
Track
Deep Learning in Python
18 hr
Seeking guidance to land your dream role and refine your deep learning skills? Look no further. This article offers answers to 20 common interview questions for deep learning positions, aiding you in excelling during interviews with just a bit of practice.
General deep learning questions usually relate to understanding the field, what distinguishes it from other AI areas, connecting real-world problems with deep learning solutions, and understanding their challenges and limitations.
Deep learning is a subarea of machine learning and AI as a whole. It involves training large models based on artificial neural networks on data.
The models learn to solve challenging predictive and inference tasks (such as classification, regression, object recognition in images, etc.) by automatically discovering complex patterns and features underlying the data. This happens by mimicking the complex internal structures in human brains.
Our Understanding Artificial Intelligence course comprehensively demystifies the areas and solvable tasks of AI, including deep learning.
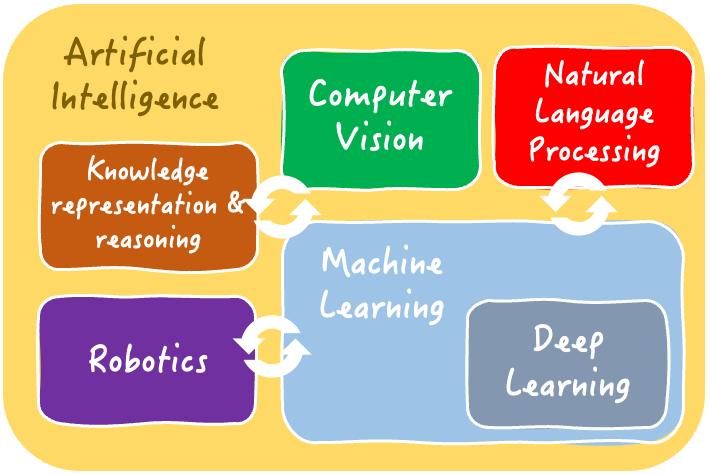
The interrelated areas of Artificial Intelligence | Iván Palomares
Deep learning solutions stand out in problems where the data has high complexity, e.g. under unstructured or high-dimensional data.
It is also the preferred choice for problems with massive amounts of data or requiring capturing nuanced patterns: more often than not, they can succeed in extracting and understanding meaningful data features that machine learning approaches may not find.
Here are some examples of problems solvable by deep learning solutions:
Beware, however, that for many simpler tasks and datasets, lightweight machine learning models like decision trees and regressors might be more than enough, making them a better choice than deep learning models due to being easier and cheaper to train and deploy.
Deep learning models usually demand thorough data preparation and processing skills; hence you may find the following article on data engineering interviews useful.
Deciding on a suitable deep learning approach depends on several factors, such as the nature of the data, the complexity of the problem, and the available computing resources.
The following steps are a simple yet effective recipe to help you make this important choice:

Three common deep learning architectures and their applications | Iván Palomares
Designing a deep learning architecture tailored to a specific task like classification involves choosing the appropriate number and size of layers of neurons, as well as choosing the right activation functions.
These decisions are typically made predicated on the characteristics of the data. For image classification, you might use a stack of convolutional layers within your architecture to capture visual patterns like colors (or combinations of colors), shapes, edges, etc.
The top layer situated at the very end of your deep learning architecture (model head) is also dependent on your task at hand, as it must be designed to produce the desired output.
For instance, for an image classification problem such as classifying chick images into bird species, these last layers should have a softmax activation function that outputs class probabilities to determine the most likely class of bird species to which the image being analyzed belongs.
