
Course
Generative AI Concepts
2 hr
105.1K
Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members of Google Research.
The model, which Google refers to as the most capable and general-purpose AI they’ve developed thus far, was designed to be multimodal. This means Gemini can comprehend various data types such as text, audio, images, video, and code.
For the remainder of this article, we’re going to cover:
On December 6, 2023, Google DeepMind announced Gemini 1.0. Upon release, Google described it as their most advanced set of Large Language Models (LLMs), thus superseding the Pathways Langauge Model (PaLM 2), which debuted in May of the same year.
Gemini defines a family of multimodal LLMs capable of understanding texts, images, videos, and audio. It’s also said to be capable of performing complex tasks in math and physics, as well as being able to generate high-quality code in several programming languages.
Fun fact: Sergey Brin, Google’s co-founder, is credited as one of the contributors to the Gemini model.
Until recently, the standard procedure for developing multimodal models consisted of training individual components for various modalities and then piecing them together to mimic some of the functionality. Such models would occasionally excel at performing certain tasks, like describing images, but they have trouble with more sophisticated and complex reasoning.
Gemini was designed to be natively multimodal; thus, it was pre-trained on several modalities from the beginning. To further refine its efficacy, Google fine-tuned it with additional multimodal data.
Consequently, Gemini is significantly more capable than existing multimodal models in understanding and reasoning about a wide range of inputs from the ground up, according to Sundar Pichai, the CEO of Google and Alphabet, and Demis Hassabis, CEO and Co-Found of Google DeepMind. They also state that Gemini’s capabilities are “state of the art in nearly every domain.”
The key features of the Gemini model include:
Multimodal AI is a new AI paradigm gaining traction in which different data types are merged with multiple algorithms to achieve a higher performance. Gemini leverages this paradigm, meaning it integrates well with various data types. You can input images, audio, text, and other data types, resulting in more natural AI interactions.
Gemini leverages Google’s TPUv5 chips, thus reportedly making it five times stronger than GPT-4. Faster processing makes Gemini capable of tackling complex tasks relatively easily and handling multiple requests simultaneously.
Gemini was trained on an enormous dataset of text and code. This ensures the model can access the most up-to-date information and provide accurate and reliable responses to your queries. According to Google, the model outperforms OpenAI’s GPT-4 and “expert level” humans in various intelligence tests (e.g., MMLU benchmark).
Gemini 1.0 can understand, explain, and generate high-quality code in the most widely used programming languages, such as Python, Java, C++, and Go – this makes it one of the leading foundation models for coding globally.
The model also excels in several coding benchmarks, including HumanEval, a highly-regarded industry standard for evaluating performance on coding tasks; it also performed well on Google’s internal, held-out dataset, which leverages author-generated code instead of information from the web.
New protections were added to Google’s AI Principles and policies to account for Gemini’s multimodal capabilities. Google says, “Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity.” They also said they’ve “conducted novel research into potential risk areas like cyber-offense, persuasion, and autonomy, and have applied Google Research’s best-in-class adversarial testing techniques to help identify critical safety issues in advance of Gemini’s deployment.”
Google says Gemini, the successor to LaMDA and PaLM 2, is their “most flexible model yet — able to efficiently run on everything from data centers to mobile devices.” They also believe Gemini’s state-of-the-art capabilities will improve how developers and business clients build and scale with AI.
The first version of Gemini, unsurprisingly named Gemini 1.0, was released in three different sizes:
Since December 13, 2023, developers and enterprise customers have been able to access Gemini Pro through Gemini’s API in Google AI Studio or Google Cloud Vertex AI.
Note Google AI Studio is a freely available browser-based IDE that developers can use to prototype generative models and easily launch applications using an API key. Google Cloud Vertex, on the other hand, is a fully managed AI platform that offers all of the tools required to build and use generative AI. According to Google, “Vertex AI allows customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.”
Through AICore, a new system feature with Android 14, Android developers, starting from Pixel 8 Pro devices, can build with Gemini Nano, the most efficient model for on-device tasks.
The Gemini models underwent extensive testing to assess their performance across a broad range of tasks before their release. Google says its Gemini Ultra model outperforms the existing state-of-the-art results on 30 of the 32 commonly used academic benchmarks for Large Language Model (LLM) research and development. Note these tasks range from natural image, audio, and video understanding to mathematical reasoning.
In an Gemini introductory blog post, Google claims Gemini Ultra is the first-ever model to outperform human experts on Massive Multitask Language Understanding (MMLU) with a score of 90.0%. Note that MMLU incorporates 57 different subjects, including math, physics, history, law, medicine, and ethics, to assess one’s ability to solve problems and a general understanding of the world.
