
Leerpad
Begeleid machine learning in Python
25 Hr
Standaard regressiemethoden minimaliseren de totale fout over alle datapunten. Dat betekent dat elke residu, hoe klein ook, het model in een bepaalde richting trekt. Het resultaat is een model dat gevoelig is voor ruis en uitschieters.
Een support vector regression-model daarentegen past een functie binnen een tolerantiemarge en negeert fouten die daarbinnen vallen. Die marge verandert het idee van optimalisatie. In plaats van elk datapunt te willen optimaliseren, richt SVR zich op de algehele structuur van de data, wat het, zoals ik je hoop te laten zien, robuust maakt op data uit de echte wereld.
Heb je nog een opfrisser nodig voordat we beginnen? Lees dan ons artikel Linear Regression in Python voor een introductie tot predictieve modellering.
Support Vector Regression is een regressiemethode gebouwd op dezelfde basis als Support Vector Machines (SVM), een klasse modellen die oorspronkelijk is ontworpen voor classificatietaken zoals spamdetectie of beeldherkenning.
Het kernidee is makkelijk te begrijpen: in plaats van elke predictiefout te minimaliseren, past SVR een functie met een tolerantietube eromheen. Fouten binnen die marge tellen niet mee. Het model focust op de algehele fit, niet op het corrigeren van elke kleine afwijking.
Dat is wat SVR onderscheidt van de meeste andere regressiemodellen.
Standaard regressiemethoden behandelen elk residu als een signaal. SVR ziet de meeste als ruis. Het resultaat is een model dat minder bezig is met precies goed zitten op elk punt en meer met het goed vatten van de onderliggende datastructuur.
Centraal in SVR staat de epsilon-tube: een tolerantiemarge die zich aan beide kanten om de passende functie wikkelt.
Elk datapunt binnen de tube geldt als dicht genoeg. SVR negeert die punten bij het fitten van het model. Alleen de punten buiten de tube doen ertoe, want die vormen daadwerkelijk de beslissingsgrens.
Voorbeeld van de epsilon-tube
Zo kun je het interpreteren:
Dit onderscheidt SVR van standaard regressie. Bij lineaire regressie trekt elk datapunt aan het model - ook de ruis. Bij SVR zijn de meeste punten irrelevant. Het resultaat is een fit die wordt gevormd door een goede algehele structuur.
SVR probeert twee tegengestelde doelen tegelijk te vervullen.
Het eerste is het model zo vlak mogelijk houden. Een vlakkere functie is eenvoudiger, en eenvoudigere modellen generaliseren meestal beter naar nieuwe data. Het tweede is het minimaliseren van fouten op punten buiten de epsilon-tube - de punten die SVR niet kan negeren.
Deze twee doelen trekken in tegenovergestelde richtingen, en daar komt de regularisatieparameter C in beeld. Die bepaalt hoeveel gewicht SVR geeft aan fouten buiten de tube ten opzichte van modelsimpliciteit:
Je ruilt altijd modelsimpliciteit in tegen fouttolerantie. De juiste waarde voor C hangt af van je data en van hoeveel ruis je verwacht. In beide richtingen miszitten verlaagt de prestaties van je model op nieuwe data.
Het is een optimalisatieprobleem dat iteratief kan worden opgelost, dus niets om je zorgen over te maken.
Bij SVR doen alleen de datapunten die buiten de epsilon-tube vallen er echt toe.
Dat zijn de support vectors: de datapunten die voorbij de marge liggen en de passende functie vormen. Alles binnen de tube wordt tijdens het trainen genegeerd. Het model "ziet" die punten in feite niet.
Support vectors
Het nuttige neveneffect hiervan is sparsity. In de praktijk wordt slechts een kleine subset van je trainingsdata support vector. De rest draagt niets bij aan het uiteindelijke model, wat SVR geheugen-efficiënt en snel maakt om te evalueren zodra het getraind is, omdat voorspellingen alleen afhangen van die paar invloedrijke punten.
SVR is niet beperkt tot rechte lijnen. Het kan niet-lineaire relaties aan via een techniek die de kernel trick heet.
In plaats van een functie te fitten in de oorspronkelijke inputruimte, projecteert SVR de data naar een ruimte met hogere dimensie waar een lineaire fit mogelijk wordt. Die lineaire fit in de hogerdimensionale ruimte vertaalt terug naar een niet-lineaire curve in je oorspronkelijke data.
De twee meest gebruikte kernels zijn:
Welke kernel je kiest, hangt af van je data. RBF is een goed startpunt als je het niet zeker weet.
Het verschil komt neer op wat elk model probeert te doen.
Lineaire regressie minimaliseert de totale fout over elk datapunt. Elk residu telt, hoe klein ook. Als je het model van koers trekt met een ruispunt, verschuift de hele fit om te compenseren.
