

Kurs
Üretken Yapay Zeka Kavramları
2 sa
110.7K
Anthropic’in bir sonraki sürümüne dair söylentiler son birkaç gündür kulislerdeydi. Birçok kişi Claude Sonnet 5’i beklerken, yılın ilk sürümü Claude Opus 4.6 şeklinde geldi.
1 milyon belirteçlik bağlam penceresi, uyarlanabilir düşünme, konuşma sıkıştırma ve zirvede yer alan çeşitli kıyaslamalarla Claude Opus 4.6, Opus 4.5’e göre bir iyileştirme sunuyor. Anthropic’in ifadeleriyle, en akıllı modellerini yükselttiler. Modele ek olarak Anthropic, Claude Code’da temsilci ekiplerini ve PowerPoint’te Claude’u da tanıttı.
Bu yazıda Claude Opus 4.6 ile gelen tüm yenilikleri ele alacak, yeni özelliklere bakacak, kıyaslamaları inceleyecek ve bir dizi uygulamalı örnekle sınırlarını zorlayacağız.
En yeni Claude özelliklerinden bazıları hakkında daha fazla bilgi edinmek için Claude Cowork ve Claude Code rehberlerimize ve ayrıca OpenClaw eğitimimize göz atmanızı öneririm. Diğer rakiplerle karşılaştırma için Muse Spark vs Claude Opus 4.6 ve GPT-5.4 vs Claude Opus 4.6 rehberlerimizi okuyun.
Claude Opus 4.6, Anthropic’in en yeni büyük dil modelidir. Opus 4.5’in ardından, şirketin ‘en akıllı’ model katmanına önemli bir yükseltmeyi temsil ediyor.
Yayın bloguna göre Anthropic, temsilci tabanlı kodlama, derin akıl yürütme ve öz-düzeltmeye daha fazla odaklandığını iddia ediyor. Bu da eylemden sürdürülebilir eyleme bir kayma olduğu anlamına geliyor.
Opus 4.6 daha dikkatli planlamak üzere tasarlandı, daha uzun sürelerde tutarlılığı artırıldı ve kendi işleyişindeki hataları saptayabiliyor. Tüm bunlar, Claude Opus 4.6’nın Terminal-Bench 2.0 kodlama değerlendirmesindeki en yüksek puan da dahil olmak üzere çeşitli kıyaslamalarda zirvede yer alması ve Humanity’s Last Exam’de diğer tüm sınır modelleri geride bırakması anlamına geliyor.
Bana en çok göze çarpan unsurlardan biri Claude Opus 4.6’daki geliştirilmiş bağlam penceresi. Beta sürümünde 1 milyon belirteçle, yeni model Gemini 3 ile aynı seviyeye geliyor; bu da bağlamı yitirmeden daha fazla bilgiyi işleyebileceği anlamına geliyor.
Claude Opus 4.6’da çoğu temsilci iş akışlarına odaklanan dikkate değer birkaç yeni özellik var. Bazı kilit noktalara bakalım:
Temsilci ekipleri, önceki Claude sürümlerinde gördüğümüz ‘alt temsilciler’in geliştirilmiş hâlidir. Temsilci ekipleri, paralel çalışabilen birden fazla, tamamen bağımsız Claude örneğini başlatmanıza olanak tanır. Oturumlardan biri işleri koordine eden ‘lider’ temsilcidir, ‘takım arkadaşları’ ise gerçek yürütmeyi üstlenir.
En ilginç bulduğum nokta, her takım üyesinin kendi bağlam penceresine sahip olması; bu da daha kapsamlı yürütmeye imkân tanır. Her takım arkadaşı ekibin diğer üyeleriyle doğrudan iletişim de kurabilir.
Elbette bu özelliğin potansiyel bir dezavantajı var: maliyet. Her temsilcinin kendi bağlam penceresi olduğundan, belirteçlerinizi hızla tüketmeye başlayabilirsiniz. Bu nedenle Anthropic, bu özelliği daha yüksek karmaşıklık düzeylerine sahip senaryolarda kullanmanızı öneriyor.
Claude Opus 4.6’nın güzel özelliklerinden biri bağlam sıkıştırma. Bu yaşam kalitesi yükseltmesi, bağlam pencerelerini dolduran uzun iş akışları yürüttüğünüzde yaşanan sorunları azaltır. Genellikle, performansın düşmeye başladığı bir bağlam duvarına çarpardınız.
Konuşma sıkıştırma ile Claude Opus 4.6, bir konuşmanın belirteç eşiğine yaklaştığını otomatik olarak tespit edebilir ve mevcut konuşmayı özlü bir blokta (sıkıştırma bloğu) özetleyebilir.
Bu özellik, etkileşimlerinizin özünü korurken çalışmanızı sürdürmek için alan açmaya yardımcı olur. Uzun süre çalışması gereken görev odaklı temsilciler kullanmayı planlıyorsanız, bu özellik iyileştirilmiş bir bellekle temsilcileri rayında tutabilir.
Claude Opus 4.6’nın, genişletilmiş düşünmeye ihtiyaç duyup duymadığını ve bu düşünme için ne kadar çaba harcayacağını belirleyen iki özelliği bulunuyor.
