

Kursus
Konsep Generative AI
2 Hr
110.7K
Rumor tentang rilis berikutnya dari Anthropic telah bergema beberapa hari terakhir. Meski banyak yang memperkirakan Claude Sonnet 5, rilis pertama tahun ini hadir dalam bentuk Claude Opus 4.6.
Dengan context window 1 juta token, pemikiran adaptif, pemadatan percakapan, dan beragam tolok ukur yang menempati puncak, Claude Opus 4.6 merupakan peningkatan dari Opus 4.5. Seperti istilah Anthropic, mereka telah meningkatkan model tercerdas mereka. Bersamaan dengan modelnya, Anthropic juga meluncurkan tim agen di Claude Code dan Claude in PowerPoint.
Dalam artikel ini, kami akan membahas semua hal baru pada Claude Opus 4.6, meninjau fitur-fitur baru, mengeksplorasi tolok ukurnya, dan mengujinya dengan beberapa contoh praktis.
Untuk mempelajari lebih lanjut beberapa fitur terbaru Claude, saya sarankan Anda melihat panduan kami tentang Claude Cowork dan Claude Code, serta tutorial OpenClaw kami. Untuk perbandingan dengan kompetitor lain, baca panduan kami tentang Muse Spark vs Claude Opus 4.6 dan GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 adalah model bahasa besar terbaru dari Anthropic. Melanjutkan dari Opus 4.5, model ini mewakili peningkatan signifikan pada tier model ‘tercerdas’ perusahaan.
Dari blog rilisnya, Anthropic menyatakan fokus yang lebih besar pada pengkodean agen, penalaran mendalam, dan koreksi mandiri. Ini berarti ada pergeseran dari aksi menuju aksi berkelanjutan.
Opus 4.6 dirancang untuk merencanakan dengan lebih cermat, memiliki koherensi yang lebih baik dalam jangka panjang, dan mengidentifikasi kesalahan dalam prosesnya sendiri. Semua ini berarti Claude Opus 4.6 memuncaki beberapa tolok ukur, termasuk skor teratas pada evaluasi pengkodean Terminal-Bench 2.0 dan mengungguli semua model frontier lainnya pada Humanity’s Last Exam.
Salah satu hal yang paling menonjol bagi saya adalah context window yang ditingkatkan pada Claude Opus 4.6. Dengan 1 juta token di versi beta, model baru ini sejalan dengan Gemini 3, artinya dapat memproses lebih banyak informasi tanpa kehilangan konteks.
Ada beberapa fitur baru yang menonjol di Claude Opus 4.6, banyak di antaranya berfokus pada alur kerja berbasis agen. Mari kita lihat beberapa poin utamanya:
Tim agen adalah peningkatan dari ‘subagen’ yang kita lihat di versi Claude sebelumnya. Tim agen memungkinkan Anda menjalankan beberapa instance Claude yang sepenuhnya independen dan dapat bekerja secara paralel. Satu sesi adalah agen ‘pemimpin’ yang mengoordinasikan, sementara ‘rekan tim’ menangani eksekusi aktualnya.
Yang paling menarik bagi saya adalah setiap anggota tim memiliki context window sendiri, sehingga memungkinkan eksekusi yang lebih menyeluruh. Setiap rekan tim juga dapat berkomunikasi langsung dengan anggota tim lainnya.
Tentu saja, fitur ini memiliki potensi kelemahan — biaya. Karena setiap agen punya context window sendiri, token Anda bisa cepat habis. Karena itu, Anthropic merekomendasikan penggunaan fitur ini untuk skenario dengan tingkat kompleksitas yang lebih tinggi.
Salah satu fitur rapi dari Claude Opus 4.6 adalah pemadatan konteks. Peningkatan kenyamanan ini membantu menghindari masalah saat Anda menjalankan alur kerja panjang yang memaksimalkan context window. Biasanya, Anda akan menabrak batas konteks di mana kinerja mulai menurun.
Dengan pemadatan percakapan, Claude Opus 4.6 dapat secara otomatis mendeteksi saat percakapan mendekati ambang token dan merangkum percakapan yang ada menjadi blok ringkas (blok pemadatan).
Fitur ini membantu mempertahankan hal-hal penting dari interaksi Anda sekaligus menyediakan ruang untuk melanjutkan pekerjaan. Jika Anda berencana menggunakan agen berorientasi tugas yang perlu berjalan lama, ini dapat menjaga mereka tetap pada jalur dengan memori yang jauh lebih baik.
Ada dua fitur pada Claude Opus 4.6 yang menentukan apakah perlu menggunakan pemikiran diperluas dan seberapa besar upaya yang dilakukan dalam pemikiran tersebut.
Pemikiran adaptif memungkinkan model menentukan seberapa kompleks prompt Anda. Berdasarkan tingkat kesederhanaan atau kompleksitas, model akan memutuskan apakah akan menggunakan pemikiran diperluas. Alih-alih pengaturan manual tentang berapa banyak token yang digunakan untuk ini, Claude akan menyesuaikan anggarannya berdasarkan kompleksitas setiap permintaan.
Parameter effort memungkinkan Anda mengatur seberapa bersemangat atau konservatif Claude dalam membelanjakan token. Intinya, Anda bisa menyeimbangkan efisiensi token dan seberapa menyeluruh tanggapan yang diberikan.