The new MMLU benchmark method to MMLU enables Gemini to make significant improvements instead of merely leveraging its first impressions by using its reasoning power to deliberate more thoroughly before responding to challenging questions.
Here’s how Gemini performed on text tasks:
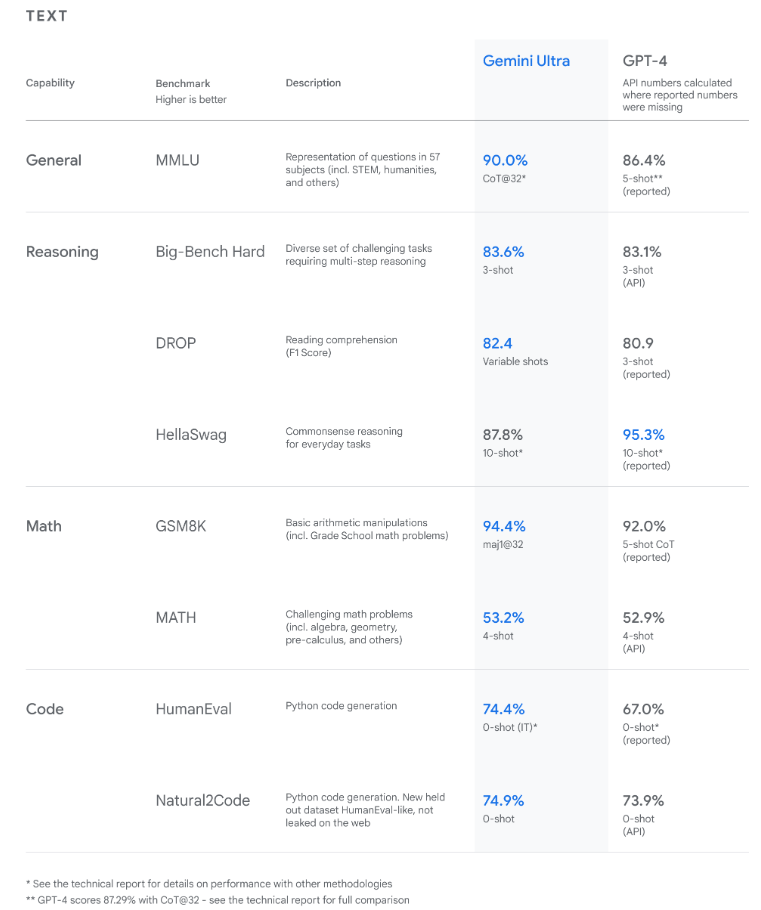
The findings reveal Gemini surpasses state-of-the-art performance on a wide range of benchmarks, including text and coding. [Source]
The Gemini Ultra model also achieved state-of-the-art on the new Massive Multidiscipline Multimodal Understanding (MMMU) benchmark with a score of 59.4%. This assessment consists of multimodal tasks across various domains requiring deliberate reasoning.
Google said, “With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models without assistance from optical character recognition (OCR) systems that extract text from images for further processing.”
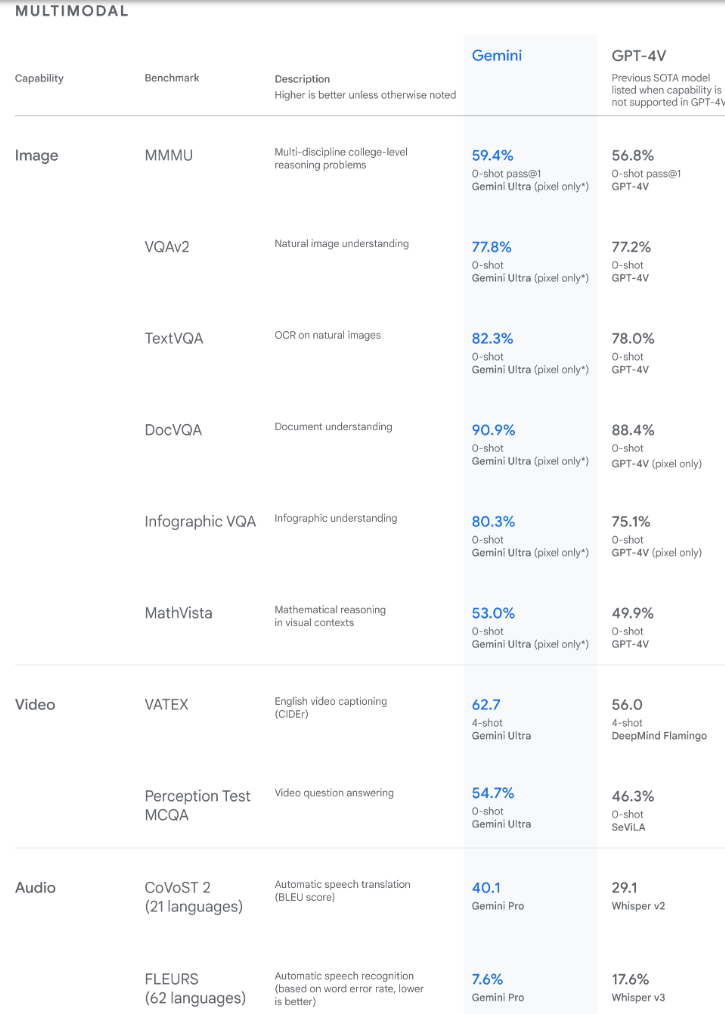
The findings reveal Gemini also surpasses state-of-the-art performance on a wide range of multimodal benchmarks. [Source]
The benchmarks set by Gemini demonstrate the model's innate multimodality and show early evidence of its capacity for more sophisticated reasoning.
