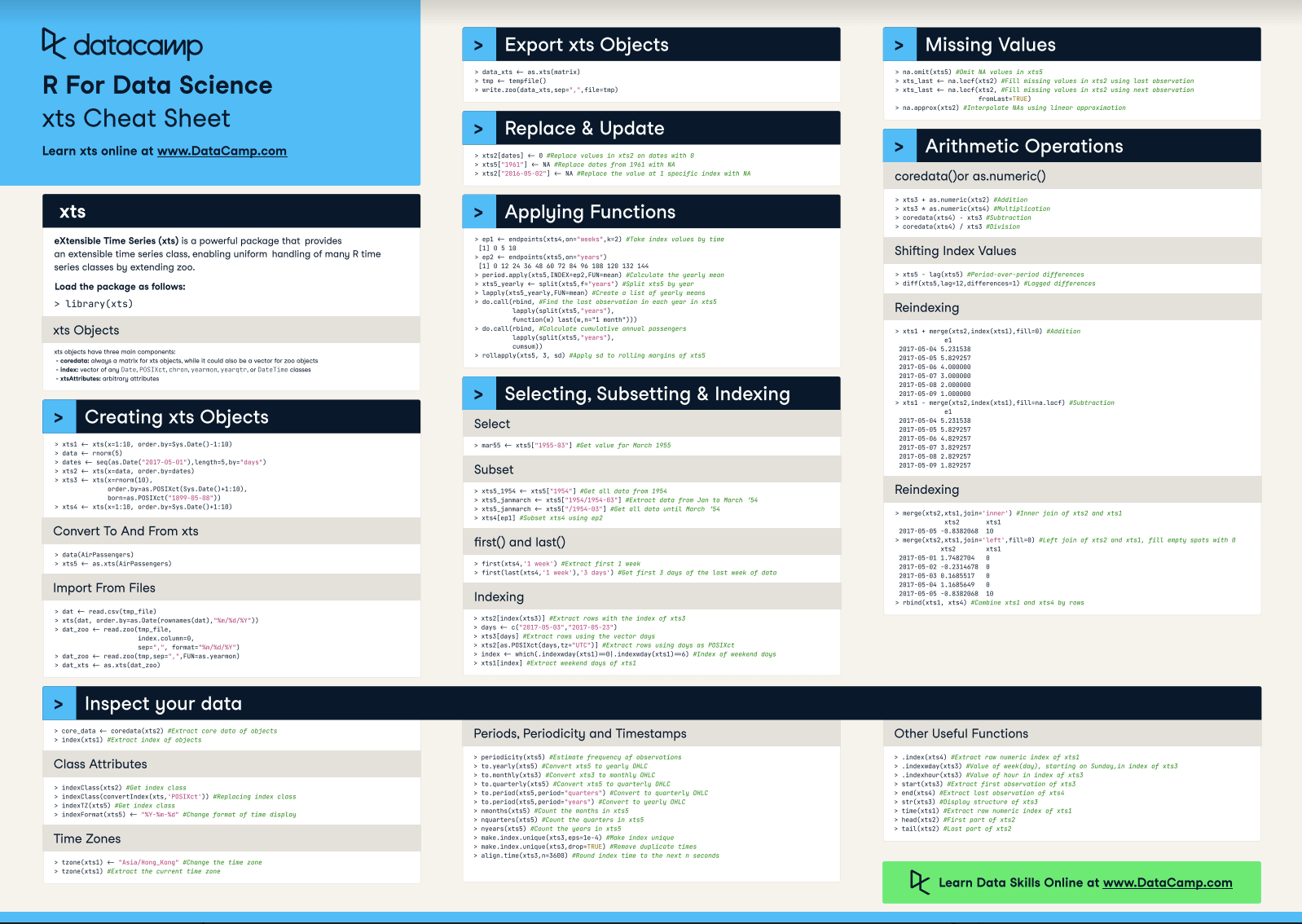
Even though the data.frame object is one of the core objects to hold data in R, you'll find that it's not really efficient when you're working with time series data. You'll find yourself wanting a more flexible time series class in R that offers a variety of methods to manipulate your data.
xts or the Extensible Time Series is one of such packages that offers such a time series object. It's a powerful R package that provides an extensible time series class, enabling uniform handling of many R time series classes by extending zoo, which is the package that is the creator for an S3 class of indexed totally ordered observations which includes irregular time series.
xts has a lot to offer to make your time series analysis fast and mistake free, but it can take some time to get used to it.
This xts cheat sheet provides you not only with an overview of the xts object, how to create and inspect them, but also goes deeper into how you can manipulate time series with xts: you'll see how to replace and update values, how to select, index and subset your objects, how to handle missing values and how to perform arithmetic operations.
Click on the button below to see (and download) the xts cheat sheet:
Have this cheat sheet at your fingertips
Download PDF

