

Corso
Concetti di IA generativa
2 h
110.7K
Negli ultimi giorni sono circolate voci sul prossimo rilascio di Anthropic. Molti si aspettavano Claude Sonnet 5, ma la prima release dell’anno arriva sotto forma di Claude Opus 4.6.
Con una finestra di contesto da 1 milione di token, ragionamento adattivo, compattazione delle conversazioni e una serie di benchmark al top, Claude Opus 4.6 è un miglioramento rispetto a Opus 4.5. Come lo definisce Anthropic, hanno aggiornato il loro modello più intelligente. Insieme al modello, Anthropic ha anche lanciato agent teams in Claude Code e Claude in PowerPoint.
In questo articolo vedremo tutte le novità di Claude Opus 4.6, esaminando le nuove funzionalità, esplorando i benchmark e mettendolo alla prova con diversi esempi pratici.
Per saperne di più su alcune delle ultime funzionalità di Claude, ti consiglio di consultare le nostre guide su Claude Cowork e Claude Code, oltre al nostro tutorial OpenClaw. Per un confronto con altri concorrenti, leggi le nostre guide su Muse Spark vs Claude Opus 4.6 e GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 è l’ultimo large language model di Anthropic. In continuità con Opus 4.5, rappresenta un upgrade significativo al livello di modello “più intelligente” dell’azienda.
Dal blog di rilascio, Anthropic afferma che c’è una maggiore attenzione al coding agentico, al deep reasoning e all’auto-correzione. Ciò significa un passaggio dall’azione all’azione sostenuta.
Opus 4.6 è progettato per pianificare con maggiore attenzione, ha una coerenza migliorata su periodi più lunghi e identifica gli errori nel proprio funzionamento. Tutto ciò significa che Claude Opus 4.6 guida diversi benchmark, incluso il punteggio più alto nella valutazione di coding Terminal-Bench 2.0 e batte tutti gli altri modelli di frontiera su Humanity’s Last Exam.
Una delle cose che mi ha colpito di più è la finestra di contesto migliorata in Claude Opus 4.6. Con 1 milione di token in beta, il nuovo modello si allinea a Gemini 3, il che significa che può elaborare più informazioni senza perdere il contesto.
Ci sono diverse nuove funzionalità degne di nota in Claude Opus 4.6, molte delle quali incentrate su flussi di lavoro agentici. Vediamo alcuni punti chiave:
Gli agent teams sono un miglioramento rispetto ai “subagents” visti nelle versioni precedenti di Claude. Gli agent teams ti permettono di avviare più istanze di Claude completamente indipendenti che possono lavorare in parallelo. Una sessione è l’agente “lead” che coordina le attività, mentre i “compagni di squadra” gestiscono l’esecuzione vera e propria.
Ciò che trovo più interessante è che ogni membro del team ha la propria finestra di contesto, consentendo un’esecuzione più approfondita. Ogni compagno di squadra può anche comunicare direttamente con gli altri del team.
Naturalmente, questa funzione ha un potenziale lato negativo: il costo. Poiché ogni agente ha la propria finestra di contesto, potresti bruciare token rapidamente. Per questo, Anthropic consiglia di usarli in scenari con livelli di complessità più elevati.
Una funzione interessante di Claude Opus 4.6 è la compattazione del contesto. Questo miglioramento della qualità della vita aiuta a evitare problemi quando esegui lunghi flussi di lavoro che saturano le finestre di contesto. In genere, si raggiunge un “muro” di contesto in cui le prestazioni iniziano a degradare.
Con la compattazione delle conversazioni, Claude Opus 4.6 può rilevare automaticamente quando una conversazione sta raggiungendo una soglia di token e riassumere la conversazione esistente in un blocco conciso (un blocco di compattazione).
Questa funzione dovrebbe aiutare a preservare gli elementi essenziali delle tue interazioni liberando al contempo spazio per continuare il lavoro. Se pensi di usare agenti orientati ai task che devono girare a lungo, questo potrebbe mantenerli sulla strada giusta con una memoria molto migliorata.
Ci sono due funzionalità di Claude Opus 4.6 che determinano se serve usare ragionamento esteso e con quanta intensità applicarlo.
Il ragionamento adattivo consente al modello di determinare quanto è complesso il tuo prompt. In base alla semplicità o complessità, deciderà se usare il ragionamento esteso. Anziché avere un’impostazione manuale per quanti token usare a questo scopo, Claude adatterà il proprio budget in base alla complessità di ogni richiesta.
Il parametro effort ti permette di impostare quanto Claude sia incline o conservativo nello spendere token. In sostanza, puoi bilanciare l’efficienza dei token e l’accuratezza/completezza delle risposte.
Quando usi Claude Opus 4.6 nell’API, puoi impostare manualmente questi parametri. Per esempio:
Di recente abbiamo parlato di Claude in Excel, mostrando come il componente aggiuntivo possa aiutarti con varie attività in un pannello laterale del tuo foglio Excel. Oltre a migliorare le funzionalità di questo strumento, Anthropic ha annunciato Claude in PowerPoint.