SVR negeert fouten binnen de epsilon-tube. Het reageert alleen op punten die buiten de marge vallen - en zelfs dan bepaalt C hoe sterk. Het model optimaliseert voor structuur, niet voor nauwkeurigheid op elk individueel punt.
Dat verschil maakt SVR robuuster voor uitschieters. Een enkel ruispunt stuurt de fit niet zoals bij lineaire regressie, omdat SVR dat punt überhaupt niet probeerde na te jagen.
Hier zijn alle verschillen:

Lineaire regressie vergeleken met SVR
SVR heeft drie parameters die je moet begrijpen voordat je het model gaat optimaliseren.
Epsilon bepaalt de breedte van de tolerantiemarge rond de passende functie. Een grotere ε betekent een bredere tube - meer punten worden genegeerd en het model wordt eenvoudiger. Een kleinere ε vernauwt de tube en dwingt het model dichter op de data te passen.
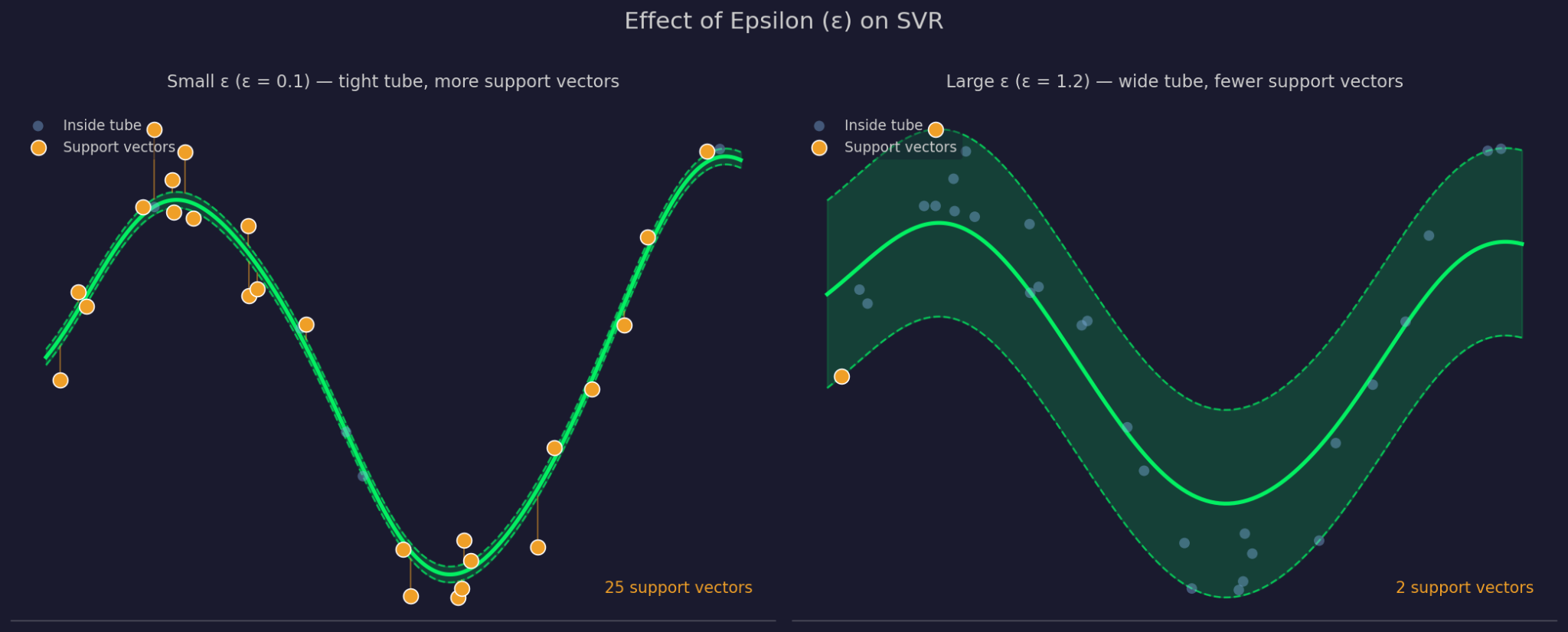
Kleine versus grote epsilon
C bepaalt hoeveel SVR fouten op punten buiten de tube bestraft. Een hoge C betekent dat het model die fouten serieus neemt en strakker past. Een lage C betekent dat het model meer schendingen accepteert in ruil voor een eenvoudigere, vlakkere functie. C en ε werken samen, want het wijzigen van de ene beïnvloedt hoe de andere zich in de praktijk gedraagt.