Saat menggunakan Claude Opus 4.6 di API, Anda dapat mengatur parameter ini secara manual. Contohnya:
Baru-baru ini kami membahas Claude in Excel, menunjukkan bagaimana add-on tersebut dapat membantu Anda dengan berbagai tugas di panel samping spreadsheet Excel Anda. Selain meningkatkan fungsionalitas alat ini, Anthropic mengumumkan Claude in PowerPoint.
Integrasi ini menghormati slide master, font, dan tata letak Anda. Anda dapat memberikan templat perusahaan dan memintanya membangun bagian tertentu, atau memilih sebuah slide dan memintanya mengonversi teks padat menjadi diagram asli yang dapat diedit.
Penekanan pada pembuatan objek PowerPoint yang dapat diedit alih-alih hanya "gambar slide" menjadikannya alat produktivitas yang nyata, bukan sekadar generator konsep.
Claude in PowerPoint saat ini dalam pratinjau riset untuk pengguna Max dan Enterprise.
Banyak klaim utama Opus 4.6 berpusat pada tugas pengkodean yang lebih sulit dan penalaran yang lebih dalam. Semua kemampuan ini bertumpu pada fondasi tertentu: kemampuan menahan banyak kendala dalam pikiran, bernalar di banyak langkah, dan menangkap kesalahan.
Dengan itu, kami menempatkan Opus 4.6 melalui serangkaian tantangan logika multi-langkah, matematika, dan pengkodean. Kami ingin melihat apakah kami dapat mengekspos beberapa kelemahan LLM yang sudah diketahui dan umum — seperti kesalahan perhitungan berantai, penalaran spasial (selalu jadi masalah), dan pertanyaan yang melibatkan kendala. Kami juga menyertakan tugas debugging khusus karena pengumuman Anthropic membanggakan kemampuan Opus 4.6 dalam analisis akar penyebab dan masalah debugging lainnya.
Tes pertama kami menggabungkan bilangan prima, heksadesimal, dan berhitung:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Kedengarannya agak kompleks, tetapi tes ini cukup mudah kami verifikasi. Jawaban benar yang kami ketahui adalah 2 karena bilangan prima ke-6 adalah 13; 13 kuadrat adalah 169, yang dalam hex adalah "A9". Ini memiliki 1 huruf × 1 digit, yang sama dengan 1 saat dikalikan, dan bilangan prima pertama adalah 2.
Kekhawatirannya adalah model bisa tersandung pada konversi hex, yang akan berakibat pada jawaban akhir yang benar-benar salah. Seperti yang Anda lihat, Opus 4.6 tidak mengalami kesulitan:

Tes kedua kami menguji penalaran spasial dan penanganan bilangan negatif:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Yang ini butuh sedikit lebih banyak kerja untuk kami verifikasi. Jawaban yang benar adalah -6.065. Kami tahu ini karena matriks yang diputar adalah [[1, 4], [5, 2]]; lalu kami bisa gunakan Python untuk mencari determinan, yang bernilai -18 dan saat kami mengkubuskan angka ini, kami mendapat -5.832; akhirnya, kami mengurangkan 233 dan mendapat -6.065.
Kami menyukai ide tes ini karena dari pengalaman kami tahu model sering menukar elemen matriks secara keliru atau kehilangan tanda negatif di tengah jalan. Lagi-lagi, Opus 4.6 tidak kesulitan:

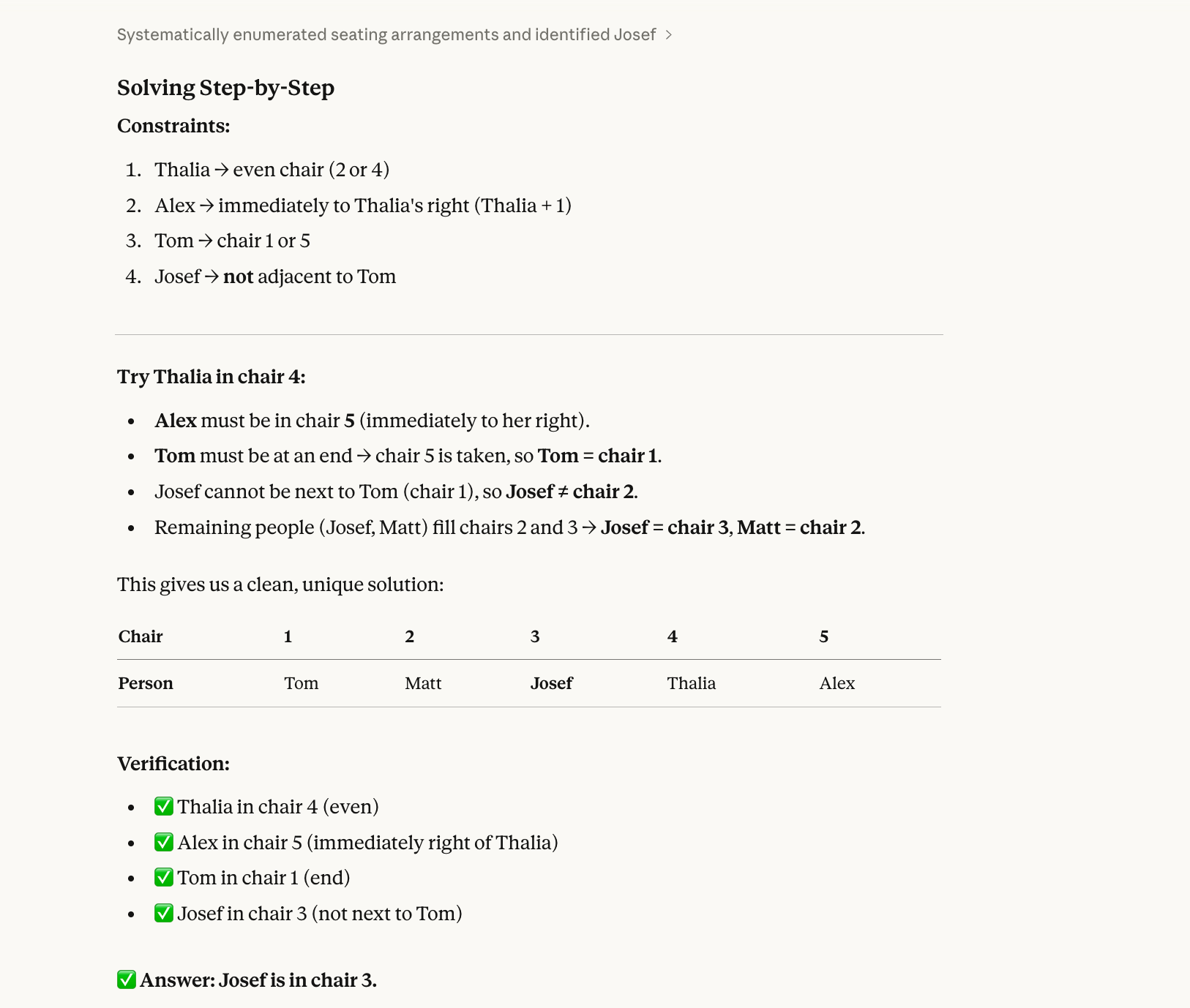
Untuk tes ketiga, kami mencoba masalah pemenuhan kendala yang memerlukan backtracking:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?Jawaban yang benar untuk tes ini adalah Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Anda bisa mengerjakannya di selembar kertas dengan sedikit usaha.
Alasan mendasar model bisa salah pada pertanyaan seperti ini karena model secara historis menyelesaikan secara berurutan, bukan secara holistik. Mereka membaca "Thalia di kursi bernomor genap" dan memilih salah satunya (misalnya, kursi 2) tanpa memeriksa apakah pilihan itu cocok dengan semua kendala lain. Lalu mereka berkomitmen pada itu, mengisi lebih banyak kursi, dan akhirnya menemui konflik, tetapi saat itu mereka sudah terjebak dan tidak kembali mencoba menempatkan Thalia di kursi 4 sebagai gantinya.
Opus 4.6 juga menjawab benar untuk yang satu ini:
Tes keempat kami mengevaluasi visualisasi spasial dan intuisi fisik:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Untuk memverifikasi yang satu ini, saya benar-benar melepas jam tangan dari pergelangan dan memutarnya.
Jawaban yang benar adalah pukul 14.30. Pada pukul 15.15, jarum menit menunjuk ke "3". Saat saya mengarahkan angka 12 ke jendela di sebelah kiri, angka "3" berpindah ke tempat angka "12". Lalu saya menambahkan 0 ke 15.15, mengurangkan 45 menit, dan saya mendapatkan pukul 14.30.
Dalam merancang tes ini, kami memperkirakan model mungkin mengacaukan memutar bidang jam dengan menggerakkan jarumnya. Kami juga pernah mendengar bahwa model cenderung menganggap menambahkan 0 itu mencurigakan dan, karenanya, akan mencoba memaksakan angka lain.