Questa integrazione rispetta i tuoi master, font e layout delle slide. Puoi fornirle un template aziendale e chiederle di creare una sezione specifica, oppure selezionare una slide e chiederle di convertire testo denso in un diagramma nativo e modificabile.
L’enfasi sulla generazione di oggetti PowerPoint modificabili, piuttosto che semplici “immagini di slide”, rende questo strumento davvero produttivo e non solo un generatore di concept.
Claude in PowerPoint è attualmente in research preview per gli utenti Max ed Enterprise.
Molte delle affermazioni di punta di Opus 4.6 riguardano task di coding più difficili e ragionamenti più profondi. Queste abilità poggiano su una base precisa: la capacità di mantenere in mente vincoli multipli, ragionare su molti passaggi e intercettare gli errori.
Con questo in mente, abbiamo sottoposto Opus 4.6 a una serie di sfide multi-step di logica, matematica e coding. Volevamo vedere se riuscivamo a mettere in luce alcune debolezze note e comuni degli LLM – cose come errori di calcolo a cascata, ragionamento spaziale (sempre problematico) e domande con vincoli. Abbiamo incluso anche un task specifico di debugging, dato che l’annuncio di Anthropic vantava le capacità di Opus 4.6 nell’analisi delle cause radice e in altri problemi di debugging.
Il nostro primo test combina numeri primi, esadecimali e conteggio:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Sembra un po’ complesso, ma è piuttosto facile per noi umani da verificare. Sappiamo che la risposta corretta è 2 perché il 6° numero primo è 13; 13 al quadrato fa 169, che in esadecimale è "A9". Questo ha 1 lettera × 1 cifra, che moltiplicati danno 1, e il primo numero primo è 2.
La preoccupazione è che un modello possa inciampare nella conversione esadecimale, con un errore a cascata nella risposta finale. Come puoi vedere, Opus 4.6 non ha avuto problemi:

Il nostro secondo test valuta il ragionamento spaziale e la gestione dei numeri negativi:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Questo ha richiesto un po’ più di lavoro per essere verificato. La risposta corretta è -6.065. Lo sappiamo perché la matrice ruotata è [[1, 4], [5, 2]]; possiamo poi usare Python per trovare il determinante, che è -18 e, elevandolo al cubo, otteniamo -5.832; infine, sottraiamo 233 e otteniamo -6.065.
