

Cursus
Generatieve AI-concepten
2 Hr
110.7K
Geruchten over de volgende release van Anthropic deden de afgelopen dagen de ronde. Terwijl velen Claude Sonnet 5 verwachtten, komt de eerste release van het jaar in de vorm van Claude Opus 4.6.
Met een contextvenster van 1 miljoen tokens, adaptief denken, gesprekscompressie en een reeks toonaangevende benchmarks is Claude Opus 4.6 een verbetering ten opzichte van Opus 4.5. Zoals Anthropic het noemt, hebben ze hun slimste model geüpgraded. Daarnaast lanceerde Anthropic ook agentteams in Claude Code en Claude in PowerPoint.
In dit artikel behandelen we alles wat nieuw is in Claude Opus 4.6: we bekijken de nieuwe functies, verkennen de benchmarks en onderwerpen het model aan de nodige praktijktests.
Wil je meer weten over de nieuwste Claude-functies? Bekijk dan onze gidsen over Claude Cowork en Claude Code, en ook onze OpenClaw-tutorial. Voor een vergelijking met andere concurrenten, lees onze gidsen over Muse Spark vs Claude Opus 4.6 en GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 is het nieuwste large language model van Anthropic. Het volgt op Opus 4.5 en is een aanzienlijke upgrade van de ‘slimste’ modelcategorie van het bedrijf.
Volgens de releaseblog legt Anthropic meer nadruk op agentisch coderen, diep redeneren en zelfcorrectie. Dat betekent een verschuiving van actie naar duurzame actie.
Opus 4.6 is ontworpen om zorgvuldiger te plannen, heeft betere coherentie over langere perioden en kan fouten in zijn eigen werking opsporen. Dit alles zorgt ervoor dat Claude Opus 4.6 verschillende benchmarks aanvoert, waaronder de hoogste score op de Terminal-Bench 2.0-codeerevaluatie, en dat het alle andere grensmodellen verslaat op Humanity’s Last Exam.
Wat mij het meest opvalt, is het verbeterde contextvenster in Claude Opus 4.6. Met 1 miljoen tokens in de bèta staat het nieuwe model op gelijke voet met Gemini 3, wat betekent dat het meer info kan verwerken zonder de context uit het oog te verliezen.
Claude Opus 4.6 kent verschillende opvallende nieuwe functies, waarvan veel gericht zijn op agentische workflows. Dit zijn de belangrijkste punten:
Agentteams zijn een verbetering van de ‘subagents’ die we in eerdere versies van Claude zagen. Met agentteams kun je meerdere, volledig onafhankelijke Claude-instanties opstarten die parallel kunnen werken. Eén sessie is de ‘lead’-agent die coördineert, terwijl ‘teamgenoten’ de daadwerkelijke uitvoering doen.
Wat ik vooral interessant vind, is dat elk teamlid een eigen contextvenster heeft, waardoor grondigere uitvoering mogelijk is. Elke teamgenoot kan ook direct met anderen in het team communiceren.
Natuurlijk heeft deze functie ook een mogelijk nadeel: de kosten. Omdat elke agent een eigen contextvenster heeft, verbruik je al snel veel tokens. Anthropic raadt daarom aan om deze te gebruiken bij scenario’s met een hogere complexiteit.
Een handige functie van Claude Opus 4.6 is contextcompressie. Deze quality-of-life-upgrade voorkomt problemen wanneer je lange workflows draait die contextvensters maximaal belasten. Gewoonlijk loop je dan tegen een contextmuur aan waarbij de prestaties verslechteren.
Met gesprekscompressie kan Claude Opus 4.6 automatisch detecteren wanneer een gesprek een tokendrempel nadert en het bestaande gesprek samenvatten tot een beknopt blok (een compressieblok).
Deze functie helpt de essentie van je interacties te bewaren en creëert tegelijk ruimte om je werk voort te zetten. Als je taakgerichte agents wilt gebruiken die lang moeten draaien, kan dit ze beter op koers houden met een sterk verbeterd geheugen.
Twee functies van Claude Opus 4.6 bepalen of uitgebreid denken nodig is en hoe intensief het dat denken inzet.
Adaptief denken laat het model bepalen hoe complex je prompt is. Op basis van de eenvoud of complexiteit beslist het of uitgebreid denken nodig is. In plaats van een handmatige instelling voor hoeveel tokens het hiervoor gebruikt, past Claude zijn budget aan op basis van de complexiteit van elke aanvraag.
Met de parameter ‘effort’ kun je instellen hoe gretig of voorzichtig Claude is met het besteden van tokens. Hiermee balanceer je in feite tokenefficiëntie en de degelijkheid van antwoorden.
Als je Claude Opus 4.6 in de API gebruikt, kun je deze parameters handmatig instellen. Bijvoorbeeld:
Onlangs bespraken we Claude in Excel, waarin we lieten zien hoe de add-on je kan helpen met verschillende taken in een zijpaneel van je Excel-spreadsheet. Naast verbeterde functionaliteit van deze tool kondigde Anthropic Claude in PowerPoint aan.