Uyarlanabilir düşünme, modelin isteminizin ne kadar karmaşık olduğunu belirlemesini sağlar. Basitlik veya karmaşıklığa göre genişletilmiş düşünmeyi kullanıp kullanmayacağına karar verir. Bunun için kaç belirteç kullanılacağına dair manuel bir ayar yerine, Claude her isteğin karmaşıklığına göre bütçesini ayarlar.
Çaba parametresi, Claude’un belirteç harcama konusunda ne kadar istekli veya temkinli olacağını ayarlamanıza olanak tanır. Özünde, belirteç verimliliği ile yanıtların ne kadar kapsamlı olacağı arasında denge kurabileceğiniz anlamına gelir.
Claude Opus 4.6’yı API’de kullanırken bu parametreleri manuel olarak ayarlayabilirsiniz. Örneğin:
Kısa süre önce Excel’de Claude’u ele aldık ve eklentinin Excel çalışma sayfanızın yan panelinde çeşitli görevlerde nasıl yardımcı olabileceğini gösterdik. Bu aracın işlevselliğini geliştirmeye ek olarak, Anthropic PowerPoint’te Claude’u duyurdu.
Bu entegrasyon, slayt ana şablonlarınıza, yazı tiplerinize ve düzenlerinize saygı gösterir. Kurumsal bir şablon verip belirli bir bölümü oluşturmasını isteyebilir veya bir slayt seçip yoğun metni yerel, düzenlenebilir bir diyagrama dönüştürmesini talep edebilirsiniz.
Sadece “slayt resimleri” üretmek yerine düzenlenebilir PowerPoint nesneleri üretmeye yapılan vurgu, bunu yalnızca bir fikir üreticisinden ziyade gerçek bir üretkenlik aracına dönüştürüyor.
PowerPoint’te Claude şu anda Max ve Kurumsal kullanıcılar için araştırma ön izlemesinde.
Opus 4.6’nın başlıca iddialarının çoğu, daha zor kodlama görevleri ve daha derin akıl yürütme etrafında toplanıyor. Bu becerilerin hepsi belirli bir temele dayanır: birden çok kısıtı aynı anda akılda tutma, birçok adım üzerinden akıl yürütme ve hataları yakalama yeteneği.
Bunu göz önünde bulundurarak, Opus 4.6’yı çok adımlı mantık, matematik ve kodlama meydan okumalarından oluşan bir diziyle sınadık. Bilinen ve yaygın LLM zayıflıklarını – kademeli hesaplama hataları, mekânsal akıl yürütme (her zaman sorunlu) ve kısıtlar içeren sorular gibi – açığa çıkarıp çıkaramayacağımızı görmek istedik. Ayrıca Anthropic’in duyurusunda Opus 4.6’nın kök neden analizi ve diğer hata ayıklama konularında ne kadar iyi olduğuyla övünmesi nedeniyle özel bir hata ayıklama görevi de ekledik.
İlk testimiz asal sayılar, onaltılı sayılar ve saymayı birleştiriyor:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Biraz karmaşık geliyor, ancak bu testin doğrulanması biz insanlar için oldukça kolay. Doğru yanıtın 2 olduğunu biliyoruz çünkü 6. asal 13’tür; 13’ün karesi 169’dur, bu da onaltılıkta "A9"dur. Bu, 1 harf × 1 rakam içerir, çarptığımızda 1 eder ve birinci asal 2’dir.
Endişe, bir modelin hex dönüşümünde tökezleyip son yanıta tamamen yanlış bir şekilde ulaşmasıydı. Gördüğünüz gibi Opus 4.6 hiç zorlanmadı:

İkinci testimiz, mekânsal akıl yürütme ve negatif sayı işlemenin bir sınavı:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Bunu doğrulamak bizim açımızdan biraz daha fazla uğraş gerektirdi. Doğru cevap -6.065. Bunu şu şekilde biliyoruz: Döndürülmüş matris [[1, 4], [5, 2]]; ardından Python kullanarak determinantı -18 buluyoruz, bunu küp aldığımızda -5.832 elde ediyoruz; son olarak 233 çıkarıp -6.065’e ulaşıyoruz.