Ci piaceva l’idea di questo test perché sappiamo per esperienza che i modelli spesso scambiano erroneamente gli elementi della matrice oppure perdono il segno negativo lungo il percorso. Anche qui, Opus 4.6 non ha avuto problemi:

Per il terzo test, abbiamo provato un problema di soddisfazione di vincoli che richiede backtracking:
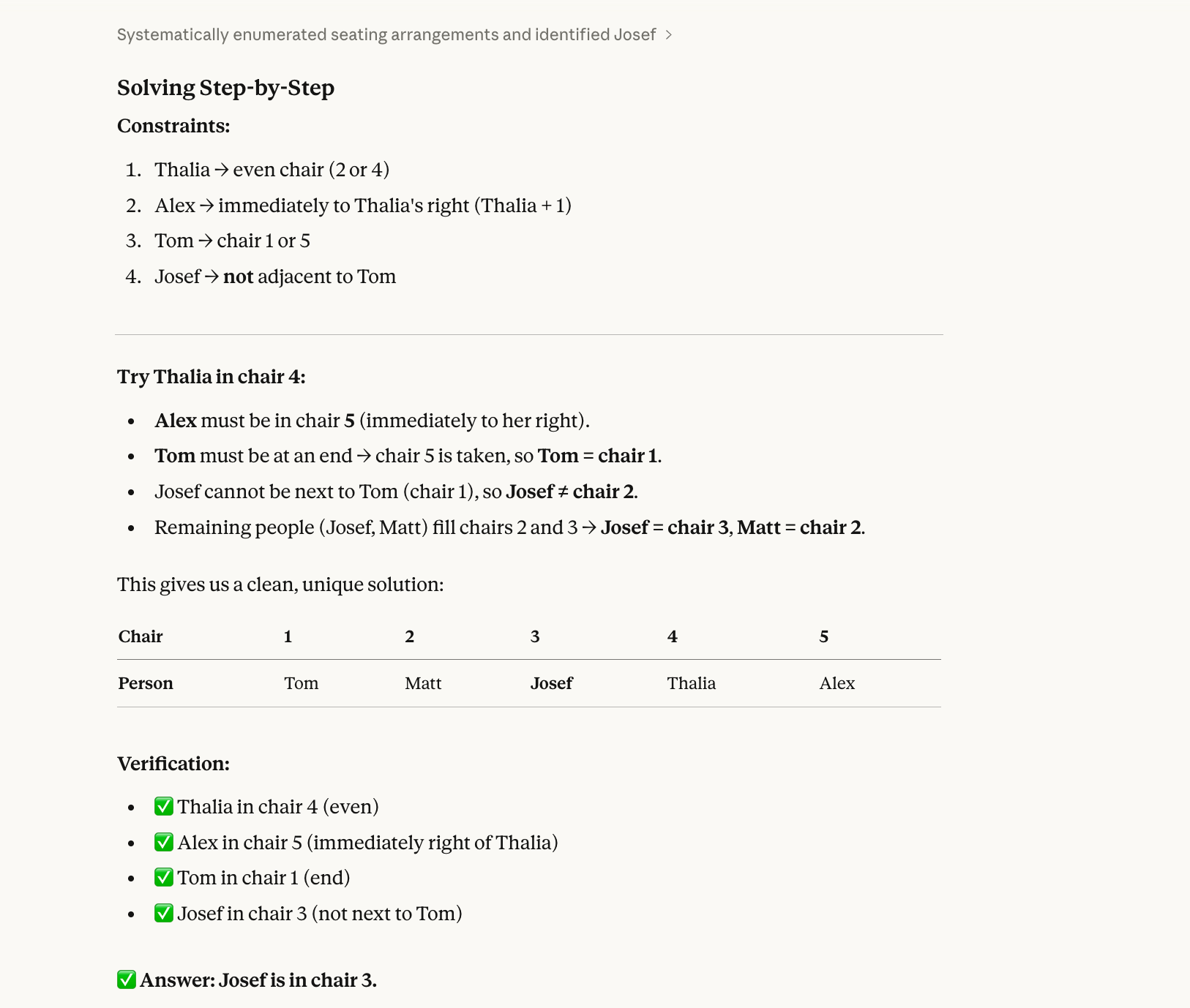
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?La risposta corretta a questo test è Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Con un po’ di impegno si può risolvere anche su carta.
Il motivo per cui un modello può sbagliare questo tipo di domanda è che storicamente risolvono in modo sequenziale, non olistico. Leggono "Thalia è su una sedia pari" e ne scelgono una (diciamo la 2) senza verificare se quella scelta sia compatibile con tutti gli altri vincoli. Poi vi si aggrappano, riempiono altre sedie e alla fine incontrano un conflitto, ma a quel punto si sono incastrati e non tornano indietro per provare Thalia sulla sedia 4.
Opus 4.6 ha risposto correttamente anche qui:
Il nostro quarto test valuta la visualizzazione spaziale e l’intuizione fisica:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Per verificarlo, ho letteralmente tolto l’orologio dal polso e l’ho ruotato.
La risposta corretta è 14:30. Alle 3:15, la lancetta dei minuti punta sul "3". Quando ho puntato il 12 verso la finestra alla mia sinistra, il "3" si è spostato dove stava il "12". Ho poi aggiunto 0 a 3:15, sottratto 45 minuti, e ho ottenuto 14:30.
Progettando il test, ci aspettavamo che i modelli confondessero la rotazione del quadrante con lo spostamento della lancetta. Sappiamo anche che tendono a considerare sospetto l’aggiungere 0 e quindi provano a forzare un numero diverso.
Tuttavia, Opus 4.6 è riuscito a risolvere il problema; ha dato la risposta corretta anche qui:

Il quinto test combina aritmetica modulare e filtraggio dei numeri primi:
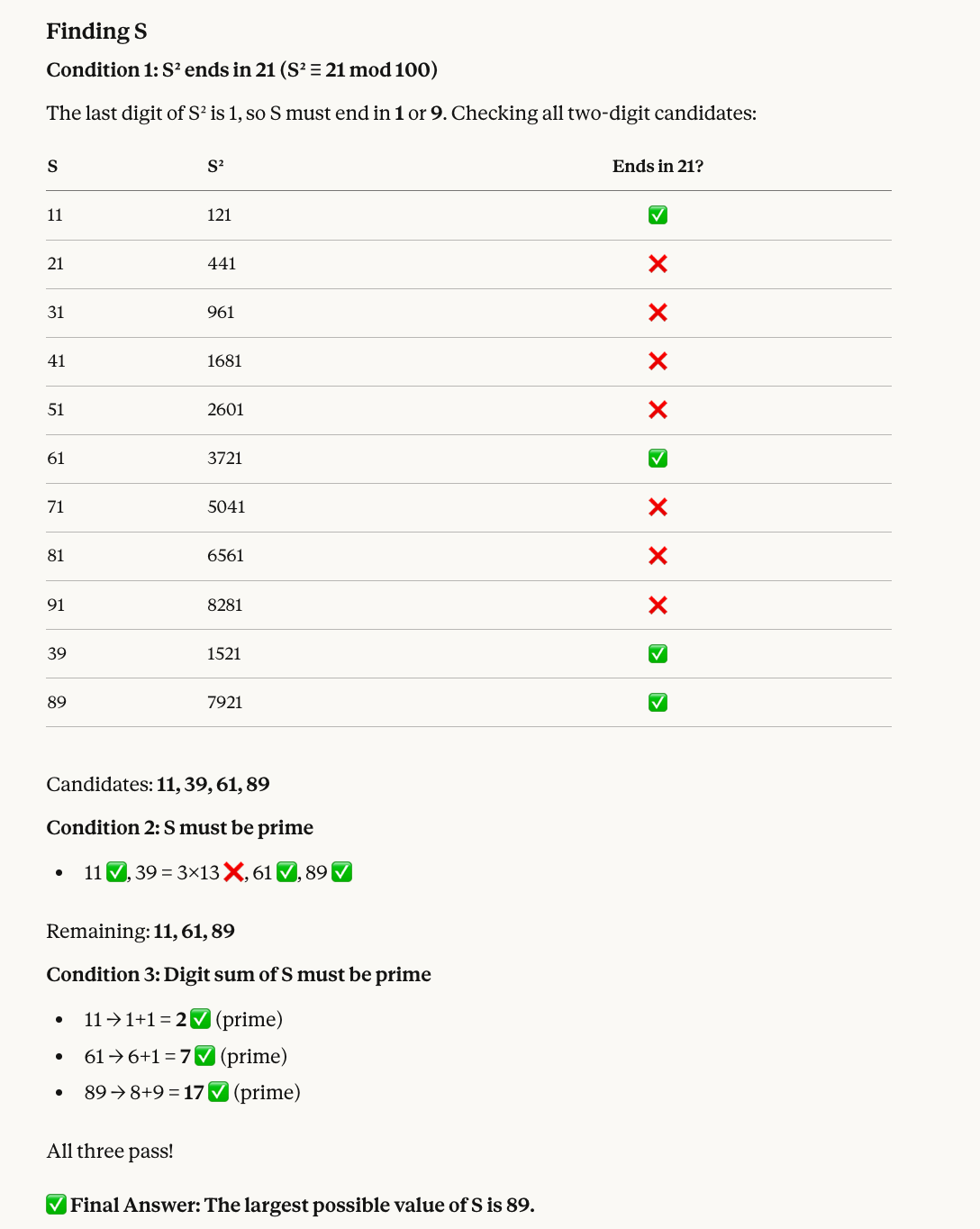
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Ecco perché il numero corretto è 89: i numeri il cui quadrato termina in 21 includono 11, 39, 61 e 89. Tra questi, 39 non è primo, quindi restano 11, 61 e 89. Tutti e tre hanno somme delle cifre prime (2, 7 e 17, rispettivamente), quindi il più grande è 89.