Deze integratie respecteert je diamodellen, lettertypen en lay-outs. Je kunt een bedrijfstemplate aanleveren en vragen een specifieke sectie te bouwen, of een dia selecteren en vragen om dichte tekst om te zetten in een native, bewerkbaar diagram.
De nadruk op het genereren van bewerkbare PowerPoint-objecten in plaats van alleen "plaatjes van dia’s" maakt dit tot een echte productiviteitstool in plaats van slechts een ideeëngenerator.
Claude in PowerPoint is momenteel in research preview voor Max- en Enterprise-gebruikers.
Veel van de belangrijkste claims van Opus 4.6 draaien om zwaardere codeertaken en dieper redeneren. Deze vaardigheden steunen op een fundament: het vermogen om meerdere beperkingen tegelijk te overzien, over veel stappen te redeneren en fouten te vinden.
Met dat in gedachten hebben we Opus 4.6 getest met een reeks meerstapslogica-, wiskunde- en codeeruitdagingen. We wilden kijken of we enkele bekende en veelvoorkomende zwaktes van LLM’s konden blootleggen – zaken als cascaderende rekenfouten, ruimtelijk redeneren (altijd een probleem) en vragen met beperkingen. We namen ook een specifieke debuggingtaak op, omdat Anthropic in de aankondiging opschepte over hoe goed Opus 4.6 is in root cause-analyse en andere debugproblemen.
Onze eerste test combineert priemgetallen, hexadecimaal en tellen:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Het klinkt wat complex, maar deze test is voor ons mensen vrij makkelijk te verifiëren. Het juiste antwoord is 2, omdat de 6e priem 13 is; 13 in het kwadraat is 169, wat in hex "A9" is. Dat heeft 1 letter × 1 cijfer, wat 1 is als je ze vermenigvuldigt, en de eerste priem is 2.
De zorg is dat een model kan struikelen over de hex-conversie, wat tot een volledig fout eindantwoord kan leiden. Zoals je ziet had Opus 4.6 hier geen moeite mee:

Onze tweede test onderzoekt ruimtelijk redeneren en omgaan met negatieve getallen:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Deze kostte iets meer werk om te verifiëren. Het juiste antwoord is -6.065. We weten dit omdat de geroteerde matrix [[1, 4], [5, 2]] is; met Python kunnen we dan de determinant vinden, die -18 is, en als we dit getal tot de derde macht verheffen, krijgen we -5.832; ten slotte trekken we er 233 van af en krijgen we -6.065.
