
Course
Data Warehousing Concepts
4 hr
48.4K
In recent years, our society has produced so much data at such a fast pace. Consequently, efficient data management systems are more necessary than ever.
Storage, management, and analysis systems are a core part of any modern organization and business. This is where data warehousing steps in—probably the most advanced technology of its type—to store large amounts of data in one single place while enhancing the analytics process.
Data warehousing technology has recently been consolidated to become more scalable and less expensive with the popularization of cloud services. That’s why in this article, we will discuss the Google Cloud Platform (GCP) and its robust data warehousing solution: BigQuery.
A data warehouse is a type of data management system designed to enable and support business intelligence activities, particularly analytics.
While traditional databases are mainly used for processing transactions, a data warehouse is optimized for read-heavy operations and complex queries.
Data warehouses are ideal systems for centralizing an organization's business intelligence and enabling integrations with other data sources. Data warehousing, therefore, refers to the process of collecting data from multiple resources and storing it in a single location: the data warehouse.
A data warehouse can be hosted on-premises or in the cloud. Using cloud-based services brings five main benefits over traditional self-managed solutions:
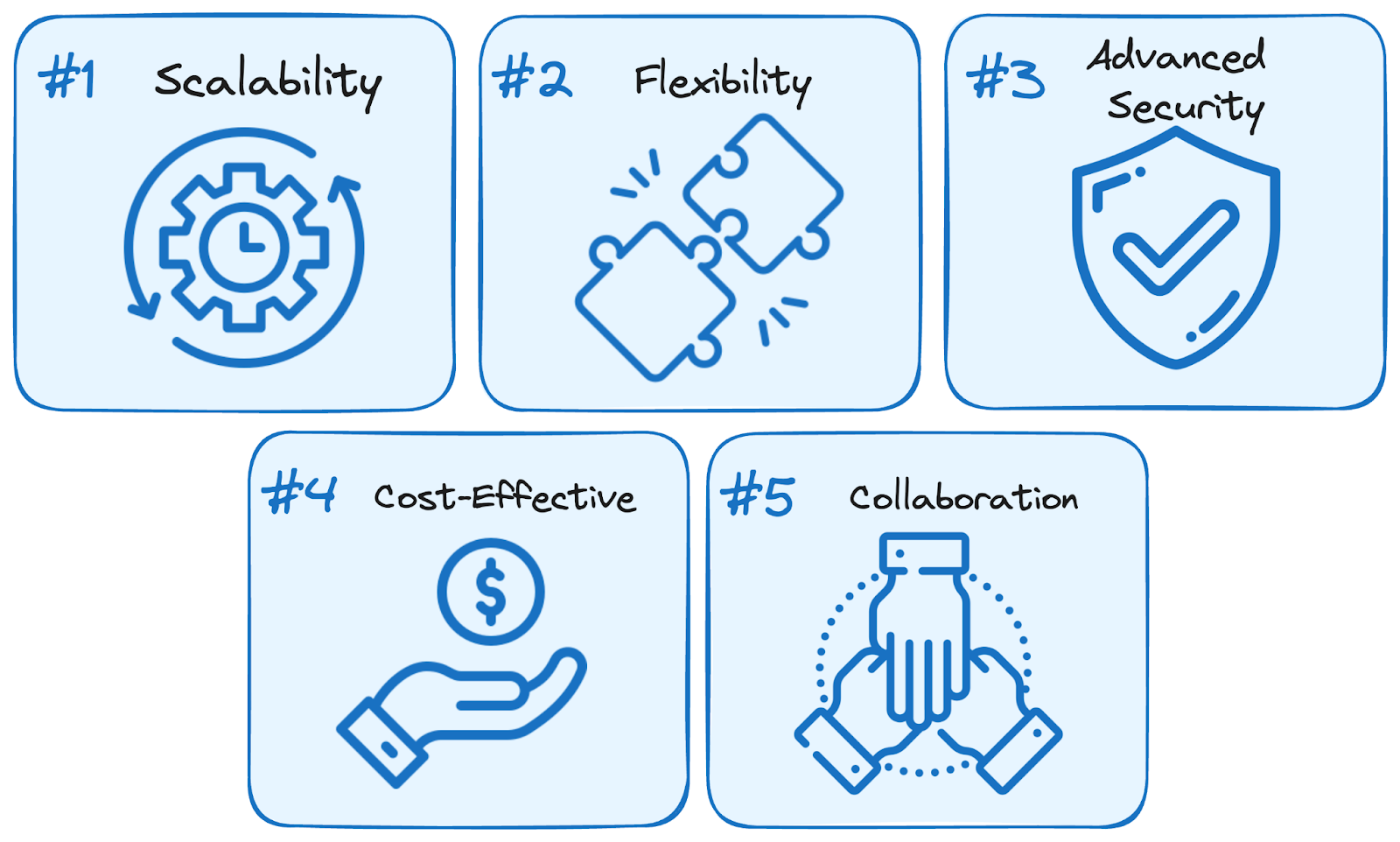
Advantages of using cloud-based services. Image by Author.
Now that we understand the data warehouse concept and the main advantages of using the cloud, the next natural question is why we should choose GCP and their data warehousing solution, BigQuery. Let’s discuss that in the following sections.
GCP is a cloud-based computing platform that allows organizations to build and deploy their applications using Google’s infrastructure. It offers a wide variety of services, covering everything from computing and storage to networking and machine learning.
If you want to learn more about GCP, I recommend getting a full overview by enrolling in our Introduction to GCP course.
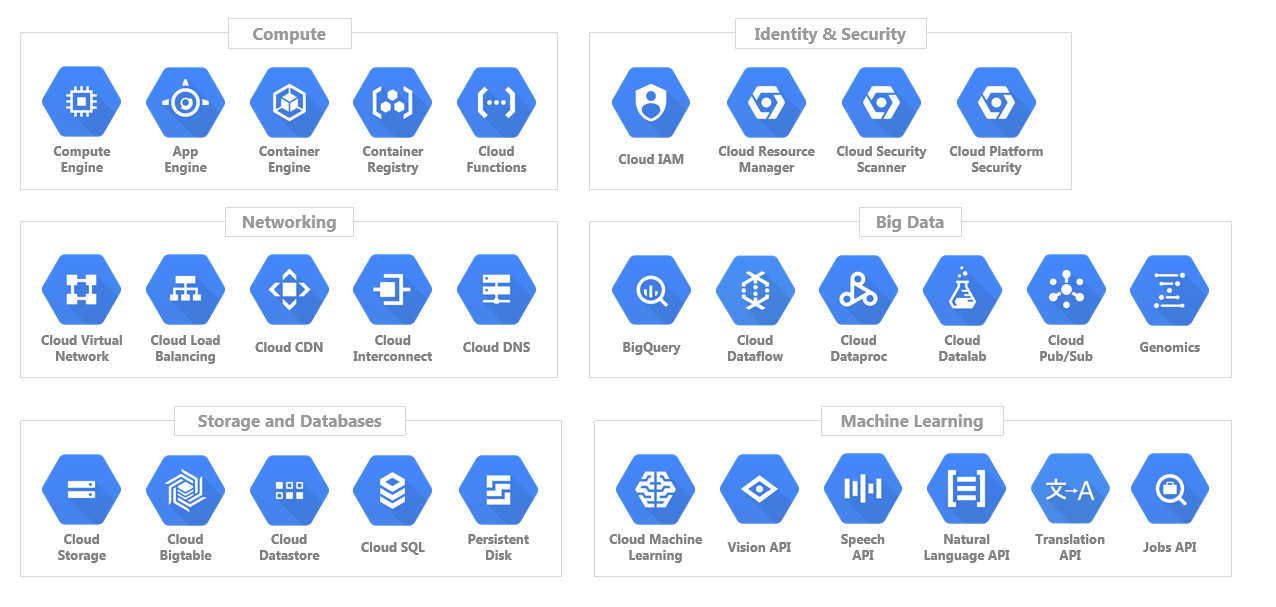
Google Cloud services overview. Image by Google Cloud.
Some of the GCP key services include:
This cheat sheet summarizes all services offered by GCP, Azure, and AWS, the most prominent cloud providers, for an in-depth comparison.
Using any cloud-based infrastructure for data warehousing provides us with some advantages, like the ones mentioned before. However, using GCP may offer some additional benefits worth mentioning:
BigQuery is a fully managed, serverless data warehouse provided by GCP. It is designed to handle large-scale data analytics and enables super-fast SQL queries. It eliminates the need for managing infrastructure, allowing users to focus on its main purpose: analyzing their data.
BigQuery offers several features that make it a powerful data warehousing solution:
Additionally, BigQuery’s cost-effective pricing model, based on data processed by queries, is ideal for large-scale data analysis and to reduce the associated cost of querying data.
In summary, BigQuery combines speed, ease of use, cost-effectiveness, and flexibility, making it a top choice for modern data warehousing.
Getting started with BigQuery is straightforward and involves the following steps:
To use BigQuery, the first step is to create a GCP account. You should go to the Google Cloud Platform website, create your account, and set up a billing account.
It is important to note that Google offers a free tier with a $300 credit for new users. This allows you to explore GCP services without incurring costs during your first three months of usage.
Once you have an account, go to the GPC console. You will see your $300 credits or the proportion you have already used if you have an active free trial.
GCP interface: Console view.
After you create a new account, a project called “My First Project” will be automatically created for you. A project is a container for all your GCP resources, including BigQuery datasets and tables.
