตัวอย่างมากกว่าหลายพันตัวอย่าง SVR จะช้า มันสเกลได้ไม่ดีเท่าอัลกอริทึมอื่น เปลี่ยนไปใช้แบบจำลองที่เหมาะกับข้อมูลขนาดใหญ่กว่า เช่น เกรเดียนต์บูสต์ติ้งหรือโครงข่ายประสาทเทียม
ควรทราบด้วยว่าการทำทั้งสี่ข้อนี้ให้ถูกต้องไม่ได้รับประกันว่าแบบจำลองจะยอดเยี่ยม แต่การทำผิดเพียงข้อใดข้อหนึ่งแทบจะรับประกันผลลัพธ์ที่แย่
โดยสรุป โปรดจำไว้ว่า SVR แก้ปัญหาที่ต่างจากรีเกรสชันมาตรฐาน แทนที่จะทำให้ข้อผิดพลาดทุกตัวน้อยที่สุด มันจะฟิตฟังก์ชันภายในระยะขอบและมองข้ามสัญญาณรบกวนที่อยู่ภายใน — ซึ่งนี่แหละที่ทำให้มีประโยชน์เมื่อข้อมูลไม่สะอาดหรือไม่เป็นเส้นตรงสมบูรณ์แบบ
มันไม่เป็นที่รู้จักในด้านความเร็วหรือความเรียบง่าย แต่มีความทนทาน หากข้อมูลมีความสัมพันธ์ไม่เชิงเส้นและมี outliers ที่ไม่ต้องการโมเดล SVR จะช่วยให้โฟกัสที่โครงสร้างแทนการไล่ตามทุกจุดข้อมูล
เพียงอย่าลืมปรับสเกลฟีเจอร์ ปรับแต่งพารามิเตอร์ เลือกเคอร์เนลที่เหมาะสม และคุมปริมาณข้อมูลให้เหมาะ หากทำถูกต้อง SVR จะให้แบบจำลองที่ทนทานซึ่งไม่น่าล้มเหลวในโปรดักชัน
SVR เป็นเพียงหนึ่งในเครื่องมือที่นักวิทยาศาสตร์ข้อมูลควรรู้ ลงทะเบียนในหลักสูตร Machine Learning Engineer ของเราเพื่อเรียนรู้อื่น ๆ และเตรียมความพร้อมสำหรับงานในปี 2026
เรียนกับ DataCamp
Tracks
Courses
Courses