We vonden dit een goed idee voor een test, omdat we weten dat modellen vaak matrixelementen verkeerd verwisselen of het minteken halverwege kwijtraken. Opnieuw had Opus 4.6 geen moeite:

Voor onze derde test probeerden we een constraint-satisfactionprobleem dat backtracking vereist:
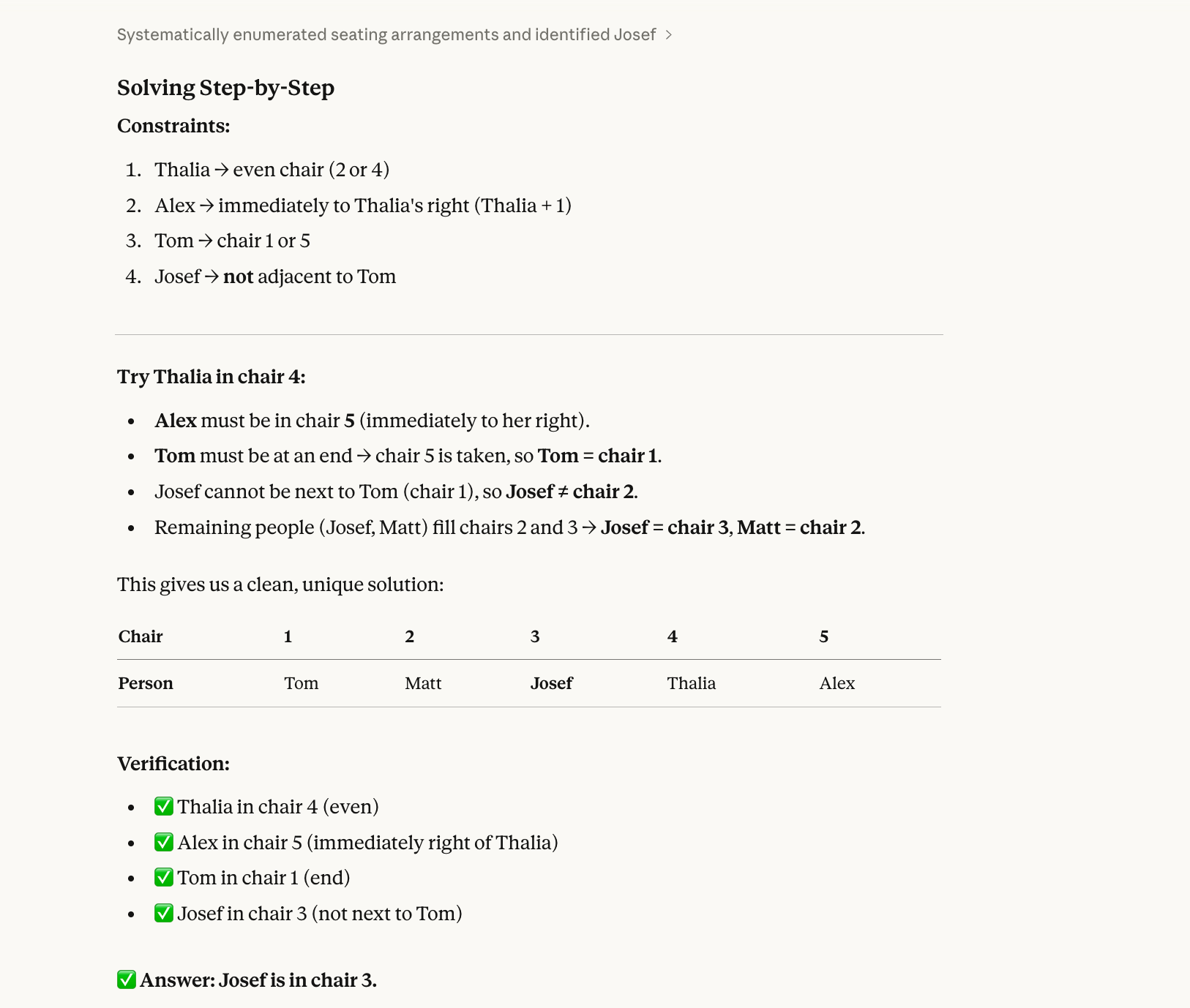
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?Het juiste antwoord is Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Met wat moeite kun je dit op papier uitwerken.
De voornaamste reden dat een model dit soort vraag fout kan hebben, is dat modellen historisch sequentieel oplossen in plaats van holistisch. Ze lezen "Thalia zit op een even stoel" en kiezen er één (bijv. stoel 2) zonder te controleren of die keuze past bij alle andere beperkingen. Dan leggen ze zich erop vast, vullen meer stoelen in en lopen uiteindelijk tegen een conflict aan, maar dan hebben ze zichzelf al klemgezet en proberen ze Thalia niet alsnog op stoel 4.
Opus 4.6 had deze ook goed:
Onze vierde test evalueert ruimtelijke visualisatie en fysieke intuïtie:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Om deze te verifiëren heb ik letterlijk mijn horloge afgedaan en rondgedraaid.
Het juiste antwoord is 14:30. Om 3:15 wijst de minutenwijzer naar de "3". Toen ik de 12 naar het raam links van me draaide, verschoof de "3" naar waar de "12" stond. Ik telde vervolgens 0 op bij 3:15, trok 45 minuten af en kwam uit op 14:30.
Bij het ontwerpen van de test verwachtten we dat modellen het draaien van de klokplaat zouden verwarren met het verplaatsen van de wijzer. We hebben ook gehoord dat modellen het optellen van 0 verdacht vinden en daarom een ander getal willen forceren.
Toch wist Opus 4.6 dit probleem op te lossen; ook hier kwam het met het juiste antwoord:

Onze vijfde test combineert modulaire rekenkunde met priemfiltering:
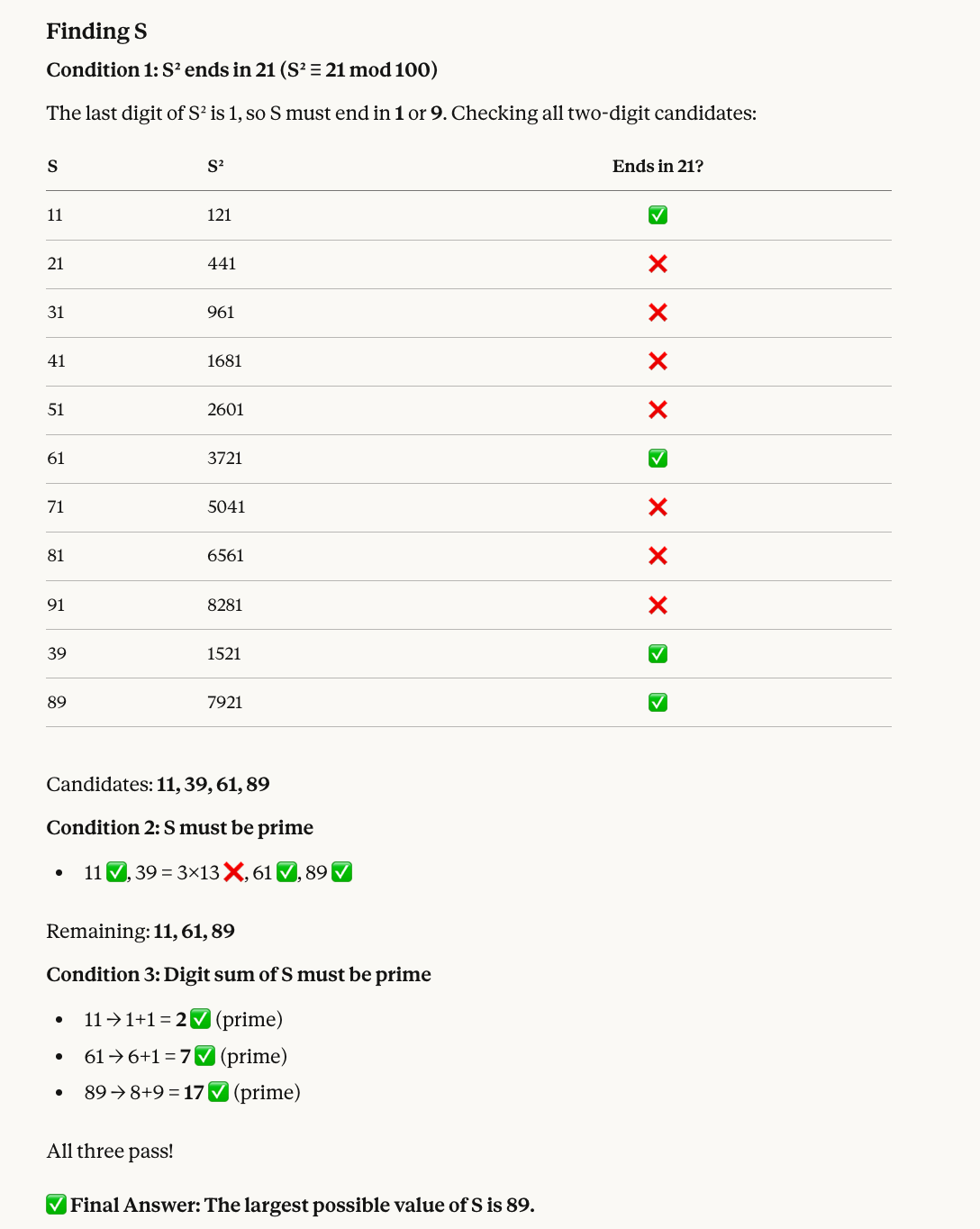
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Zo weten we dat 89 het juiste getal is: Getallen waarvan het kwadraat eindigt op 21 zijn onder meer 11, 39, 61 en 89. Daarvan is 39 geen priem, dus blijven 11, 61 en 89 over. Alle drie hebben ze een cijfersom die priem is (2, 7 en 17), dus de grootste is 89.
