To stay competitive, insurance organizations must scale the number of insights and value they produce from their data. In the second half of this recent webinar, Sudaman Thoppan Mohanchandralal, Regional Chief Data and Analytics Officer at Allianz Benelux, discusses the key steps insurance organizations must take to fully realize data science's potential.
From Data Science Garage to Factory
In the webinar, Sudaman describes the current utilization of data science in the insurance industry as an analytics garage. Organizations currently recognize that big data is a priority, but they are not efficiently leveraging it across all decisions.
IBM reports that while 71% of insurers have products that rely on data in their portfolios, many do not have a cohesive data strategy to scale data science and machine learning. Sudaman likens the end-goal organizations should be striving for to an analytics factory. Here, organizations leverage data at scale across all decisions allowing for three key benefits:
- Massive financial potential: A lot of opportunities to scale the core business through machine learning use cases.
- Advantages over new competitors entering the market: Making data-driven decisions is necessary to compete with new competitors with disruptive data and analytics-driven business models.
- New possibilities to extend the core business: By making smarter decisions for the core business, resources open up to expand into new business models outside of today’s core. Some of these next-generation services are described by Capgemini here.
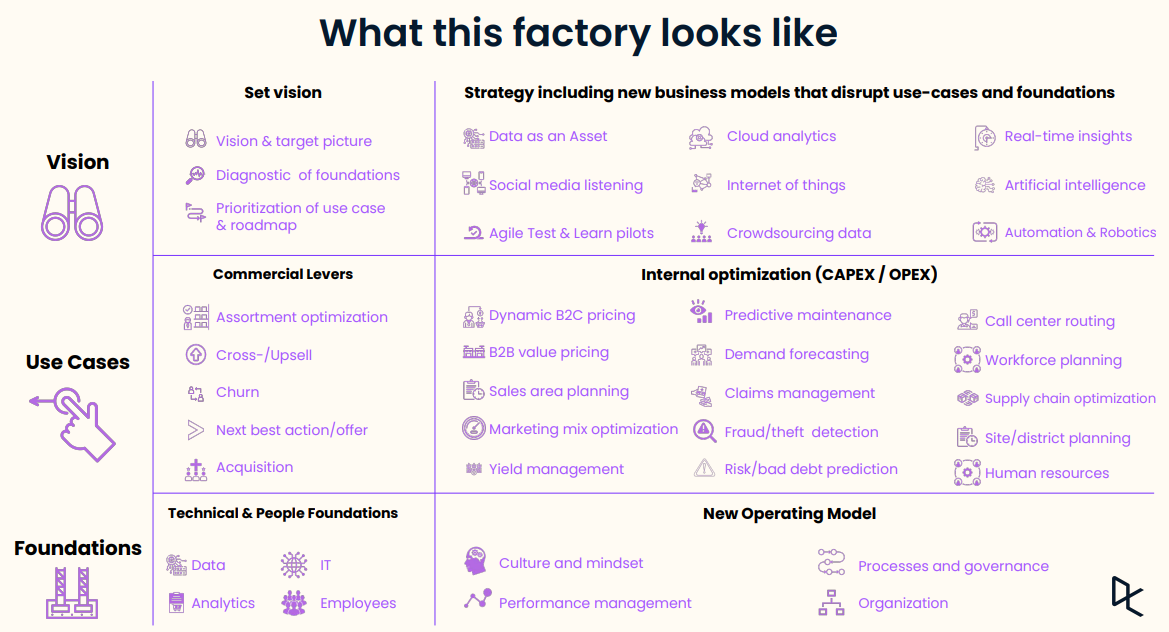
However, clear obstacles are currently present stopping insurers from scaling analytics factories. Here are a few of them listed in the webinar

Obstacle #1: Unclear Governance
The first step to reaching an analytics factory is clear governance. In this webinar, Aaren Stubberfield, Manager of Data Governance and AI at Ingredion Inc., describes how data governance minimizes business risk from data privacy laws by providing clarity about data. This clarity also allows for more confidence in decisions made based on this data. McKinsey argues that upwards of over 30% of employees' time is wasted in some departments on non-value-added tasks when data quality and availability are poor due to a lack of governance. Clear governance is essential to creating a data science factory.
Obstacle #2: Shortage of Key Talent
The next step is developing data science talent within an organization. These skills can be broken down into three main roles:
- Data Scientist: Require a background in applied mathematics and technical skills in areas like data mining, statistics, machine learning, and computer science. Their main job is to build algorithms for valuable use cases.
- Analytics Engineer: Typically have a background in data science with more of an emphasis on computer science and programming skills. Their role is to use the data scientist’s algorithms and make them scalable for production environments.
- Analytics Translator: Have backgrounds in data science and business. Their function is to translate business problems into technical language and to translate model outputs into business solutions.
Developing these skills at scale can be challenging with the data talent shortage. Thus, organizations must look to upskill internally by creating a learning culture. These roles are all necessary for reaching a data science factory.
Once these roles are filled, projects with quick wins can be chosen to prove the potential of the factory. These quick wins can then be systematized and scaled to productionize the analytics process with full-stack data products. These benefits all come from building the right team and addressing the talent shortage internally.
Obstacle #3: Lack of Frontline Involvement
The third step is involving frontline workers. Everyone in the organization must be data literate. Employees who work close to the customers need to understand the systems being deployed. They must be able to communicate why they are recommending a specific service for the customer or why services are priced the way that they are. Effective communication with customers, which is essential for building an analytics factory, comes from frontline involvement. This is where building a data culture comes into play—which was covered by Sudaman in another DataCamp webinar.
Obstacle #4: Management Attention
Finally, management must be involved for the factory to work. They must work intimately with the data talent to drive organizational change. They should leverage their business knowledge and expertise to drive financial impact and value to the organization from the new technology that is developed from the data teams. Without proper attention from those making decisions, the benefits from the factory cannot be realized.
To learn more about how insurers can scale their analytics garages to factories, make sure to tune in to the on-demand webinar.