Bu testi, deneyimlerimizden modellerin sıklıkla matris elemanlarını yanlış yer değiştirdiğini veya süreçte negatif işareti kaybettiklerini bildiğimiz için seçmiştik. Yine, Opus 4.6 hiç zorlanmadı:

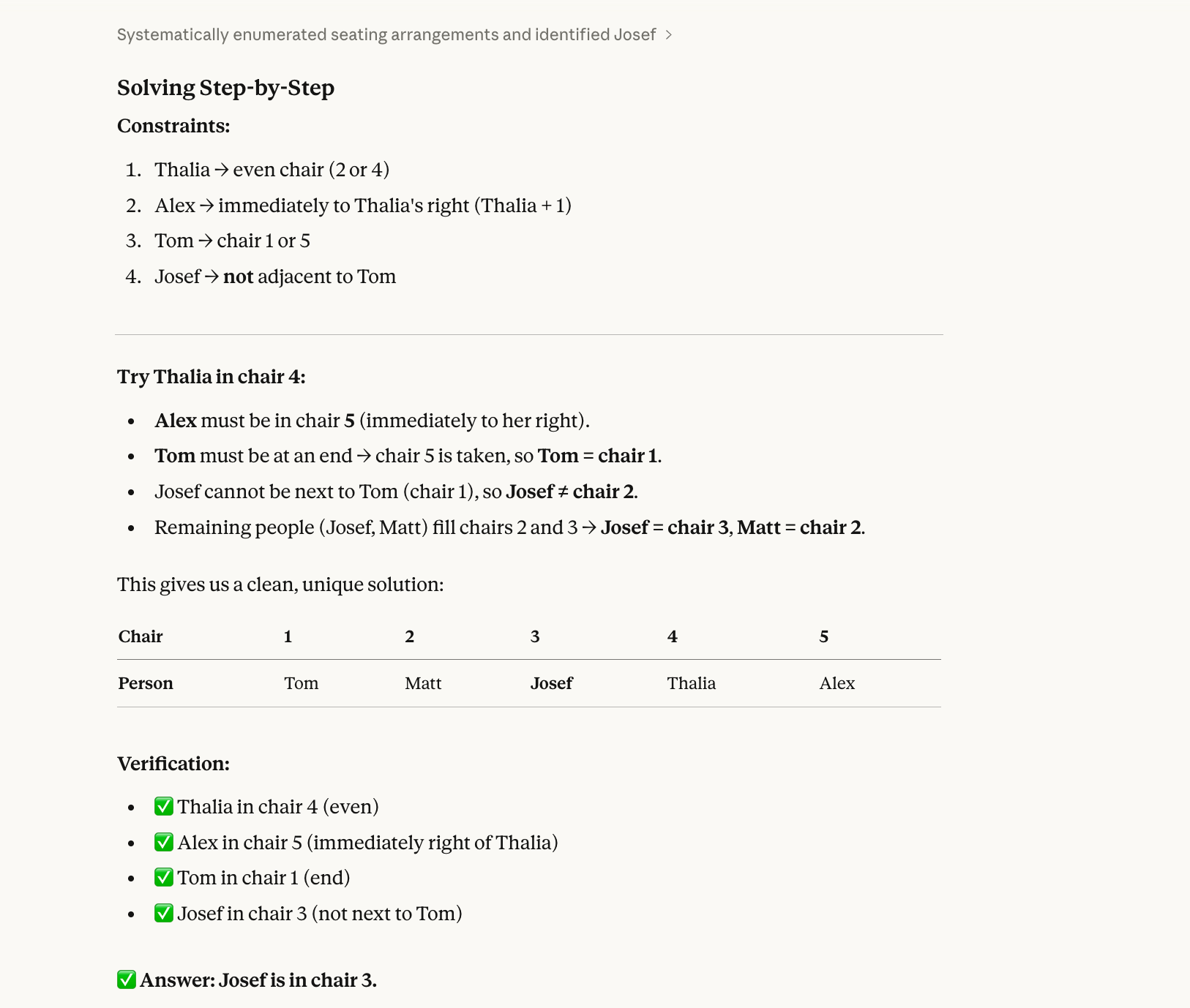
Üçüncü testimiz için geri izleme gerektiren bir kısıt tatmin problemi denedik:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?Bu testin doğru yanıtı Josef’tir. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Biraz uğraşla kâğıt üzerinde çözebilirsiniz.
Bir modelin bu tür bir soruyu yanlış yapmasının temel nedeni, tarihsel olarak sıralı değil, bütüncül çözüm üretmemeleridir. “Thalia çift numaralı sandalyede” ifadesini okur ve diğer kısıtlarla uyumlu olup olmadığını kontrol etmeden birini (ör. sandalye 2) seçer. Sonra bu seçime bağlı kalır, daha fazla sandalyeyi doldurur ve sonunda bir çakışmaya çarpar; ancak o noktaya gelene kadar kendini köşeye sıkıştırmış olur ve Thalia’yı sandalye 4’te denemek için geri dönmez.
Opus 4.6 bunu da doğru yaptı:
Dördüncü testimiz, mekânsal görselleştirme ve fiziksel sezgiyi değerlendiriyor:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Bunu doğrulamak için gerçekten bileğimdeki saati çıkarıp çevirdim.
Doğru yanıt 14:30. Saat 3:15’te dakika ibresi "3"ü gösterir. 12’yi solumdaki pencereye çevirdiğimde, "3" "12"nin olduğu yere taşındı. Sonra 3:15’e 0 ekledim, 45 dakika çıkardım ve 14:30’a ulaştım.
Testi tasarlarken, modellerin saat kadranını döndürmeyi ibreyi hareket ettirmekle karıştırmalarını bekliyorduk. Ayrıca modellerin 0 eklemeyi şüpheli bulma ve dolayısıyla farklı bir sayı dayatma eğiliminde olduklarını duyduk.