Opus 4.6 gaf opnieuw het juiste antwoord en voegde dit keer ook een handig visueel element toe:
De volgende test koppelt factorial-rekenwerk, stringmanipulatie en priemgetallen:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Zo hebben wij 425 als juiste antwoord geverifieerd: 5! = 120; trek er 1 af en je krijgt 119; draai de cijfers om en je krijgt 911. Met wat R-code (zie hieronder) zagen we dat er 152 priemgetallen zijn tussen 10 en 911, en hun som is 64.598. Ten slotte delen en afronden in R: 64.598 ÷ 152 ≈ 425.

Hier is het R-script dat we gebruikten:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Onze volgende test richt zich op een van de belangrijkste claims van Opus 4.6: bugs in code diagnosticeren. We weten dat modellen code vaak regel voor regel correct volgen, maar er niet in slagen die trace te koppelen aan het onderliggende probleem.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Dit is het antwoord en waarom het een goede test is: de functie deelt altijd door window (3), zelfs wanneer het segment aan het begin van de lijst minder dan 3 elementen bevat. De foutieve output is [3.33, 10.0, 20.0, 30.0, 40.0], maar de eerste twee waarden zouden 10.0 en 15.0 moeten zijn, aangezien die segmenten respectievelijk slechts 1 en 2 elementen bevatten. De oplossing is / window vervangen door / len(chunk).
We vinden deze test sterk omdat modellen vaak de lus perfect natrekken, maar dan melden dat "de output er goed uitziet" — ze zien de wiskunde stap voor stap gebeuren en markeren niet dat één element door 3 delen verkeerd is. Het vereist dat het model intentie (wat een voortschrijdend gemiddelde zou moeten doen) naast uitvoering (wat de code daadwerkelijk doet) houdt en het gat daartussen spot.

Onze laatste test bevat geen wiskunde, alleen contrafeitelijk redeneren.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Toegegeven, hier is geen eenduidig juist antwoord op, en het is lastig je dit voor te stellen. Maar we willen dat het model in elk geval de implicaties doorredeneert, en we vinden dat het antwoord van Claude Opus 4.6 redelijk genoeg is.
Alles bij elkaar behaalde Opus 4.6 een perfecte score, al zat er, zoals je zag, één vraag tussen waar het antwoord wat subjectief is, dus oordeel zelf maar.