Namun, Opus 4.6 berhasil menyelesaikan masalah ini; ia juga mendapatkan jawaban yang benar:

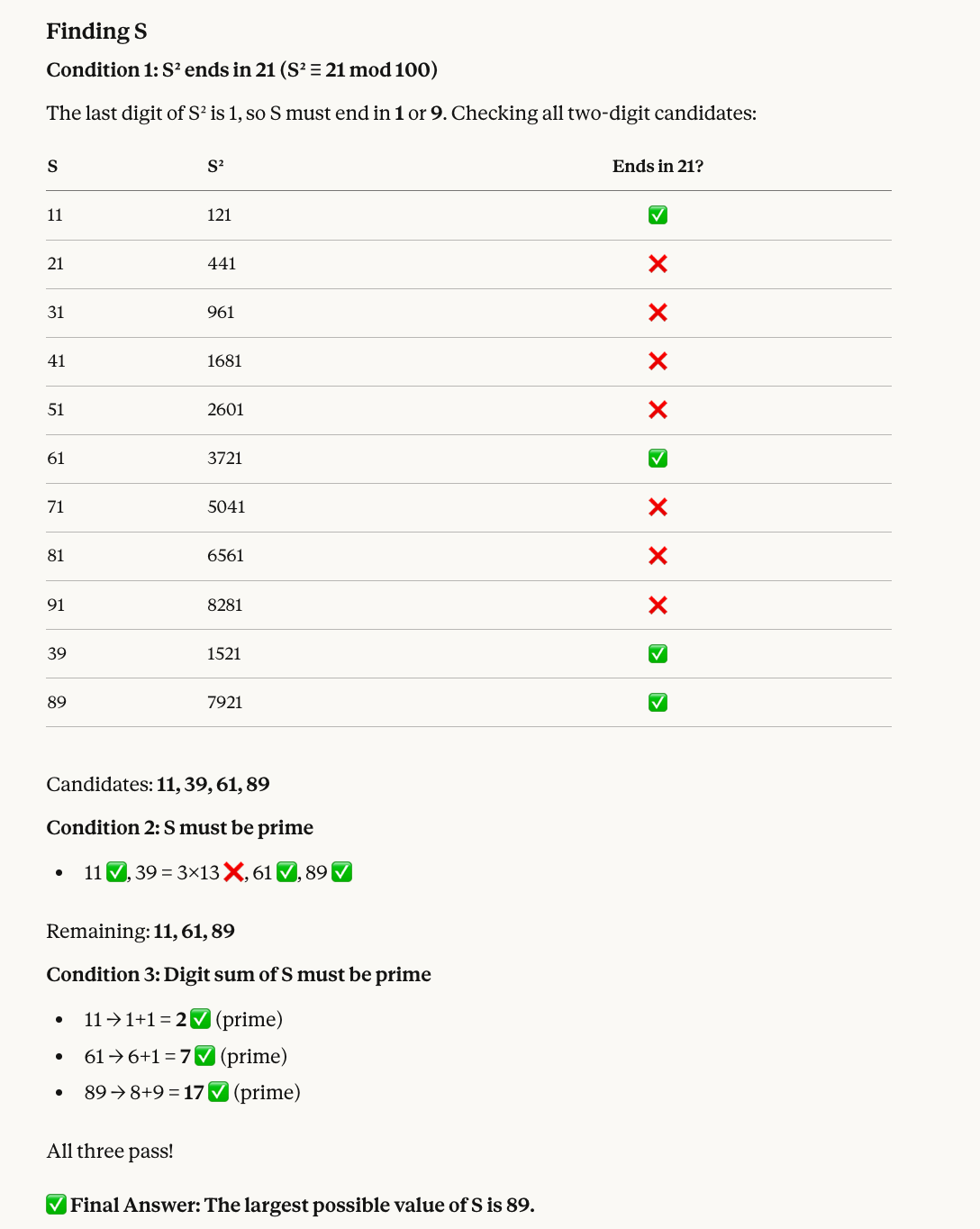
Tes kelima kami menggabungkan aritmetika modular dengan penyaringan bilangan prima:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Inilah alasannya angka yang benar adalah 89: Angka yang kuadratnya berakhiran 21 termasuk 11, 39, 61, dan 89. Di antaranya, 39 bukan prima, jadi tersisa 11, 61, dan 89. Ketiganya punya jumlah digit yang prima (masing-masing 2, 7, dan 17), jadi yang terbesar adalah 89.
Opus 4.6 kembali memberikan jawaban yang benar, dan kali ini juga menyertakan visual yang membantu:
Tes berikutnya merangkai matematika faktorial, manipulasi string, dan bilangan prima:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Berikut cara kami memverifikasi 425 sebagai jawaban benar: 5! = 120; kurangi 1 menjadi 119; balik digitnya menjadi 911. Lalu, menggunakan R (ditunjukkan di bawah), kami bisa melihat ada 152 bilangan prima antara 10 dan 911, dan jumlahnya 64.598. Terakhir, menggunakan R lagi, kami bagi dan bulatkan: 64.598 ÷ 152 ≈ 425.

Berikut skrip R yang kami gunakan:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Tes berikutnya menargetkan salah satu klaim utama Opus 4.6: mendiagnosis bug dalam kode. Kami tahu bahwa model sering melacak kode baris demi baris dengan benar tetapi gagal mengaitkan pelacakan tersebut ke cacat yang mendasarinya.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Berikut jawabannya dan mengapa ini berfungsi sebagai tes: fungsi selalu membagi dengan window (3), bahkan ketika potongannya kurang dari 3 elemen di awal daftar. Keluaran yang buggy adalah [3.33, 10.0, 20.0, 30.0, 40.0], tetapi dua nilai pertama seharusnya 10.0 dan 15.0 karena potongan tersebut masing-masing hanya berisi 1 dan 2 elemen. Perbaikannya adalah mengubah / window menjadi / len(chunk).
Kami menyukai tes ini karena model sering melacak loop dengan sempurna, tetapi kemudian melaporkan "keluaran terlihat benar" — mereka melihat matematikanya terjadi langkah demi langkah dan tidak menandai bahwa membagi satu elemen dengan 3 itu salah. Ini mengharuskan model untuk menahan niat (apa yang seharusnya dilakukan running average) bersama dengan eksekusi (apa yang sebenarnya dilakukan kode) dan melihat celah di antara keduanya.

Tes terakhir kami tidak mengandung matematika, hanya penalaran kontrafaktual.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Memang, tidak ada satu jawaban yang pasti di sini, dan sulit bagi kita untuk membayangkannya. Namun kami mencari model yang setidaknya mampu menalar implikasinya, dan kami rasa jawaban Claude Opus 4.6 cukup masuk akal.
