
Course
Introduction to MongoDB in Python
3 hr
24K
In the recent past, computers functioned like efficient but literal librarians. If you searched for "giant robot battles," they would only find titles with those exact words. A perfect match like "Kaiju Mech Warfare" would be overlooked. Computers recognised words but missed the music—they lacked understanding, nuance, and context. This was the keyword search era, which served as our best option for many years.
Then came a revolution. Drawing inspiration from the human brain, artificial intelligence developed a new way of learning. Rather than simply memorising words, AI began comprehending relationships between them. It is understood that "king" relates to "man" as "queen" relates to "woman." It recognised that "happy," "joyful," and "ecstatic" share an emotional territory, while "sombre" exists in a completely different realm.
How did AI accomplish this? By creating a map of meaning.
Imagine a vast, multi-dimensional galaxy where every concept—a word, a sentence, an image, a song—is a star. In this galaxy, stars with similar meanings cluster together, while unrelated ones exist light-years apart.
A vector embedding is simply the coordinate of a star in this galaxy. It's a list of numbers (e.g., [0.12, -0.45, 0.89, ...]) that precisely locates a concept on this map of meaning.
Vector search is the revolutionary ability to navigate this map. When you ask, "a film about an orphaned boy who discovers he's a wizard," we don't hunt for those exact keywords. Instead, we:
The closest stars represent the most semantically similar results. This is how AI evolved from a literal librarian to a wise sage that understands what you actually mean.
Searching by meaning rather than keywords powers modern AI applications across industries. This capability enables:
Vector search bridges human intent and digital data, fundamentally transforming how we interact with information. This technology makes digital systems feel less mechanical and more like intuitive collaborators.
Welcome to the new frontier of search! MongoDB introduced Vector Search in Atlas. This lets you store and query vector embeddings (like those from text, images, or audio) directly inside MongoDB—no need for a separate vector database like Pinecone or Weaviate.