Opus 4.6 is de onbetwiste leider op minstens vier belangrijke benchmarks:
Terminal-Bench 2.0 is een agentische codeerbenchmark; Humanity’s Last Exam test complex redeneren; GDPval-AA test de prestaties bij kenniswerk; BrowseComp meet het vermogen van een model om moeilijk vindbare info online te achterhalen.
De Claude-modellen hebben terecht de reputatie tot de beste coders te behoren. Laten we dus beginnen met de resultaten van de Terminal-Bench 2.0-benchmark.
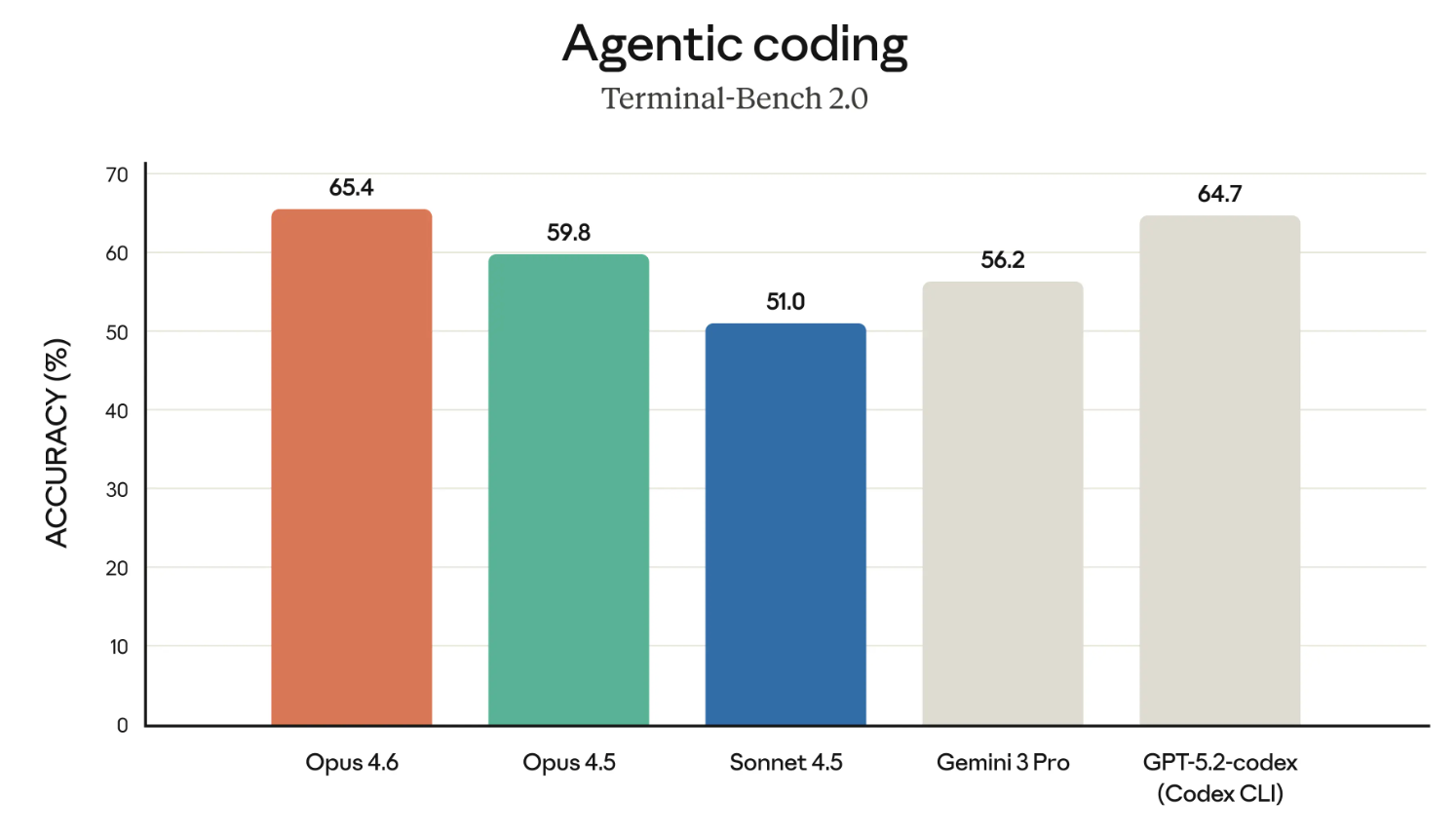
Als de grafiek hierboven Opus 4.6 lijkt uit te lichten ten opzichte van GPT-5.2-codex – dat is vast geen toeval. Anthropic daagt OpenAI de laatste tijd op meerdere fronten direct uit en positioneert zich nadrukkelijk voor enterprise-gebruik.
