
Programa
Aprendizado de máquina supervisionado em Python
25 h
Métodos tradicionais de regressão minimizam o erro total em todos os pontos de dados. Isso significa que todo resíduo, por menor que seja, puxa o modelo em alguma direção. Como resultado, você acaba com um modelo sensível a ruídos e outliers.
Já a Support Vector Regression, por outro lado, ajusta uma função dentro de uma margem de tolerância e ignora os erros que ficam dentro dela. Essa margem muda a lógica de otimização. Em vez de tentar otimizar cada ponto, a SVR foca na estrutura geral dos dados, o que a torna, como espero mostrar, robusta em dados do mundo real.
Se você precisa de um aquecimento antes de começar, leia nosso artigo Linear Regression in Python para uma introdução à modelagem preditiva.
Support Vector Regression é um método de regressão construído sobre a mesma base das Support Vector Machines (SVM), uma classe de modelos originalmente criada para tarefas de classificação, como detecção de spam ou reconhecimento de imagens.
A ideia central é simples: em vez de tentar minimizar todo erro de previsão, a SVR ajusta uma função permitindo uma margem de tolerância ao redor dela. Os erros que ficam dentro dessa margem não contam. O modelo foca em acertar o ajuste global, sem perseguir cada pequena variação.
É isso que diferencia a SVR da maioria dos outros modelos de regressão.
Métodos tradicionais tratam todo resíduo como sinal. A SVR trata a maioria deles como ruído. Assim, você acaba com um modelo menos preocupado em acertar exatamente cada ponto e mais em capturar a estrutura subjacente dos dados.
No centro da SVR está o chamado tubo epsilon — uma margem de tolerância que envolve a função ajustada nos dois lados.
Qualquer ponto que caia dentro do tubo é considerado próximo o suficiente. A SVR ignora esses pontos ao ajustar o modelo. Só os pontos fora do tubo importam, pois são eles que de fato moldam a fronteira de decisão.
Exemplo de tubo epsilon
Veja como interpretar:
É isso que separa a SVR da regressão linear. Na regressão linear, todo ponto puxa o modelo — inclusive os ruidosos. Na SVR, a maioria dos pontos é irrelevante. O resultado é um ajuste guiado por boa estrutura geral.
A SVR tenta equilibrar duas metas ao mesmo tempo.
A primeira é manter o modelo o mais "plano" possível. Funções mais planas são mais simples, e modelos simples tendem a generalizar melhor. A segunda é minimizar os erros nos pontos fora do tubo epsilon — aqueles que a SVR não pode ignorar.
Essas metas puxam em direções opostas, e é aí que entra o parâmetro de regularização C. Ele controla o peso dado aos erros fora do tubo em relação à simplicidade do modelo:
Você sempre estará trocando simplicidade do modelo por tolerância a erro. O valor certo de C depende dos dados e do nível de ruído esperado. Errar para qualquer lado reduz o desempenho em novos dados.
É um problema de otimização resolvido de forma iterativa, então não é motivo de preocupação.
Na SVR, apenas os pontos que ficam fora do tubo epsilon realmente importam.
Eles são os vetores de suporte — os pontos que ultrapassam a margem e moldam a função ajustada. Tudo que está dentro do tubo é ignorado no treino. O modelo nunca "vê" esses pontos de forma relevante.
Vetores de suporte
O efeito colateral positivo disso é a esparsidade. Na prática, apenas um subconjunto pequeno do seu treino vira vetor de suporte. O restante não contribui para o modelo final, o que torna a SVR eficiente em memória e rápida para avaliar depois de treinada, já que as previsões dependem só desses poucos pontos influentes.
A SVR não se limita a ajustar retas. Ela lida com relações não lineares por meio da técnica chamada kernel trick.
Em vez de ajustar a função no espaço original, a SVR projeta os dados em um espaço de maior dimensão onde um ajuste linear se torna possível. Esse ajuste linear no espaço de maior dimensão se traduz em uma curva não linear no espaço original.
Os kernels mais comuns são:
A escolha do kernel depende dos seus dados. Quando estiver em dúvida, comece com RBF.
A diferença está no objetivo de cada modelo.
Regressão linear minimiza o erro total em cada ponto de dados. Todo resíduo conta, por menor que seja. Se um ponto ruidoso desvia o modelo, o ajuste inteiro se desloca para compensar.
A SVR ignora erros dentro do tubo epsilon. Ela só reage aos pontos que caem fora da margem — e mesmo assim, o C controla o quanto. O modelo otimiza a estrutura, não a precisão em cada ponto individual.
