
Track
Professional Data Engineer in Python
40 hr
Data scientists start learning about SQL early. That’s understandable, given the ubiquity and high usefulness of tabular information. However, there are other successful database formats, like graph databases, to store connected data that don’t fit into a relational SQL database. In this tutorial, we will learn about Neo4j, a popular graph database management system that you can use to create, manage, and query graph databases in Python.
Before talking about Neo4j, let’s take a moment to understand graph databases better. We have a full article explaining what graph databases are, so we’ll summarize the key points here.
Graph databases are a type of NoSQL database (they don’t use SQL) designed for managing connected data. Unlike traditional relational databases that use tables and rows, graph databases use graph structures that are made up of:
This structure makes graph databases ideal for handling interconnected data in fields and applications such as social networks, recommendations, fraud detection, etc., often outperforming relational DBs in terms of querying efficiency. Here is the structure of a sample graph database for a football dataset:
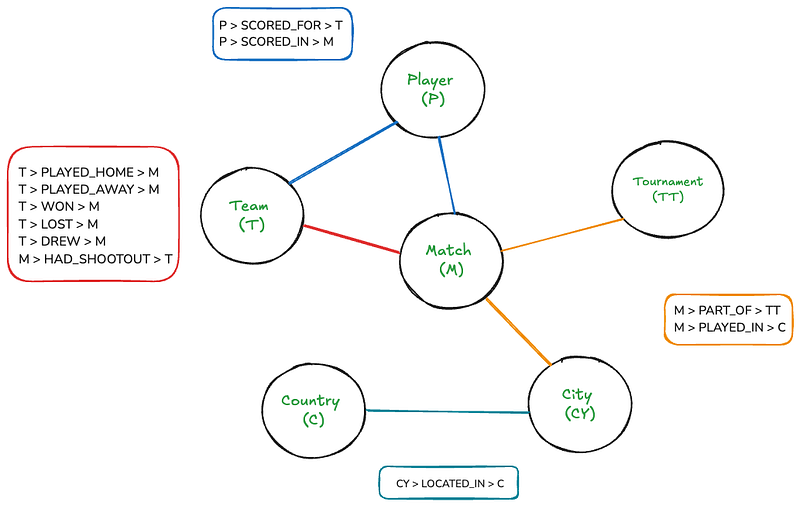
Even though this graph represents something fairly intuitive to humans, it can get pretty complicated if drawn on canvas. But, with Neo4j, traversing this graph will be as straightforward as writing simple SQL joins.
The graph has six nodes: Match, Team, Tournament, Player, Country, and City. The rectangles list the relationships that exist between nodes. There are also a few node and relationship properties:
This schema allows us to represent:
The schema captures the hierarchical nature of locations (City within Country) and the various relationships between entities (e.g., Teams playing Matches, Players scoring for Teams in Matches).
This structure allows for flexible querying, such as finding all matches between two teams, all goals scored by a player, or all matches in a specific tournament or location.
But let’s not get ahead of ourselves. For starters, what is Neo4j and why use it?
Neo4j, the leading name in the world of graph DB management, is known for its powerful features and versatility.
At its core, Neo4j uses native graph storage, which is highly optimized to carry out graph operations. Its efficiency in handling complex relations makes it outperform traditional databases for connected data. Neo4j’s scalability is truly impressive: it can handle billions of nodes and relationships with ease, making it suitable for both small projects and large enterprises.
Another key aspect of Neo4j is data integrity. It ensures full ACID (Atomicity, Consistency, Isolation, Durability) compliance, providing reliability and consistency in transactions.
Speaking of transactions, its query language, Cypher, offers a very intuitive and declarative syntax designed for graph patterns. For this reason, its syntax has been dubbed with the “ASCII art” nickname. Cypher will be no problem to learn, especially if you are familiar with SQL.
With Cypher, it is easy to add new nodes, relationships, or properties without worrying about breaking existing queries or schema. It is adaptable to the rapidly changing requirements of modern development environments.
Neo4j has a vibrant ecosystem support. It has extensive documentation, comprehensive tools to visualize graphs, active community and integrations with other programming languages such as Python, Java, and JavaScript.
Before we dive into working with Neo4j, we need to set up our environment. This section will guide you through creating a cloud instance to host Neo4j databases, setting up a Python environment, and establishing a connection between the two.