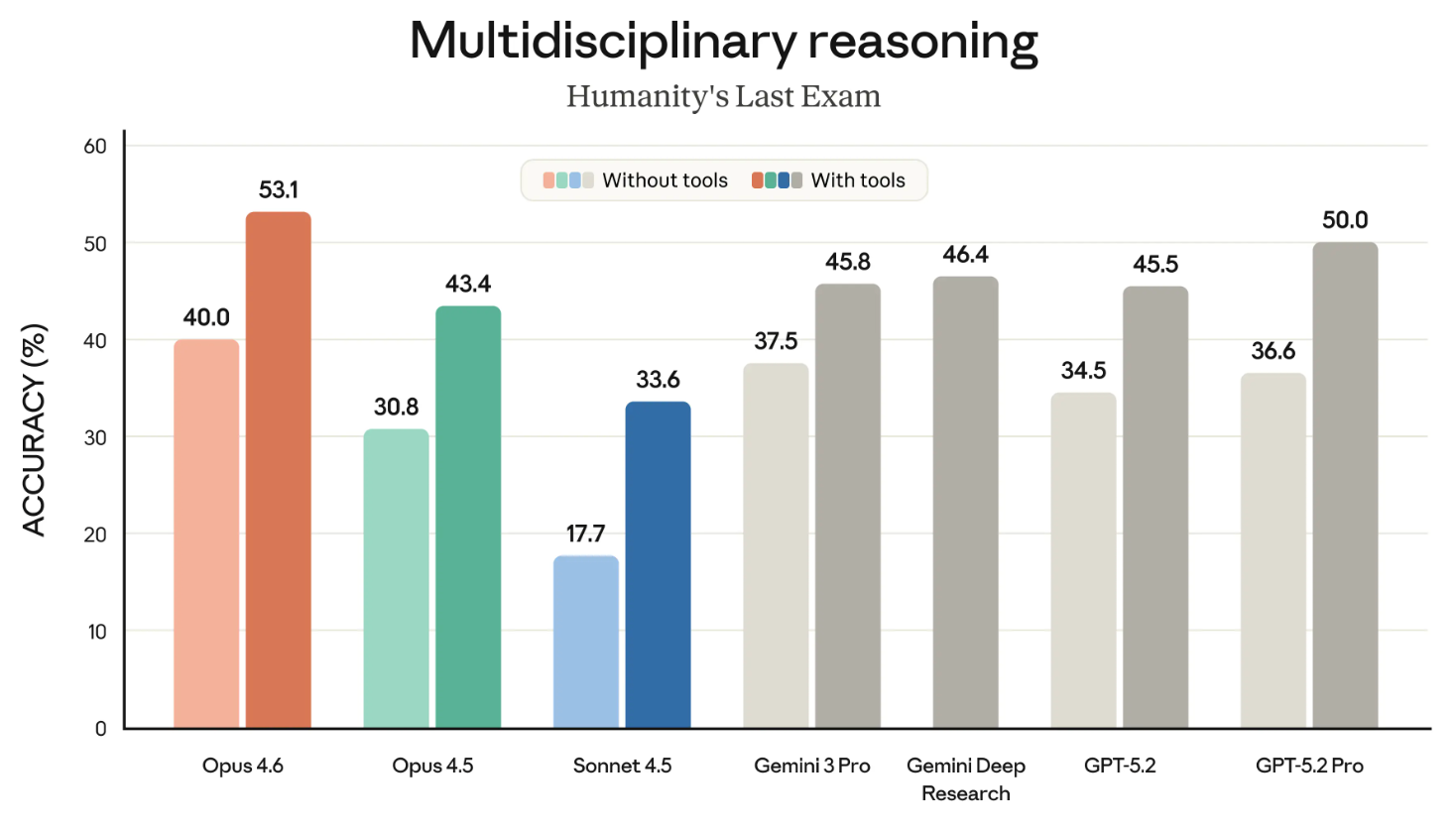
Humanity’s Last Exam is een van de bekendste benchmarks, en eentje die we allemaal goed in de gaten houden. Het meet het algemene redeneervermogen van een model.
De volgende grafiek toont het succes van verschillende grensmodellen op de HLE-benchmark, zowel mét als zonder tools. (‘Met tools’ betekent dat het model gebruik mocht maken van externe mogelijkheden zoals webzoeken en code uitvoeren.)
Misschien was dit beter geweest als twee grafieken. Dat detail terzijde is de conclusie duidelijk: Opus 4.6 is de leider in zowel de categorie ‘mét tools’ als ‘zonder tools’.