Singkatnya, Opus 4.6 meraih skor sempurna, meskipun, seperti yang Anda lihat, kami menyertakan satu pertanyaan dengan jawaban yang agak subjektif, sehingga Anda bisa menjadi penilai akhir.

Opus 4.6 menjadi pemimpin tak terbantahkan di setidaknya empat tolok ukur penting:
Terminal-Bench 2.0 adalah tolok ukur pengkodean agen; Humanity’s Last Exam adalah tes penalaran kompleks; GDPval-AA menguji performa pekerjaan berbasis pengetahuan; BrowseComp mengukur kemampuan model menemukan info yang sulit ditemukan di internet.
Model-model Claude memiliki reputasi yang layak sebagai salah satu pengode terbaik. Jadi mari mulai dengan melihat hasil tolok ukur Terminal-Bench 2.0.
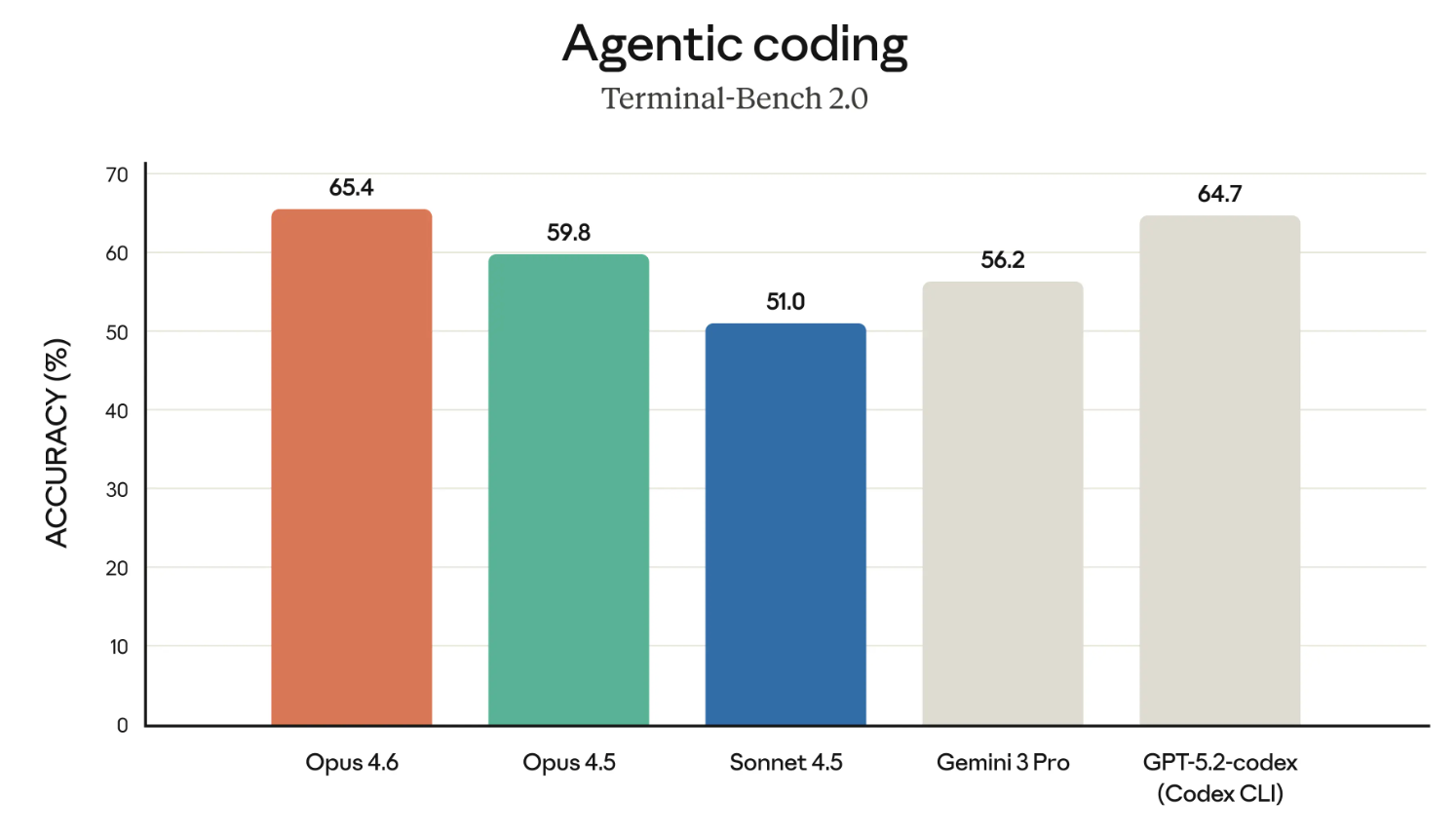
Jika grafik di atas tampak menyoroti Opus 4.6 terkait GPT-5.2-codex — yah, itu jelas disengaja. Anthropic secara langsung menantang OpenAI di beberapa area akhir-akhir ini, dan sedang membangun argumen untuk penggunaan enterprise.