If you wish to work with local graph databases in Neo4j, then you would need to download and install it locally, along with its dependencies like Java. But in most cases, you will be interacting with an existing remote Neo4j database on some cloud environment.
For this reason, we won’t install Neo4j on our system. Instead, we will create a free database instance on Aura, Neo4j’s fully managed cloud service. Then, we will use the neo4j Python client library to connect to this database and populate it with data.
To host a free graph database on Aura DB, visit its product page and click on “Get Started for Free.”
Once you register, you will be presented with the available plans, and you should choose the free option. You will then be given a new instance with a username and password to connect to it:
Copy your password, username, and the connection URI.
Then, create a new working directory and a .env file to store your credentials:
$ mkdir neo4j_tutorial; cd neo4j_tutorial
$ touch .envPaste the following contents inside the file:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME"
NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD"
NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"Now, we will install the neo4j Python client library in a new Conda environment:
$ conda create -n neo4j_tutorial python=3.9 -y
$ conda activate neo4j_tutorial
$ pip install ipykernel # To add the environment to Jupyter
$ ipython kernel install --user --name=neo4j_tutorial
$ pip install neo4j python-dotenv tqdm pandasThe commands also install ipykernel library and use it to add the newly created Conda environment to Jupyter as a kernel. Then, we install the neo4j Python client to interact with Neo4j databases and python-dotenv to manage our Neo4j credentials securely.
Data ingestion into a graph database is a complicated process that requires knowledge of Cypher fundamentals. Since we have yet to learn about Cypher basics, you will use a Python script that I have prepared for the article that will automatically ingest real-world historical football data. The script will use the credentials you have stored to connect to your AuraDB instance.
The football data comes from this Kaggle dataset on international football matches played between 1872 and 2024. The data is available in a CSV format, so the script breaks it down and converts it into graph format using Cypher and Neo4j. Towards the end of the article, when we are comfortable enough with these technologies, we will go through the script line-by-line so you can understand how to convert tabular information into a graph.
Here are the commands to run (ensure you have set up the AuraDB instance and stored your credentials in a .env file in your working directory):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py
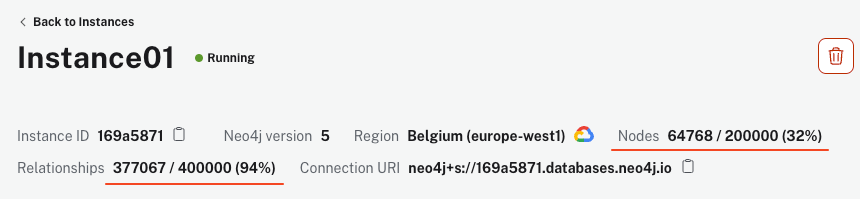
$ python ingest_football_data.pyThe script may take a few minutes to run, depending on your machine and Internet connection. However, once it finishes, your AuraDB instance must show over 64k nodes and 340k relationships.
Now, we are ready to connect to our Aura DB instance. First, we will read our credentials from the .env file using dotenv:
import os
from dotenv import load_dotenv
load_dotenv()
NEO4J_USERNAME = os.getenv("NEO4J_USERNAME")
NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD")
NEO4J_URI = os.getenv("NEO4J_URI")Now, let’s establish a connection:
from neo4j import GraphDatabase
uri = NEO4J_URI
username = NEO4J_USERNAME
password = NEO4J_PASSWORD
driver = GraphDatabase.driver(uri, auth=(username, password))
try:
driver.verify_connectivity()
print("Connection successful!")
except Exception as e:
print(f"Failed to connect to Neo4j: {e}")Output:
Connection successful!Here is an explanation of the code:
GraphDatabase from neo4j to interact with Neo4j.uri, username, password).GraphDatabase.driver(), establishing a connection to our Neo4j database.with block, we use the verify_connectivity() function to see if a connection is established. By default, verify_connectivity() returns nothing if a connection is successful.Once the tutorial finishes, call driver.close() to terminate the connection and free up resources. Driver objects are expensive to create, so you should only create a single object for your application.
Cypher’s syntax is designed to be intuitive and visually representative of graph structures. It relies on the following ASCII-art type of syntax:
(nodes)-[:CONNECT_TO]->(other_nodes)Let’s break down the key components of this general query pattern:
In a Cypher query, a keyword in parentheses signifies a node name. For example, (Player) matches all Player nodes. Almost always, node names are referred to with aliases to make queries more readable, easier to write, and compact. You can add an alias to a node name by putting a colon before it: (m:Match).
