Track
पर्यवेक्षित मशीन लर्निंग में Python
25 घंटा
मानक रिग्रेशन विधियाँ सभी डेटा बिंदुओं पर कुल त्रुटि को न्यूनतम करती हैं। इसका मतलब है कि हर अवशिष्ट, चाहे कितना भी छोटा हो, मॉडल को किसी न किसी दिशा में खींचता है। नतीजतन, आपके पास एक ऐसा मॉडल रह जाता है जो शोर और आउट्लायर के प्रति संवेदनशील होता है।
दूसरी ओर, सपोर्ट वेक्टर रिग्रेशन मॉडल एक सहनशीलता मार्जिन के भीतर एक फ़ंक्शन फिट करता है और उस मार्जिन के अंदर आने वाली त्रुटियों को अनदेखा करता है। यह मार्जिन अनुकूलन की धारणा को बदल देता है। हर डेटा बिंदु को अनुकूलित करने की कोशिश करने के बजाय, SVR डेटा की समग्र संरचना पर ध्यान देता है, जो इसे, जैसा कि मैं आपको दिखाना चाहता हूँ, वास्तविक दुनिया के डेटा पर मजबूत बनाता है।
यदि आपको शुरुआत से पहले एक प्राइमर चाहिए, तो भविष्यवाणी मॉडलिंग का परिचय पाने के लिए हमारा Python में लीनियर रिग्रेशन आलेख पढ़ें।
सपोर्ट वेक्टर रिग्रेशन, सपोर्ट वेक्टर मशीन (SVM) की ही बुनियाद पर बना एक रिग्रेशन तरीका है, जो मूल रूप से स्पैम डिटेक्शन या इमेज रिकग्निशन जैसे वर्गीकरण कार्यों के लिए डिज़ाइन किए गए मॉडलों का वर्ग है।
मुख्य विचार समझना आसान है — हर भविष्यवाणी त्रुटि को न्यूनतम करने की कोशिश करने के बजाय, SVR एक फ़ंक्शन फिट करता है और उसके चारों ओर एक सहनशीलता मार्जिन की अनुमति देता है। उस मार्जिन के भीतर आने वाली त्रुटियाँ गिनी ही नहीं जातीं। मॉडल का ध्यान समग्र फिट पर होता है, न कि हर छोटे विचलन को सुधारने पर।
यही बात SVR को अधिकांश अन्य रिग्रेशन मॉडलों से अलग करती है।
मानक रिग्रेशन विधियाँ हर अवशिष्ट को संकेत मानती हैं। SVR उनमें से अधिकांश को शोर मानता है। नतीजतन, आपका मॉडल हर बिंदु पर बिल्कुल सही होने की कम चिंता करता है और डेटा की अंतर्निहित संरचना को सही पाने पर अधिक केंद्रित होता है।
SVR के केंद्र में एप्सिलॉन ट्यूब नाम की चीज़ होती है — सहनशीलता का एक मार्जिन जो फिट किए गए फ़ंक्शन के दोनों ओर लिपटा रहता है।
जो भी डेटा बिंदु ट्यूब के अंदर आता है, उसे पर्याप्त रूप से निकट माना जाता है। मॉडल फिट करते समय SVR उन बिंदुओं को अनदेखा करता है। केवल ट्यूब के बाहर वाले बिंदु मायने रखते हैं, क्योंकि वही निर्णय सीमा को वास्तव में आकार देते हैं।
एप्सिलॉन ट्यूब का उदाहरण
इसे आप ऐसे समझ सकते हैं:
यही बात SVR को मानक रिग्रेशन से अलग करती है। लीनियर रिग्रेशन में, हर डेटा बिंदु मॉडल को खींचता है — शोर वाले भी। SVR में, ज्यादातर बिंदु अप्रासंगिक होते हैं। नतीजा एक ऐसा फिट होता है जो समग्र रूप से अच्छी संरचना से बनता है।
SVR के सामने एक साथ संतुष्ट करने के लिए दो परस्पर-विरोधी लक्ष्य होते हैं।
पहला, मॉडल को यथासंभव सपाट रखना। सपाट फ़ंक्शन सरल होता है, और सरल मॉडल आमतौर पर नए डेटा पर बेहतर सामान्यीकरण करते हैं। दूसरा, एप्सिलॉन ट्यूब के बाहर वाले बिंदुओं पर त्रुटियों को न्यूनतम करना — वे जिन्हें SVR अनदेखा नहीं कर सकता।
ये दोनों लक्ष्य विपरीत दिशाओं में खींचते हैं, और यहीं नियमितीकरण पैरामीटर C काम आता है। यह नियंत्रित करता है कि मॉडल सादगी की तुलना में ट्यूब के बाहर की त्रुटियों को SVR कितनी वरीयता देता है:
आप हमेशा मॉडल सादगी और त्रुटि सहनशीलता के बीच अदला-बदली कर रहे होते हैं। C का सही मान आपके डेटा और अपेक्षित शोर पर निर्भर करता है। किसी भी दिशा में गलत चुनाव नए डेटा पर प्रदर्शन घटा देगा।
यह एक अनुकूलन समस्या है जिसे क्रमिक रूप से हल किया जा सकता है, इसलिए चिंता की बात नहीं है।
SVR में, केवल वे डेटा बिंदु मायने रखते हैं जो एप्सिलॉन ट्यूब के बाहर आते हैं।
इन्हीं को सपोर्ट वेक्टर कहा जाता है — वे बिंदु जो मार्जिन से परे होते हैं और फिटेड फ़ंक्शन को आकार देते हैं। ट्यूब के अंदर की हर चीज़ को प्रशिक्षण के दौरान अनदेखा किया जाता है। मॉडल वास्तव में उन बिंदुओं को किसी सार्थक तरीके से “देखता” ही नहीं।
सपोर्ट वेक्टर
इसका एक उपयोगी पार्श्व-प्रभाव स्पार्सिटी है। व्यवहार में, आपके प्रशिक्षण डेटा का केवल एक छोटा उपसमुच्चय ही सपोर्ट वेक्टर बनता है। बाकी का अंतिम मॉडल में कोई योगदान नहीं होता, जिससे प्रशिक्षण के बाद SVR मेमोरी-कुशल और मूल्यांकन में तेज़ हो जाता है, क्योंकि पूर्वानुमान केवल उन्हीं कुछ प्रभावशाली बिंदुओं पर निर्भर करते हैं।
SVR केवल सीधी रेखाएँ फिट करने तक सीमित नहीं है। यह कर्नेल ट्रिक नामक तकनीक के माध्यम से गैर-रेखीय संबंधों को संभाल सकता है।
तो, मूल इनपुट स्पेस में फ़ंक्शन फिट करने के बजाय, SVR डेटा को एक उच्च-आयामी स्पेस में मैप करता है, जहाँ रैखिक फिट संभव हो जाता है। उच्च-आयामी स्पेस में वह रैखिक फिट आपके मूल डेटा में एक गैर-रेखीय वक्र के रूप में अनुवादित हो जाता है।
दो सबसे आम कर्नेल जिन्हें आप उपयोग करेंगे, ये हैं:
कौन सा कर्नेल चुनना है यह आपके डेटा पर निर्भर करता है। अनिश्चित होने पर RBF अच्छा शुरुआती बिंदु है।
