Track
Обучение с учителем на Python
25 ч
Стандартные методы регрессии минимизируют суммарную ошибку по всем точкам данных. Это означает, что каждый остаток, каким бы маленьким он ни был, тянет модель в какую-то сторону. В результате вы получаете модель, чувствительную к шуму и выбросам.
Модель регрессии опорных векторов, напротив, аппроксимирует функцию в пределах допусков и игнорирует ошибки, которые укладываются в этот допуск. Такой допуск меняет само понимание оптимизации. Вместо того чтобы подгонять каждый объект, SVR фокусируется на общей структуре данных, что, как я надеюсь показать, делает его устойчивым на данных из реального мира.
Если вам нужен краткий вводный материал перед началом, ознакомьтесь с нашей статьёй Линейная регрессия на Python — для введения в предиктивное моделирование.
Регрессия опорных векторов — это метод регрессии, основанный на той же идее, что и машины опорных векторов (SVM) — класс моделей, изначально разработанный для задач классификации, таких как обнаружение спама или распознавание изображений.
Ключевая идея проста: вместо минимизации каждой ошибки предсказания SVR подгоняет функцию, допуская вокруг неё некоторую погрешность. Ошибки, попадающие в этот допуск, не учитываются. Модель сосредоточена на общем качестве аппроксимации, а не на исправлении каждого малого отклонения.
Именно это отличает SVR от большинства других регрессионных моделей.
Стандартные методы регрессии воспринимают каждый остаток как сигнал. SVR считает большинство из них шумом. В итоге получается модель, которая меньше стремится к точному попаданию в каждую точку и больше — к правильному описанию базовой структуры данных.
В центре SVR — так называемая эпсилон-труба — допуск, обрамляющий аппроксимирующую функцию с обеих сторон.
Любая точка данных, попавшая внутрь трубы, считается достаточно близкой. SVR игнорирует такие точки при обучении модели. Значение имеют только точки вне трубы — именно они формируют границу решения.
Пример эпсилон-трубы
Вот как это интерпретировать:
В этом и заключается отличие SVR от стандартной регрессии. В линейной регрессии каждая точка тянет модель — включая шумные. В SVR большинство точек несущественны. Получается аппроксимация, основанная на общей хорошей структуре.
У SVR две конкурирующие цели, которые он пытается удовлетворить одновременно.
Первая — сделать модель как можно более «плоской». Более простые функции лучше обобщают на новые данные. Вторая — минимизировать ошибки на точках за пределами эпсилон-трубы — тех, которые SVR игнорировать не может.
Эти цели тянут в разные стороны, и здесь вступает в игру параметр регуляризации C. Он контролирует, насколько сильно SVR наказывает ошибки за пределами трубы по сравнению с простотой модели:
Вы всегда балансируете между простотой модели и допуском к ошибкам. Правильное значение C зависит от ваших данных и ожидаемого уровня шума. Ошибка в любую сторону снизит качество модели на новых данных.
Это задача оптимизации, которую можно решать итеративно, так что поводов для беспокойства нет.
В SVR фактически имеют значение только те точки данных, которые лежат вне эпсилон-трубы.
Это и есть опорные векторы — точки данных за пределами допуска, формирующие аппроксимирующую функцию. Всё, что внутри трубы, игнорируется при обучении. Модель «не видит» эти точки в сколь-либо значимом смысле.
Опорные векторы
Полезное следствие этого — разреженность. На практике лишь небольшая часть обучающих данных становится опорными векторами. Остальные ничем не участвуют в итоговой модели, что делает SVR экономичным по памяти и быстрым при применении: предсказания зависят только от нескольких влиятельных точек.
SVR не ограничивается прямыми линиями. Он справляется с нелинейными зависимостями благодаря приёму под названием kernel trick.
Вместо подгонки функции в исходном пространстве признаков SVR отображает данные в пространство большей размерности, где возможна линейная аппроксимация. Эта линейная аппроксимация в пространстве высокой размерности возвращается в виде нелинейной кривой в исходном пространстве.
Два наиболее распространённых ядра, которые вы будете использовать:
Выбор ядра зависит от ваших данных. Если не уверены, начните с RBF.
Всё упирается в то, что именно пытается сделать каждая модель.
Линейная регрессия минимизирует суммарную ошибку по всем точкам. Каждый остаток учитывается, каким бы малым он ни был. Если шумная точка «утащит» модель, вся аппроксимация сместится, чтобы это компенсировать.
SVR игнорирует ошибки внутри эпсилон-трубы. Он реагирует только на точки за пределами допуска — и даже тогда сила реакции регулируется C. Модель оптимизируется под структуру, а не под точность по каждой отдельной точке.