Inside the parentheses, you can specify one or more node properties for precise matching using dictionary-like syntax. For example:
// All tournament nodes that are FIFA World Cup
(t:Tournament {name: "FIFA World Cup"})Node properties are written as-is, while the value you want them to have must be a string.
Relationships connect nodes to each other, and they are wrapped with square brackets and arrows:
// Match nodes that are PART_OF some tournament
(m:Match)-[PART_OF]->(t:Tournament)You can add aliases and properties to relationships as well:
// Matches that Brazil participated in a penalty shootout and was the first shooter
(p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)Relationships are wrapped with arrows -[RELATIONSHIP]->. Again, you can include aliases properties inside braces. For example:
// All players who scored an own goal
(p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)Just like COUNT(*) FROM table_name would not return anything without a SELECT clause in SQL, (node) - [RELATIONSHIP] -> (node) wouldn't fetch any results. So, just like in SQL, Cypher has different clauses to structure your query logic like SQL:
MATCH: Pattern matching in the graphWHERE: Filtering the resultsRETURN: Specifying what to include in the result setCREATE: Creating new nodes or relationshipsMERGE: Creating unique nodes or relationshipsDELETE: Removing nodes, relationships, or propertiesSET: Updating labels and propertiesHere’s a sample query that demonstrates these concepts:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament)
WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True
RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute
ORDER BY s.minute DESC
LIMIT 5This query finds all players who scored own goals in World Cup matches after the 80th-minute mark. It reads almost like SQL, but its SQL equivalent involves at least one JOIN.
The Neo4j Python driver is the official library that interacts with a Neo4j instance through Python applications. It verifies and communicates Cypher queries written in plain Python strings with a Neo4j server and retrieves the results in a unified format.
It all starts by creating a driver object with the GraphDatabase class. From there, we can start sending queries using the execute_query method.
For our first query, let’s ask an interesting question : Which team won the most World Cup matches?
# Return the team that won the most number of World Cup matches
query = """
MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"})
RETURN t.name AS Team, COUNT(m) AS MatchesWon
ORDER BY MatchesWon DESC
LIMIT 1
"""
records, summary, keys = driver.execute_query(query, database_="neo4j")First, let’s break down the query:
MATCH close defines the pattern we want: Team -> Wins -> Match -> Part of -> TournamentRETURN is the equivalent of SQL's SELECT statement, where we can return the properties of returned nodes and relationships. In this clause, you can also use any supported aggregation function in Cypher. Above, we are using COUNT.ORDER BY clause works in the same manner as SQL's.LIMIT is used to control the length of the returned records.After we define the query as a multi-line string, we pass it to the execute_query() method of the driver object and specify the database name (the default is neo4j). The output always contains three objects:
records: A list of Record objects, each representing a row in the result set. Each Record is a named tuple-like object where you can access fields by name or index.summary: A ResultSummary object containing metadata about the query execution, such as query statistics and timing information.keys: A list of strings representing the column names in the result set.We will touch on the summary object later because we are mostly interested in records, which contain Record objects. We can retrieve their info by calling their data() method:
for record in records:
print(record.data())Output:
{'Team': 'Brazil', 'MatchesWon': 76}The result correctly shows that Brazil has won the most World Cup matches.
Our last query isn’t reusable, as it only finds the most successful team in World Cup history. What if we want to find the most successful team in Euro history?
This is where query parameters come in:
query = """
MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament})
RETURN t.name AS Team, COUNT(m) AS MatchesWon
ORDER BY MatchesWon DESC
LIMIT $limit
"""In this version of the query, we introduce two parameters using the $ sign:
tournamentlimitTo pass values to the query parameters, we use keyword arguments inside execute_query:
records, summary, keys = driver.execute_query(
query, database_="neo4j", tournament="UEFA Euro", limit=3,
)
for record in records:
print(record.data())Output:
{'Team': 'Germany', 'MatchesWon': 30}
{'Team': 'Spain', 'MatchesWon': 28}
{'Team': 'Netherlands', 'MatchesWon': 23}It is always recommended to use query parameters whenever you are thinking of ingesting changing values into your query. This best practice protects your queries from Cypher injections and enables Neo4j to cache them.
