Successful data science projects require collaboration across teams. Data science projects are not impactful without proper alignment with all relevant stakeholders. In a recent DataCamp webinar, Brian Campbell, Engineering Manager, Internal Engineering at Lucid Software, discusses the best practices for cross-team collaboration on data science projects.
Three Types of Collaborators
Data scientists must collaborate with other stakeholders to drive impact with their projects. Data scientists should rely on others within their organization to better understand the business value and metrics underlying the problems they are interested in, how to navigate complex data environments, and how to deploy their models to customers. In the webinar, Brian discusses three types of collaborators:
Problem Expert
The problem expert is the collaborator who sets the foundation for a data science project. Their job is to provide domain expertise for a project and to define the problem statement.
Problem experts intimately understand the metrics impacted by a data science project and how they translate to business outcomes. They also know the accuracy needed for a model to be valuable. This knowledge is critical information because no model can be perfectly accurate. Understanding what is reasonable and valuable to aim for is essential to defining goals and setting expectations early in a project.
Data Expert
Data is the key ingredient for any successful data science project. Many organizations have complex data landscapes that make it challenging to know what data is available and what data is needed to solve a problem.
Data experts are in charge of knowing what data is available in a domain, how to get the data, and what data is best suited for specific business questions. They can sometimes be the problem expert themselves but are typically in data engineering roles within the organization.
Implementation Experts
Finally, implementation experts are in charge of understanding how to deploy these models to customers. They are experts in the infrastructure and resources required to deploy models at scale.
When collaborating with these experts, it's important to let them know well in advance about the project so that they have time to ensure there is proper infrastructure in place when the model is ready to be deployed. It’s also important to know how the work will be used—as a feature in the product, part of an API, integrated with an existing process, or requiring a new process from scratch. The project's use will determine who the best implementation expert to collaborate with will be.

How to Effectively Work With Collaborators
Timelines are a critical component of collaboration. These allow everyone involved in the project to plan when they will get involved to help advance it to completion.
Consider a proposed project to deploy a customer retention model. This model will identify customers who are at risk of no longer purchasing a subscription from the organization and will send a promotional email to them to entice them to stay.
This project will require initially understanding customer retention metrics and trends, collecting relevant data, cleaning and analyzing the data, building the classification model, integrating it into the automated email system, and setting it live. All of these steps could take weeks and many steps will require help from the three stakeholders discussed in the previous section.
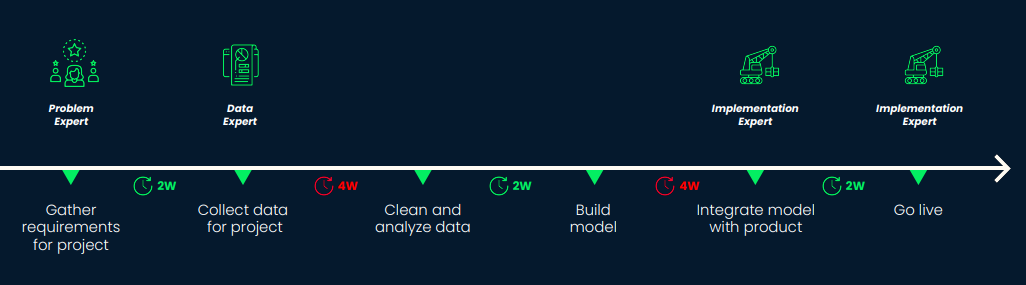
Setting an initial timeline allows collaborators to roadmap when they need to be available to help with the project. If delays occur, partners should be informed immediately. Implementation experts should not show up a month early if there is a delay in the data collection phase as this will waste their time and hurt opportunities for future collaborations with them.
To learn more about data science project management best practices, tune in to the on-demand webinar for more in-depth examples.