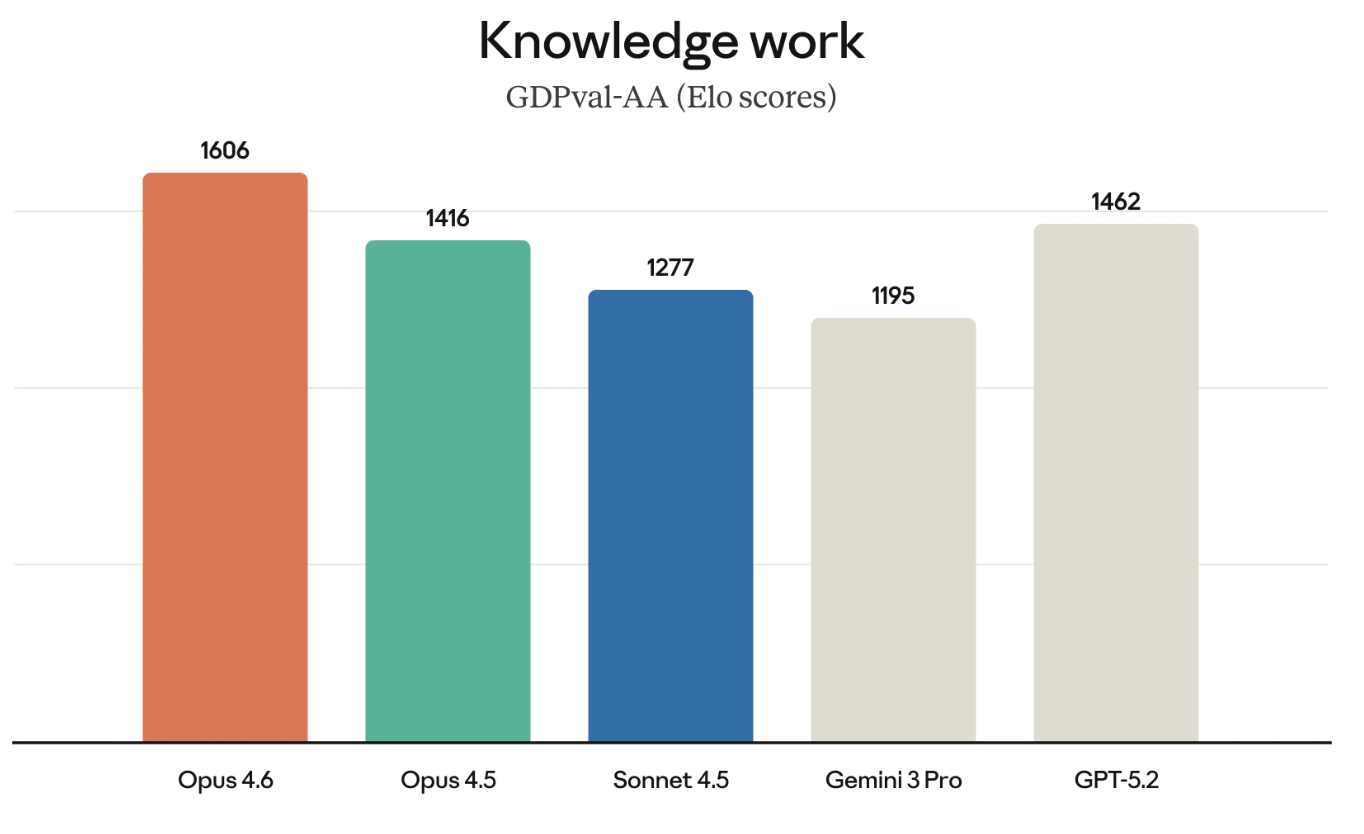
GDPval-AA (de naam zegt het al) is een test van wat wordt beschouwd als economisch waardevol kenniswerk. Denk aan zaken als financiële modellen draaien of onderzoek doen.
GDPval-AA en vergelijkbare benchmarks worden alleen maar belangrijker omdat ze echt meten welk werk bedrijven daadwerkelijk inkopen. Het succes van Opus 4.6 op GDPval-AA is ook weer een directe uitdaging voor de GPT-reeks, want OpenAI en Anthropic concurreren om veel van dezelfde klanten.
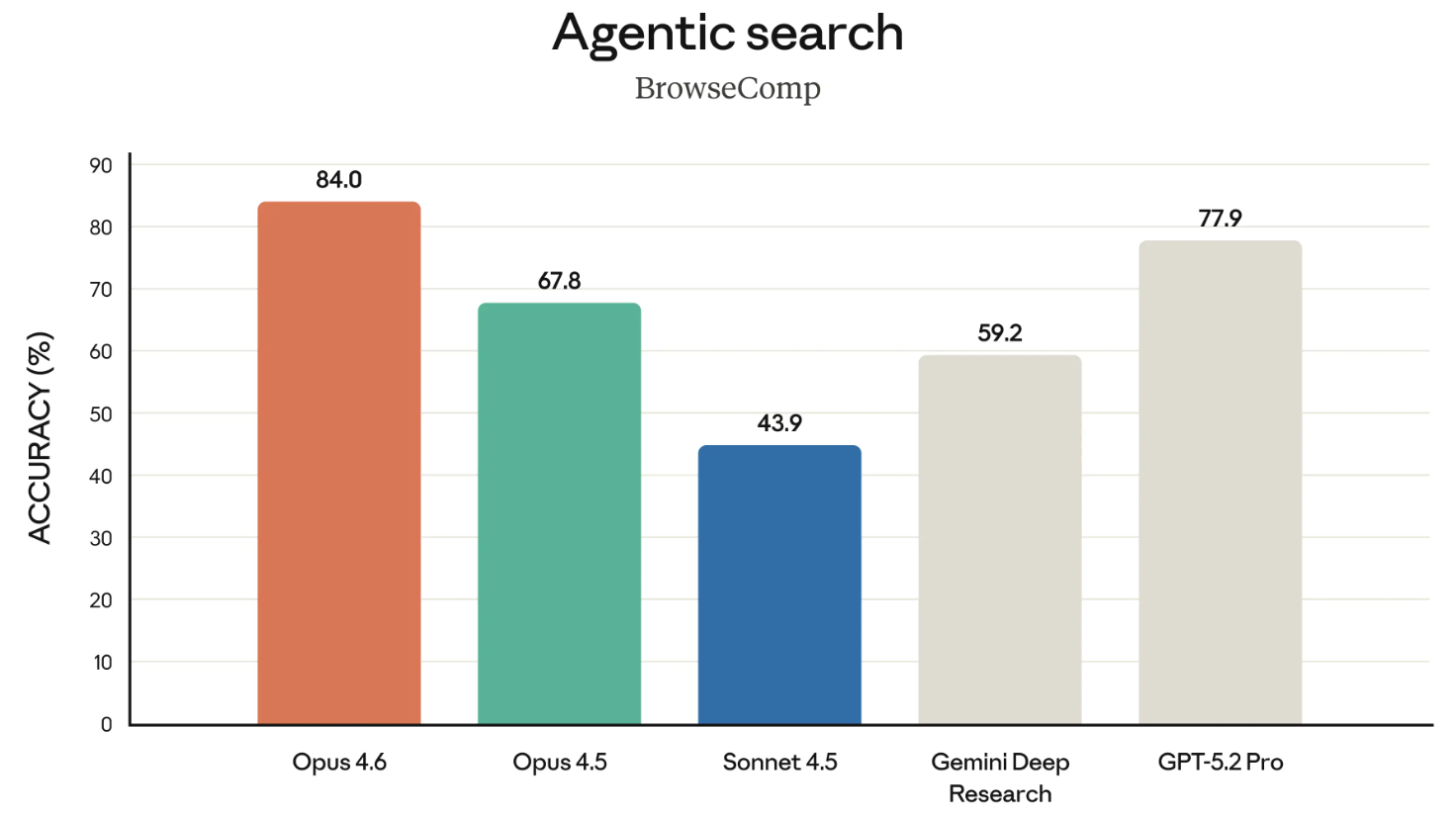
BrowseComp is de laatste benchmark uit de release die het vermelden waard is. Het meet het vermogen van een model om moeilijk vindbare info online op te sporen. Wat geschiedenis: OpenAI ontwikkelde BrowseComp oorspronkelijk om de zoekmogelijkheden van hun eigen modellen te tonen.
In een opvallende zet linkte Anthropic in deze release direct naar OpenAI’s aankondiging van april 2025 over de ontwikkeling van BrowseComp toen het benadrukte dat Opus 4.6 daar bovenaan staat. Een tikje schamper, om zo OpenAI’s eigen benchmark tegen hen te gebruiken.
Opus 4.6 is op het moment van schrijven breed beschikbaar. Je kunt Opus 4.6 echter niet gebruiken zonder te upgraden naar een pro-account, dat ook andere voordelen biedt, zoals de mogelijkheid om Claude in Excel te gebruiken.
Ben je ontwikkelaar, gebruik dan claude-opus-4-6 in de Claude API. De prijs is niet veranderd: nog steeds $5/$25 per miljoen tokens. Als je in de war bent door de twee bedragen: het eerste bedrag is wat je betaalt om tokens naar het model te sturen (je prompts dus) en het tweede is wat je betaalt voor de tokens die het model terug genereert (de antwoorden).