Essa diferença torna a SVR mais robusta a outliers. Um único ponto ruidoso não distorce o ajuste como na regressão linear, porque a SVR nunca tentou persegui-lo.
Confira todas as diferenças:

Regressão linear comparada à SVR
A SVR tem três parâmetros que você precisa entender antes de otimizar o modelo.
Epsilon define a largura da margem de tolerância ao redor da função ajustada. Um ε maior significa um tubo mais largo — mais pontos são ignorados e o modelo fica mais simples. Um ε menor estreita o tubo e força o modelo a se ajustar mais de perto aos dados.
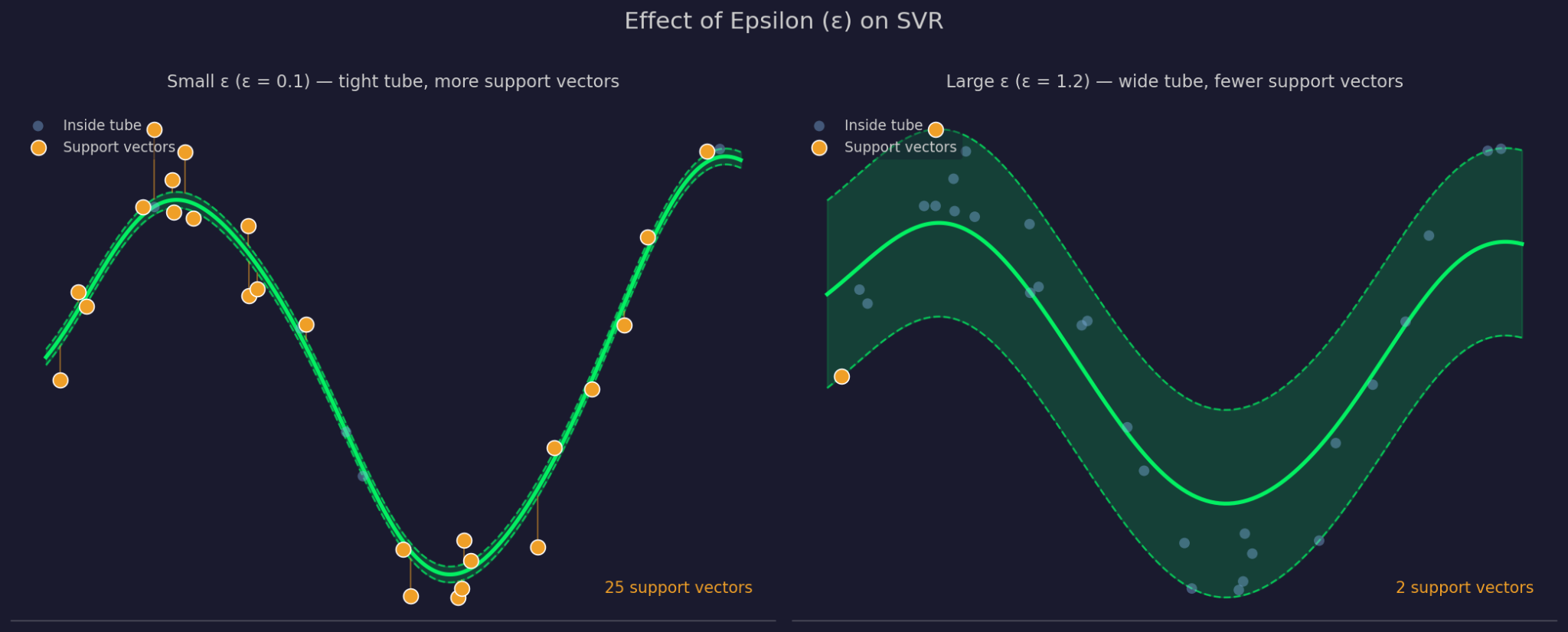
Epsilon pequeno vs. grande
C controla o quanto a SVR penaliza os erros nos pontos fora do tubo. C alto faz o modelo levar esses erros mais a sério e ajustar com mais rigidez. C baixo permite aceitar mais violações em troca de uma função mais simples e plana. C e ε trabalham juntos, já que alterar um afeta o comportamento do outro na prática.
C pequeno vs. grande
O kernel determina como a SVR lida com padrões não lineares. RBF é a escolha mais comum e funciona bem como padrão. Kernels polinomiais são úteis para formatos de curva específicos. O kernel linear reduz a SVR a uma regressão linear baseada em margem, útil quando os dados já são bem comportados.