Ancak Opus 4.6 bu problemi de çözdü; doğru cevabı verdi:

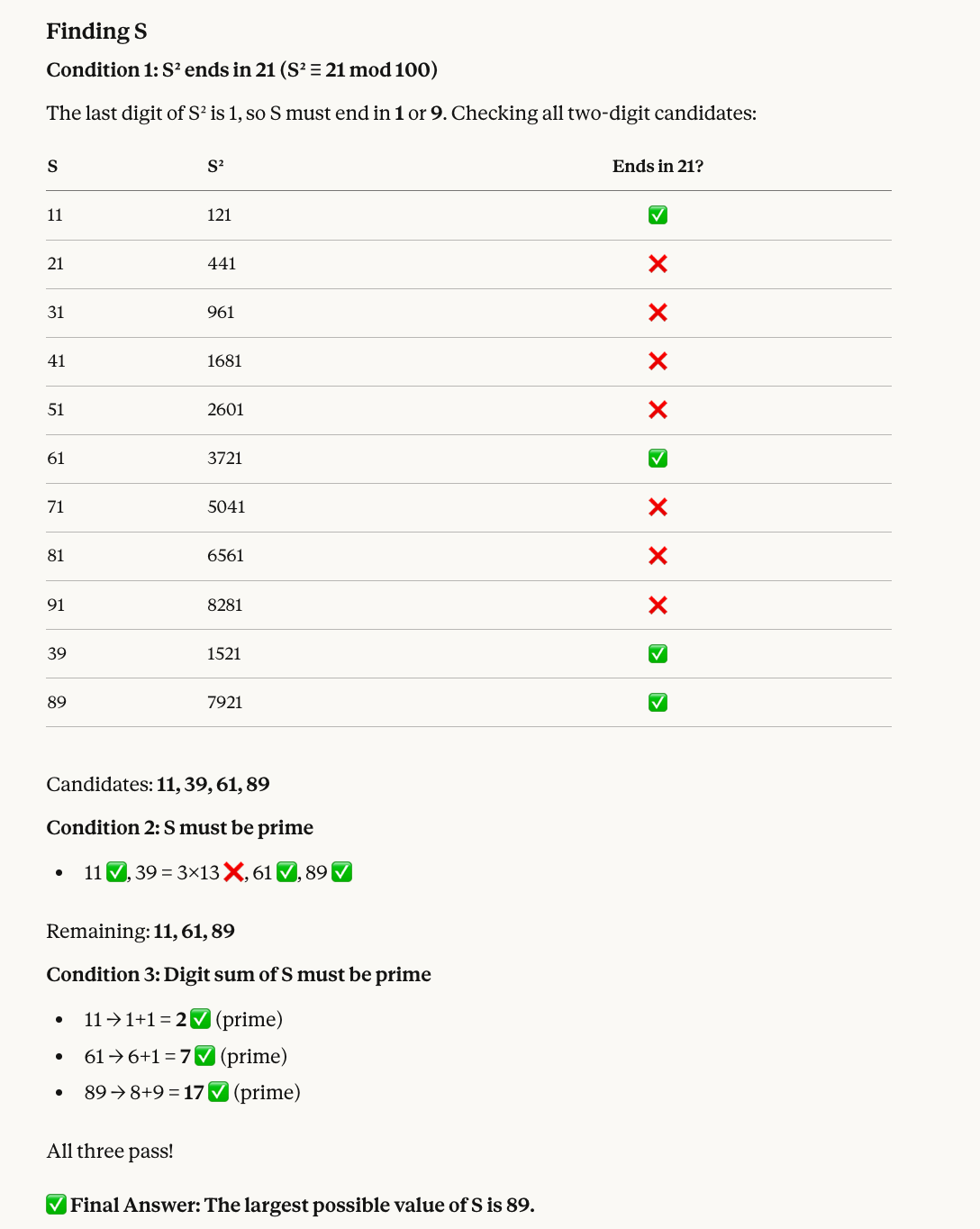
Beşinci testimiz, modüler aritmetiği asal filtrelemeyle birleştiriyor:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Doğru sayının 89 olmasının nedeni şu: Karesi 21 ile biten sayılar arasında 11, 39, 61 ve 89 bulunur. Bunlardan 39 asal değildir, dolayısıyla 11, 61 ve 89 kalır. Üçünün de basamak toplamı asaldır (sırasıyla 2, 7 ve 17); bu nedenle en büyüğü 89’dur.
Opus 4.6 yine doğru cevabı buldu ve bu kez yardımcı bir görsel de ekledi:
Sıradaki test, faktöriyel matematiği, dize işleme ve asalları birbirine bağlıyor:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.425’in doğru yanıt olduğunu şu şekilde doğruladık: 5! = 120; 1 çıkarınca 119; basamakları ters çevirince 911. Ardından aşağıdaki R kodunu kullanarak 10 ile 911 arasında 152 asal olduğunu ve toplamlarının 64.598 olduğunu gördük. Son olarak yine R ile böldük ve yuvarladık: 64.598 ÷ 152 ≈ 425.

Kullandığımız R betiği şudur:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Sıradaki testimiz Opus 4.6’nın başlıca iddialarından birini hedefliyor: kodlardaki hataları teşhis etmek. Modellerin sıklıkla kodu satır satır doğru izlediğini ancak izi alttaki kusurla ilişkilendirmekte başarısız olduğunu biliyoruz.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Yanıt ve neden iyi bir test olduğu şöyle: İşlev, listenin başında parça 3 öğeden az olduğunda bile her zaman window (3) ile böler. Hatalı çıktı [3.33, 10.0, 20.0, 30.0, 40.0]’dır, ancak ilk iki değer 10.0 ve 15.0 olmalıdır; çünkü bu parçalar sırasıyla yalnızca 1 ve 2 öğe içerir. Düzeltme, / window ifadesini / len(chunk) olarak değiştirmektir.
Bu testi seviyoruz çünkü modeller genellikle döngüyü mükemmel şekilde izliyor ama ardından “çıktı doğru görünüyor” diyor — matematiğin adım adım işlediğini görüp tek bir öğeyi 3’e bölmenin yanlış olduğunu işaretlemiyorlar. Bu, modelin niyeti (yürüyen ortalamanın ne yapması gerektiği) ile icrayı (kodun gerçekte ne yaptığı) aynı anda tutmasını ve aradaki farkı görmesini gerektirir.