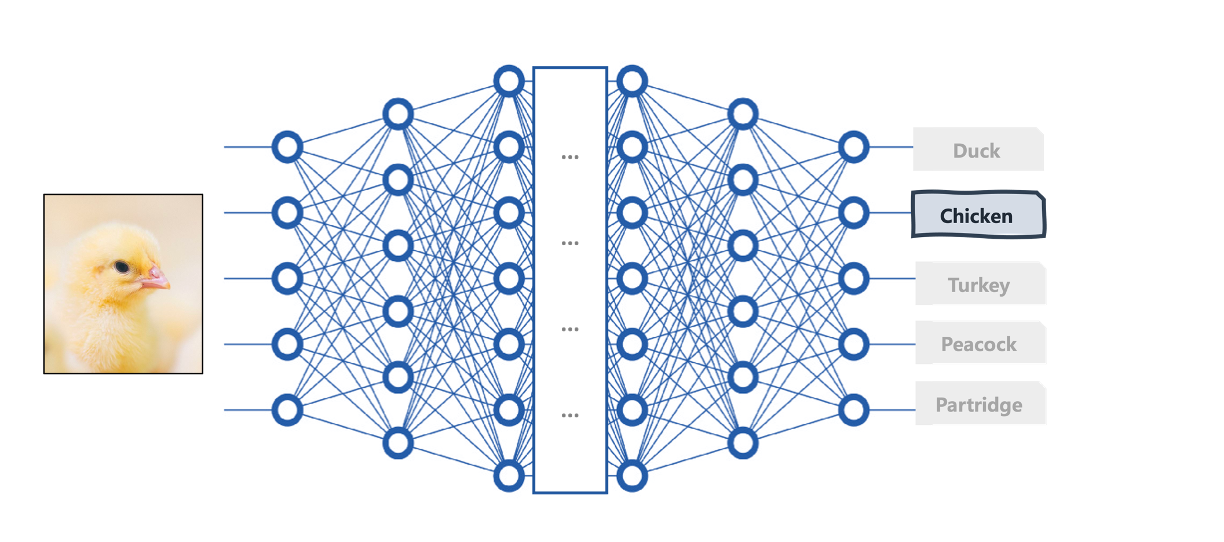
A deep learning architecture for image classification | Iván Palomares
Frequent challenges that may hinder the successful real-world application of deep learning models include overfitting, vanishing and exploding gradients, and the necessity of large amounts of labeled data for training. The good news is that thanks to continued research efforts, there are approaches to address them.
On top of these problem-specific solutions, make sure you establish regular model monitoring and fine-tuning mechanisms to ensure good performance in the long run.
If you are a new graduate or seeking your first deep learning position in the job market, you may expect questions that test your acquisition of foundational knowledge and practical skills in training and evaluating deep learning models in an experimental setting.
Activation functions are mathematical functions used in all modern deep neural network architectures. This occurs at the neuron level, during the process of mapping several neuron inputs into an output value being fired to neurons in the next layer.
They are crucial in deep learning models because they introduce non-linearity, which is vital to enable them to learn complex relationships and patterns in the data during training.
Otherwise, they’d learn little more than linearity patterns from the data by applying successive linear combinations of inputs — just like classical linear regression models do!
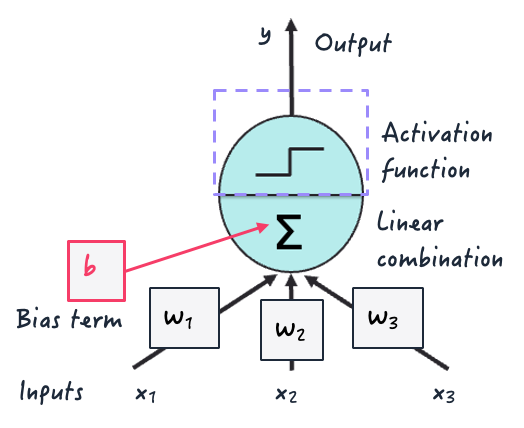
Activation function inside an artificial neuron | Iván Palomares
Examples of popular activation functions are the logistic (logit), hyperbolic tangent (tanh), and rectified linear unit (ReLU) activation, as depicted below.