The obvious question that typically arises next is, “How does Gemini compare to GPT-4?”
Both models have similar feature sets and can interact with and interpret text, image, video, audio, and code data, enabling users to apply them to various tasks.
Users of both tools have the option to fact-check, but how they go about providing this functionality is different. Where OpenAI’s GPT-4 provides source links for the claims it makes, Gemini enables users to perform a Google search to confirm the response by clicking a button.
It’s also possible to augment both models with additional extensions, although, at the time of writing, Google’s Gemini model is much more limited.
For example, it’s possible to utilize Google tools such as flights, maps, YouTube, and their range of Workspace applications with Gemini. In contrast, there’s a far larger selection of plug-ins and extensions available for OpenAI's GPT-4, of which most are created by third parties. On-the-fly image creation is also possible with GPT-4; Gemini is designed to be capable of such functionality, but, at the time of writing, it cannot.
On the other hand, Gemini’s response times are faster than that of GPT-4, which can occasionally be slowed down or entirely interrupted due to the sheer volume of users on the platform.
Google’s Gemini models can perform various tasks across several modalities, such as text, audio, image, and video comprehension.
Combining different modalities to understand and generate output is also possible due to Gemini’s multimodal nature.
Examples of use cases for Gemini include:
Gemini models can summarize content from various data types. According to a research paper titled GEMINI: Controlling The Sentence-Level Summary Style in Abstractive Text Summarization, the Gemini model “integrates rewrites and a generator to mimic sentence rewriting and abstracting techniques, respectively.”
Namely, Gemini adaptively selects whether to rewrite a specific document sentence or generate a summary sentence entirely from scratch. The findings of the experiments revealed that the approach used by Gemini outperformed the pure abstractive and rewriting baselines on three benchmark datasets, achieving the best results on WikiHow.
Gemini can generate text-based input in response to a user prompt - this text can also be driven by a Q&A-style chatbot interface. Thus, Gemini can be deployed to handle customer inquiries and offer assistance in a natural yet engaging manner, which can free up the responsibilities of human agents to apply themselves more to complex tasks and improve customer satisfaction.
It may also be used for creative writing, such as co-authoring a novel, writing poetry in various styles, or generating scripts for movies and plays. This can significantly boost the productivity of creative writers and reduce the tension caused by writer's block.
With their broad multilingual capabilities, the Gemini models can understand and translate over 100 different languages. According to Google, Gemini surpasses Chat GPT-4V’s state-of-the-art performance “on a range of multimodal benchmarks,” such as automatic speech recognition (ASR) and automatic speech translation.
Gemini can understand and interpret images, making it suitable for image captioning and visual Q&A use cases. The model can also parse complex visuals, including diagrams, figures, and charts, without requiring external OCR tools.
Developers can use Gemini to solve complex coding tasks and debug their code. The model is capable of understanding, explaining, and generating in the most used programming languages, such as Python, Java, C++, and Go.
Google’s new set of multimodal Large Language Models (LLMs), Gemini, is the successor to LaMDA and PaLM 2. They describe it as their most advanced set of LLMs capable of understanding texts, images, videos, audio, and complex tasks like math and physics. Gemini is also capable of generating high-quality code in many of the most popular programming languages.
The model has achieved state-of-the-art capability in various tasks, and many at Google believe it represents a significant leap forward in how AI can help improve our daily lives.
Continue your learning with the following resources:
And before you go, don't forget to subscribe to our YouTube channel. We have great content for all the most relevant and trending topics, including a tutorial on how to build multimodal apps with Gemini, so do have a look.
Start Your AI Journey Today!
Course
Course
Course
blog
James Chapman
7 min
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
14 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
François Aubry