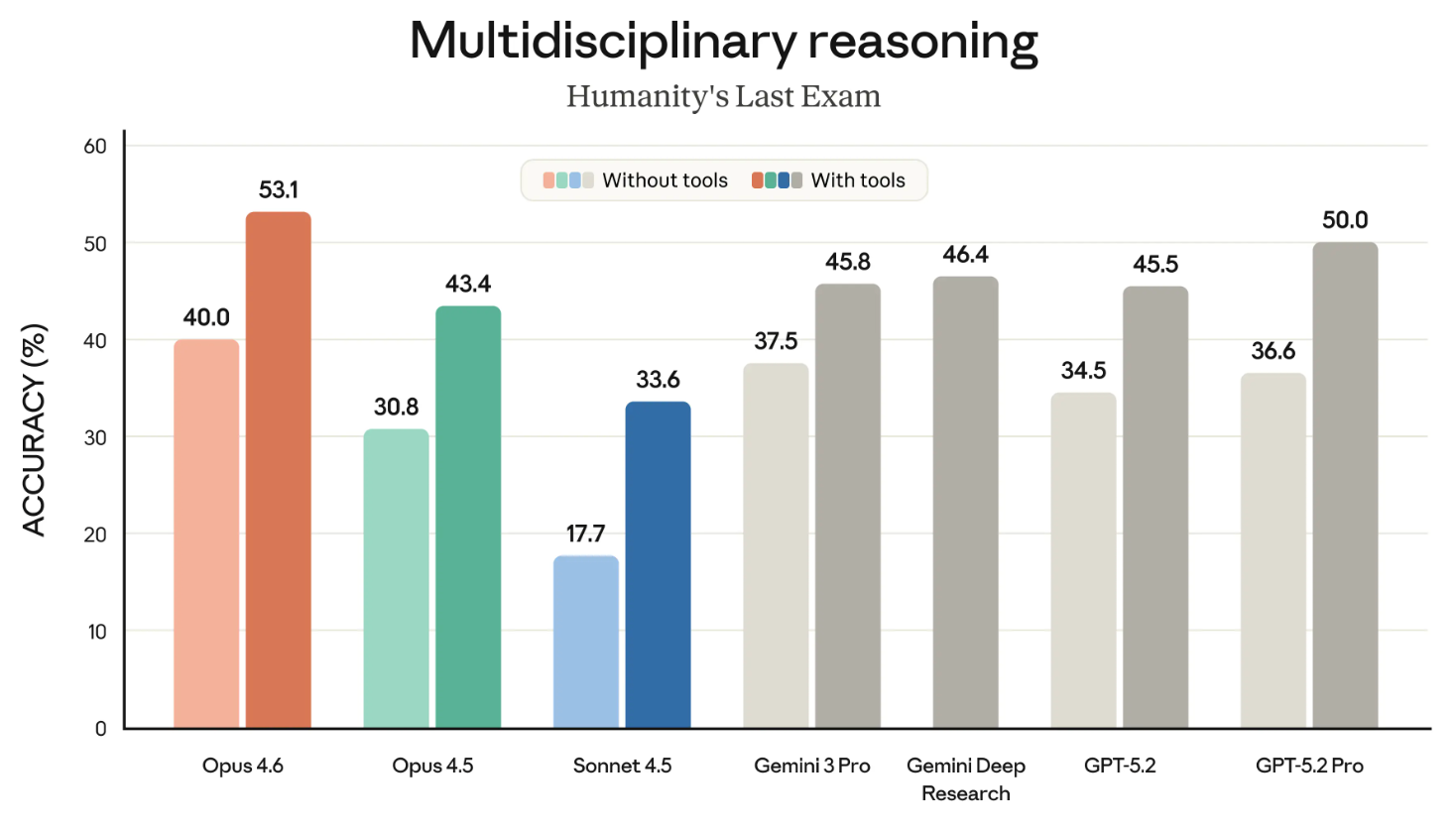
Humanity’s Last Exam adalah salah satu tolok ukur paling dikenal, dan ini yang kami semua amati dengan saksama. Tolok ukur ini mengukur kemampuan model untuk bernalar secara umum.
Grafik berikut menunjukkan keberhasilan berbagai model frontier pada tolok ukur HLE baik dengan maupun tanpa alat. (‘Dengan alat’ berarti model diizinkan menggunakan kemampuan eksternal seperti penelusuran web dan eksekusi kode.)
Grafik ini mungkin lebih baik jika dipecah menjadi dua. Terlepas dari poin kecil itu, intinya jelas: Opus 4.6 adalah pemimpin dalam kategori ‘dengan alat’ maupun ‘tanpa alat’.