Opus 4.6 ha dato ancora una volta la risposta giusta, includendo anche un utile visual:
Il test successivo mette in sequenza fattoriali, manipolazione di stringhe e numeri primi:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Ecco come abbiamo verificato 425 come risposta corretta: 5! = 120; sottrai 1 per ottenere 119; inverte le cifre per ottenere 911. Poi, usando un po’ di codice R (mostrato sotto), abbiamo visto che ci sono 152 numeri primi tra 10 e 911, e la loro somma è 64.598. Infine, sempre in R, dividiamo e arrotondiamo: 64.598 ÷ 152 ≈ 425.

Ecco lo script R che abbiamo usato:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Il test successivo prende di mira una delle affermazioni principali di Opus 4.6: diagnosticare bug nel codice. Sappiamo che i modelli spesso tracciano correttamente il codice riga per riga ma non collegano la traccia al difetto di fondo.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Ecco la risposta e perché funziona come test: la funzione divide sempre per window (3), anche quando il blocco ha meno di 3 elementi all’inizio della lista. L’output con bug è [3.33, 10.0, 20.0, 30.0, 40.0], ma i primi due valori dovrebbero essere 10.0 e 15.0 dato che quei blocchi contengono rispettivamente solo 1 e 2 elementi. La correzione è cambiare / window in / len(chunk).
Apprezziamo questo test perché i modelli spesso tracciano il loop alla perfezione, ma poi riportano “l’output sembra corretto” — vedono la matematica svolgersi passo dopo passo e non segnalano che dividere un singolo elemento per 3 è sbagliato. Richiede che il modello mantenga l’intento (cosa dovrebbe fare una media mobile) insieme all’esecuzione (cosa fa effettivamente il codice) e individui il divario tra le due.

L’ultimo test non ha matematica, solo ragionamento controfattuale.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?È vero, non c’è una singola risposta corretta qui, ed è difficile da immaginare. Ma vogliamo che il modello ragioni almeno sulle implicazioni, e riteniamo che la risposta di Claude Opus 4.6 sia abbastanza ragionevole.
In definitiva, per farla breve, Opus 4.6 ha ottenuto un punteggio perfetto, anche se, come hai visto, abbiamo incluso una domanda in cui la risposta era un po’ soggettiva, quindi il giudizio finale spetta a te.