फर्क इस बात पर आकर टिकता है कि हर मॉडल क्या करने की कोशिश कर रहा है।
लीनियर रिग्रेशन हर डेटा बिंदु पर कुल त्रुटि को न्यूनतम करता है। हर अवशिष्ट गिना जाता है, चाहे कितना ही छोटा क्यों न हो। यदि कोई शोर वाला बिंदु मॉडल को पथभ्रष्ट करता है, तो पूरा फिट उसकी भरपाई के लिए खिसक जाता है।
SVR एप्सिलॉन ट्यूब के भीतर की त्रुटियों को अनदेखा करता है। यह केवल उन बिंदुओं पर प्रतिक्रिया देता है जो मार्जिन के बाहर आते हैं — और तब भी, C यह नियंत्रित करता है कि कितनी तीव्रता से। मॉडल संरचना के लिए अनुकूलन करता है, न कि हर व्यक्तिगत बिंदु पर सटीकता के लिए।
यह अंतर SVR को आउट्लायर के प्रति अधिक मज़बूत बनाता है। एक अकेला शोरयुक्त बिंदु फिट को वैसे नहीं बिगाड़ेगा जैसा लीनियर रिग्रेशन में हो सकता है, क्योंकि SVR ने शुरुआत से ही उसे पकड़ने की कोशिश नहीं की थी।
यह हैं सभी अंतर:

लीनियर रिग्रेशन बनाम SVR
SVR में तीन पैरामीटर होते हैं जिन्हें मॉडल अनुकूलित करने से पहले समझना ज़रूरी है।
एप्सिलॉन फिटेड फ़ंक्शन के चारों ओर सहनशीलता मार्जिन की चौड़ाई परिभाषित करता है। बड़ा ε मतलब चौड़ी ट्यूब — ज़्यादा बिंदु अनदेखा होंगे और मॉडल सरल होगा। छोटा ε ट्यूब को कस देता है और मॉडल को डेटा के अधिक पास फिट होने के लिए बाध्य करता है।
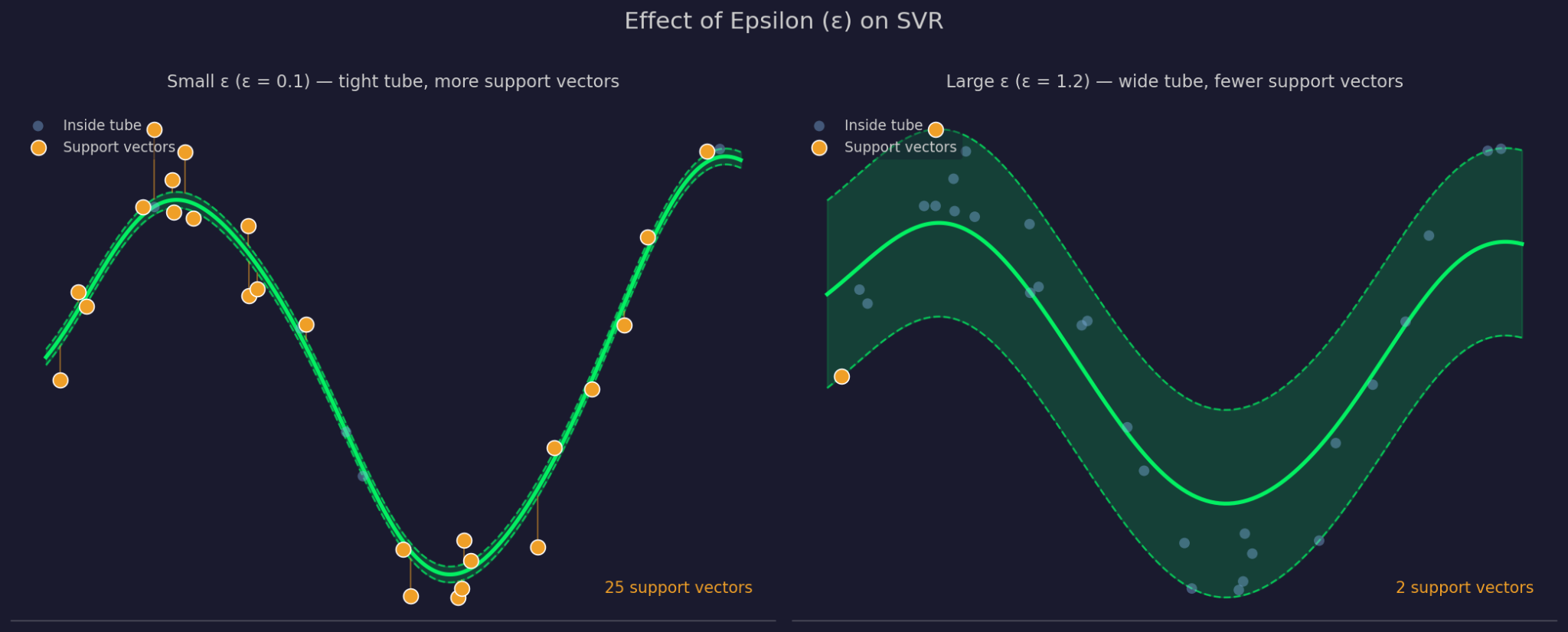
छोटा बनाम बड़ा एप्सिलॉन
C नियंत्रित करता है कि SVR ट्यूब के बाहर वाले बिंदुओं पर त्रुटियों को कितनी सख्ती से दंडित करता है। उच्च C का मतलब है कि मॉडल उन त्रुटियों को गंभीरता से लेता है और अधिक कसे हुए तरीके से फिट करता है। कम C का मतलब है कि मॉडल एक सरल, सपाट फ़ंक्शन के बदले अधिक उल्लंघन स्वीकार करता है। C और ε साथ मिलकर काम करते हैं, क्योंकि एक को बदलने से व्यवहार में दूसरे पर असर पड़ता है।
छोटा बनाम बड़ा C
कर्नेल यह निर्धारित करता है कि SVR गैर-रेखीय पैटर्नों को कैसे संभालता है। RBF सबसे आम विकल्प है और डिफ़ॉल्ट के रूप में अच्छा काम करता है। पॉलीनॉमियल कर्नेल विशेष वक्र आकारों के लिए उपयोगी है। लीनियर कर्नेल SVR को मार्जिन-आधारित लीनियर रिग्रेशन में बदल देता है, जो तब उपयोगी हो सकता है जब आपका डेटा पहले से ही अच्छा-ख़ासा रैखिक हो।
SVR को अच्छी तरह काम कराने के लिए कुछ चरणों और पूर्वापेक्षाओं से गुजरना होता है। आइए देखें ये क्या हैं।
यह है सामान्य कार्यप्रवाह:
अपने डेटा को स्केल करें: SVR फीचर स्केल के प्रति संवेदनशील है। यदि आपके फीचर अलग-अलग स्केल पर हैं, तो मॉडल अपेक्षित तरीके से व्यवहार नहीं करेगा। फिट करने से पहले X और y दोनों पर StandardScaler का उपयोग करें
कर्नेल चुनें: अधिकांश समस्याओं के लिए RBF सही डिफ़ॉल्ट है। यदि आपके पास यह मानने का ठोस कारण है कि संबंध उस आकार का अनुसरण करता है, तो पॉलीनॉमियल पर स्विच करें
अपने पैरामीटर ट्यून करें: फिट करने से पहले C, epsilon और gamma सेट करें। यहाँ ग्रिड सर्च या क्रॉस-वैलिडेशन मानक तरीके हैं
मॉडल फिट करें: स्केल किए गए प्रशिक्षण डेटा पर .fit() कॉल करें। प्रशिक्षण के बाद, मूल्यांकन से पहले अपनी भविष्यवाणियों को मूल स्केल पर वापस लाने के लिए इनवर्स-ट्रांसफॉर्म करें
यहाँ scikit-learn का उपयोग करते हुए एक पूर्ण उदाहरण है:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
टेस्ट सेट पर RMSE
इस कोड में ध्यान देने लायक दो बातें हैं। पहली, StandardScaler को X और y दोनों पर अलग-अलग लागू किया गया है। केवल फीचर्स को स्केल करना एक आम गलती है जो SVR के साथ खराब परिणाम देती है। दूसरी, पूर्वानुमानों को अंत में इनवर्स-ट्रांसफॉर्म किया गया है ताकि मूल्यांकन से पहले उन्हें मूल स्केल पर वापस लाया जा सके।
नीचे दिए गए दो प्लॉट दिखाते हैं कि फिटेड मॉडल कैसा दिखता है। पहला प्रशिक्षण और टेस्ट डेटा पर एप्सिलॉन ट्यूब के साथ SVR वक्र दिखाता है:
प्रशिक्षण और टेस्ट डेटा पर एप्सिलॉन ट्यूब
दूसरा प्लॉट टेस्ट सेट पर पूर्वानुमानित बनाम वास्तविक मानों की तुलना करता है:
पूर्वानुमानित बनाम वास्तविक मान
विकर्ण के पास के बिंदु दर्शाते हैं कि मॉडल अच्छी भविष्यवाणी कर रहा है।
SVR की कुछ विशिष्ट ताकतें हैं जो इसे सही परिस्थिति में सही उपकरण बनाती हैं। इसी तरह, इसकी कुछ कमजोरियाँ भी हैं जो इसे अन्य परिस्थितियों में गलत चुनाव बना देती हैं।
SVR कुछ विशेष परिस्थितियों में सबसे अच्छा काम करता है। आपको SVR तब उपयोग करना चाहिए जब:
आपको SVR से बचना चाहिए जब:
यदि आपका डेटासेट बड़ा और शोरयुक्त है, तो ग्रेडिएंट बूस्टिंग तरीकों पर पहले नज़र डालना उचित है। जब आपके पास साफ-सुथरा, मध्यम आकार का डेटा हो और उसकी संरचना साधारण मॉडल अच्छी तरह फिट न कर पा रहे हों, तब SVR बेहतरीन काम करता है।
SVR से जुड़ी अधिकांश समस्याएँ एक ही सेट की गलतियों पर आ टिकती हैं — इसलिए इसे क्या न करना है की चीट शीट मानें।