To create a new project, click on the selector next to the Google Cloud logo in the upper navigation bar. A new section with a listing of all your projects should appear. You can create a new project by clicking the “New Project” button.
GCP interface: List of projects.
You may be required to provide billing information to activate a new project, but remember that you can take advantage of the free credits to avoid any cost. Now, you need to provide a name for your project and click on the “Create” button.
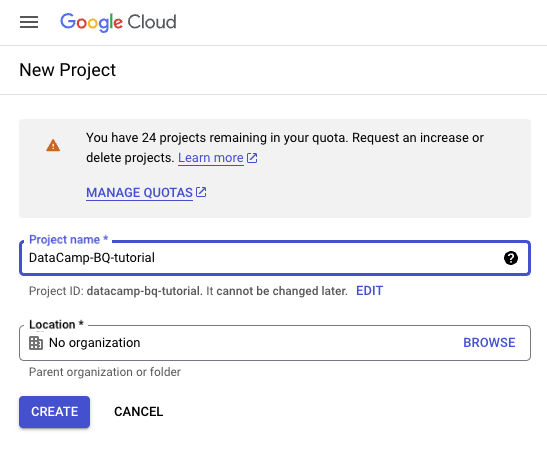
GCP interface: Creating a new project.
For this tutorial, I created a new project called “DataCamp-BQ-Tutorial.” Feel free to do the same.
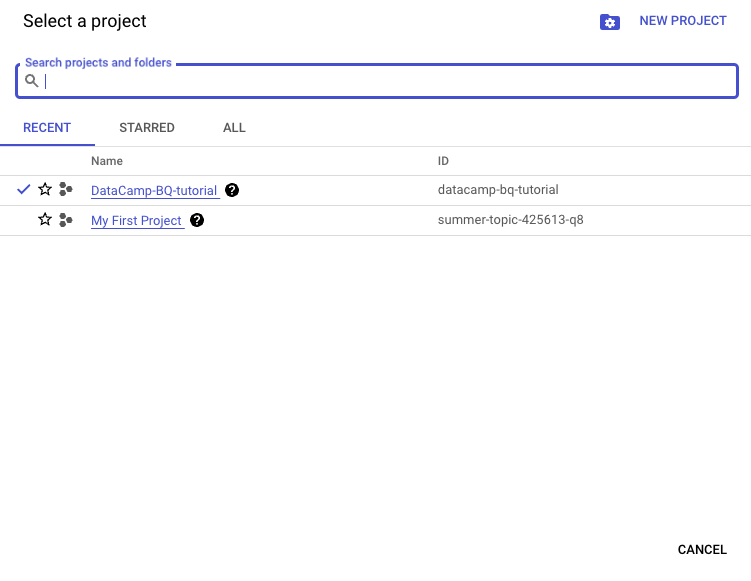
GCP interface: Selecting a project.
To use BigQuery, you need to enable the BigQuery API for your project. You can do this either by going directly to the BigQuery service and activating it from there or by going to the “API & Services” dashboard in the GCP console.
If you are not familiar with the GCP interface, I recommend you take the Introduction to GCP course to learn some of the first notions.
To find the BigQuery service, we can use the search bar in the GCP console, as you can observe in the following screenshot.
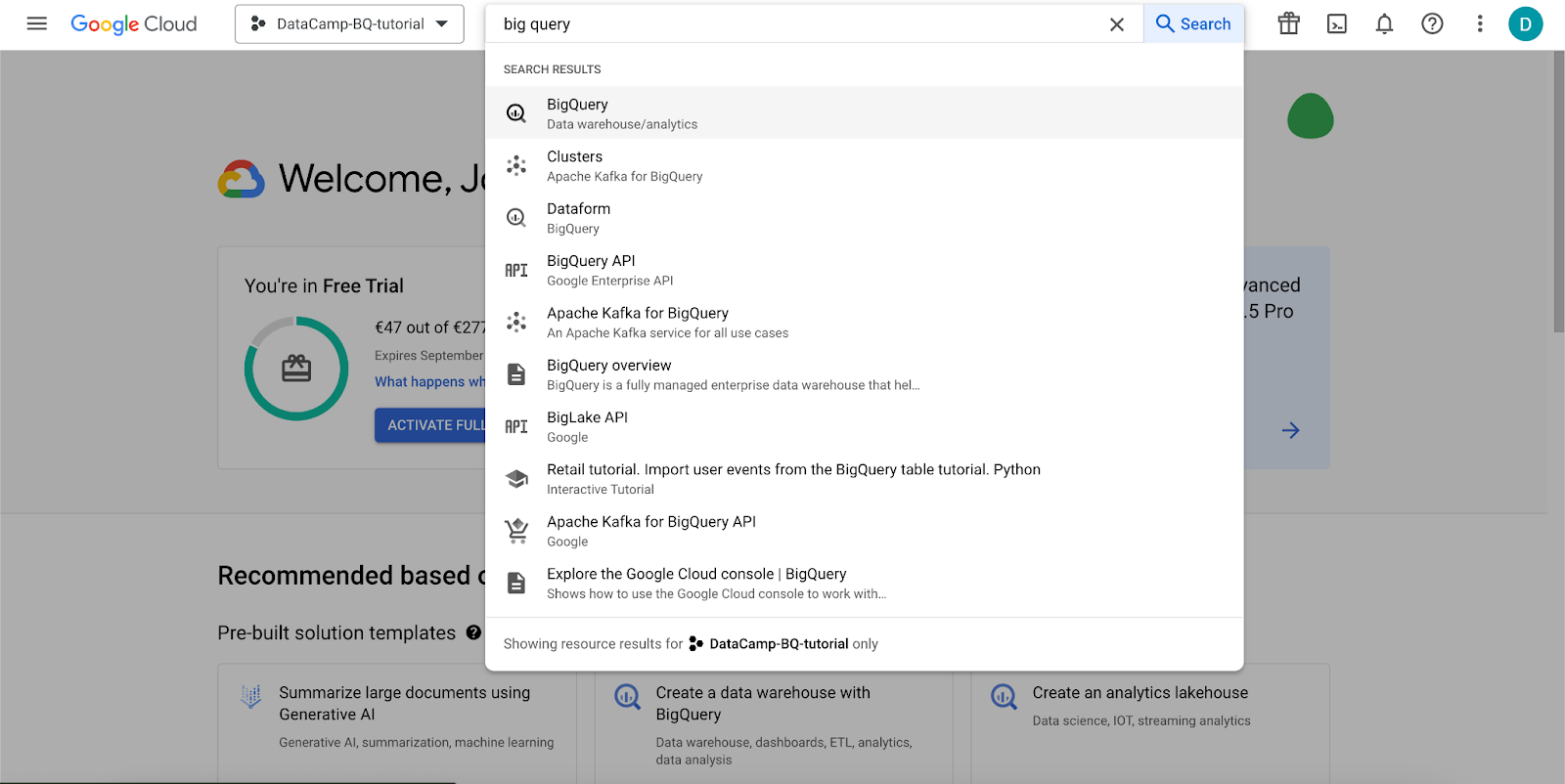
GCP interface: Looking for the BigQuery service.
A view like the following one should appear, asking us to enable the BigQuery API.
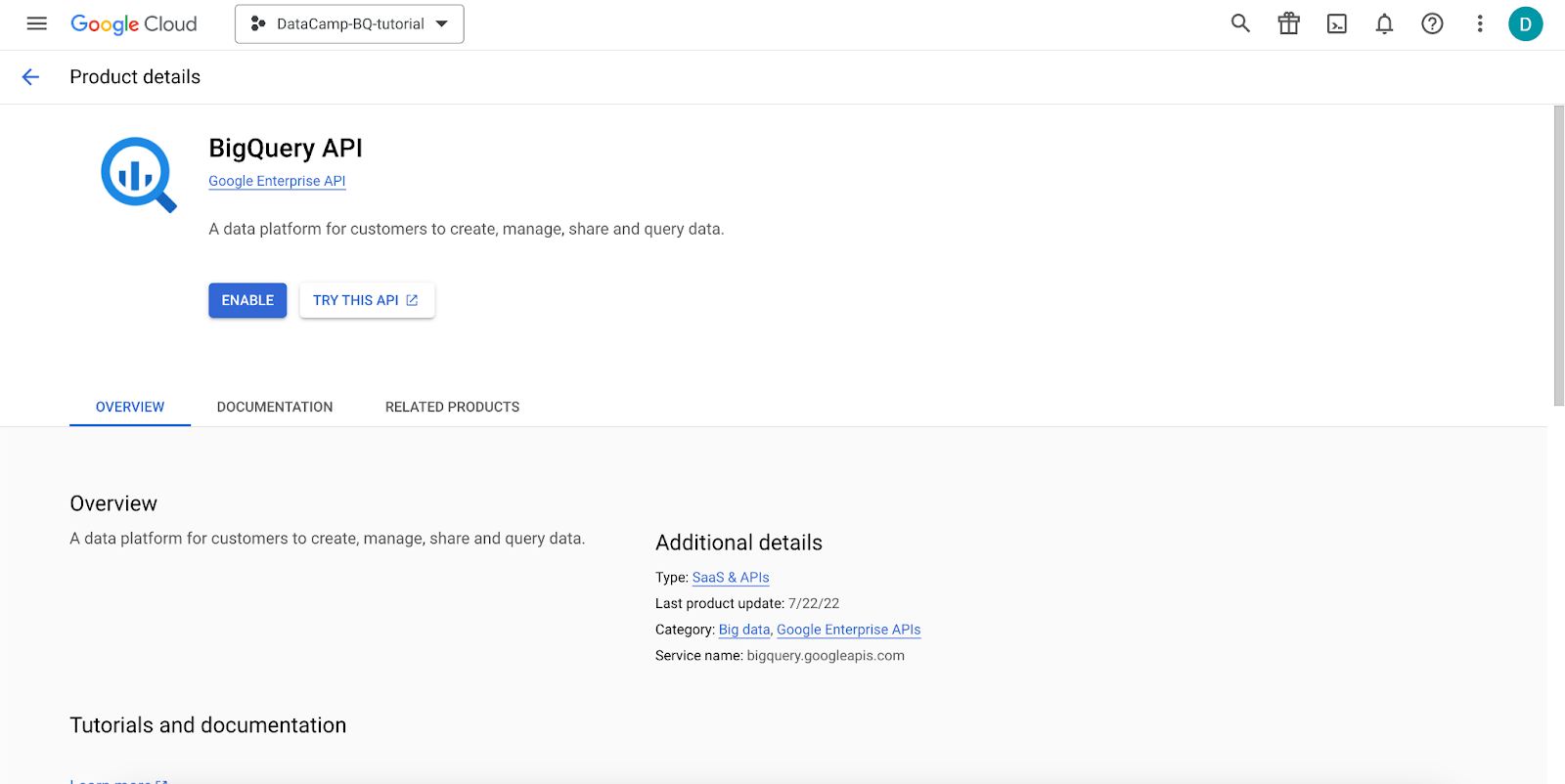
GCP interface: Enabling the BigQuery API.