Opus 4.6 è il leader indiscusso in almeno quattro benchmark importanti:
Terminal-Bench 2.0 è un benchmark di coding agentico; Humanity’s Last Exam è un test di ragionamento complesso; GDPval-AA testa le performance nel lavoro di conoscenza; BrowseComp misura la capacità di un modello di trovare online informazioni difficili da reperire.
I modelli Claude hanno la meritata reputazione di essere tra i migliori nel coding. Quindi iniziamo guardando i risultati del benchmark Terminal-Bench 2.0.
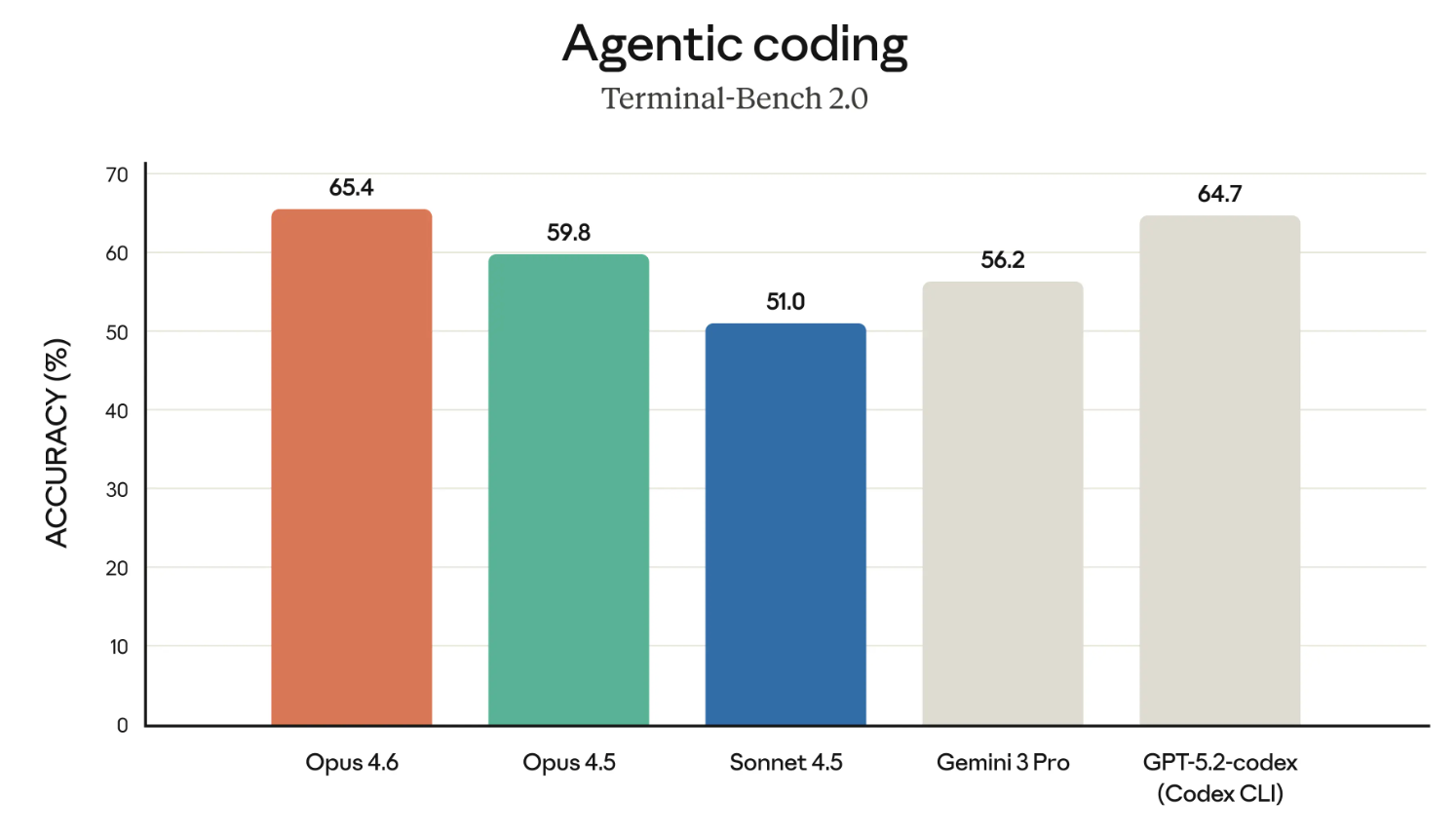
Se il grafico sopra sembra mettere in evidenza Opus 4.6 rispetto a GPT-5.2-codex — beh, è sicuramente intenzionale. Anthropic ha sfidato direttamente OpenAI in diverse aree di recente e sta costruendo il caso per l’uso enterprise.
