
Course
Understanding ChatGPT
1 hr
424.4K
GPT-4 Vision (GPT-4V) is a multimodal model that allows a user to upload an image as input and engage in a conversation with the model. The conversation could comprise questions or instructions in the form of a prompt, directing the model to perform tasks based on the input provided in the form of an image.
The GPT-4V model is built upon the existing capabilities of GPT-4, offering visual analysis in addition to the existing text interaction features. We have covered the beginner-friendly introduction to the OpenAI API that’ll help you get up to speed on the developments prior to the release of the GPT-4V model.
Now that we’ve understood some of the many capabilities of GPT-4 Vision, let’s go hands-on to experience it better ourselves.
GPT-4 Vision is currently (as of Oct 2023) available for the ChatGPT Plus and Enterprise users only. ChatGPT Plus costs $20/month, which can be upgraded to from your regular free ChatGPT accounts.
Assuming you’re completely new to ChatGPT, here’s how to access GPT-4 Vision:
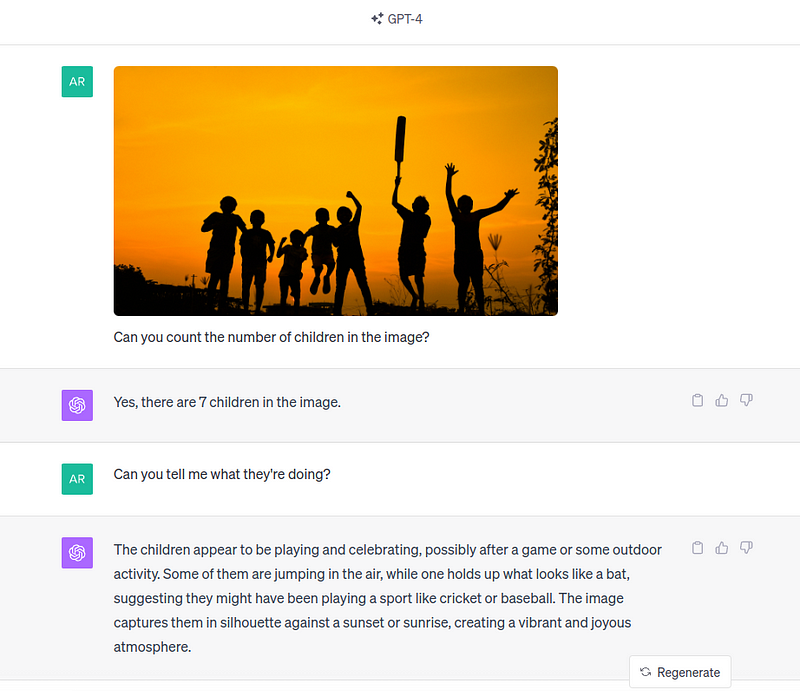
Here, GPT-4 Vision does a pretty good job of understanding that the kids were playing cricket based on the bat in a child’s hand. In the world of AI, this task is known as object detection, where the objects identified are children and the bat. Check out our tutorial on YOLO object detection to learn more.
Similarly, you can proceed to perform a different task better depending on your use case.
Now that we have understood its capabilities, let us extend them to some practical applications in the industry:
GPT-4 Vision’s integration of advanced language modeling with visual capabilities opens up new possibilities in academic fields, particularly in deciphering historical manuscripts. This task has traditionally been a meticulous and time-consuming endeavor carried out by skilled paleographers and historians.