After you click the “Enable” button, the API will be enabled. It will take a few seconds.
Once the API is enabled, you should be taken to the BigQuery console, a web-based interface allowing you to interact with the BigQuery service. The console provides tools for managing datasets, writing and executing queries, and monitoring job statuses.
You can always access the BigQuery console from the GCP main console, either by using the search bar as shown in the previous step or by going to the main menu at the top left corner of the screen.
GCP interface: BigQuery console main interface.
BigQuery supports two SQL dialects: standard SQL and legacy SQL. Standard SQL is the preferred choice for querying data in BigQuery because it complies with the ANSI SQL 2011 standard.
To further understand how BigQuery works, it is important to consider that data is organized into datasets and tables:
project ID and dataset ID.To further exemplify these two concepts, tables are the smallest unit of data we can have, and the datasets work as “folders” that contain those tables. Within a single dataset, tables are identified by their names and can be organized logically according to the needs of the data and project.
Now, we are ready to start querying data in BigQuery, but you will notice a big problem: There is no data at all.
To get started, we will play with the public datasets BigQuery provides for free. To access them, click on the “Add” button next to the “Explorer.”
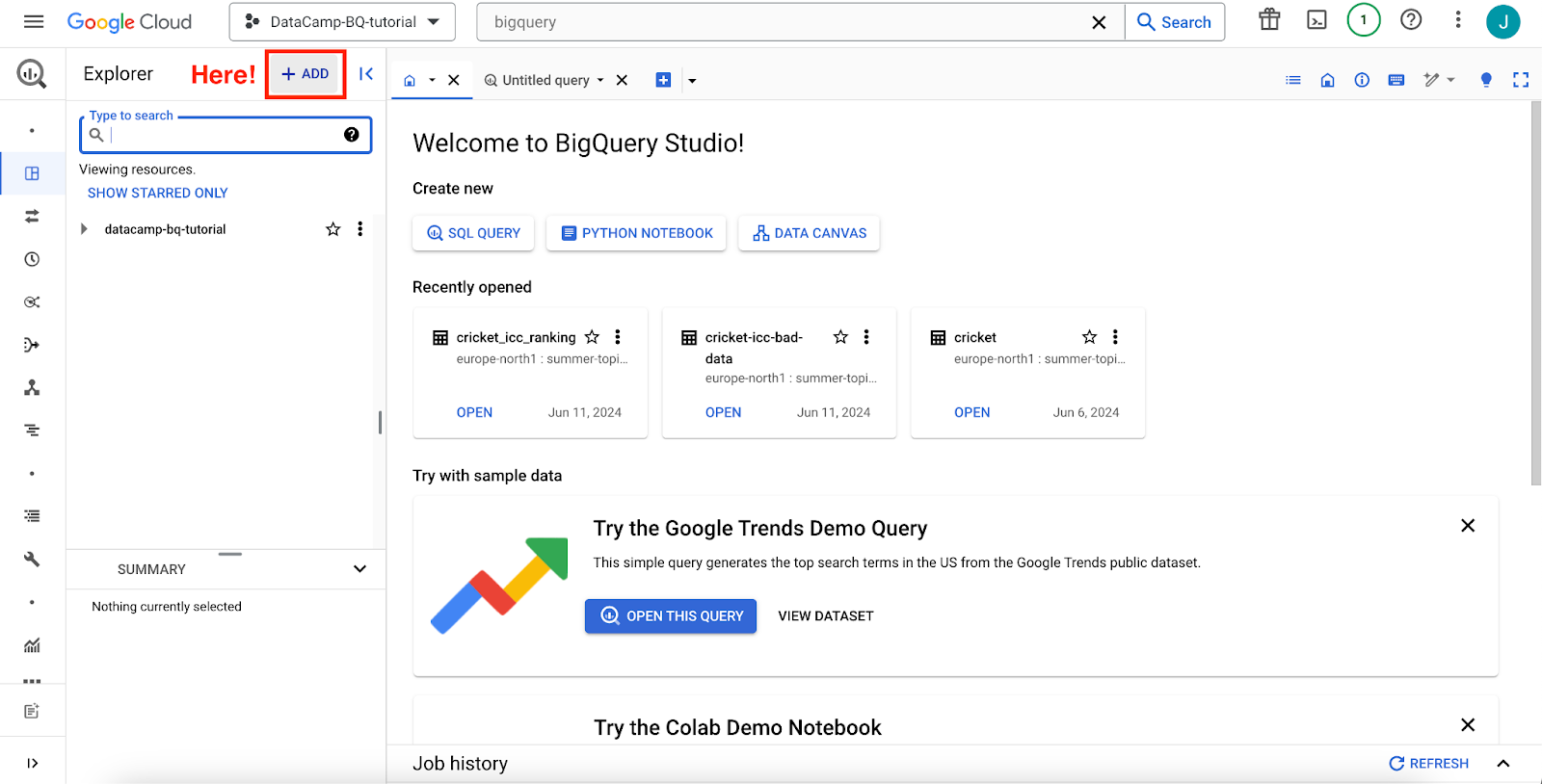
GCP interface: BigQuery console main interface, add a dataset.
Then, a new interface with several options for adding data to BigQuery will appear.
There are simple integrations, such as Google Drive, or more advanced integrations, such as Amazon S3 or Azure Blob Storage.
In our case, we will select “Public Datasets.”
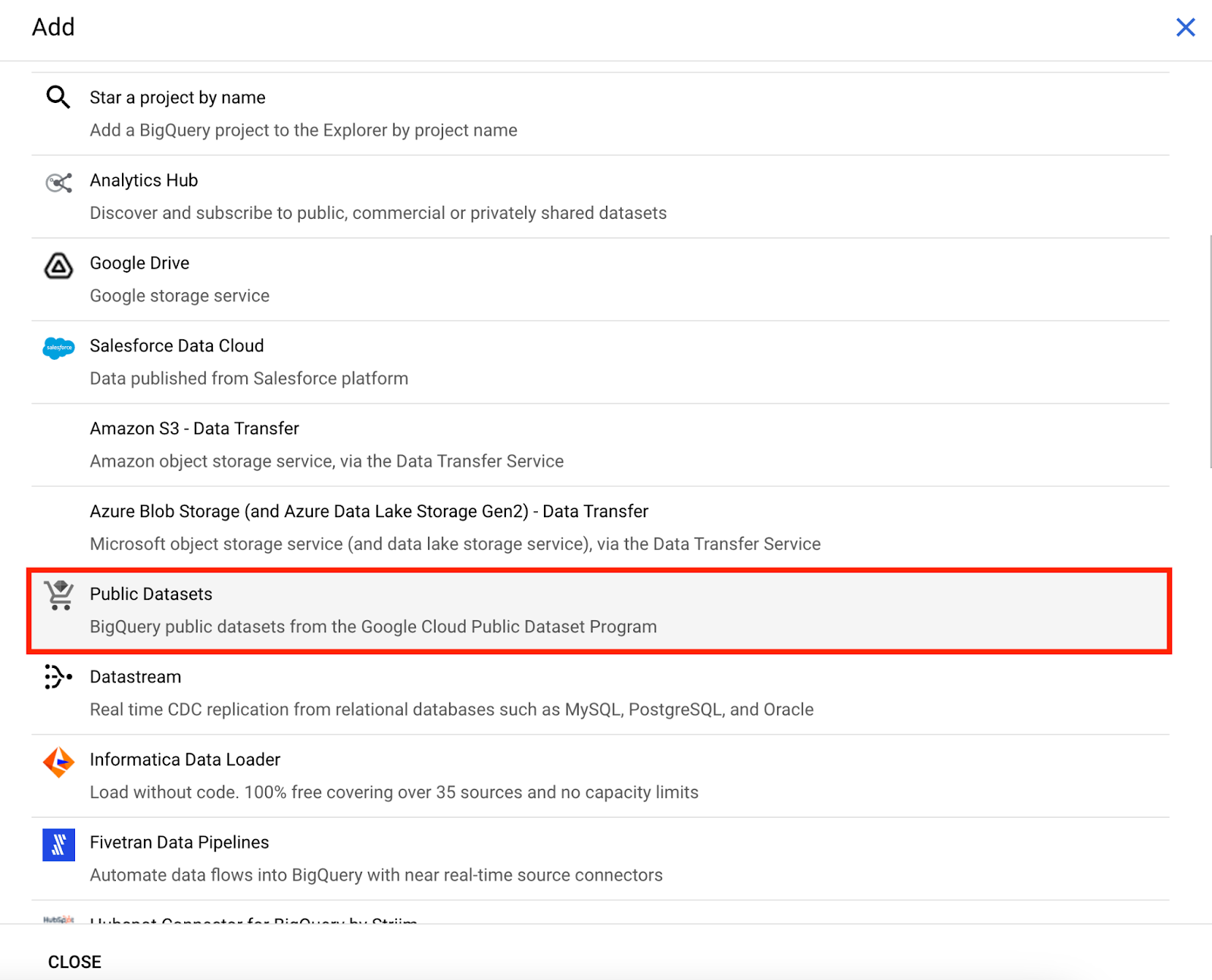
GCP interface: BigQuery console adding data options.