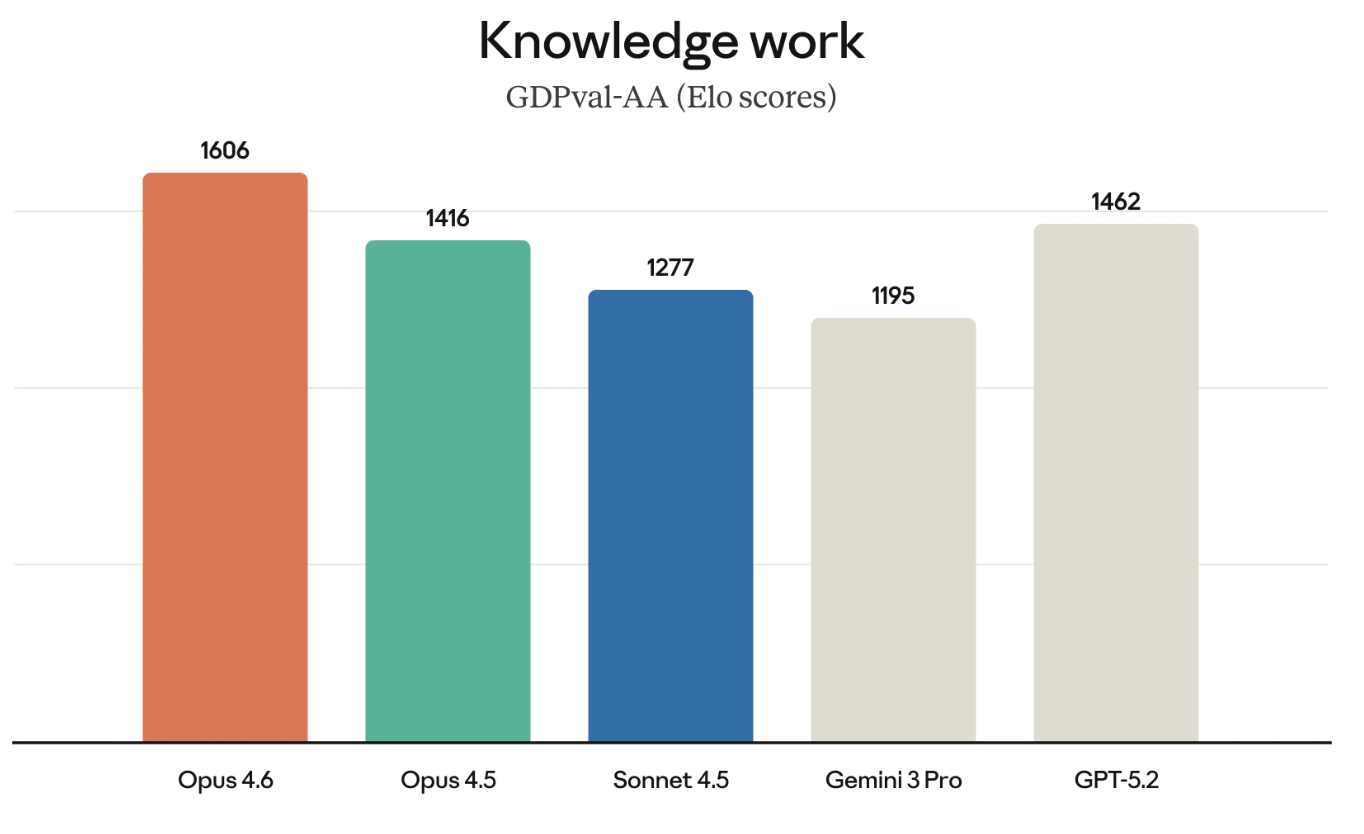
GDPval-AA (sesuai namanya) adalah tes tentang apa yang dianggap sebagai pekerjaan pengetahuan yang bernilai secara ekonomi. Pikirkan hal-hal seperti menjalankan model finansial atau melakukan riset.
GDPval-AA dan tolok ukur serupa lainnya semakin penting karena benar-benar mengukur jenis pekerjaan yang dibayar oleh perusahaan. Keberhasilan Opus 4.6 pada GDPval-AA juga merupakan tantangan langsung lainnya terhadap suite model GPT karena OpenAI dan Anthropic bersaing untuk banyak pelanggan yang sama.
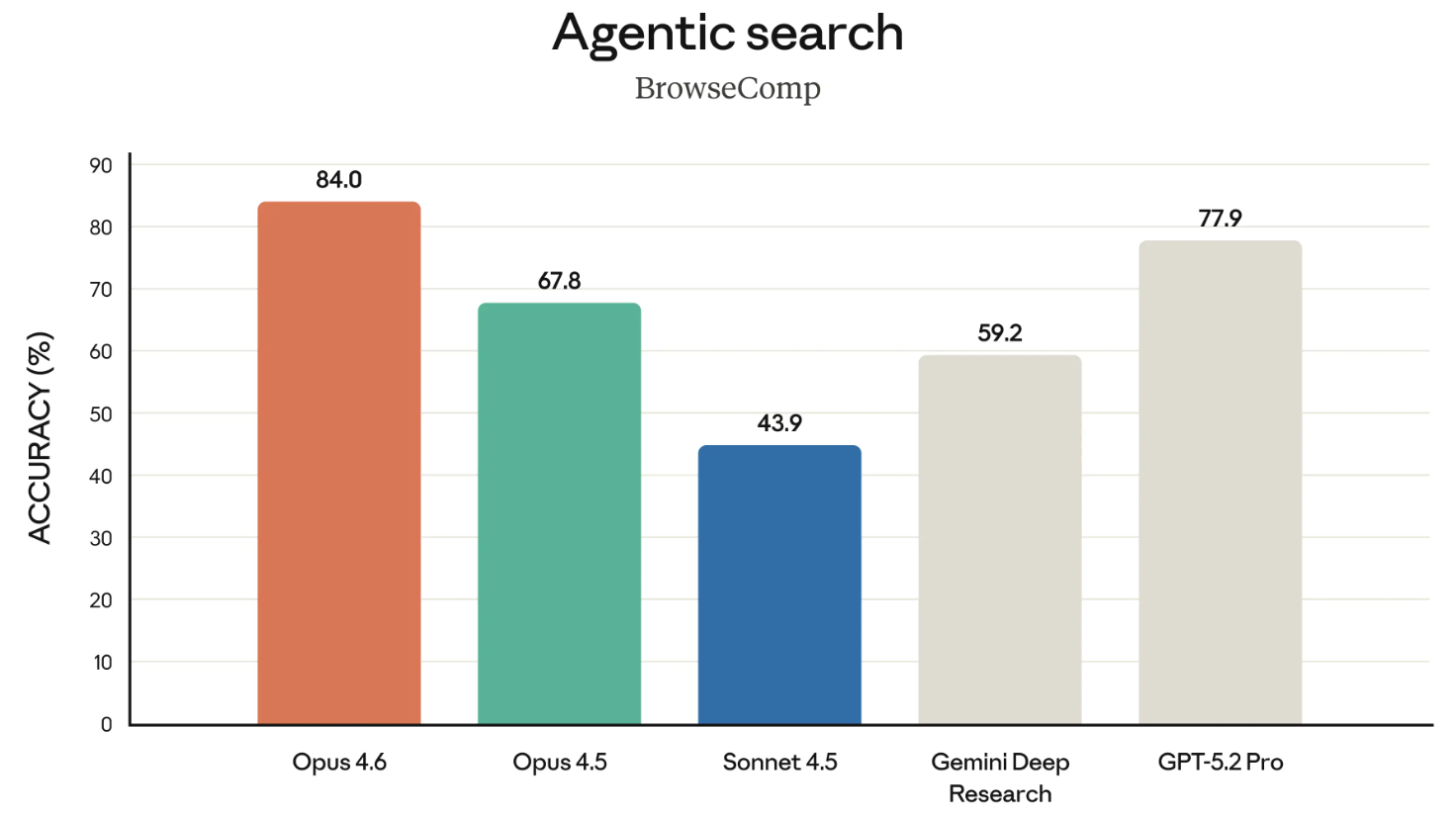
BrowseComp adalah tolok ukur terakhir yang layak disebut dari rilis ini. Tolok ukur ini mengukur kemampuan model menelusuri info yang sulit ditemukan di internet. Sedikit sejarah: OpenAI sebenarnya mengembangkan BrowseComp untuk memamerkan kemampuan pencarian model mereka sendiri.
Dalam langkah yang menyindir, di rilis ini, Anthropic secara langsung menautkan ke pengumuman OpenAI pada April 2025 tentang pengembangan BrowseComp saat menyoroti bahwa Opus 4.6 menempati puncak pada tolok ukur tersebut. Ini sedikit gerakan sinis, mengutip tolok ukur milik OpenAI untuk menantang mereka kembali.
Opus 4.6 tersedia luas pada saat artikel ini ditulis. Namun, Anda tidak dapat mengakses Opus 4.6 tanpa meningkatkan ke akun pro, yang hadir dengan manfaat lain, seperti memungkinkan Anda menggunakan Claude in Excel.