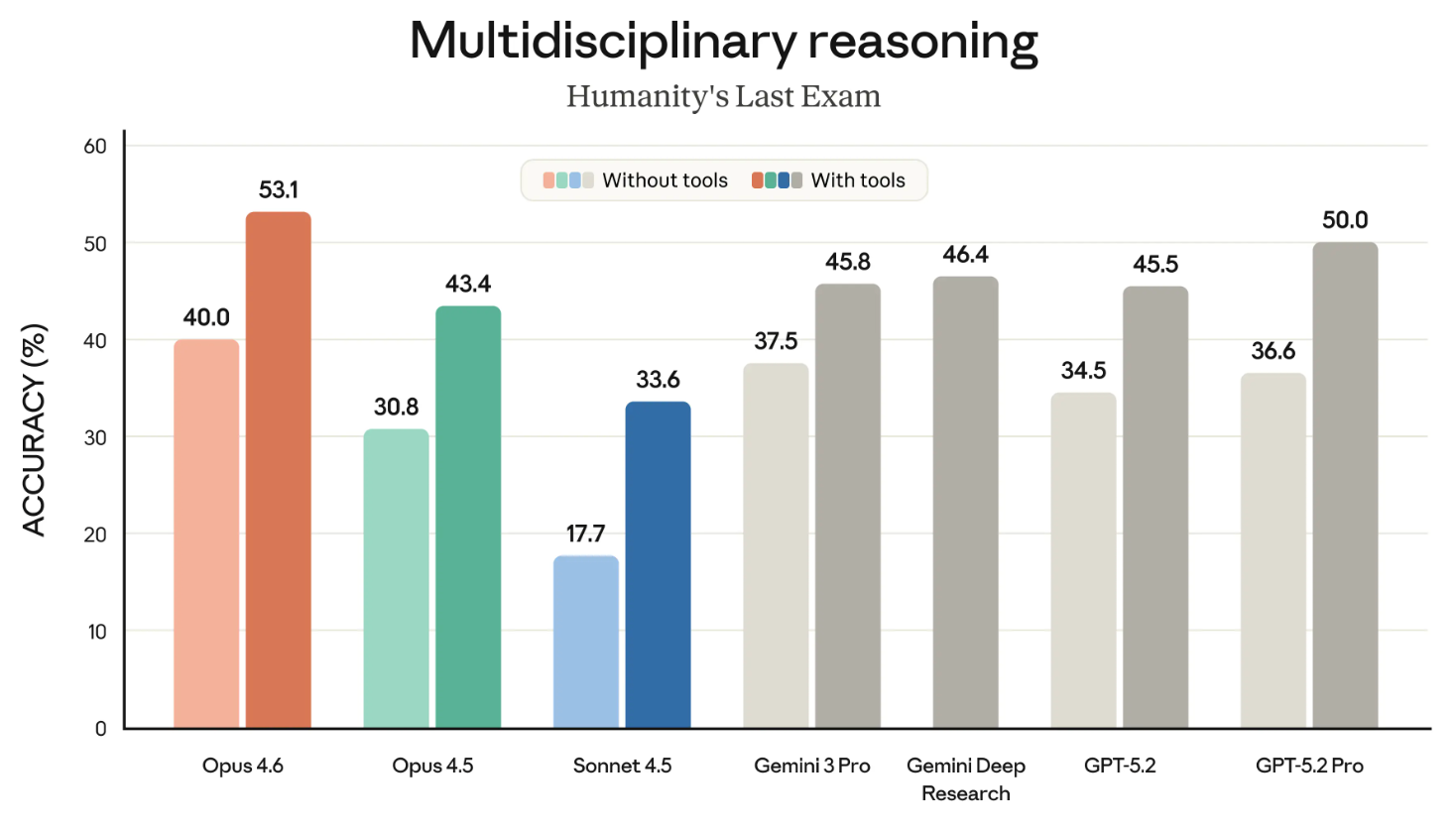
Humanity’s Last Exam è uno dei benchmark più noti, e uno che seguiamo tutti da vicino. Misura la capacità generale di ragionamento di un modello.
Il grafico seguente mostra il successo dei diversi modelli di frontiera nel benchmark HLE sia con che senza strumenti. (“Con strumenti” significa che al modello è stato consentito usare capacità esterne come la ricerca sul web e l’esecuzione di codice.)
Forse il grafico starebbe meglio diviso in due. A parte questo dettaglio, il messaggio è chiaro: Opus 4.6 è il leader sia nella categoria “con strumenti” che in quella “senza strumenti”.