We will then be taken to the “Marketplace,” which will show us all the public datasets available for use.
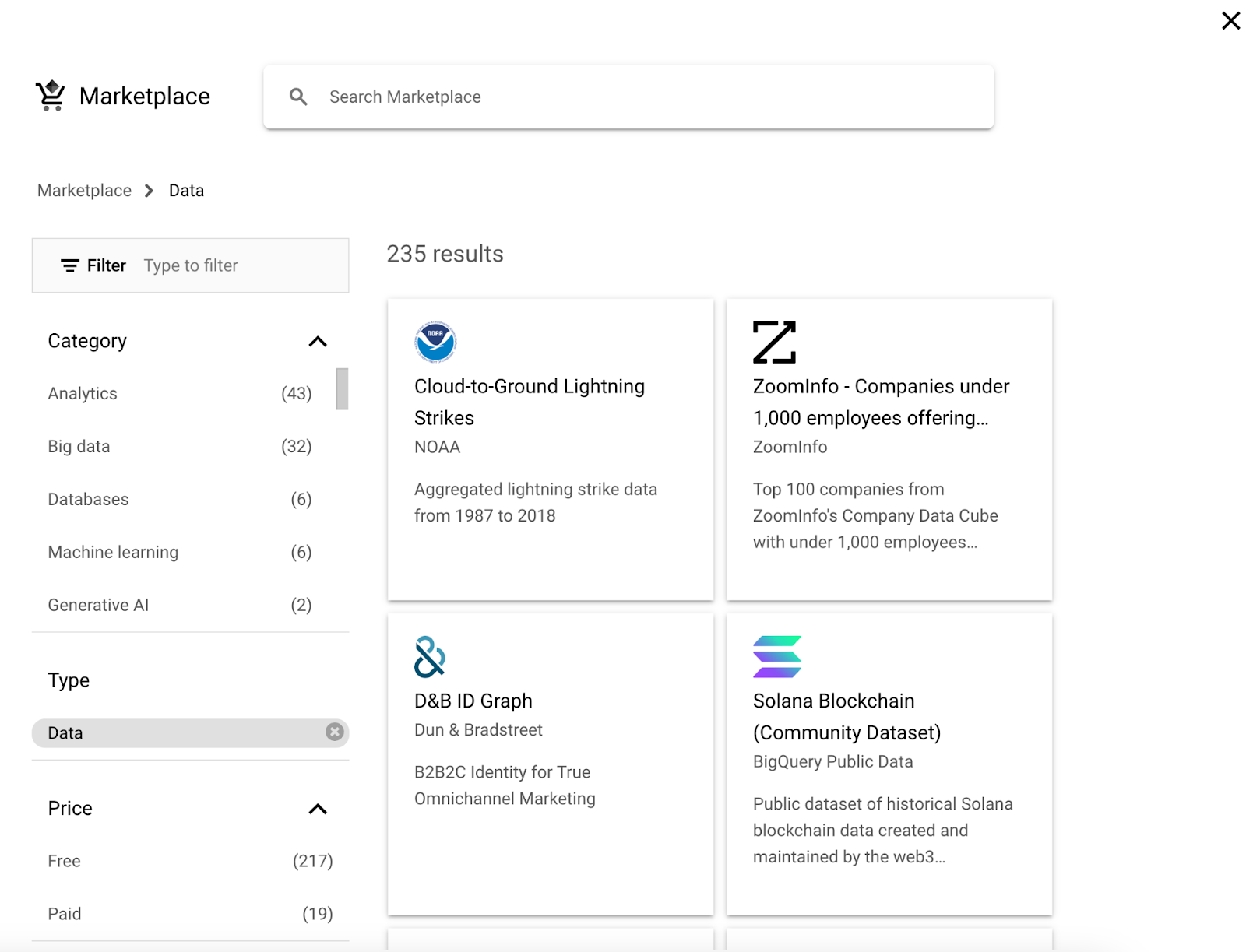
GCP interface: Data marketplace for public datasets.
You can select any dataset of interest to you. The data will appear automatically in BigQuery under the big-query-public-data dataset. Some datasets contain a single table, while others store multiple ones.
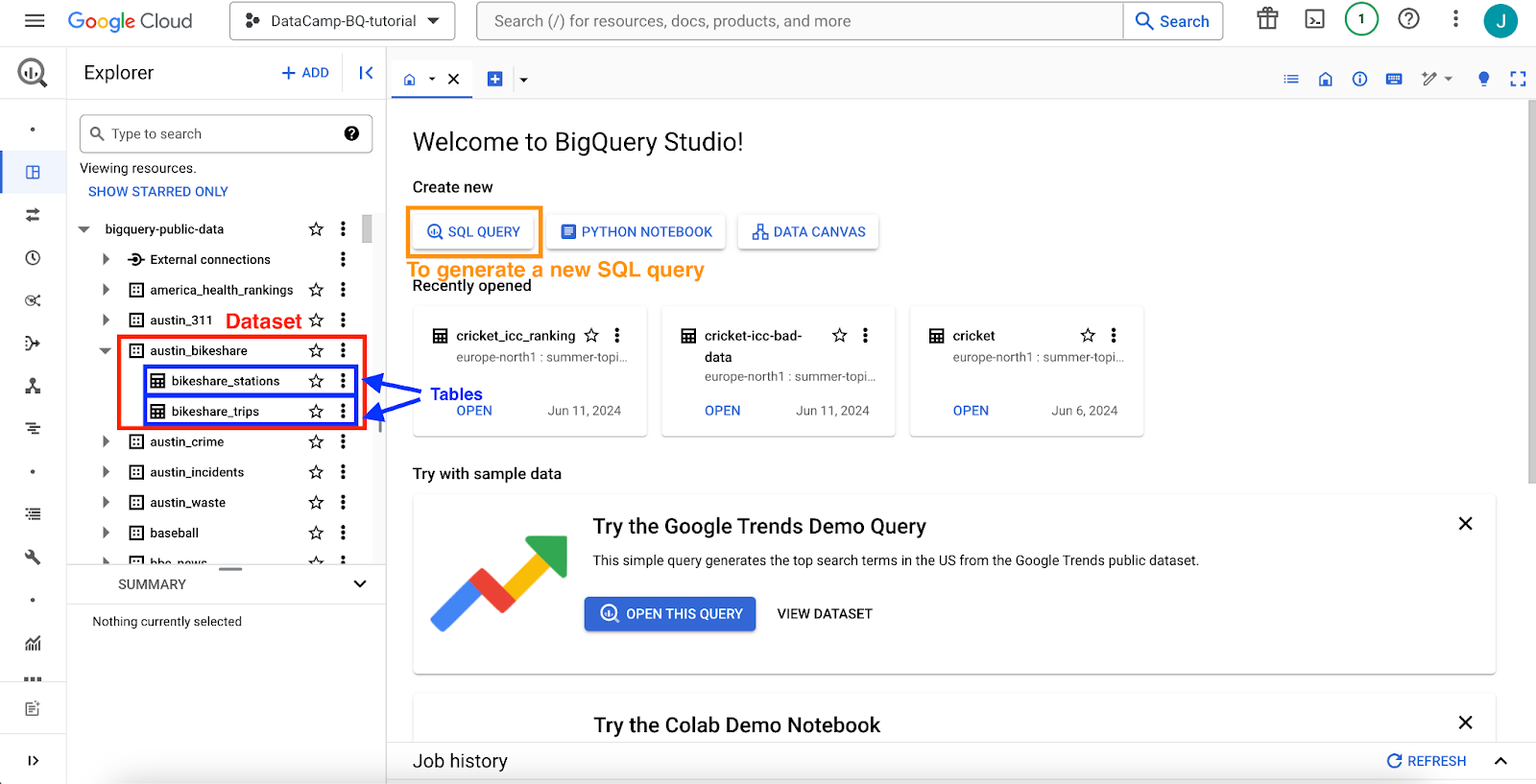
GCP interface: BigQuery main interface, selecting a new table.
When you select any table, the schema will be displayed. Clicking on the interface's different options will give you more details about the tables or even a data preview.