फीचर स्केलिंग न करना। SVR दूरी-आधारित एल्गोरिद्म है, यानी अनस्केल्ड फीचर मॉडल पर हावी हो जाएँगे। फिट करने से पहले हमेशा X और y दोनों पर StandardScaler लागू करें।
एप्सिलॉन को गलत समझना। एप्सिलॉन अब तक का सबसे महत्वपूर्ण पैरामीटर है। बहुत बड़ा हुआ तो आपका मॉडल बहुत कुछ अनदेखा कर देगा और अंडरफिट करेगा। बहुत छोटा हुआ तो यह मानक रिग्रेशन जैसा व्यवहार करेगा, हर डेटा बिंदु के पीछे भागेगा। अपनी टेस्ट सेट पर कौन-सा सबसे अच्छा है देखने के लिए हमेशा ग्रिड सर्च करें।
पैरामीटर ट्यूनिंग को छोड़ देना। डिफ़ॉल्ट पैरामीटर के साथ SVR चलाना और अच्छे परिणाम की उम्मीद करना शायद ही काम करता है — जैसे अधिकांश मशीन लर्निंग मॉडलों में। C, एप्सिलॉन और गामा को साथ में ट्यून करने की ज़रूरत है। क्रॉस-वैलिडेशन के साथ ग्रिड सर्च का उपयोग करें।
बहुत बड़े डेटासेट पर SVR का उपयोग करना। यदि आपके पास कुछ हज़ार से अधिक नमूने हैं, तो SVR धीमा होगा। यह अन्य एल्गोरिद्म की तरह स्केल नहीं करता। ऐसे मॉडल पर स्विच करें जो बड़े डेटासेट के साथ बेहतर काम करते हैं, जैसे ग्रेडिएंट बूस्टिंग या न्यूरल नेटवर्क।
यह बात भी याद रखने योग्य है कि इन चार चीज़ों को सही करना एक बेहतरीन मॉडल की गारंटी नहीं देता, लेकिन इनमें से किसी एक को भी गलत करना लगभग निश्चित रूप से खराब मॉडल की गारंटी देता है।
अंत में याद रखें कि SVR मानक रिग्रेशन से अलग समस्या हल करता है। हर त्रुटि को न्यूनतम करने के बजाय, यह एक मार्जिन के भीतर फ़ंक्शन फिट करता है और उसके अंदर आने वाले शोर को अनदेखा करता है — यही उसे तब उपयोगी बनाता है जब आपका डेटा साफ़ या पूरी तरह रैखिक नहीं होता।
यह अपनी गति या सरलता के लिए प्रसिद्ध नहीं है। लेकिन यह मज़बूत है। यदि आपके डेटा में गैर-रेखीय संबंध और ऐसे आउट्लायर हैं जिन्हें आप मॉडल नहीं करना चाहते, तो SVR आपको संरचना पर ध्यान केंद्रित करने का तरीका देता है, हर डेटा बिंदु के पीछे भागने का नहीं।
बस ध्यान रखें कि अपने फीचर स्केल करें, पैरामीटर ट्यून करें, सही कर्नेल चुनें, और डेटा की मात्रा पर संयम रखें। यदि आप ये सही करते हैं, तो SVR आपको एक मज़बूत मॉडल देगा जो प्रोडक्शन में फेल होने की संभावना कम रखेगा।
SVR हर डेटा साइंटिस्ट के लिए जानने का सिर्फ एक उपकरण है। अन्य सीखने और 2026 में जॉब-रेडी होने के लिए हमारे Machine Learning Engineer ट्रैक में नामांकन करें।
DataCamp के साथ सीखें
Track
course
course