Son testimizde matematik yok, sadece karşı-olgusal akıl yürütme var.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Kabul edelim, burada tek bir doğru cevap yok ve kendimizi hayal etmek zor. Ama en azından modelin sonuçlar üzerine akıl yürütmesini bekliyoruz ve Claude Opus 4.6’nın yanıtının yeterince makul olduğunu düşünüyoruz.
Özetle, Opus 4.6 kusursuz bir skor elde etti; ancak gördüğünüz gibi yanıtın biraz öznel olduğu bir soru da ekledik, son kararı siz verebilirsiniz.

Opus 4.6, en az dört önemli kıyaslamada tartışmasız lider:
Terminal-Bench 2.0 bir temsilci tabanlı kodlama kıyaslamasıdır; Humanity’s Last Exam karmaşık akıl yürütmeyi sınar; GDPval-AA bilgi işinin performansını test eder; BrowseComp ise bir modelin çevrimiçi olarak zor bulunan bilgiyi bulma becerisini ölçer.
Claude modelleri, en iyi kodlayıcılardan biri olma konusunda haklı bir üne sahip. O hâlde Terminal-Bench 2.0 kıyaslamasının sonuçlarına bakarak başlayalım.
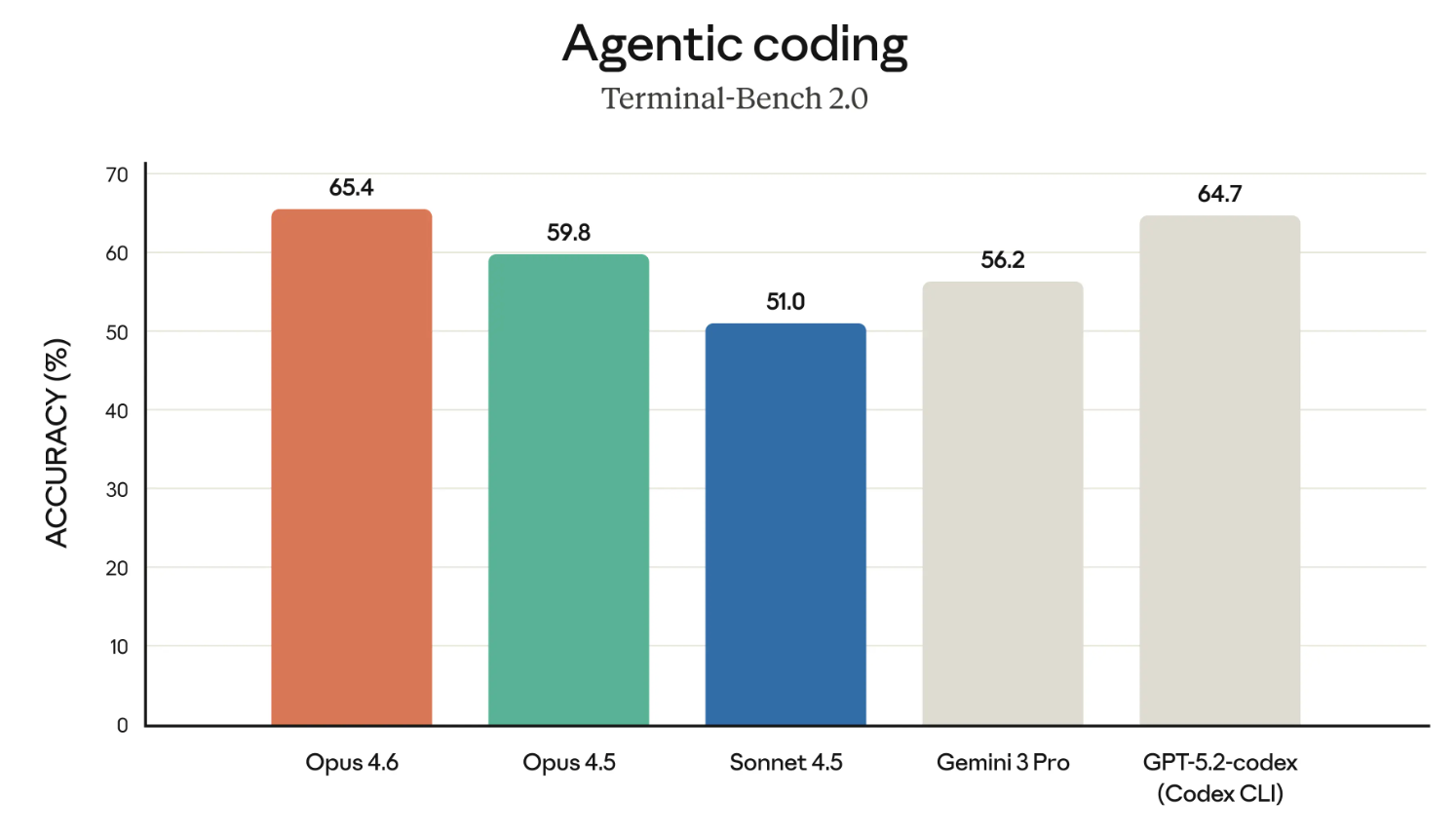
Yukarıdaki grafik Opus 4.6’yı GPT-5.2-codex ile ilişkilendirir gibi görünüyorsa – bu, elbette kasıtlıdır. Anthropic son zamanlarda çeşitli alanlarda OpenAI’a doğrudan meydan okuyor ve kurumsal kullanım için güçlü bir argüman sunuyor.