Writing new information to an existing database is similarly done with execute_query but by using a CREATE clause in the query. For example, let's create a function that will add a new node type - team coaches:
def add_new_coach(driver, coach_name, team_name, start_date, end_date):
query = """
MATCH (t:Team {name: $team_name})
CREATE (c:Coach {name: $coach_name})
CREATE (c)-[r:COACHES]->(t)
SET r.start_date = $start_date
SET r.end_date = $end_date
"""
result = driver.execute_query(
query,
database_="neo4j",
coach_name=coach_name,
team_name=team_name,
start_date=start_date,
end_date=end_date
)
summary = result.summary
print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}")
print(f"Nodes created: {summary.counters.nodes_created}")
print(f"Relationships created: {summary.counters.relationships_created}")The function add_new_coach takes five parameters:
coach_name: The name of the new coach to be added.team_name: The name of the team the coach will be associated with.start_date: The date when the coach starts coaching the team.end_date: The date when the coach's tenure with the team ends.The Cypher query in the function does the following:
start_date and end_date properties on the COACHES relationship.The query is executed using the execute_query method, which takes the query string and a dictionary of parameters.
After execution, the function prints:
COACHES relationship).Let’s run it for one of the most successful coaches in international football history, Lionel Scaloni, who won three consecutive major international tournaments (World Cup and two Copa Americas):
from neo4j.time import DateTime
add_new_coach(
driver=driver,
coach_name="Lionel Scaloni",
team_name="Argentina",
start_date=DateTime(2018, 6, 1),
end_date=None
)Output:
Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000
Nodes created: 1
Relationships created: 1In the above snippet, we are using the DateTime class from neo4j.time module to pass a date correctly into our Cypher query. The module contains other useful temporal data types you may want to check out.
Apart from CREATE, there is also the MERGE clause for creating new nodes and relationships. Their key difference is:
CREATE always creates new nodes/relationships, potentially leading to duplicates.MERGE only creates nodes/relationships if they don't already exist.For example, in our data ingestion script, as you will see later:
MERGE for teams and players to avoid duplicates.CREATE for SCORED_FOR and SCORED_IN relationships because a player can score multiple times in a single match.This approach ensures data integrity while allowing for multiple similar but distinct relationships.
When you run execute_query, the driver creates a transaction under the hood. A transaction is a unit of work that is either executed in its entirety or rolled back as a failure. This means that when you are creating thousands of nodes or relationships in a single transaction (it is possible) and some error is encountered in the middle, the entire transaction fails without writing any new data to the graph.
To have finer control over each transaction, you need to create session objects. For example, let’s create a function to find the top K goal scores in a given tournament using a session object:
def top_goal_scorers(tx, tournament, limit):
query = """
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament)
WHERE t.name = $tournament
RETURN p.name AS Player, COUNT(s) AS Goals
ORDER BY Goals DESC
LIMIT $limit
"""
result = tx.run(query, tournament=tournament, limit=limit)
return [record.data() for record in result]First, we create top_goal_scorers function that accepts three parameters, the most important one being the tx transaction object that will be obtained using a session object.
with driver.session() as session:
result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5)
for record in result:
print(record)Output:
{'Player': 'Miroslav Klose', 'Goals': 16}
{'Player': 'Ronaldo', 'Goals': 15}
{'Player': 'Gerd Müller', 'Goals': 14}
{'Player': 'Just Fontaine', 'Goals': 13}
{'Player': 'Lionel Messi', 'Goals': 13}Then, under a context manager created with the session() method, we use execute_read(), passing the top_goal_scorers() function, along with any parameters the query requires.
The output of execute_read is a list of Record objects that correctly show the top 5 goal scorers in World Cup history, including names like Miroslav Klose, Ronaldo Nazario, and Lionel Messi.
The counterpart of execute_read() for data ingestion is execute_write().
With that said, let’s now look at the ingestion script we used earlier to get a feel for how data ingestion works with the Neo4j Python driver.
The ingest_football_data.py file starts with import statements and loading the necessary CSV files:
import pandas as pd
import neo4j
from dotenv import load_dotenv
import os
from tqdm import tqdm
import logging
# CSV file paths
results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv"
goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv"
shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv"
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.info("Loading data...")