Эта разница делает SVR более устойчивым к выбросам. Одна шумная точка не испортит подгонку так, как в линейной регрессии, потому что SVR изначально не пытается «гнаться» за ней.
Все различия собраны здесь:

Сравнение линейной регрессии и SVR
В SVR есть три параметра, которые нужно понимать перед оптимизацией модели.
Эпсилон определяет ширину допуска вокруг аппроксимирующей функции. Большой ε — более широкая труба: больше точек игнорируется, модель упрощается. Малый ε сужает трубу и заставляет модель теснее подгоняться к данным.
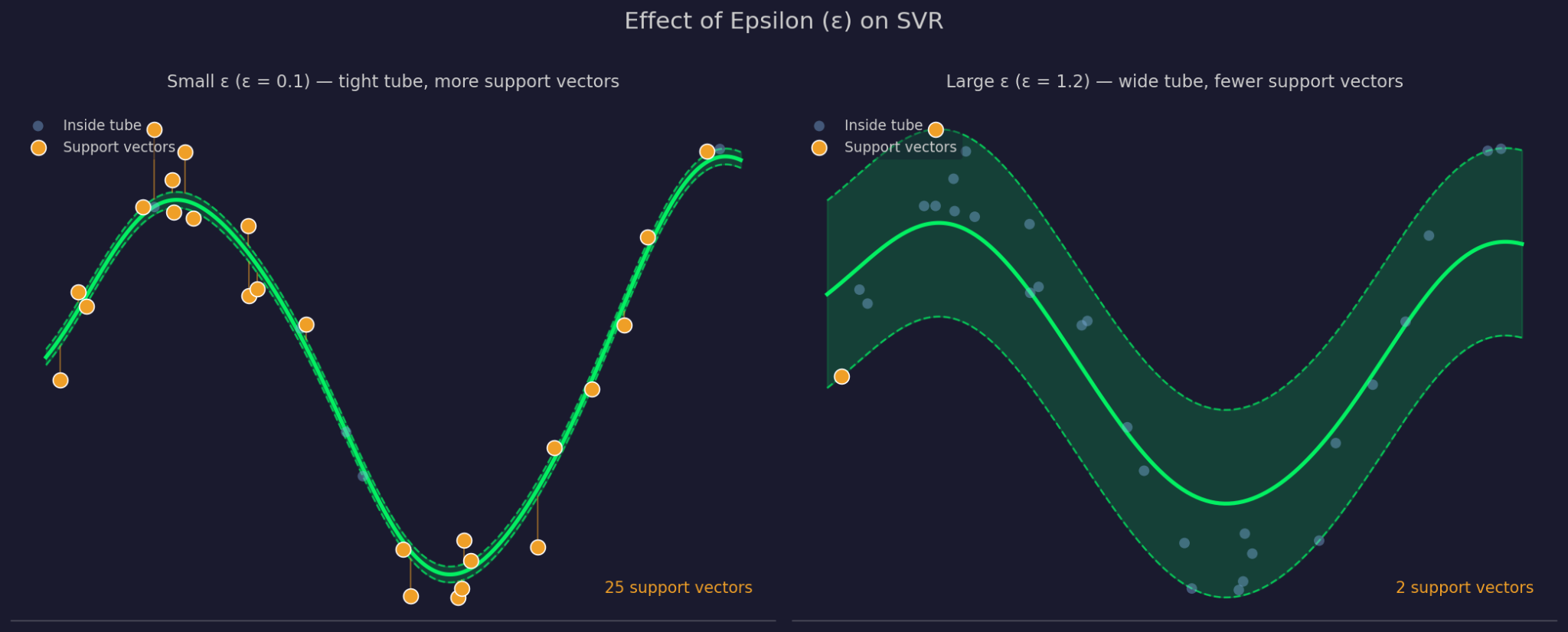
Малый и большой эпсилон
C определяет, насколько сильно SVR штрафует ошибки на точках за пределами трубы. Большой C — модель воспринимает эти ошибки всерьёз и подгоняется плотнее. Малый C — модель принимает больше нарушений в обмен на более простую, «плоскую» функцию. C и ε работают совместно, и изменение одного влияет на поведение другого на практике.
Малый и большой C
Ядро определяет, как SVR обрабатывает нелинейные закономерности. RBF — самый распространённый и хорошо работающий по умолчанию вариант. Полиномиальные ядра полезны для конкретных форм кривых. Линейные ядра сводят SVR к линейной регрессии с допуском, что пригодно, если ваши данные уже «хорошо себя ведут».
Чтобы SVR хорошо работал, нужно пройти через несколько шагов и предусловий. Покажу, какие именно.