Claude Opus 4.6 staat bovenaan de ranglijsten van belangrijke benchmarks zoals GPDVal-AA, die meet hoe goed een model presteert op economisch belangrijke taken — precies waar grote enterprise-klanten om geven. OpenAI zou hiervan geschrokken kunnen zijn, want slechts enkele uren vóór de release van Opus 4.6 kondigden ze OpenAI Frontier aan, een nieuw enterpriseplatform voor het bouwen, uitrollen en beheren van AI-agents in productie.
Met andere woorden, in plaats van te concurreren op modelbenchmarks, laat Frontier zien dat OpenAI focust op de infrastructuur rond zijn modelreeks, specifiek door AI-agents gedeelde bedrijfscontext, permissies en het vermogen te geven om feedback in de tijd te ontvangen en ervan te leren. Nu het terrein verliest op benchmarks, laat OpenAI doorschemeren dat hun platform beter gepositioneerd is om agents in een bedrijf daadwerkelijk nuttig te maken.
Of dat een strategische koerswijziging is of een stilzwijgende erkenning dat ze de modelrace verliezen, mag je zelf bepalen.
Al met al zijn we onder de indruk van wat Anthropic met Claude Opus 4.6 biedt, en we kijken ernaar uit om met de agentteams aan de slag te gaan. Wil je meer leren over de Claude-familie, bekijk dan zeker de cursus Introduction to Claude Models.
Leer AI met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