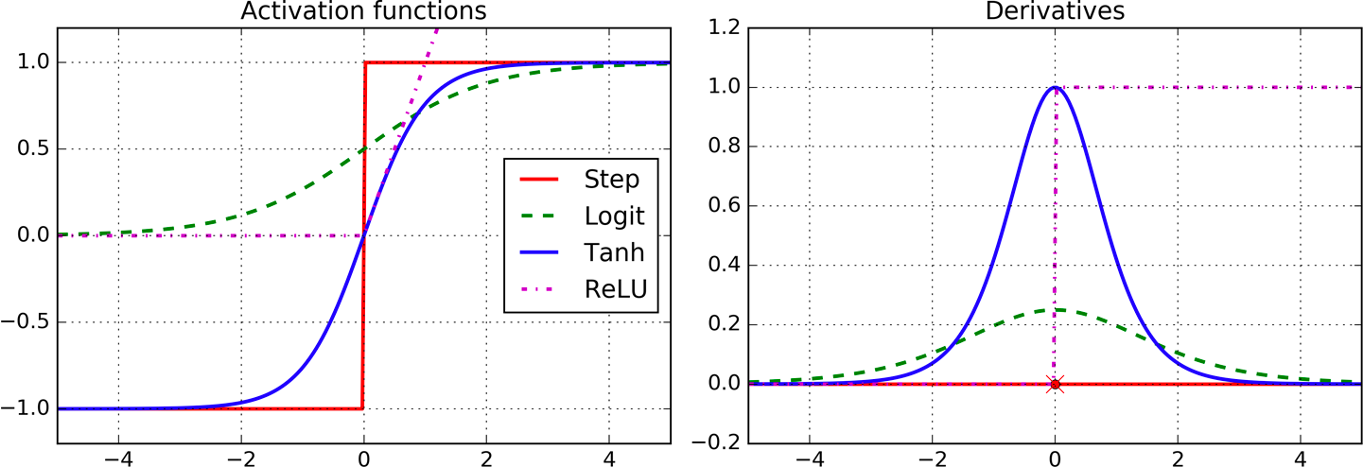
Examples of activation functions | Image by Aurelien Geron (O’Reilly)
The performance of deep learning models can be evaluated utilizing common machine learning metrics dependent upon the task.
For classification, consider metrics like accuracy, precision, recall, F1-score, and Area Under the Curve (AUC). Meanwhile, for regression, we can use error metrics like Root Mean Square Error (RMSE).
These metrics should be utilized to benchmark model predictions against ground truth labels or baseline models. For more advanced models and applications such as NLP, there are a range of language task-specific metrics like BLEU score for translation, ROUGE score for summarization, and so on.
Deep learning is used across a wide spectrum of real-world applications, some of which are:
Interview questions for an engineering-focused deep learning role will focus on aspects like programming frameworks, libraries, and tools.
To build a simple feed-forward neural network for image classification in Tensorflow, we may start by defining the model architecture layer-by-layer using Tensorflow Sequential API.
This includes specifying the appropriate number of neurons and activation functions per layer and defining the final layer (output layer) with softmax activation.
Then, we would compile the model specifying a suitable loss function like categorical cross-entropy, an optimizer like Adam, and validation metrics before training it on the training data during a specified number of epochs. Once the model has been built, its performance on the validation set can be evaluated.
Tensorflow is commonly used along with the Keras API, which you will be able to master upon completing the Advanced Deep Learning with Keras course.
To handle overfitting in a deep learning model implemented with PyTorch, a common strategy is incorporating regularization techniques such as L1 or L2 regularization with penalty terms added to the loss function.
Alternatively, dropout layers can be introduced to randomly disable neurons during training; this prevents the model from overly relying on specific features extracted from the data.
These two strategies can be combined with early stopping to finalize training when validation performance starts degrading.
Interested in honing your PyTorch skills? Then, be sure to check this Introduction to Deep Learning in the PyTorch course.
VGG, BERT, or ResNet, are well-known examples of pre-trained models that can be loaded for transfer learning and fine-tuning purposes. Specifically, the process involves replacing the model head, i.e. the final classification layer, with a new one suited to the target task.
After this slight structural change to the model architecture, we proceed to retrain it on a new dataset using a low learning rate to adapt the model weights to the new task while major features originally learned by the pre-trained models are mostly kept.
The following are some potential questions the interviewer might ask you for a position that involves building or managing deep learning solutions in computer vision like image processing applications.
CNNs are specialized deep learning architectures for processing visual data. Their stack of convolution layers and underlying operations on image data are designed to mimic the visual cortex in animal brains.
CNNs excel at tasks like image classification, object detection, and image segmentation. Here’s a brief use case description for each of these tasks:
Convolution layers in CNNs are responsible for feature extraction upon input images. They apply a set of learnable weights called filters or kernels to detect patterns and features like edges, shapes, and textures along with their spatial information and relationships, thereby learning hierarchical visual representations.
Meanwhile, pooling layers downsample feature maps (intermediate image representations) output by convolutional layers. In other words, their original spatial dimension or resolution is reduced while important extracted information is retained.
Combining successive convolution layers with pooling layers in a CNN helps increase robustness to variations in inputs, reduces computational complexity at training and inference time, and helps prevent issues like overfitting.
Among the usual challenges and limitations in deep learning models, the following examples get particularly accentuated in models for computer vision like CNNs:
Here are some potential questions the interviewer might ask you for a position involving leveraging deep learning technologies in NLP applications.