In this tutorial, we will build a simple but powerful shoes recommendation engine using Python and MongoDB Atlas. You'll learn how to transform text into meaningful numerical representations (vectors) and then use Atlas's built-in Vector Search to find movies with similar plots.
pip install pymongo sentence-transformers numpy
vectorDemoitems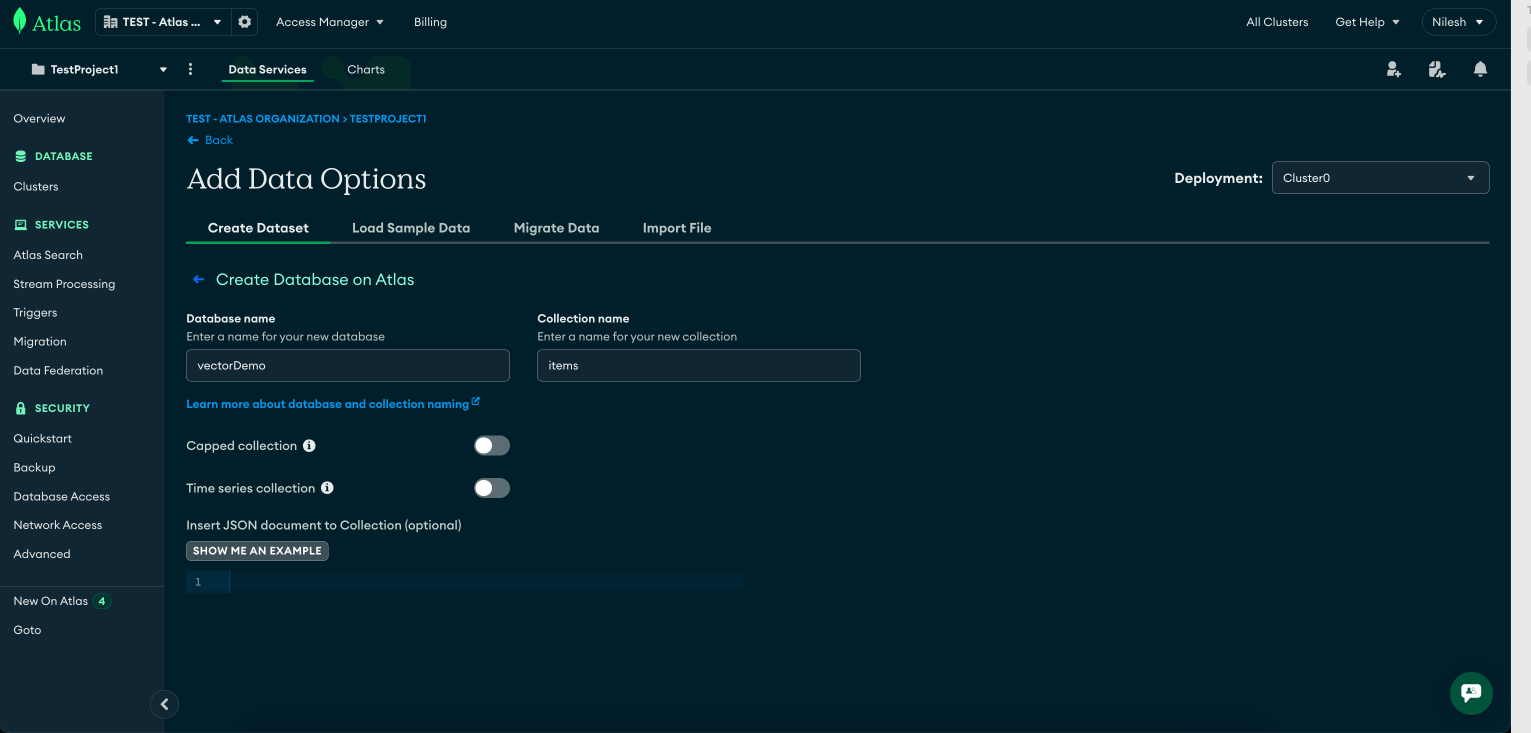
items.{
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 768,
"similarity": "cosine"
}
]
}
Note: 768 is the embedding size we’ll use with the sentence-transformers model.
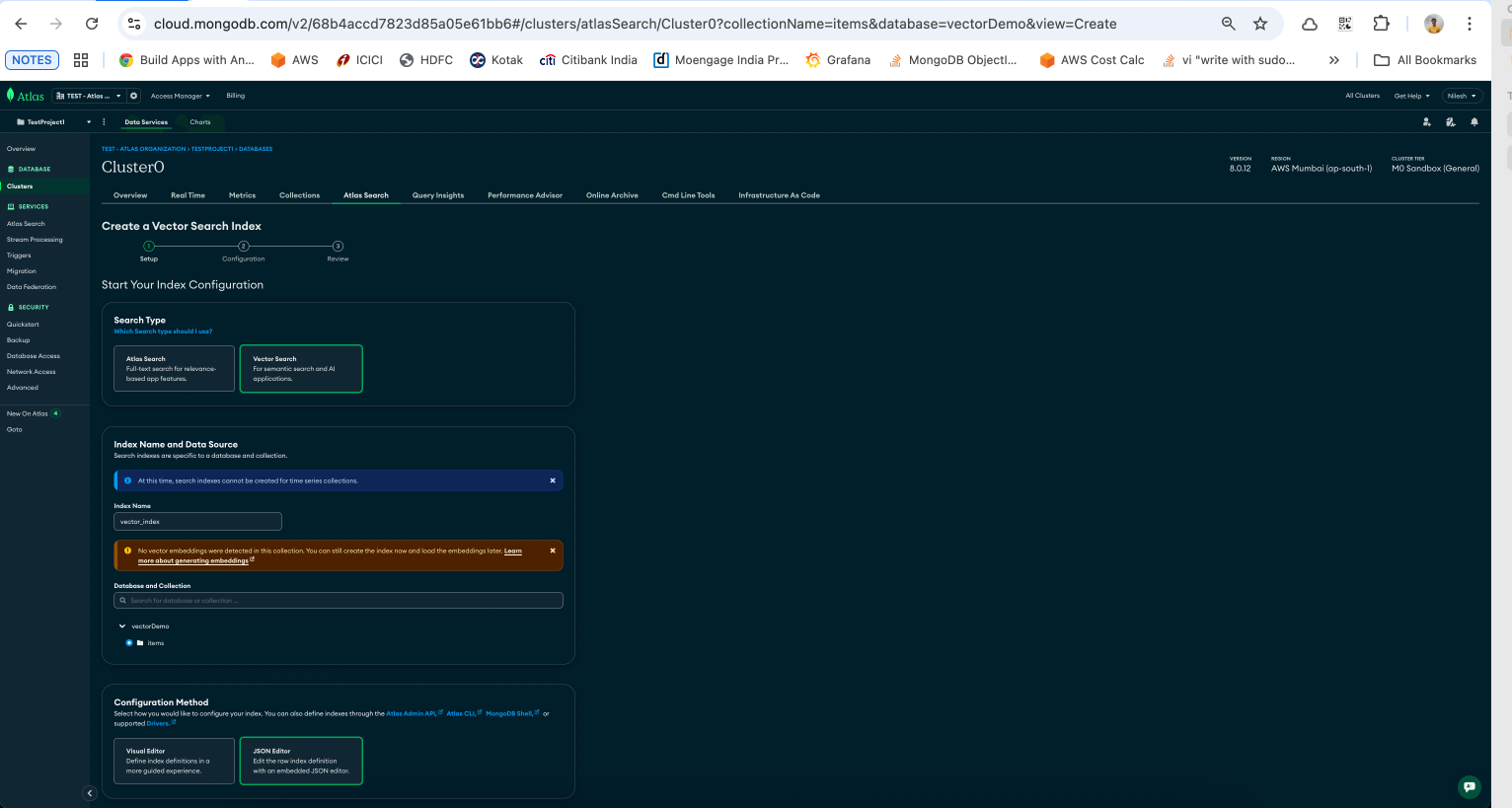

Understanding the index definition:
"type": "vector": Tells MongoDB Atlas this is a vector index."path": "embedding": Crucially, this points to the field in our documents that contains the vectors."numDimensions": 768: This must match the dimension of the vectors our model produces."similarity": "cosine": The algorithm used to measure the "closeness" of vectors. It is excellent for text-based similarity.Get your MongoDB Atlas connection string:
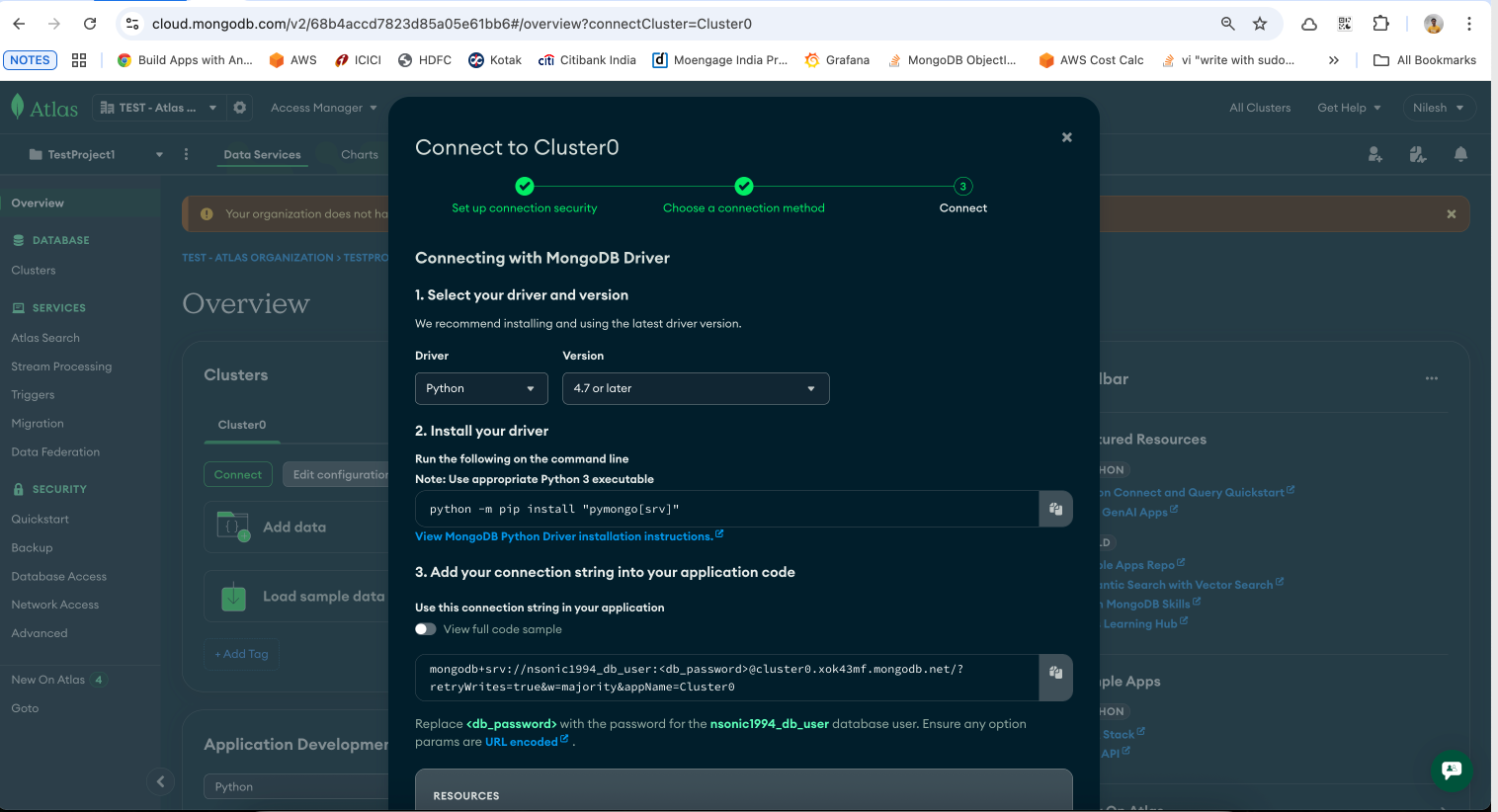
<username>, <password>, and <cluster-url> in the snippet below.from pymongo import MongoClient
# Replace with your Atlas connection string
uri = "mongodb+srv://<username>:<password>@<cluster-url>/vectorDemo?retryWrites=true&w=majority"
client = MongoClient(uri)
db = client["vectorDemo"]
collection = db["items"]
print("Connected to MongoDB Atlas")
# Clear existing
collection.delete_many({})
print("Cleared collection.")We’ll use SentenceTransformers to convert text into embeddings.
from sentence_transformers import SentenceTransformer
# Choose model: higher-quality for search -> "sentence-transformers/all-mpnet-base-v2" (768-d)
# If you need faster/smaller: "all-MiniLM-L6-v2" (384-d)
MODEL_NAME = "sentence-transformers/all-mpnet-base-v2"
# MODEL_NAME = "all-MiniLM-L6-v2"
# Note: if you use all-mpnet-base-v2, your Atlas vector index must use numDimensions: 768
# If you use all-MiniLM-L6-v2, index numDimensions: 384
model = SentenceTransformer(MODEL_NAME)
def embed_text(text: str):
return model.encode(text).tolist()Let’s store some product descriptions in MongoDB with their embeddings.
# Each product includes name, description, list of features, use_cases and tags.
products = [
# Marathon / long-distance running (explicit!)
{
"name": "MarathonPro 3000",
"description": "Designed specifically for marathon and ultra distance running: maximum cushioning, breathable knit upper, responsive midsole and engineered heel support for long-run comfort.",
"features": ["marathon", "long-distance", "max cushioning", "breathable", "support"],
"category": "shoes",
"use_cases": ["marathon", "long-distance running", "road running"],
"tags": ["running", "endurance", "comfort"]
},
{
"name": "Enduro LongRun",
"description": "Lightweight long-run trainer optimized for marathon pacing with added cushioning, stable platform, and enhanced forefoot energy return for hours of comfortable running.",
"features": ["long-run", "lightweight", "energy return", "cushioning"],
"category": "shoes",
"use_cases": ["marathon", "road running"],
"tags": ["running","marathon","comfort"]
},
# Road running / neutral
{
"name": "Red Road Runner",
"description": "Neutral road running shoe for daily training: breathable mesh, moderate cushioning and responsive ride; suitable for tempo runs and long easy runs.",
"features": ["road running", "breathable", "moderate cushioning"],
"category": "shoes",
"use_cases": ["training", "road running", "tempo runs"],
"tags": ["running","training"]
},
# Trail running (explicit trail)
{
"name": "TrailMaster RidgeGrip",
"description": "Trail-running shoe with aggressive outsole, rock plate for protection, waterproof upper, designed for technical trails and rugged terrain.",
"features": ["trail", "high grip", "rock plate", "waterproof"],
"category": "shoes",
"use_cases": ["trail running", "hiking", "off-road"],
"tags": ["trail","outdoors"]
},
# Tennis & court
{
"name": "CourtPro Tennis",
"description": "Court shoe with lateral support, non-marking sole and reinforced toe; built for tennis footwork and short intense bursts, not for long-distance running.",
"features": ["court", "lateral support", "non-marking sole"],
"category": "shoes",
"use_cases": ["tennis","court sports"],
"tags": ["tennis","sport"]
},
# Formal
{
"name": "Oxford Leather Formal",
"description": "Classic leather formal shoe for office and events: polished leather, sturdy sole, refined silhouette.",
"features": ["formal", "leather", "office"],
"category": "shoes",
"use_cases": ["formal wear","office"],
"tags": ["formal","leather"]
},
# Hiking
{
"name": "Alpine Trek Boots",
"description": "High-ankle hiking boots with waterproof membrane, ankle support and durable lugged outsole for mountain treks.",
"features": ["hiking", "waterproof", "ankle support", "lugged outsole"],
"category": "shoes",
"use_cases": ["hiking","trekking","outdoor"],
"tags": ["outdoors","hiking"]
},
# Casual sneakers
{
"name": "Classic Canvas Sneaker",
"description": "Casual everyday canvas sneaker with rubber sole, comfortable fit for daily wear and walking.",
"features": ["casual","canvas", "everyday"],
"category": "shoes",
"use_cases": ["casual","walking"],
"tags": ["casual"]
},
# Cross-trainer
{
"name": "CrossFit Trainer",
"description": "Stable cross-trainer shoe engineered for gym workouts, short sprints, and lateral movements; flexible yet supportive.",
"features": ["cross-train","stable","gym"],
"category": "shoes",
"use_cases": ["gym","cross-training"],
"tags": ["training","gym"]
},
# Cleats
{
"name": "Pro Soccer Cleats",
"description": "Low-profile football/soccer cleats with studded outsole; optimized for grip on grass and agility.",
"features": ["cleats","studs","agility"],
"category": "shoes",
"use_cases": ["soccer","football"],
"tags": ["sports","cleats"]
}
]
# ---------- Create 'canonical_text' to improve embedding quality for better scoring ----------
for p in products:
# join features and others into one rich text blob
features = ", ".join(p["features"])
uses = ", ".join(p["use_cases"])
tags = ", ".join(p["tags"])
canonical = f"{p['name']}. {p['description']}. Features: {features}. Use cases: {uses}. Tags: {tags}."
p["canonical_text"] = canonical
# ---------- Embed canonical_text----------
print("Embedding items...")
for p in products:
p["embedding"] = embed_text(p["canonical_text"])
# ---------- Insert into MongoDB ----------
collection.insert_many(products)
By using insert_many, we perform a single, efficient bulk write operation to our database.
It's time for the final, most exciting step! We will use MongoDB's aggregation framework and the $vectorSearch—an operator to find the best shoe query.
query_text = "25k long running best shoes"
query_embedding = embed_text(query_text)
pipeline = [
{
"$vectorSearch": {
"index": "vector_index", # Use the vector search index you created
"path": "embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"limit": 3
}
},
{
"$project": {
"name": 1,
"description":1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
results = collection.aggregate(pipeline)
print(f"\nSearch results for: '{query_text}'\n")
for r in results:
print(f"- {r['name']} (score: {r['score']:.4f})")Dissecting the $vectorSearch pipeline:
$vectorSearch: This is the core operator. It efficiently compares our queryVector against the indexed plot_embedding field for all documents.$project: This stage reshapes the output. We include the name and description, exclude the noisy _id and other fields, and most importantly, we add a score field using $meta: "vectorSearchScore". This score, from 0 to 1, indicates how similar the result is to our query.If everything is set up correctly, you’ll see something like this:
Search results for: '25k long running best shoes'
- MarathonPro 3000 (score: 0.7980)
- Red Road Runner (score: 0.7479)
- Enduro LongRun (score: 0.7389)Notice that “MarathonPro 3000” comes out on top—exactly what we’d expect.
Congratulations! You've successfully built a vector search application from scratch. You've learned how to connect to a database, create and validate data, generate vector embeddings, and leverage the power of MongoDB Atlas to find information in a truly intelligent way. Welcome to the future of data interaction.
In this tutorial, you successfully learned how to:
Experiment with different similarity metrics (dotProduct, euclidean).
Top DataCamp Courses
Course
Course
Course
blog
Anaiya Raisinghani
12 min
Tutorial
Karen Zhang
Tutorial
Nilesh Soni
Tutorial
Derrick Mwiti
Tutorial
Anaiya Raisinghani
Tutorial
Bex Tuychiev