Kleine versus grote C
De kernel bepaalt hoe SVR niet-lineaire patronen verwerkt. RBF is de meest gebruikte keuze en werkt goed als standaard. Polynomiale kernels zijn handig voor specifieke bochtvormen. Lineaire kernels reduceren SVR tot een marge-gebaseerde lineaire regressie, wat nuttig kan zijn als je data al netjes is.
SVR goed laten werken draait om een paar stappen en randvoorwaarden. Ik laat je zien welke dat zijn.
Dit is de typische workflow:
Schaal je data: SVR is gevoelig voor de schaal van features. Als je features op verschillende schalen staan, gedraagt het model zich niet zoals verwacht. Gebruik StandardScaler op zowel X als y vóór het fitten
Kies een kernel: RBF is de juiste standaard voor de meeste problemen. Schakel over naar polynomiaal als je een specifieke reden hebt om te geloven dat de relatie die vorm volgt
Stel je parameters af: Stel C, epsilon en gamma in vóór het fitten. Grid search of cross-validatie zijn hier de standaardaanpakken
Fit het model: Roep .fit() aan op de geschaalde trainingsdata. Zodra het getraind is, transformeer je je voorspellingen terug naar de oorspronkelijke schaal
Hier is een volledig voorbeeld met scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE op de testset
Een paar dingen om op te letten in deze code. Ten eerste wordt StandardScaler afzonderlijk toegepast op zowel X als y. Alleen de features schalen is een veelgemaakte fout die tot slechte resultaten met SVR leidt. Ten tweede worden voorspellingen aan het eind teruggetransformeerd naar de oorspronkelijke schaal voordat ze worden geëvalueerd.
De twee onderstaande grafieken laten zien hoe het gefitte model eruitziet. De eerste toont de SVR-curve met de epsilon-tube over de trainings- en testdata:
Epsilon-tube over de trainings- en testdata
De tweede vergelijkt voorspelde met werkelijke waarden op de testset:
Voorspelde versus werkelijke waarden
Punten dicht bij de diagonaal betekenen dat het model goed voorspelt.
SVR heeft een specifieke set sterke punten die het de juiste tool maken in de juiste situatie. Evenzo heeft het zwaktes die het in andere gevallen ongeschikt maken.
SVR werkt het best onder specifieke voorwaarden. Je gebruikt SVR wanneer:
Vermijd SVR wanneer:
Als je dataset groot en ruisig is, zijn gradient boosting-methoden het eerst het bekijken waard. SVR is geweldig als je schone, middelgrote data hebt met structuur die eenvoudigere modellen niet goed kunnen fitten.
De meeste problemen met SVR komen neer op dezelfde set fouten - behandel dit dus als een spiekbriefje van wat je niet moet doen.
Je features niet schalen. SVR is een op afstanden gebaseerd algoritme, wat betekent dat ongeschaalde features het model domineren. Pas altijd StandardScaler toe op zowel X als y vóór het fitten.
Epsilon verkeerd begrijpen. Epsilon is veruit de belangrijkste parameter. Te groot en je model onderfit omdat het te veel negeert. Te klein en het gedraagt zich als standaard regressie, waarbij het elk datapunt achterna zit. Doe altijd een grid search om te zien wat het beste presteert op je testset.
Parameters niet afstemmen. SVR met standaardparameters draaien en goede resultaten verwachten werkt zelden - net als bij de meeste machinelearningmodellen. C, epsilon en gamma moeten samen worden afgestemd. Gebruik grid search met cross-validatie.
SVR gebruiken op zeer grote datasets. Heb je meer dan een paar duizend samples, dan is SVR traag. Het schaalt simpelweg niet zoals andere algoritmen. Schakel over naar een model dat beter met grote datasets omgaat, zoals gradient boosting of een neuraal netwerk.
Het is ook belangrijk om te beseffen dat deze vier dingen goed doen geen geweldig model garandeert, maar er één verkeerd doen vrijwel zeker een slecht model oplevert.
Onthoud tot slot dat SVR een ander probleem oplost dan standaard regressie. In plaats van elke fout te minimaliseren, past het een functie binnen een marge en negeert het de ruis die daarbinnen valt - precies wat het nuttig maakt wanneer je data niet schoon of perfect lineair is.
Het staat niet bekend om zijn snelheid of eenvoud. Maar het is robuust. Als je data niet-lineaire relaties en uitschieters heeft die je niet wilt modelleren, geeft SVR je een manier om je op structuur te richten in plaats van elk datapunt achterna te zitten.
Onthoud wel: schaal je features, stel je parameters af, kies de juiste kernel en wees terughoudend met de hoeveelheid data. Als je dat goed doet, levert SVR je een robuust model op dat waarschijnlijk niet zal falen in productie.
SVR is slechts één tool die elke data scientist moet kennen. Schrijf je in voor ons Machine Learning Engineer-traject om de andere te leren en in 2026 klaar te zijn voor de arbeidsmarkt.
Leer met DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