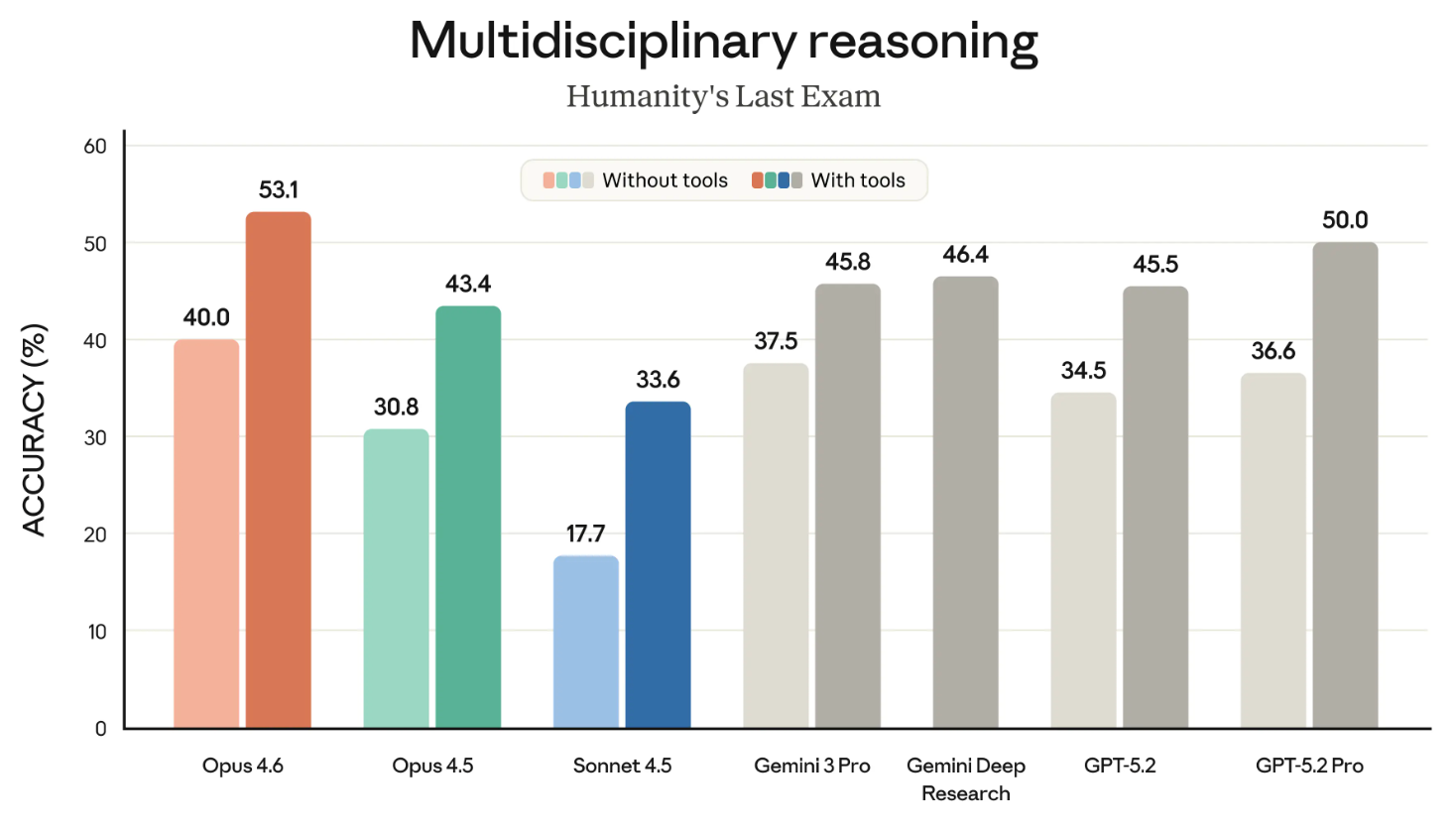
Humanity’s Last Exam en bilinen kıyaslamalardan biridir ve hepimizin yakından takip ettiği bir metriktir. Bir modelin genel olarak akıl yürütme yeteneğini ölçer.
Aşağıdaki grafik, HLE kıyaslamasında farklı sınır modellerinin araçlı ve araçsız başarılarını gösteriyor. (‘Araçlı’, modelin web’de arama veya kod çalıştırma gibi haricî yetenekleri kullanmasına izin verildiği anlamına gelir.)
Bu grafik iki ayrı grafik olarak daha iyi olabilirdi. Bu küçük noktayı bir kenara bırakırsak, çıkarım net: Opus 4.6 hem ‘araçlı’ hem de ‘araçsız’ kategorilerde liderdir.
GDPval-AA (adı üstünde) ekonomik değeri olan bilgi işini test eder. Finansal modeller çalıştırmak veya araştırma yapmak gibi şeyleri düşünün.
GDPval-AA ve benzeri diğer kıyaslamalar giderek daha önemli hale geliyor; çünkü işletmelerin gerçekten para ödediği iş türlerini ölçüyorlar. Opus 4.6’nın GDPval-AA’daki başarısı aynı zamanda GPT model serisine doğrudan bir meydan okumadır; çünkü OpenAI ve Anthropic aynı müşterilerin birçoğu için rekabet ediyor.