My personal suggestion is just to start exploring these datasets on your own.
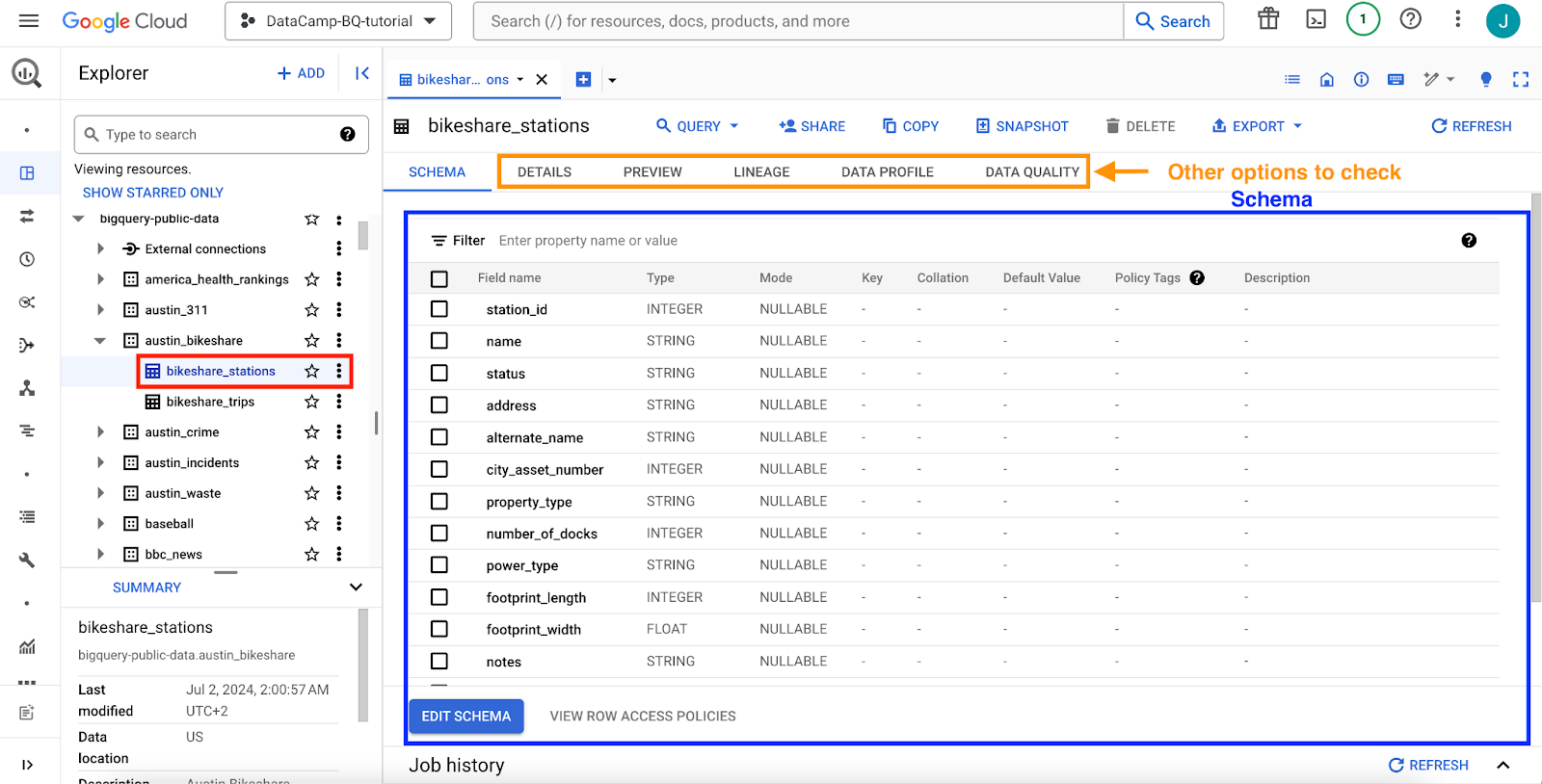
GCP interface: BigQuery main interface, selecting a table.
Getting started with querying data in BigQuery involves understanding basic SQL commands. You can perform simple SELECT statements to retrieve specific columns from a dataset.
For instance, we can generate a simple query to get the station_id and the corresponding name from the bikeshare_stations table contained within the austin_bikeshare dataset.
SELECT station_id, name
FROM `bigquery-public-data.austin_bikeshare.bikeshare_stations`If we execute the query by clicking on the “Run” button, we will immediately obtain the result.
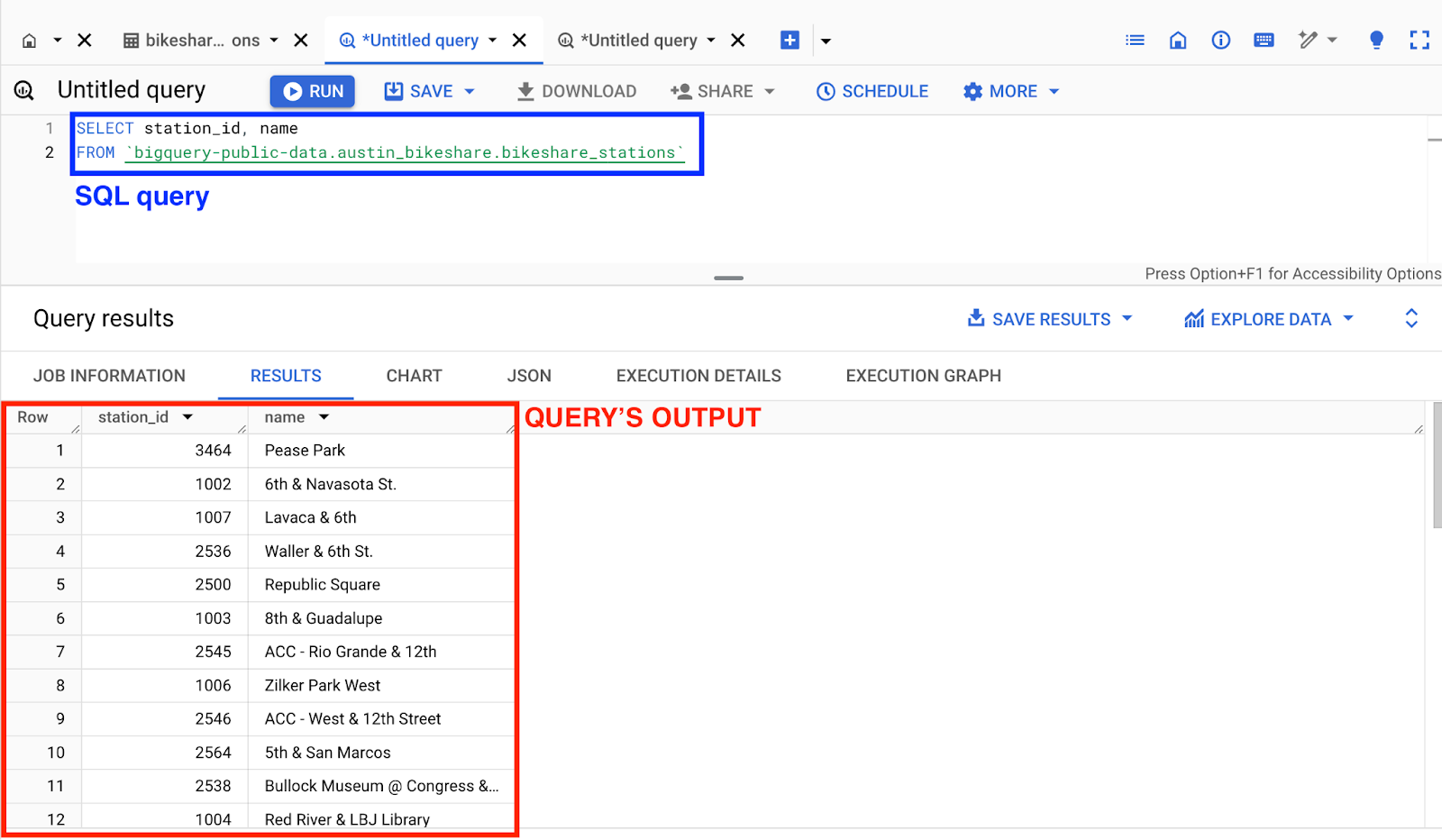
GCP interface: BigQuery main interface, running a query.
If you are unfamiliar with SQL, you can start with this amazing code-along to understand the language's most basic commands.
Once you have mastered the basic commands of SQL, you can further enhance your skills with advanced queries.
BigQuery offers advanced SQL features such as window functions, common table expressions (CTEs), and subqueries. These tools allow more complex data manipulation and analysis.
For example, we can generate a new query using a window function to calculate a running total duration of trips for each individual bike, using the bikeshare_trips table from the austin_bikeshare dataset:
SELECT
trip_id,
bike_id,
start_time,
duration_minutes,
SUM(duration_minutes) OVER (PARTITION BY bike_id ORDER BY start_time) AS cumulative_duration
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
ORDER BY
bike_id,
start_time;To learn more about advanced SQL commands, I recommend you to read our How to Become a SQL Expert article.