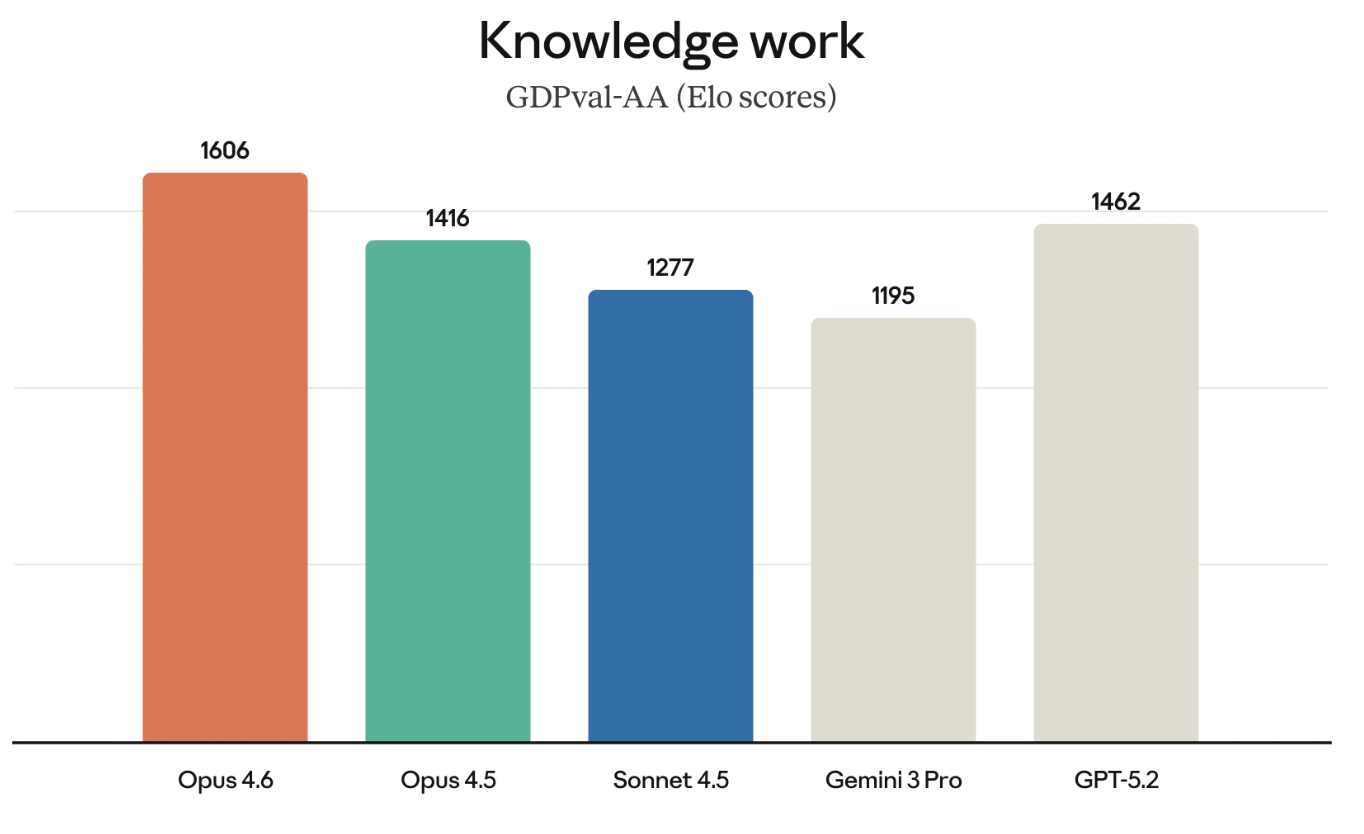
GDPval-AA (come suggerisce il nome) è un test di ciò che viene considerato lavoro di conoscenza economicamente prezioso. Pensa ad attività come eseguire modelli finanziari o fare ricerca.
GDPval-AA e altri benchmark simili stanno diventando sempre più importanti perché misurano davvero i tipi di lavoro per cui le aziende pagano effettivamente. Il successo di Opus 4.6 su GDPval-AA è anche un’ulteriore sfida diretta alla suite di modelli GPT, dato che OpenAI e Anthropic competono per molti degli stessi clienti.
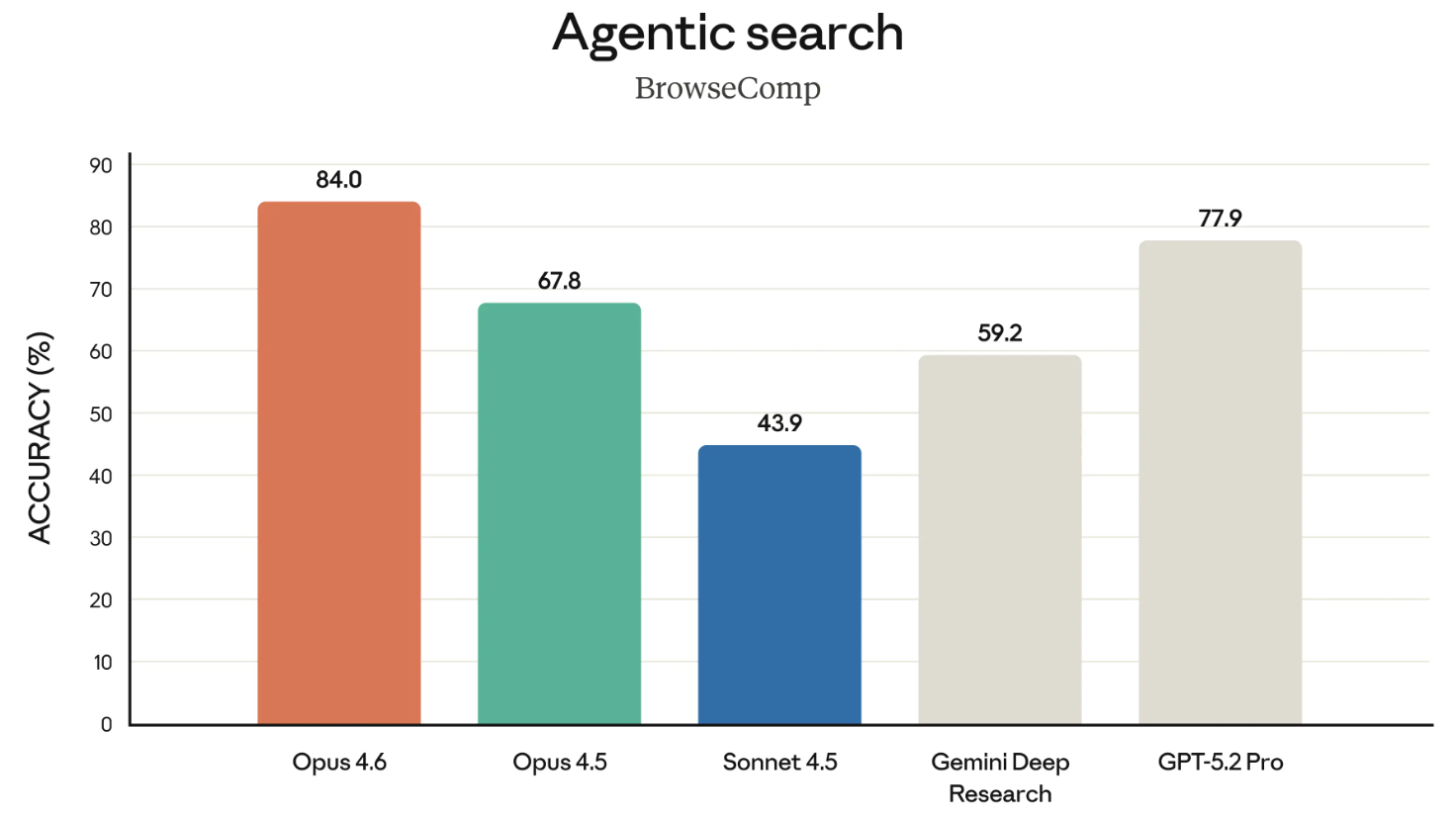
BrowseComp è l’ultimo benchmark degno di nota tra quelli citati nel rilascio. Misura la capacità di un modello di rintracciare online informazioni difficili da trovare. Un po’ di storia: OpenAI ha sviluppato BrowseComp per mostrare le capacità di ricerca dei propri modelli.
In una mossa pungente, in questo rilascio Anthropic ha collegato direttamente l’annuncio di aprile 2025 di OpenAI sullo sviluppo di BrowseComp per evidenziare che Opus 4.6 è in cima alla classifica su quel benchmark. È stata una mossa un po’ maliziosa, citare contro OpenAI il loro stesso benchmark.
Opus 4.6 è ampiamente disponibile al momento della stesura di questo articolo. Tuttavia, non puoi accedere a Opus 4.6 senza passare a un account pro, che offre anche altri vantaggi, come la possibilità di usare Claude in Excel.