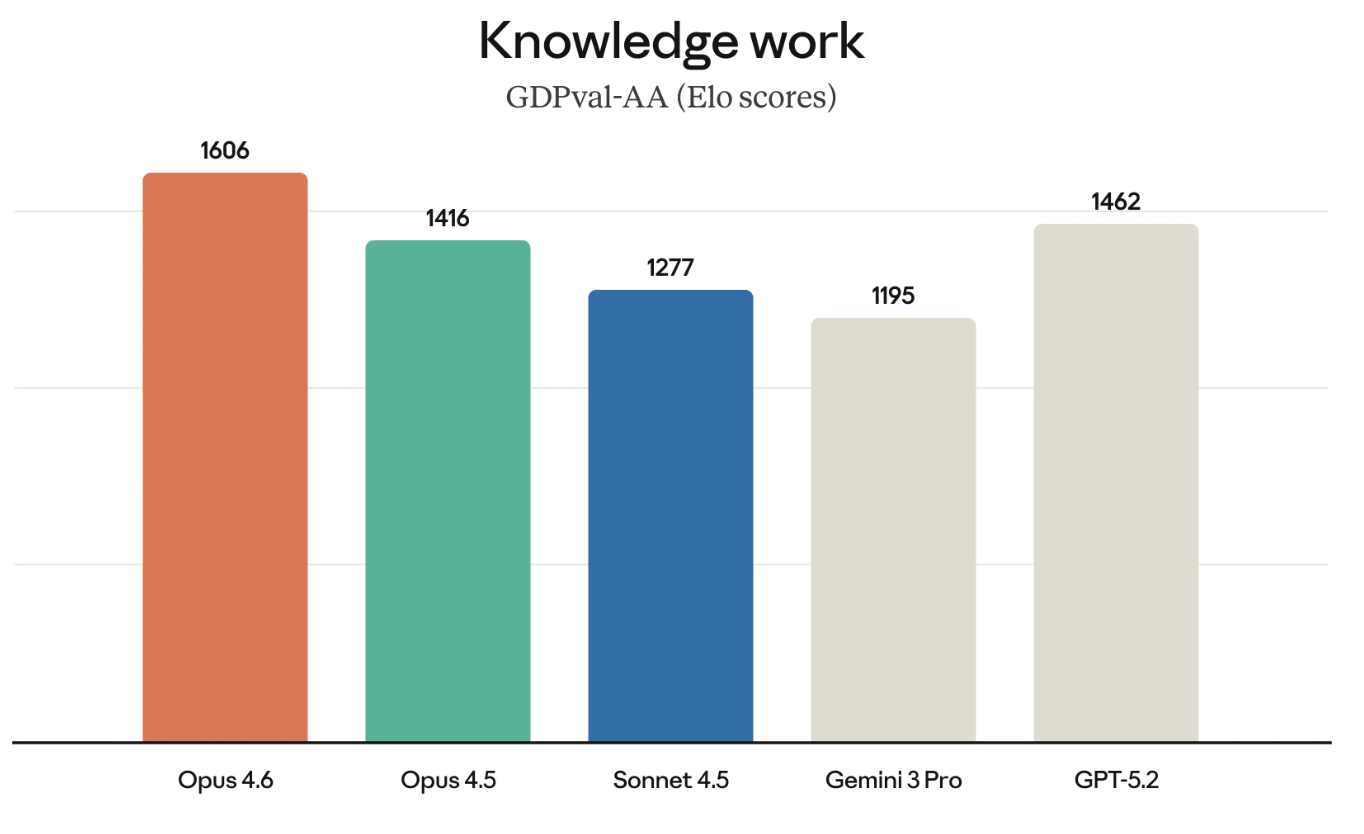
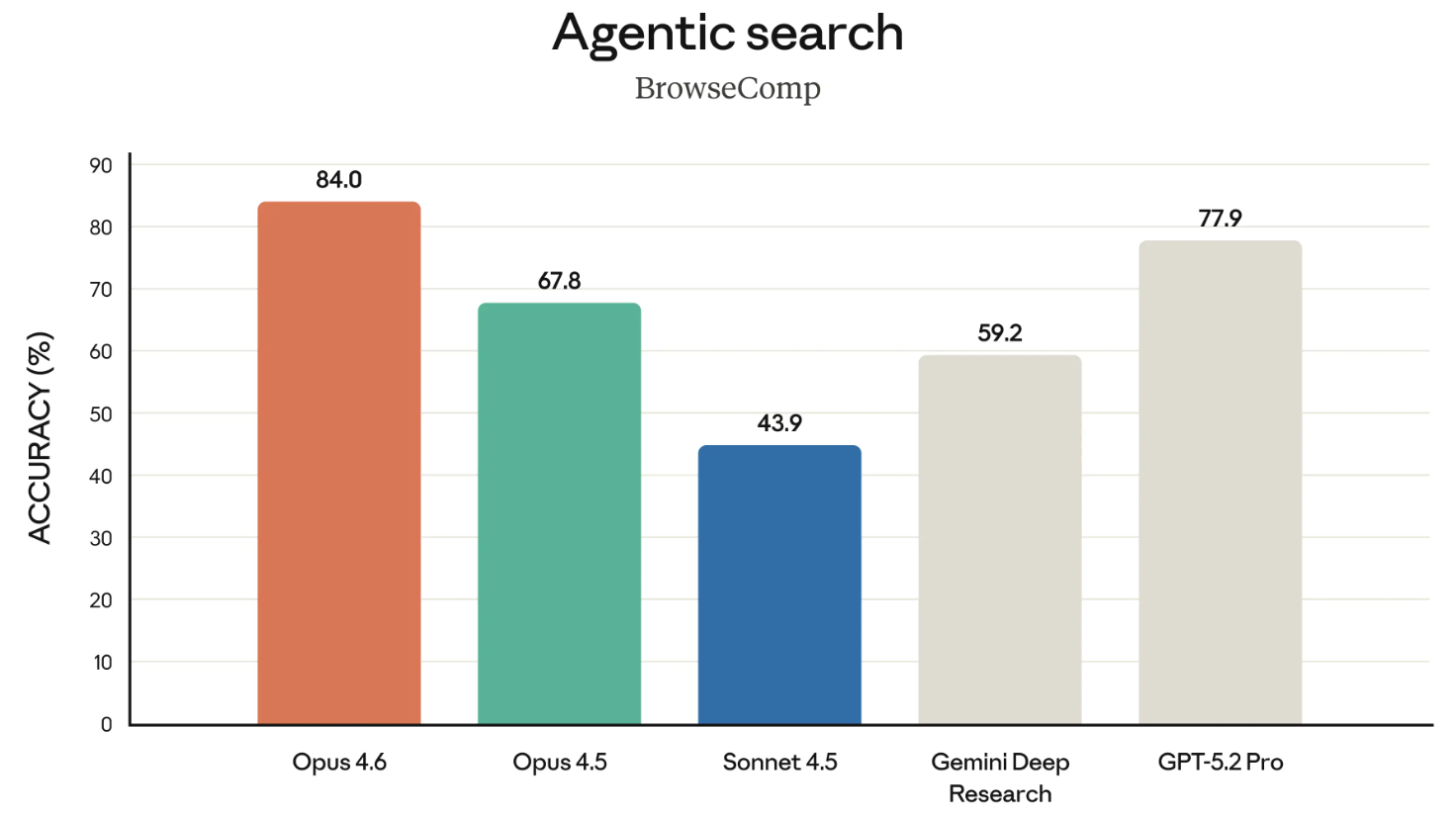
BrowseComp, bu sürümden bahsetmeye değer son kıyaslama. Bir modelin çevrimiçi olarak zor bulunan bilgileri takip etme becerisini ölçer. Biraz geçmiş: OpenAI aslında BrowseComp’ı kendi modellerinin arama yeteneklerini göstermek için geliştirmişti.
Bu sürümde Anthropic, Opus 4.6’nın bu kıyaslamada zirvede olduğunu vurgularken, doğrudan OpenAI’ın Nisan 2025’teki BrowseComp duyurusuna bağlantı verdi. OpenAI’ın kendi kıyaslamasını onlara karşı referans göstermek biraz sivri bir hamleydi.
Opus 4.6, bu makale yazıldığı sırada geniş ölçekte kullanılabilir durumda. Ancak Opus 4.6’ya pro hesaba yükseltmeden erişemezsiniz; bu hesap, Excel’de Claude kullanabilmek gibi başka avantajlar da sunar.
Bir geliştiriciyseniz, Claude API’de claude-opus-4-6 modelini kullanmalısınız. Fiyatlandırma değişmedi: Hâlâ milyon belirteç başına $5/$25. İki sayı kafanızı karıştırıyorsa, ilk sayının modele gönderdiğiniz belirteçler (yani istemleriniz) için, ikincisinin ise modelin ürettiği belirteçler (yanıtlar) için ödediğiniz tutar olduğunu bilin.