# Load data
results_df = pd.read_csv(results_csv_path, parse_dates=["date"])
goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"])
shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])This code block also sets up a logger. The next few lines of code read my Neo4j credentials using dotenv and creates a Driver object:
uri = os.getenv("NEO4J_URI")
user = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
try:
driver = neo4j.GraphDatabase.driver(uri, auth=(user, password))
print("Connected to Neo4j instance successfully!")
except Exception as e:
print(f"Failed to connect to Neo4j: {e}")
BATCH_SIZE = 5000Since there are more than 48k matches in our database, we define a BATCH_SIZE parameter to ingest data in smaller samples.
Then, we define a function called create_indexes that accepts a session object:
def create_indexes(session):
indexes = [
"CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)",
"CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)",
"CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)",
"CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)",
"CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)",
"CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)",
]
for index in indexes:
session.run(index)
print("Indexes created.")Cypher indexes are database structures that improve query performance in Neo4j. They speed up the process of finding nodes or relationships based on specific properties. We need them for:
In our case, indexes on team names, match IDs, and player names will help our queries run faster when searching for specific entities or performing joins across different node types. It is a best practice to create such indexes for your own databases.
Next, we have the ingest_matches function. It is large, so let's break it down block by block:
def ingest_matches(session, df):
query = """
UNWIND $batch AS row
MERGE (m:Match {id: row.id})
SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral
MERGE (home:Team {name: row.home_team})
MERGE (away:Team {name: row.away_team})
MERGE (t:Tournament {name: row.tournament})
MERGE (c:City {name: row.city})
MERGE (country:Country {name: row.country})
MERGE (home)-[:PLAYED_HOME]->(m)
MERGE (away)-[:PLAYED_AWAY]->(m)
MERGE (m)-[:PART_OF]->(t)
MERGE (m)-[:PLAYED_IN]->(c)
MERGE (c)-[:LOCATED_IN]->(country)
WITH m, home, away, row.home_score AS hs, row.away_score AS as
FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END |
MERGE (home)-[:WON]->(m)
MERGE (away)-[:LOST]->(m)
)
FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END |
MERGE (away)-[:WON]->(m)
MERGE (home)-[:LOST]->(m)
)
FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END |
MERGE (home)-[:DREW]->(m)
MERGE (away)-[:DREW]->(m)
)
"""
...The first thing you will notice is the UNWIND keyword, which is used to process a batch of data. It takes the $batch parameter (which will be our DataFrame rows) and iterates over each row, allowing us to create or update multiple nodes and relationships in a single transaction. This approach is more efficient than processing each row individually, especially for large datasets.
The rest of the query is familiar since it uses multiple MERGE clauses. Then, we reach the WITH clause, which uses FOREACH constructs with IN CASE statements. These are used to conditionally create relationships based on the match outcome. If the home team wins, it creates a 'WON' relationship for the home team and a 'LOST' relationship for the away team, and vice versa. In case of a draw, both teams get a 'DREW' relationship with the match.
The rest of the function divides the incoming DataFrame into matches and constructs the data that will be passed to the $batch query parameter:
def ingest_matches(session, df):
query = """..."""
for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"):
batch = df.iloc[i : i + BATCH_SIZE]
data = []
for _, row in batch.iterrows():
match_data = {
"id": f"{row['date']}_{row['home_team']}_{row['away_team']}",
"date": row["date"].strftime("%Y-%m-%d"),
"home_score": int(row["home_score"]),
"away_score": int(row["away_score"]),
"neutral": bool(row["neutral"]),
"home_team": row["home_team"],
"away_team": row["away_team"],
"tournament": row["tournament"],
"city": row["city"],
"country": row["country"],
}
data.append(match_data)
session.run(query, batch=data)ingest_goals and ingest_shootouts functions use similar constructs. However, ingest_goals have some additional error and missing value handling.
At the end of the script, we have the main() function that executes all our ingestion functions with a session object:
def main():
with driver.session() as session:
create_indexes(session)
ingest_matches(session, results_df)
ingest_goals(session, goalscorers_df)
ingest_shootouts(session, shootouts_df)
print("Data ingestion completed!")
driver.close()
if __name__ == "__main__":
main()We’ve covered key aspects of working with Neo4j graph databases using Python:
To further your Neo4j journey, explore these resources:
Remember, the power of graph databases lies in representing and querying complex relationships. Keep experimenting with different data models and exploring advanced Cypher features.
Top DataCamp Courses
Track
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Sejal Jaiswal
Tutorial
Dr Ana Rojo-Echeburúa