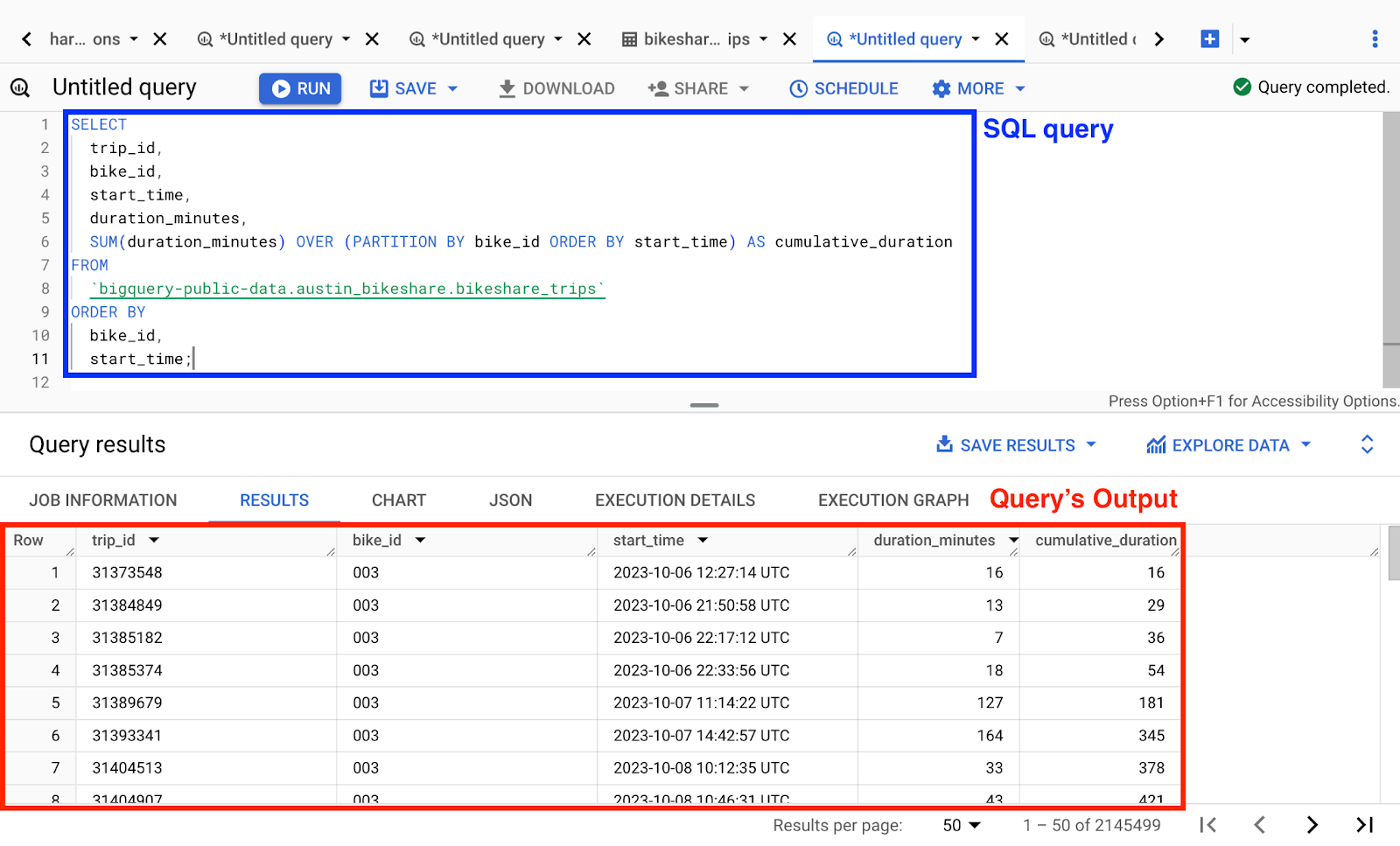
GCP interface: BigQuery main interface, query results.
Optimizing queries in BigQuery can significantly enhance performance and reduce costs. One of the easiest ways to reduce costs is always to check how much data you will execute before running the query.
When generating a new query, GCP will approximate the amount of data you will be executing.
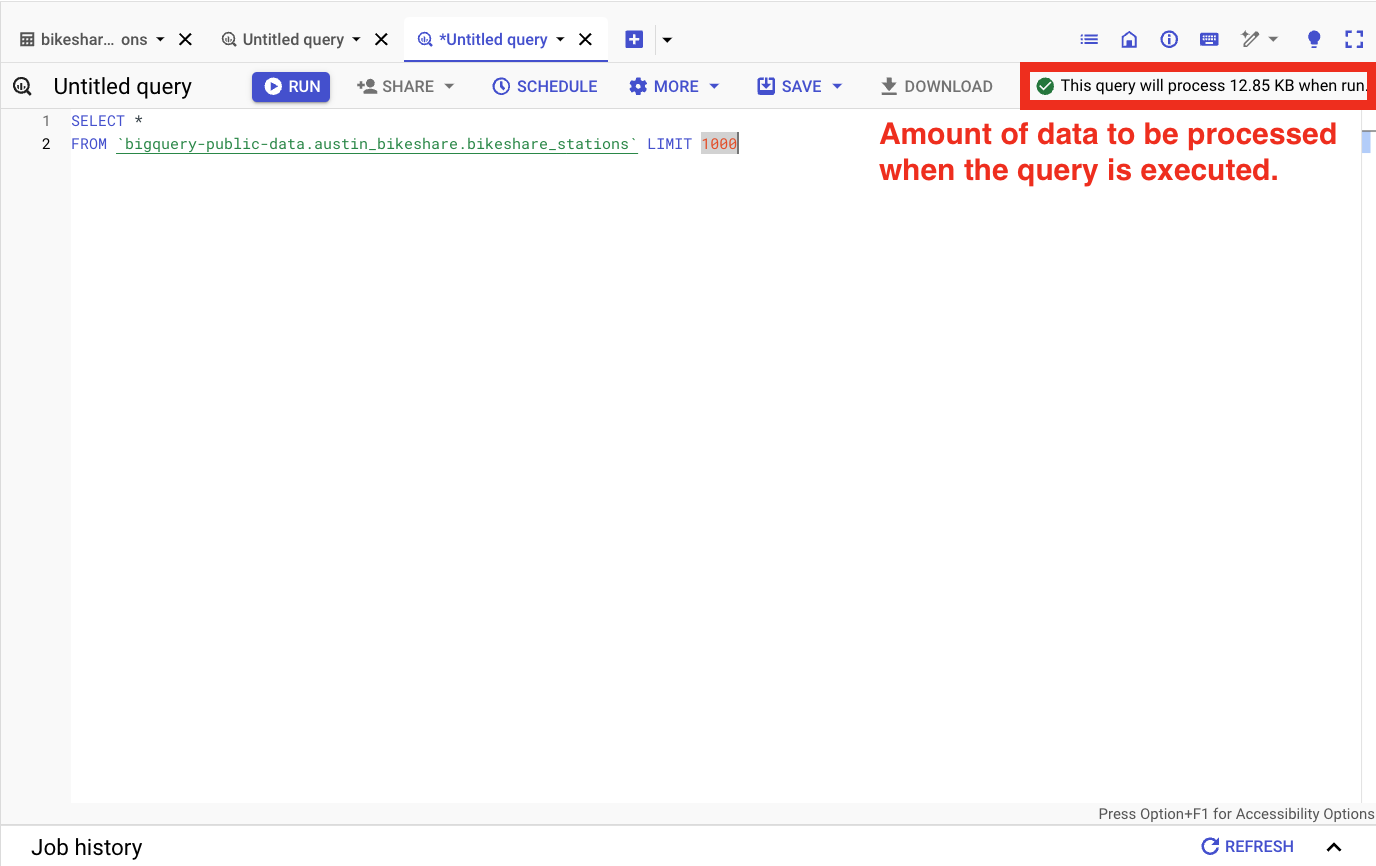
GCP interface: BigQuery main interface, amount of data to be processed.
Some other tips to keep in mind are:
SELECT * by specifying only the columns you need, and leverage query caching whenever possible.Following these tips can ensure more efficient and cost-effective queries in BigQuery.
BigQuery ML simplifies machine learning by enabling data scientists and analysts to build and deploy models using SQL queries directly within BigQuery. This integration allows users to leverage BigQuery's powerful data processing capabilities, eliminating the need to move data between platforms.
With BigQuery ML, you can create, train, and evaluate various machine learning models, such as linear regression, without the need to use any other tool.
For example, to create a linear regression model predicting sales, you would use:
CREATE OR REPLACE MODEL `datacamp_test.bike_usage_model`
OPTIONS(model_type='linear_reg', input_label_cols=['duration_minutes']) AS
SELECT
start_time,
EXTRACT(HOUR FROM start_time) AS hour_of_day,
start_station_id,
end_station_id,
subscriber_type,
bike_type,
duration_minutes
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`;If we execute the code, a new model will be generated based on the data we have selected.