We first give an image that appears to be part of an old newspaper article:
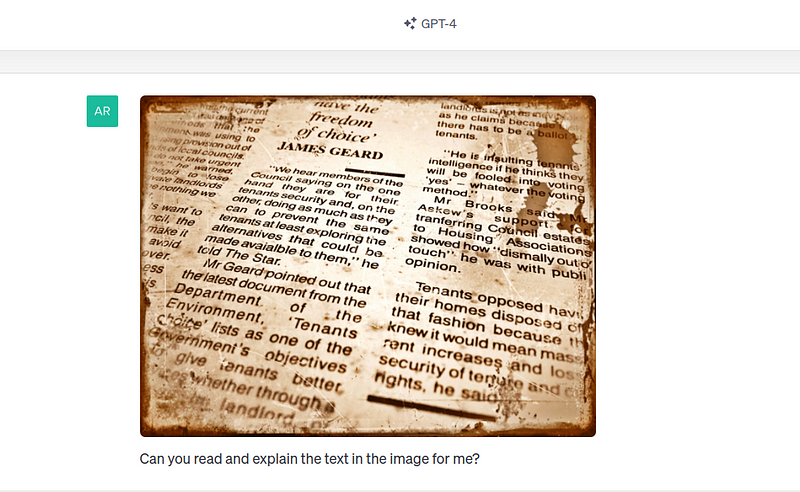
GPT-4 Vision does a good job of reading the contents of the image and interpreting it:
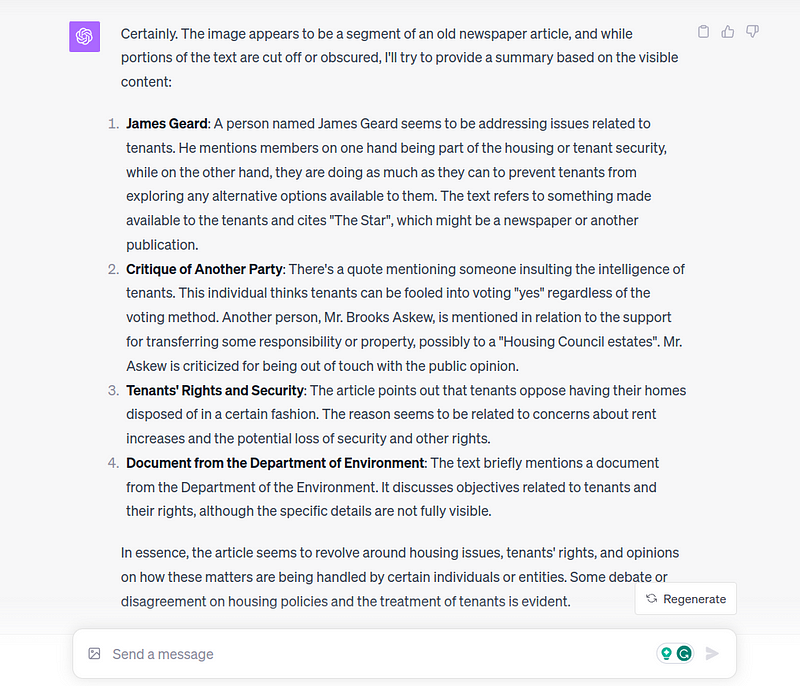
The model was able to read, decipher the contents, and provide an analysis of it while providing a realistic answer, that some portions of the image are cut off and obscured.
However, it is also worth noting that the model struggles when given complex manuscripts, especially in other languages (more on this later), as seen below:
The GPT-4 vision can write code for a website when provided with a visual image of the design required. It takes from a visual design to source code for a website. This single ability of the model can drastically reduce the time taken to build websites.
Let us prompt the GPT-4 Vision with a hand-drawn simple design for a blogging website.
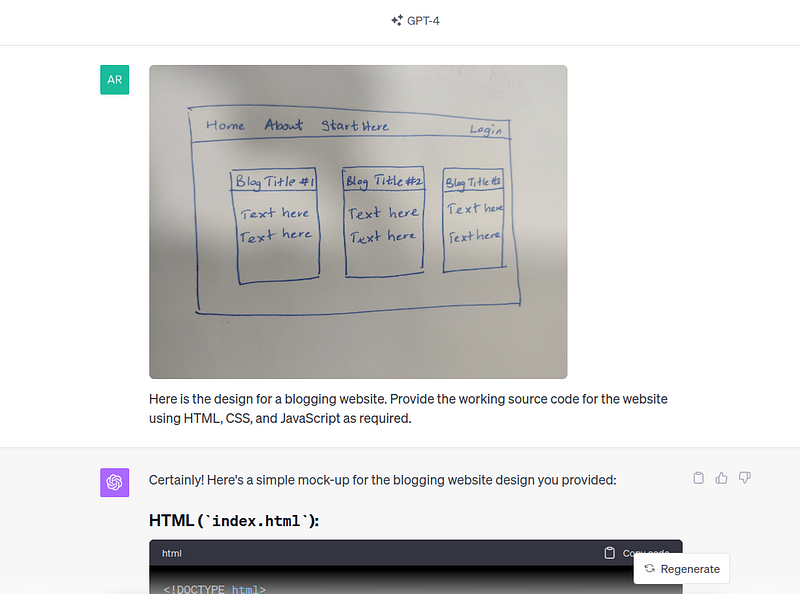
Once it provides the source code, we simply copy-paste and create the HTML and CSS files as instructed. Here’s how the website looked:
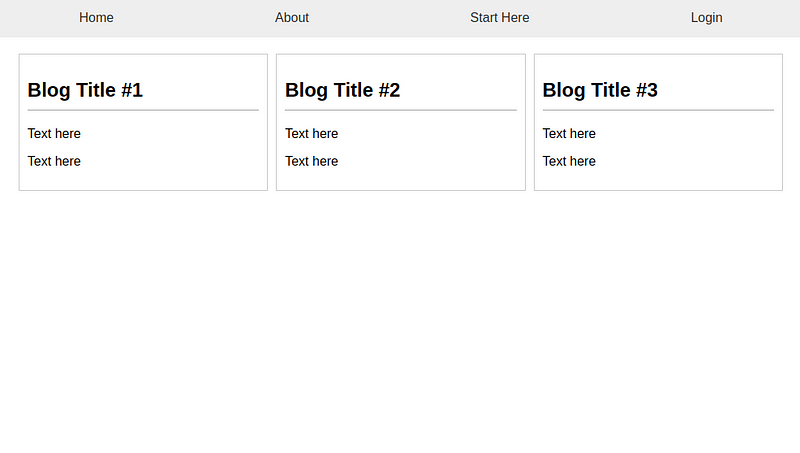
Doesn’t it look strikingly similar? Of course, we gave a simple example, but you could take it from here and develop a more complex and tailor-made website in a fraction of the time, thanks to the newly introduced GPT-4 Vision model.