Se sei uno sviluppatore, dovresti usare claude-opus-4-6 nella Claude API. I prezzi non sono cambiati: restano $5/$25 per milione di token. Se ti confondono i due numeri, sappi che il primo è ciò che paghi per inviare token al modello (cioè i tuoi prompt) e il secondo è ciò che paghi per i token che il modello genera in risposta.
Claude Opus 4.6 è in cima alla classifica in benchmark importanti come GPDVal-AA, che misura quanto bene un modello esegua task economicamente rilevanti, ciò che interessa ai grandi clienti enterprise. OpenAI potrebbe essere stata scossa da questo sviluppo, perché poche ore prima del rilascio di Opus 4.6 ha annunciato OpenAI Frontier, una nuova piattaforma enterprise per costruire, distribuire e gestire agenti di AI in produzione.
In altre parole, invece di competere sui benchmark dei modelli, Frontier ci mostra che OpenAI è focalizzata sull’infrastruttura intorno alla sua suite di modelli, in particolare offrendo agli agenti di AI un contesto aziendale condiviso, permessi e la capacità di ricevere e imparare dal feedback nel tempo. Perdita di terreno nei benchmark, OpenAI segnala che la sua piattaforma è meglio posizionata per rendere gli agenti realmente utili in azienda.
Che sia una svolta strategica o un’ammissione tacita di star perdendo la corsa sui modelli, sta a te deciderlo.
Nel complesso, però, siamo impressionati da quanto Anthropic offre con Claude Opus 4.6 e non vediamo l’ora di mettere le mani sugli agent teams. Se vuoi saperne di più sulla famiglia Claude, dai un’occhiata al corso Introduction to Claude Models.
Impara l’AI con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