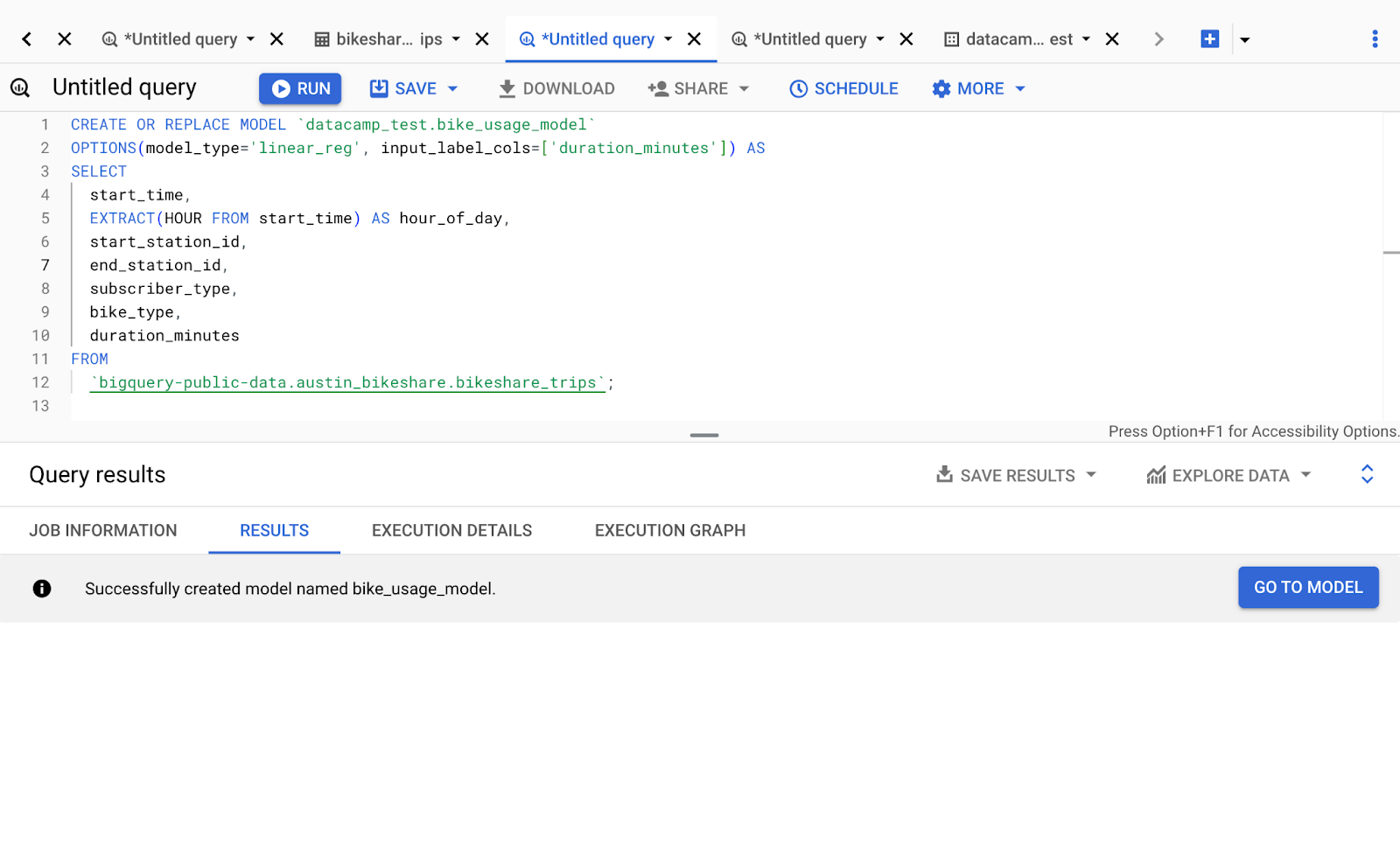
GCP interface: BigQuery main interface, running an ML model.
This integration simplifies the process of applying machine learning to your data, streamlining the workflow and making machine learning more accessible and efficient.
Designing an efficient data warehouse schema is crucial for optimizing query performance in BigQuery.
Remember that any process that runs in the cloud comes with an associated cost. Therefore, I recommend to:
Before deciding on a final schema, we need to think about how we will be accessing the data. BigQuery generally provides high performance across many data model methodologies.
Let’s review some common schema design strategies.
Unlike normalization, which minimizes redundancy and organizes data into smaller, related tables, denormalization intentionally introduces redundancy for efficiency. It involves merging tables and including duplicate data to reduce the complexity of queries, which can lead to faster read times.

Denormalized table examples. Image by Google Cloud.
In a denormalized database, data retrieval operations often become simpler and quicker because fewer joins are required, reducing the overall query execution time. This approach is particularly useful in data warehousing and analytical databases, like BigQuery, where read operations are more frequent than write operations.
However, normalization increases data storage requirements. That’s why the recommended way to denormalize data in BigQuery is to use nested fields.
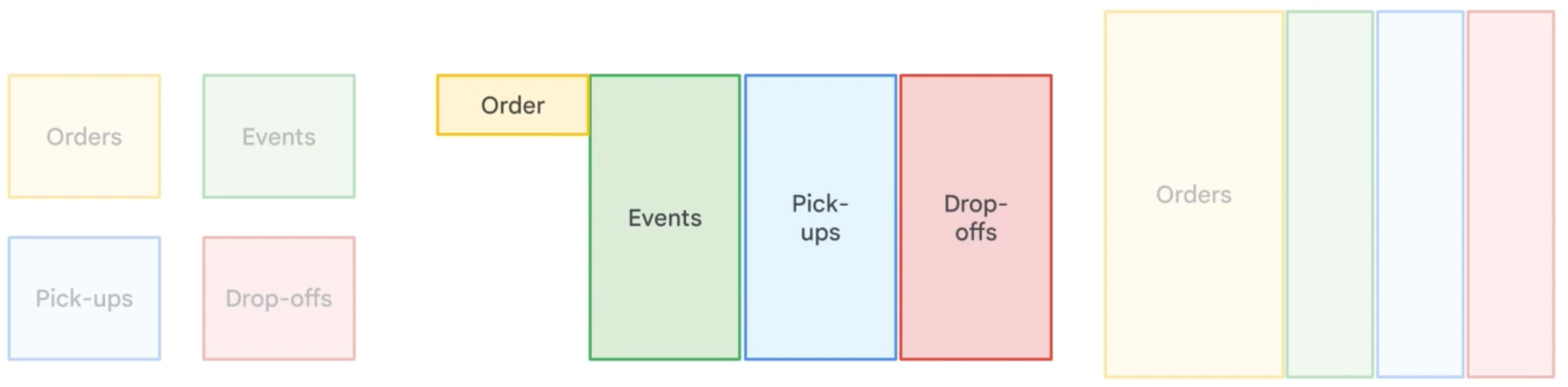
Comparison of different data normalization strategies: Original tables on the left, denormalized data with nested order records in the middle, and denormalized data with repeated records on the right. Image by Google Cloud.
Partitioning and clustering are powerful features in BigQuery that help optimize storage and query performance.
A partitioned table is divided into segments, called partitions, that make it easier to manage and query the data. By splitting a large table into smaller partitions, you can improve query performance and control costs by reducing the number of bytes read by a query.
Tables can be partitioned by specifying a partition column which is used to segment the table.
A clustered table implies organizing the data contained within the table according to single or multiple columns to optimize the queries when applying specific constraints.
You can observe both concepts in the following diagram.
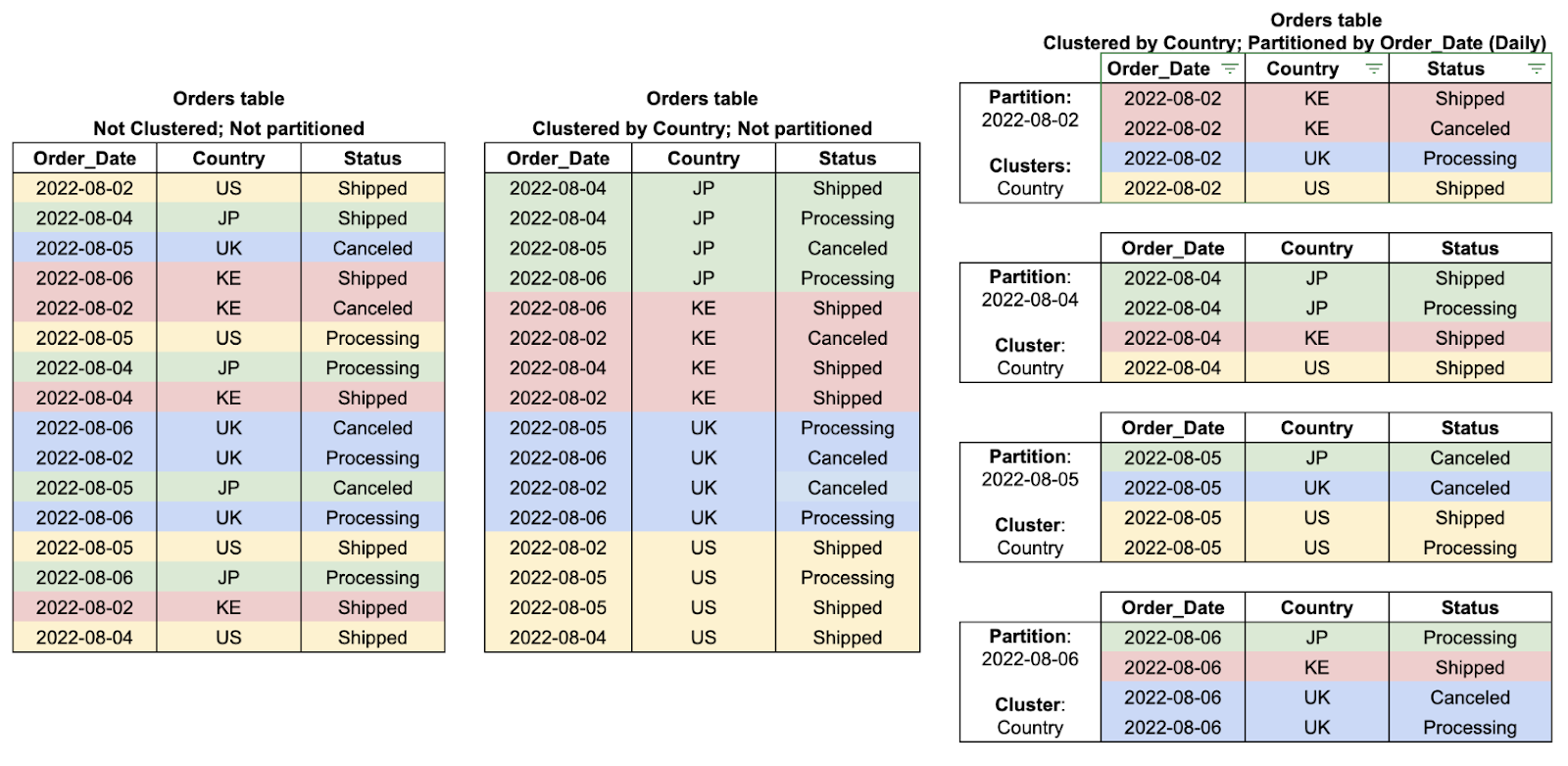
Table cluster and partition examples: The default table is on the left, the clustered table is in the middle, and the clustered and partitioned table is on the right. Image by Google Cloud.
When storing and querying data, it is helpful to keep the following data type properties in mind:
ORDER BY clause. This applies to all data types except for ARRAY, STRUCT, GEOGRAPHY, and JSON.GROUP BY, DISTINCT, and PARTITION BY. All data types except ARRAY, STRUCT, GEOGRAPHY, and JSON are supported. 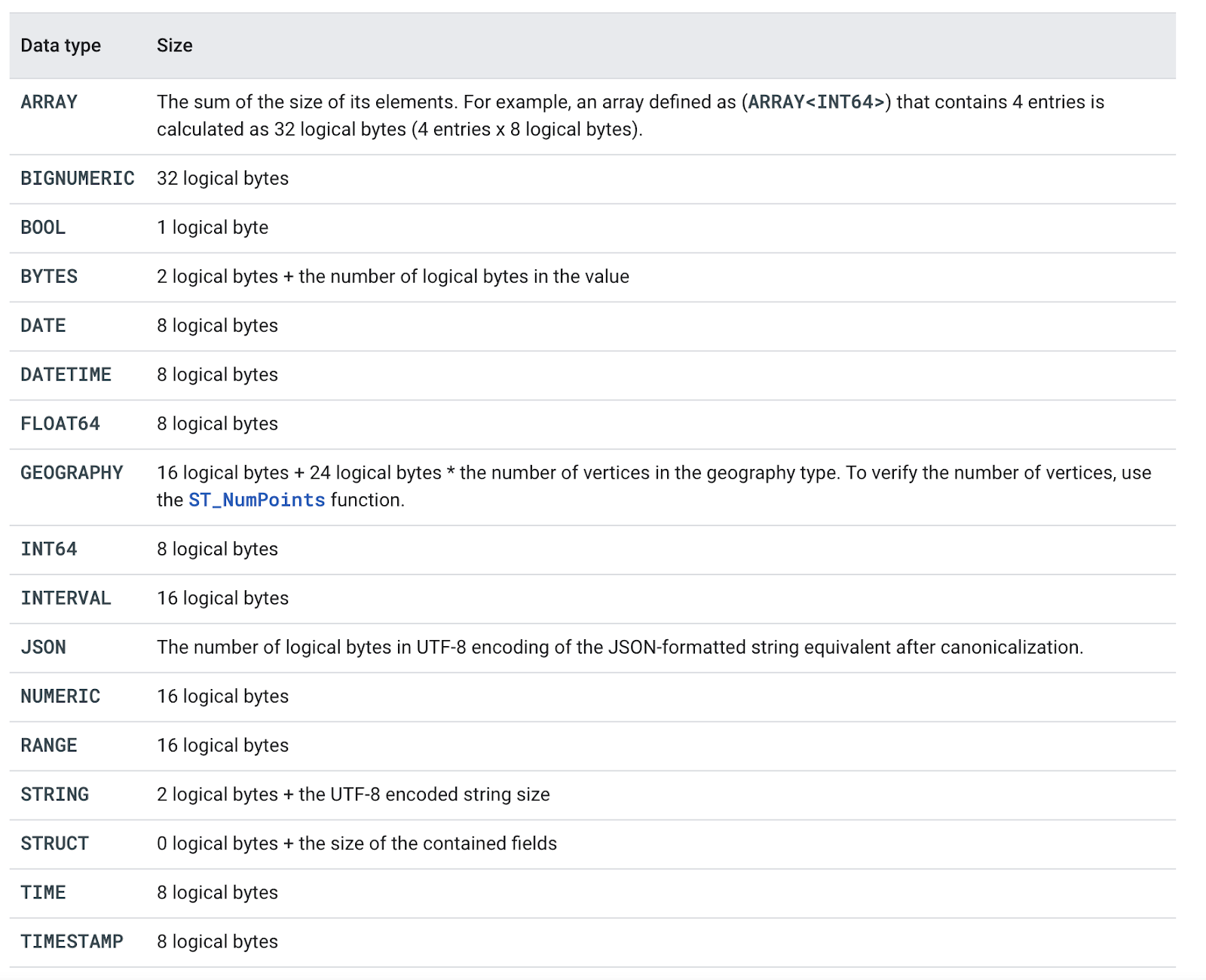
BigQuery data types. Image from Google Cloud Documentation.
Remember to use the appropriate data types for each variable, and always try to use the smallest unit datatype right for a given value.
Now that we know the best data modeling strategies, how can we load data into BigQuery?
To start using BigQuery for business intelligence or other data operations, we usually need to “ingest” data from different sources into it. Let’s review some methods to do that.
BigQuery supports various data ingestion methods, including batch loading, streaming, and multiple integrations with Cloud Storage. Choosing the right method depends on your use case and data volume.
Batch loading involves loading large volumes of data into BigQuery in bulk. This method is suitable for historical data loads and periodic data updates that are not too frequent.
Traditional extract, transform, and load (ETL) jobs fall into this category.
Options for batch loading in BigQuery include:
Batch loading can be done as a one-time operation or on a recurring schedule. To generate a recurrent schedule, you can simply run BigQuery Data Transfer Service transfers on a schedule, use an orchestration service such as Cloud Composer to schedule load jobs or use a cron job to load data on a schedule like Pub/Sub.
Streaming data allows you to ingest data into BigQuery in real time. This method is ideal for applications that require up-to-date data for analysis and reporting.
Options for streaming in BigQuery include the following:
Another alternative is to use SQL to generate new data from existing tables and store the results in BigQuery. Options for generating data include:
Monitoring is crucial for running reliable applications in the cloud. BigQuery workloads are no exception, especially if your workload has high volumes or is mission-critical.
Any job within BigQuery relies on security permissions, requires some resources, and implies an associated cost, so it is important to monitor its activity.
Effective resource management is important for optimizing BigQuery's performance. It involves strategically allocating resources such as slots and reservations to ensure that queries are executed efficiently.
Proper resource management helps to avoid bottlenecks and ensures that workloads are distributed evenly, thereby maximizing the system’s throughput and minimizing wait times.
Monitoring performance and usage is essential to maintaining BigQuery's efficiency. This includes tracking query performance, identifying slow-running queries, and analyzing usage patterns. To monitor BigQuery’s performance, it is important to leverage logs.
Logs are text records that are generated in response to particular events or actions. BigQuery creates log entries for actions such as creating or deleting a table, purchasing slots, or running a load job.
Ensuring the security of your BigQuery data involves implementing robust access controls. Use IAM (Identity and Access Management) roles to grant appropriate permissions to users and groups.
Encrypting data both at rest and in transit provides an additional layer of security. Regularly auditing access logs and permissions helps maintain compliance and prevent unauthorized access.
The Comprehensive Guide to Mastering Cloud Services provides vast information about security in GCP.
Cost management strategies are vital for controlling expenses while using BigQuery. These strategies include setting budgets, taking advantage of cost controls, and optimizing queries to reduce the amount of data processed.
Leveraging BigQuery’s pricing models, such as flat-rate pricing for predictable workloads and on-demand pricing for variable workloads, can help manage costs effectively.
Additionally, leveraging techniques already discussed, such as partitioned tables, can further optimize query costs by reducing the amount of data scanned.
BigQuery has been successfully implemented in various real-world scenarios to efficiently manage and analyze large datasets. Some notable examples are:
You can learn more about real-world companies leveraging BigQuery and GCP on the Google Cloud website.
Cloud-based data warehousing with BigQuery offers unparalleled advantages in managing and analyzing large datasets. Adopting the strategies we discussed in this article can help you make informed decisions and gain a competitive edge in the data-centric landscape.
If you want to expand your knowledge of cloud services and data warehousing, I strongly encourage you to follow more hands-on tutorials.
If you're new to the field, you can start with our GCP introductory course. Some other great resources to consider are:
Learn more about data engineering and GCP with these courses!
Course
Course
Course
blog
Oleh Maksymovych
9 min
blog
Jana Barth
13 min
blog
Sanjana Putchala
10 min
Tutorial
Eduardo Oliveira
Tutorial
Zoumana Keita
code-along
Eduardo Oliveira