Claude Opus 4.6, büyük kurumsal müşterilerin önemsediği ekonomik açıdan önemli görevlerde bir modelin performansını ölçen GPDVal-AA gibi önemli kıyaslamalarda lider konumda. OpenAI bu gelişmeden rahatsız olmuş olabilir; zira Opus 4.6’nın çıkışından sadece saatler önce, üretimde yapay zekâ temsilcileri oluşturmak, dağıtmak ve yönetmek için yeni bir kurumsal platform olan OpenAI Frontier’ı duyurdular.
Başka bir deyişle, model kıyaslamalarında rekabet etmek yerine Frontier bize, OpenAI’ın model paketinin etrafındaki altyapıya odaklandığını; özellikle de yapay zekâ temsilcilerine paylaşılan iş bağlamı, izinler ve zaman içinde geri bildirim alma ve ondan öğrenme yeteneği vermeye odaklandığını gösteriyor. Kıyaslamalarda geride kalırken OpenAI, platformunun şirket içinde temsilcileri gerçekten faydalı kılmak için daha iyi konumlandığını işaret ediyor.
Bunun stratejik bir dönüş mü yoksa model yarışını kaybettiklerine dair zımnî bir kabul mü olduğuna siz karar verin.
Genel olarak, Anthropic’in Claude Opus 4.6 ile sunduklarından etkilendik ve temsilci ekipleriyle uygulamalı çalışmayı dört gözle bekliyoruz. Claude ailesi hakkında daha fazla bilgi edinmek istiyorsanız, mutlaka Introduction to Claude Models kursuna göz atın.
DataCamp ile Yapay Zekâyı Öğrenin
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