Типичный рабочий процесс:
Масштабируйте данные: SVR чувствителен к масштабу признаков. Если признаки на разных шкалах, модель будет вести себя непредсказуемо. Применяйте StandardScaler как к X, так и к y перед обучением
Выберите ядро: RBF — подходящий вариант по умолчанию для большинства задач. Переключайтесь на полиномиальное, если есть конкретные основания полагать, что зависимость имеет такую форму
Настройте параметры: Задайте C, epsilon и gamma перед обучением. Сетки параметров (grid search) или кросс-валидация — стандартные подходы
Обучите модель: Вызовите .fit() на масштабированных обучающих данных. После обучения инвертируйте трансформацию предсказаний обратно к исходной шкале
Ниже — полный пример на scikit-learn:
import numpy as np
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate sample data
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 30))
y = 2.5 * np.sin(X * 0.8) + np.random.normal(0, 0.4, 30)
# Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features and target
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, 1))
X_test_scaled = scaler_X.transform(X_test.reshape(-1, 1))
y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
# Fit SVR
svr = SVR(kernel="rbf", C=2.0, epsilon=0.5, gamma=0.3)
svr.fit(X_train_scaled, y_train_scaled)
# Predict and inverse-transform
y_pred_scaled = svr.predict(X_test_scaled)
y_pred = scaler_y.inverse_transform(y_pred_scaled.reshape(-1, 1)).ravel()
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Test RMSE: {rmse:.3f}")
RMSE на тестовом наборе
Пара моментов, на которые стоит обратить внимание. Во-первых, StandardScaler применяется отдельно и к X, и к y. Масштабирование только признаков — частая ошибка, ведущая к плохим результатам с SVR. Во-вторых, предсказания в конце преобразуются обратно к исходной шкале перед оценкой.
Два графика ниже показывают, как выглядит обученная модель. Первый — кривая SVR с эпсилон-трубой на обучающих и тестовых данных:
Эпсилон-труба на обучающих и тестовых данных
Второй — сравнение предсказанных и фактических значений на тестовом наборе:
Предсказанные против фактических значений
Точки, близкие к диагонали, означают, что модель предсказывает хорошо.
У SVR есть набор сильных сторон, делающих его правильным выбором в одних ситуациях, и слабых — делающих его неподходящим в других.
SVR лучше всего работает при определённых условиях. Используйте SVR, когда:
Избегайте SVR, когда:
Если у вас большой и шумный набор данных, сначала присмотритесь к методам градиентного бустинга. SVR хорош, когда у вас чистые данные среднего размера со структурой, которую простые модели описать не могут.
Большинство проблем с SVR сводятся к одному и тому же набору ошибок — используйте это как шпаргалку «как не надо делать».
Отсутствие масштабирования признаков. SVR — алгоритм, основанный на расстояниях, поэтому немасштабированные признаки будут доминировать. Всегда применяйте StandardScaler и к X, и к y перед обучением.
Неправильное понимание эпсилона. Эпсилон — самый важный параметр. Слишком большой — и модель недообучается, игнорируя слишком много. Слишком маленький — и она ведёт себя как стандартная регрессия, «гоняясь» за каждой точкой. Всегда проводите перебор по сетке, чтобы понять, что лучше работает на вашем тестовом наборе.
Пропуск настройки параметров. Запуск SVR с параметрами по умолчанию и ожидание хороших результатов редко работает — как и в большинстве задач ML. C, epsilon и gamma нужно настраивать вместе. Используйте grid search с кросс-валидацией.
Применение SVR к очень большим наборам данных. Если у вас больше нескольких тысяч объектов, SVR будет медленным. Он просто не масштабируется так, как другие алгоритмы. Переключайтесь на модель, лучше работающую с большими данными, например, градиентный бустинг или нейронную сеть.
Важно понимать: правильная реализация этих четырёх пунктов не гарантирует отличную модель, но ошибка в любом из них почти наверняка гарантирует плохую.
Подводя итог, помните: SVR решает иную задачу, чем стандартная регрессия. Вместо минимизации каждой ошибки он подгоняет функцию в пределах допуска и игнорирует шум, который в него укладывается — именно это делает его полезным, когда данные неидеальны или не строго линейны.
Он не славится ни скоростью, ни простотой. Зато он устойчив. Если в данных есть нелинейности и выбросы, которые вы не хотите моделировать, SVR позволит сфокусироваться на структуре, а не «гоняться» за каждой точкой.
Просто не забывайте масштабировать признаки, настраивать параметры, выбирать подходящее ядро и быть консервативными в отношении объёма данных. Если всё сделать правильно, SVR даст вам надёжную модель, вряд ли подводящую в продакшене.
SVR — лишь один из инструментов, которые должен знать каждый дата-сайентист. Запишитесь на наш трек Machine Learning Engineer, чтобы изучить остальные и быть готовыми к работе в 2026 году.
Учитесь с DataCamp
Track
Course
Course