Fazer a SVR funcionar bem envolve cumprir alguns passos e pré-requisitos. Veja os principais.
O fluxo típico é:
Faça o scaling dos dados: a SVR é sensível à escala das features. Se suas variáveis estiverem em escalas diferentes, o modelo não se comportará como esperado. Use StandardScaler em X e y antes de ajustar
Escolha um kernel: RBF é o padrão certo para a maioria dos problemas. Troque para polinomial se houver razão específica para acreditar naquele formato
Faça a calibragem dos parâmetros: defina C, epsilon e gamma antes de treinar. Grid search ou cross-validation são as abordagens padrão
Ajuste o modelo: chame .fit() nos dados de treino escalados. Depois de treinado, faça a transformação inversa das previsões para voltar à escala original
Aqui vai um exemplo completo usando scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE no conjunto de teste
Alguns pontos de atenção no código. Primeiro, o StandardScaler é aplicado separadamente em X e y. Escalar apenas as features é um erro comum que leva a resultados ruins com SVR. Segundo, as previsões passam por transformação inversa no final para voltar à escala original antes da avaliação.
Os dois gráficos abaixo mostram como fica o modelo ajustado. O primeiro mostra a curva da SVR com o tubo epsilon sobre os dados de treino e teste:
Tubo epsilon sobre os dados de treino e teste
O segundo compara valores previstos versus reais no conjunto de teste:
Previstos versus reais
Pontos próximos da diagonal indicam boas previsões.
A SVR tem um conjunto específico de pontos fortes que a tornam a ferramenta certa na situação certa. Do mesmo modo, há limitações que a tornam inadequada em outros cenários.
A SVR funciona melhor em um conjunto específico de condições. Use SVR quando:
Evite SVR quando:
Se seu dataset é grande e ruidoso, métodos de gradient boosting valem a pena ser avaliados primeiro. A SVR brilha quando você tem dados limpos, de tamanho moderado, com estrutura que modelos mais simples não capturam bem.
A maioria dos problemas com SVR se resume ao mesmo conjunto de deslizes — então trate esta lista como um guia do que evitar.
Não escalar suas features. A SVR é baseada em distâncias, então features não escaladas dominam o modelo. Sempre aplique StandardScaler tanto em X quanto em y antes de treinar.
Entender mal o epsilon. Epsilon é, de longe, o parâmetro mais importante. Muito grande e seu modelo underfita por ignorar demais. Muito pequeno e ele passa a se comportar como a regressão tradicional, perseguindo cada ponto. Sempre faça grid search para ver o que performa melhor no seu conjunto de teste.
Pular a calibração de parâmetros. Rodar a SVR com valores padrão e esperar bons resultados raramente funciona — como na maioria dos modelos de machine learning. C, epsilon e gamma precisam ser ajustados em conjunto. Use grid search com cross-validation.
Usar SVR em datasets muito grandes. Se você tem mais que alguns milhares de amostras, a SVR ficará lenta. Ela simplesmente não escala como outros algoritmos. Migre para um modelo mais adequado a grandes volumes, como gradient boosting ou uma rede neural.
Importante: acertar esses quatro pontos não garante um modelo excelente, mas errar qualquer um deles quase certamente garante um modelo ruim.
Para concluir, lembre-se de que a SVR resolve um problema diferente da regressão tradicional. Em vez de minimizar cada erro, ela ajusta uma função dentro de uma margem e ignora o ruído que fica ali — exatamente o que a torna útil quando seus dados não são limpos ou perfeitamente lineares.
Ela não é conhecida por sua velocidade ou simplicidade. Mas é robusta. Se seus dados têm relações não lineares e outliers que você não quer modelar, a SVR permite focar na estrutura em vez de perseguir cada ponto.
Lembre-se de escalar as features, calibrar os parâmetros, escolher o kernel certo e ser conservador com a quantidade de dados. Fazendo isso, a SVR tende a gerar um modelo robusto e pouco propenso a falhas em produção.
SVR é apenas uma das ferramentas que todo cientista de dados precisa conhecer. Inscreva-se na nossa trilha Machine Learning Engineer para aprender as demais e ficar pronto para o mercado em 2026.
Aprenda com a DataCamp
Programa
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Zoumana Keita
Tutorial
Somil Asthana
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team
Tutorial
DataCamp Team