Transformers are a breakthrough family of deep learning architectures and the current state-of-the-art to address a wide range of challenging NLP problems. Attention mechanisms are pivotal to transformer architectures that underlie Large Language Models (LLMs) like BERT and GPT and are largely responsible for their success.
Transformers have the ability to capture complex patterns, contextual information, and long-range dependencies between elements of an input text, significantly overcoming problems found in previous solutions like limited memory in RNNs (Recurrent Neural Networks).
Attention mechanisms essentially weigh the importance of each token in a sequence, without the need to process it token by token.
This important component of transformers led to significant advancements in tasks like text classification, language generation, and text summarization, and has revolutionized the area of LLMs and AI as a whole.
Datacamp’s course on Introduction to LLMs in Python equips you not only with practical skills to build and leverage LLMs but also with a solid understanding of the main concepts surrounding LLMs and transformer architectures.
Model pre-training trains a deep learning model, such as BERT, for text classification, on a large corpus of text data (millions to billions of example texts) to learn language representations for general-purpose language understanding.
Model fine-tuning, on the other hand, involves taking a pre-trained model and fine-tuning its learned parameters on a specific downstream NLP application, e.g. sentiment analysis of hotel reviews.
Since fine-tuning is typically aimed at specific use cases, it requires using a small and domain-specific dataset of labeled text examples, thereby adapting the weights in parts of the model to learn the nuances of the target task and improving the model performance under that specific context without the computational cost and data requirements of training a model from scratch.
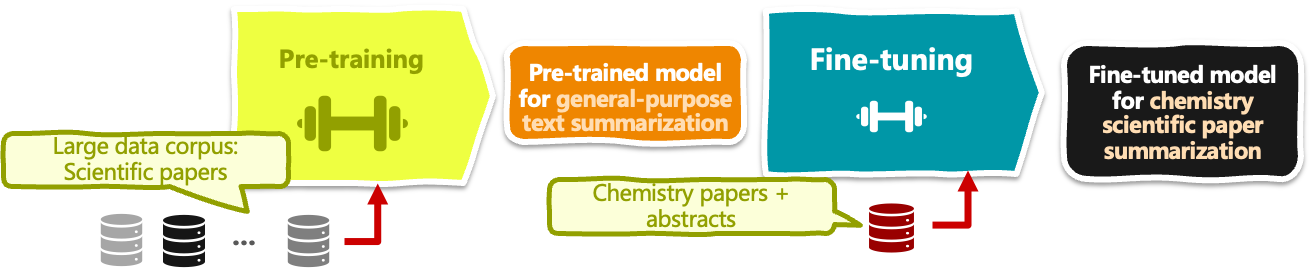
Example of model pre-training and fine-tuning an LLM for chemistry paper summarization | Iván Palomares
BERT’s architecture is a simplified variant of the original encoder-decoder transformer, called the encoder-only transformer.
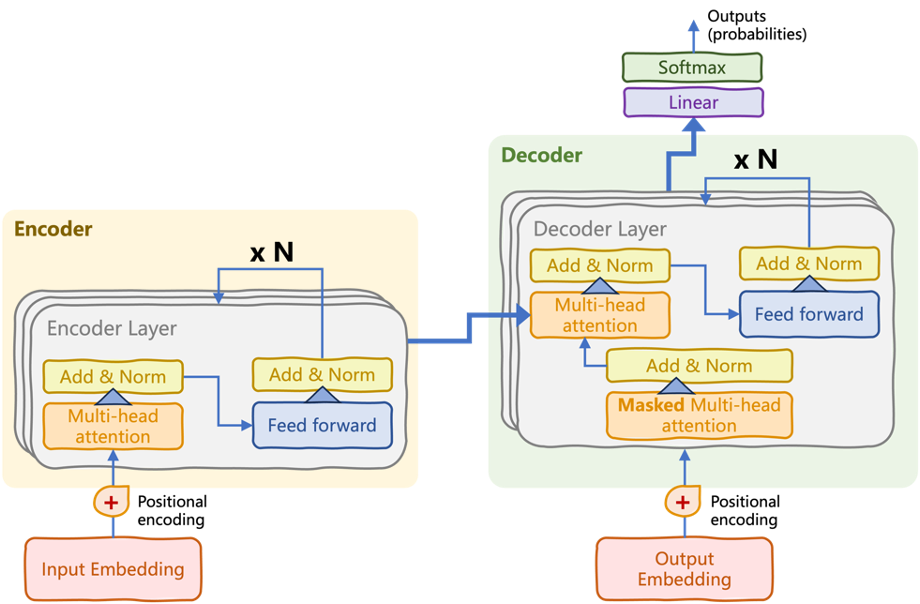
The original transformer architecture, divided into encoder and decoder stacks | Introduction to LLMs in Python (Iván Palomares)
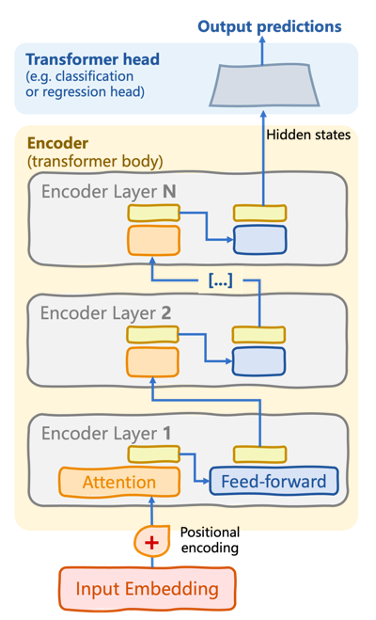
Encoder-only transformer architecture used by models like BERT | Introduction to LLMs in Python (Iván Palomares)
The encoder stack consists of multiple encoder layers (see the above diagram). Within each layer, there are (sub)layers of self-attention mechanisms and feedforward neural networks. The key to the language understanding process undertaken by BERT lies in the bidirectional attention flow iteratively applied within the encoder, such that dependencies between words in an input sequence are captured in both directions. Feedforward neural connections “tie together” these learned dependencies into more complex language patterns.
Besides this general characteristic of encoder-only transformers, BERT is characterized by incorporating a Masked Language Modelling (MLM) approach. This mechanism is used during pre-training to mask some words at random, thereby forcing the model to learn to predict masked words based on understanding the context surrounding them.