Jika Anda seorang pengembang, Anda harus menggunakan claude-opus-4-6 di Claude API. Harganya tidak berubah: Masih $5/$25 per satu juta token. Jika Anda bingung tentang dua angka itu, ketahuilah bahwa angka pertama adalah yang Anda bayar untuk mengirim token ke model (maksudnya prompt Anda), dan yang kedua adalah yang Anda bayar untuk token yang dihasilkan kembali (tanggapan).
Claude Opus 4.6 berada di puncak papan peringkat pada tolok ukur penting seperti GPDVal-AA, yang mengukur seberapa baik model berkinerja pada tugas yang penting secara ekonomi, yaitu hal yang diperhatikan pelanggan perusahaan besar. OpenAI mungkin terusik oleh perkembangan ini karena hanya beberapa jam sebelum rilis Opus 4.6, mereka mengumumkan OpenAI Frontier, yaitu platform enterprise baru untuk membangun, menerapkan, dan mengelola agen AI di produksi.
Dengan kata lain, alih-alih bersaing pada tolok ukur model, Frontier menunjukkan bahwa OpenAI berfokus pada infrastruktur di sekitar suite modelnya, khususnya dengan memberikan konteks bisnis bersama kepada agen AI, perizinan, dan kemampuan menerima serta belajar dari umpan balik seiring waktu. Kehilangan posisi pada tolok ukur, OpenAI memberi sinyal bahwa platformnya lebih siap untuk benar-benar membuat agen berguna di perusahaan.
Apakah itu sebuah poros strategi atau pengakuan terselubung bahwa mereka kalah dalam perlombaan model, terserah Anda untuk menilainya.
Secara keseluruhan, kami terkesan dengan apa yang ditawarkan Anthropic melalui Claude Opus 4.6, dan kami menantikan untuk mencoba langsung tim agen. Jika Anda ingin mempelajari lebih lanjut tentang keluarga Claude, pastikan untuk melihat kursus Introduction to Claude Models.
Belajar AI dengan DataCamp
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