The model is capable of analyzing data visualizations to interpret the underlying data and provide key insights based on the visualizations. To test out this feature, we can simply give a plot and ask for insights.
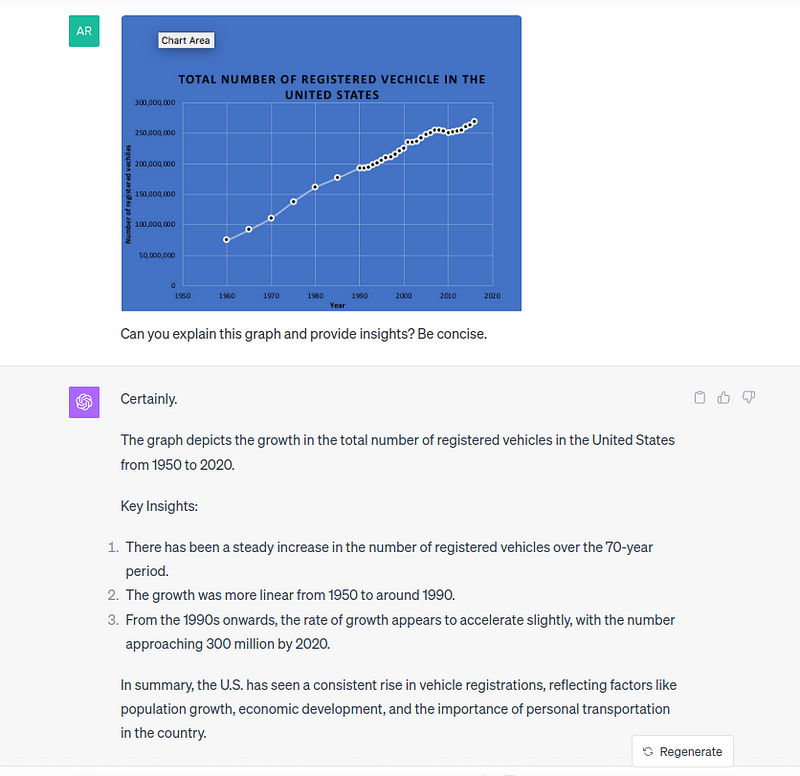
While it does a good job of understanding the overall context of the plot and the linear trend, it makes errors by mentioning the starting year as 1950, though the data points only start from 1960. The model also derives factors such as population growth and economic development — while they could be true, those insights cannot be derived from this particular graph alone.
One can ask multiple follow-up questions to refine the initial output from the GPT-4 Vision model. Based on our testing, a human in the loop is still necessary for reviewing the insights, and the model can enhance the productivity of data interpretation use cases.
With the advent of ChatGPT, social media is full of various prompt engineering techniques, and many have found surprising, creative ways to use the generative technology to their advantage.
For this tutorial, we will use the DALL-E-3 (which is also available in ChatGPT Plus) together with GPT-4 Vision, to creatively create a social media post.
Step 1: Ask GPT-4 to create a prompt to generate an image. Let’s say you want to create a post contrasting the differences between a data scientist role in a startup vs a corporate one.