Let’s finish with the three questions you may be asked if applying for an advanced deep learning role.
The following combined strategy can be implemented to maximize deep learning model performance when faced with the common problem of limited training data:
Deploying deep learning solutions at scale in production settings demands paying attention to several considerations, three of which are:
Other important considerations for deploying deep learning models into production include hardware and network infrastructure, system monitoring, and seamless integration with existing software frameworks.
Recent deep-learning breakthroughs have the potential to reshape numerous industries profoundly and even create new ones.
Attention mechanisms used in the transformer architectures behind LLMs are revolutionizing the NLP field, significantly pushing the boundaries of NLP tasks and enabling more sophisticated human-machine interactions through conversational AI solutions, question-answering, and much more. The recent inclusion of Retrieval Augmented Generation (RAG) in the equation is further helping LLMs in producing truthful and evidence-based language.
Reinforcement learning is one of the most promising AI trends since its principles mimic the basics of how humans learn. Its integration with deep learning architectures, particularly generative models like generative adversarial networks, is at the forefront of scholarly research today. Big names like OpenAI, Google, and Microsoft, combine these two AI domains in their latest ground-breaking solutions capable of generating “real-like” content in multiple formats.
These and other recent advances have drastically democratized the use of AI by society, hence it is convenient to put the lens on AI ethics, legal aspects, and regulations as a key issue to work on to ensure a beneficial impact of deep learning solutions across society.
To conclude this exploration of common deep learning interview questions, one obvious observation is that the key to success hinges on a mix of theoretical foundations, a strong command of practical skills, and staying up to date with the latest advancements.
Deep learning isn’t just about algorithms, models, and architecture design choices. It’s about identifying the best solutions for solving real-world data problems.
And continuous learning is key. Datacamp offers a thorough Deep Learning in Python skills track as well as two deep learning application-oriented tracks: image processing and natural language processing. These tracks offer a structured roadmap to enhance your deep learning skills, ensuring readiness for your next interview.
Finally, check out the final sections of this article about machine learning interview questions if you are looking for general guidelines on how to prepare for your deep learning interview. Since deep learning is a subfield of machine learning, blending those general guidelines with the 20 deep learning questions we’ve reviewed here will surely help to prepare you.
Continue Your Deep Learning Journey Today!
Track
Course
Course
blog
Abid Ali Awan
15 min
blog
Vinod Chugani
15 min
blog
Abid Ali Awan
15 min
blog
Gus Frazer
12 min
blog
Laiba Siddiqui
15 min
blog
Hesam Sheikh Hassani
15 min