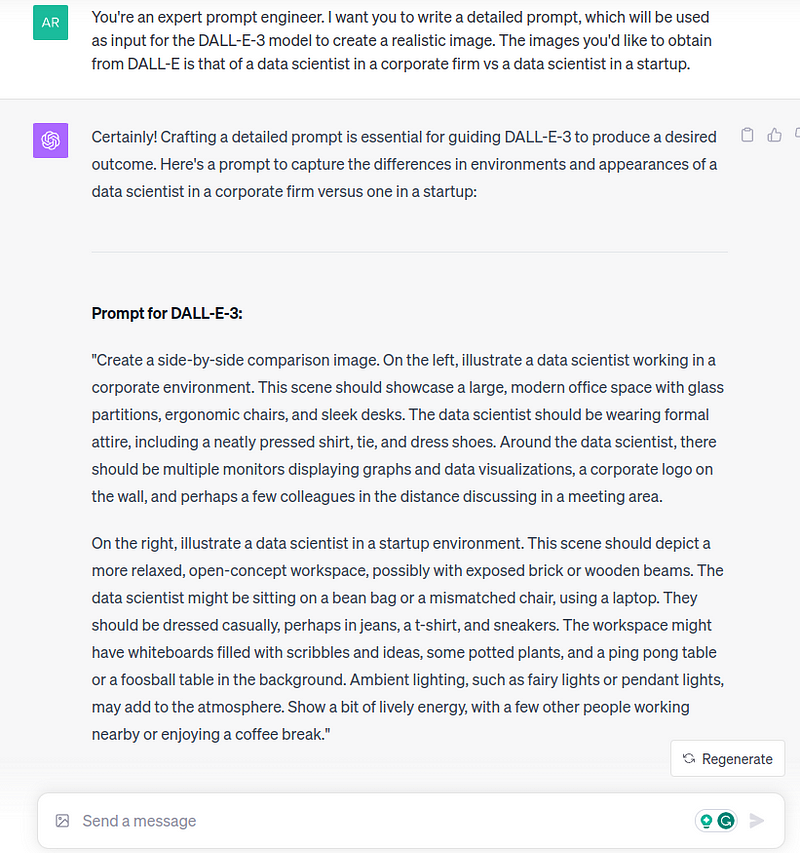
Step 2: Use the prompt and generate an image from DALL-E. You can tweak and refine the prompt till you’re happy with the output.

Step 3: Use the image and ask GPT-4 Vision to create a post that goes alongside the image.
By tweaking and providing a more detailed prompt, a better output could be obtained, and creative content generation could be explored further. It's worth noting that spamming the internet or social media with AI-generated content isn’t recommended, as this content comes with its own limitations. Instead, fact-check and refine it with your own experiences.
Of course, this isn’t an exhaustive list of use cases that’s possible — GPT-4 Vision is capable of many more. Instead, treat this as an inspiration and a starting point to exploring your curiosity by applying the technology to a domain of your choice.
There’s one last thing you need to be aware of before using GPT-4 Vision in use cases — the limitations and risks associated with it.
This is particularly important because OpenAI themselves have taken a few extra months since the launch of GPT-4 in March 2023 to test it with their internal and external “red-teaming” exercise to determine the shortcomings of this generative technology, which they have outlined in the system card.
While the GPT-4 model represents significant progress toward reliability and accuracy, it’s not always the case. According to OpenAI, based on the internal tests, the GPT-4 Vision can still be unreliable and inaccurate at times. The team goes as far as even mentioning that “ChatGPT can make mistakes. Verify important information.” beneath the chat bar when we input text and images.
Thus, it is of utmost importance that users critically assess the output of the model and remain vigilant.
According to OpenAI, similar to its predecessors, GPT-4 Vision continues to reinforce social biases and worldviews, including harmful stereotypical and demeaning associations for certain marginalized groups. Thus, it is important to understand this limitation and take other necessary steps to handle the bias within the use case itself and not rely on the model to solve it.
In addition to the bias concerns, the data shared with ChatGPT may be used to train models unless opted out; hence, it’s important to be mindful not to be sharing any sensitive or private information with the model. Users also may choose to opt out of sharing data for improving models by going into “Data Controls” under the “Settings & Beta section.”
GPT-4 Vision is unable to answer questions that ask to identify specific individuals in an image. This is an expected “refusal” behavior by design. Furthermore, OpenAI advises refraining from using GPT-4 Vision on high-risk tasks, which include:
Thus, as users, we need to be vigilant in using GPT-4 Vision responsibly, particularly in above mentioned high-risk tasks and sensitive contexts.
This tutorial provided you with a comprehensive introduction to the newly released GPT-4 Vision model. You also were cautioned on the limitations and risks the model poses, and now understand how and when to use the model.
The most practical way to master the new technology is to get your hands on it and experiment by providing various prompts to evaluate its capabilities, and over time, you’d grow more comfortable with it.
While this is a relatively new and one-month-old tool, it’s built upon the principles of Large Language Models and GPT-4. Here are some more related resources if you’re looking to dive deep into the underlying foundational and related concepts of the GPT-4 Vision model:
Start Your ChatGPT Journey Today!
Course
Course
Course
blog
Sandra Kublik
15 min
blog
Richie Cotton
7 min
blog
Adel Nehme
7 min
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali

