
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Wir haben zahlreiche Anleitungen zur Feinabstimmung großer Sprachmodelle (LLMs) erkundet, aber es gibt nur sehr wenige Ressourcen, die den Prozess der Feinabstimmung multimodaler Modelle abdecken. In diesem Tutorial werden wir ein hochmodernes multimodales Modell namens Llama 3.2 Vision Model erkunden und zeigen, wie wir es anhand des Amazon-Produktdatensatzes feinabstimmen können. Unser Ziel ist es, einen Generator für Produktbeschreibungen zu entwickeln, der genaue und vereinfachte Bildunterschriften für auf Amazon gelistete Produkte liefert.
Wenn du neu in der Feinabstimmung von LLMs bist, nimm bitte die Feinabstimmung mit Llama 3 Kurs, um dich mit den gängigen Methoden und Begriffen vertraut zu machen. Du kannst dir auch unser Llama 3.2 90B-Tutorial ansehen: . Darin erfährst du, wie du mit Streamlit für das Frontend, Llama 3.2 90B für die Erzeugung von Bildunterschriften und Groq als API eine App für Bildunterschriften erstellst.

Bild vom Autor
Llama 3.2 führt multimodale Modelle ein, die sowohl Bild- als auch Textdaten verarbeiten können, um natürliche und genaue Antworten zu erzeugen. Die Llama 3.2-Vision-Modelle sind in 11B- und 90B-Parameter-Varianten erhältlich und wurden speziell dafür entwickelt, Image Reasoning-Anwendungsfälle mit bemerkenswerter Präzision zu bewältigen. Diese Modelle übertreffen viele bestehende Open-Source- und geschlossene multimodale Modelle bei branchenüblichen Benchmarks.
Lies das Llama 3.2 Handbuch: Funktionsweise, Anwendungsfälle und mehr, um mehr über alle Modellvariablen im Detail zu erfahren.
Die Bildverarbeitungsmodelle von Llama 3.2 eignen sich hervorragend für Aufgaben wie das Verstehen von Dokumenten, die Analyse von Diagrammen und Grafiken, die Beschriftung von Bildern und das visuelle Grounding, bei dem natürlichsprachliche Beschreibungen verwendet werden, um Objekte in Bildern zu identifizieren.
Das Llama 3.2 Vision Modell baut auf dem älteren Llama 3.1 Textmodell auf, das ein fortschrittliches Sprachmodell mit einer Transformatorarchitektur ist. Sie wurde mit überwachtem Lernen (SFT) und Verstärkungslernen mit menschlichem Feedback (RLHF) feinabgestimmt, um den menschlichen Präferenzen für Hilfsbereitschaft und Sicherheit zu entsprechen.
Um die Bilderkennung zu erleichtern, enthält Llama 3.2 Vision einen separat trainierten Vision Adapter. Dieser Adapter verwendet Cross-Attention-Schichten, um die Ausgaben des Bildkodierers in das vortrainierte Llama 3.1-Sprachmodell zu integrieren, damit es sowohl text- als auch bildbasierte Aufgaben effektiv bearbeiten kann.
Llama 3.2 Vision eignet sich hervorragend für Anwendungsfälle wie visuelle Fragebeantwortung, Dokumentenanalyse, Bildunterschriften, Bild-Text-Retrieval und visuelles Grounding.
Für dieses Projekt werden wir Kaggle als Programmier- und Berechnungsumgebung, Unsloth als Feinabstimmungs-Framework und den Amazon-Produktbeschreibungsdatensatz verwenden. Unsloth ist schnell, verbraucht weniger GPU-Speicher und benötigt im Vergleich zu herkömmlichen Methoden weniger Codezeilen.
Wenn du die LLMs für eine Lösung zur Texterstellung verfeinern willst, haben wir das perfekte Tutorial für dich: Llama 3.2 feinjustieren und lokal nutzen: Eine Schritt-für-Schritt-Anleitung.
Erstelle ein neues Kaggle-Notebook und stelle den Beschleuniger so ein, dass er zwei T4-GPUs verwendet. Füge deinen Hugging Face Token als Kaggle-Geheimnis hinzu, damit du dein Modell später sicher in dein Hugging Face-Repository übertragen kannst. Installiere dann das Python-Paket unsloth mit dem Befehl pip.
%%capture
!pip install unslothEntdecke mehr über Unsloth, indem du den Unsloth Guide liest : Optimieren und beschleunigen Sie die LLM-Feinabstimmung.
In diesem Setup laden wir das Modell Llama-3.2-11B-Vision-Instruct, insbesondere die von Unsloth bereitgestellte Version, die für eine effiziente Feinabstimmung und Inferenz optimiert ist. Das Modell wird in 4-Bit-Quantisierung geladen, um den Speicherbedarf und die Rechenanforderungen deutlich zu reduzieren, so dass auch große Visionsmodelle auf den T4-GPUs ausgeführt werden können.
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)LoRA (Low-Rank Adaptation) ist eine Technik zur effizienten Feinabstimmung großer vortrainierter Modelle durch die Einführung lernfähiger Low-Rank-Matrizen in bestimmte Teile des Modells. Dieser Ansatz ist leichtgewichtig und rechnerisch effizient und ermöglicht eine aufgabenspezifische Feinabstimmung, ohne die Kernstruktur des vortrainierten Modells zu verändern.
Um ein Modell mit LoRA zu trainieren, konzentrieren wir uns auf die Auswahl und Feinabstimmung spezifischer Komponenten, wie z. B. Sehschichten, Sprachschichten, Aufmerksamkeitsmodule und MLP-Module. So können wir das Modell für bestimmte Aufgaben mit minimalen Änderungen an der ursprünglichen Architektur anpassen.
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3443,
use_rslora = False,
loftq_config = None,
)Laden Sie die philschmid/amazon-product-descriptions-vlm Datensatz aus dem Hugging Face Hub und wähle nur die ersten 500 Stichproben aus. Der Datensatz enthält Produktbilder und Produktbeschreibungen sowie andere notwendige Informationen.
from datasets import load_dataset
dataset = load_dataset("philschmid/amazon-product-descriptions-vlm",
split = "train[0:500]")
datasetDataset({
features: ['image', 'Uniq Id', 'Product Name', 'Category', 'Selling Price', 'Model Number', 'About Product', 'Product Specification', 'Technical Details', 'Shipping Weight', 'Variants', 'Product Url', 'Is Amazon Seller', 'description'],
num_rows: 500
})Dies ist eine der Abbildungen des Produkts.
dataset[45]["image"]
Hier ist seine Beschreibung.
dataset[45]["description"]'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'Jetzt werden wir den Datensatz verarbeiten, der nur den Text und die Bilder enthält. Die Prompt-Vorlagen enthalten Benutzerfragen, Bilder und Produktbeschreibungen.
instruction = """
You are an expert Amazon worker who is good at writing product descriptions.
Write the product description accurately by looking at the image.
"""
def convert_to_conversation(sample):
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": instruction},
{"type": "image", "image": sample["image"]},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": sample["description"]}],
},
]
return {"messages": conversation}
pass
converted_dataset = [convert_to_conversation(sample) for sample in dataset]Der neue Datensatz ist nicht tabellarisch, sondern folgt einem Prompt-Stil, der dem Format von OpenAI ähnelt.
converted_dataset[45]{'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': '\nYou are an expert Amazon worker who is good at writing product descriptions. \nWrite the product description accurately by looking at the image.\n'},
{'type': 'image',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x302>}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': 'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'}]}]}Wir wählen das 46. Beispiel aus dem Datensatz aus und führen eine Inferenz durch, um festzustellen, wie gut es die Produktbeschreibung ohne Feinabstimmung schreibt.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)Die erstellte Beschreibung ist lang und ungenau. Sogar der Schreibstil ist anders.
The image showcases a race car featuring the well-known sponsorship branding "Nationwide," likely the primary vehicle in the Nationwide Series. The vehicle has a blue hood with the "Nationwide" logo prominently displayed and white text that reads, "on your side," on the windscreen. The car is predominantly white and grey, adorned with sponsor decals on various parts of the vehicle.
The front grille showcases the Chevrolet "Bowtie" logo, and the car is equipped with Chevrolet emblems and other sponsor decals, including:
• A white 88 logo on the front windscreen
Notably, the vehicle's wheels are equipped with "GoodYearWir werden nun das Modell für das Training einstellen und einen SFT-Trainer (Supervised Fine-Tuning) initialisieren, um ein Bildverarbeitungsmodell für das Training mit einem benutzerdefinierten Datensammler, einem Datensatz und einer Trainingskonfiguration vorzubereiten, die für ein effizientes Fine-Tuning optimiert sind.
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
fp16=not is_bf16_supported(),
bf16=is_bf16_supported(),
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none", # For Weights and Biases
remove_unused_columns=False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
dataset_num_proc=4,
max_seq_length=2048,
),
)Starte den Trainingsprozess, indem du den trainer.train() Code ausführst.
trainer_stats = trainer.train()Das Modell hat eine Epoche in 16 Minuten abgeschlossen, und der Trainingsverlust hat sich allmählich verringert. Das ist ein gutes Ergebnis.
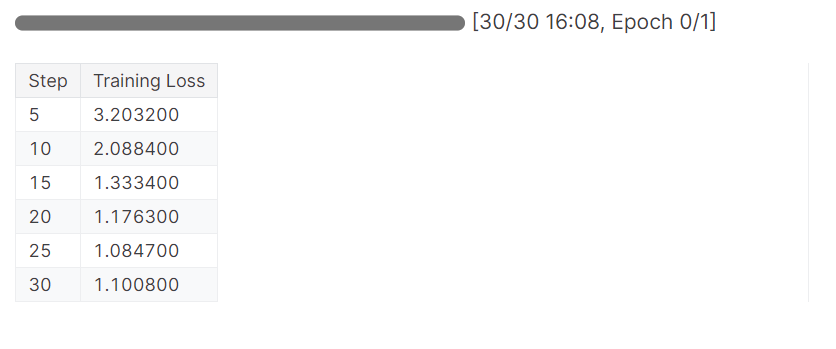
Wir werden nun unser Modell testen, um zu prüfen, ob die Feinabstimmung erfolgreich war. Wir werden dasselbe Beispielbild aus dem Datensatz auswählen und die Inferenz darauf anwenden.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)Die Ergebnisse sind toll, aber nicht ganz genau. Die Hashtags waren unnötig. Um optimale Ergebnisse zu erzielen, müssen wir das Modell mit dem gesamten Datensatz mit mindestens 3 Eposh trainieren.
Bring the thrill of NASCAR racing to your desk or shelf with the 1/64 Die-Cast 2016 NASCAR 88 Dale Earnhardt Jr. Nationwide Chevrolet SS! Highly detailed and precision engineered, this collectible die-cast car captures the iconic look of Earnhardt's famous No. 88 ride. Perfect for kids and adults alike, this miniature masterpiece makes a great gift. #NASCAR #DieCast #CollectibleCars #DaleEarnhardtJr #Nationwide<|eot_id|>Wir speichern das Modell lokal und schieben es dann zum Hugging Face Hub. Um das Modell auf den Hugging Face-Server hochzuladen, müssen wir uns mit unserem Hugging Face-Token anmelden.
Entdecke die transformative Welt von Hugging Face, dem Open-Source-Hub der KI-Community für maschinelles Lernen und große Sprachmodelle (LLMs), indem du den Blog liest . Was ist Hugging Face? Die Open-Source-Oase der KI-Community.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Danach speicherst du das Modell und den Tokenizer lokal.
model.save_pretrained("llama_3.2_vision_amazon_product") # Local saving
tokenizer.save_pretrained("llama_3.2_vision_amazon_product")Verwende dann push_to_hub, um das Modell auf dem Hugging Face Hub zu speichern.
model.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online saving
tokenizer.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online savingSaved model to https://huggingface.co/kingabzpro/llama_3.2_vision_amazon_productMit dem obigen Befehl wird das neue Modell-Repository erstellt und alle Dateien an Hugging Face übertragen.
Source: kingabzpro/llama_3.2_vision_amazon_product
Wenn du Probleme beim Ausführen des obigen Codes hast, schau bitte im Kaggle-Notizbuch nach: Feinabstimmung der Llama 3.2 Vision auf dem Amazon-Datensatz
Die Feinabstimmung der Llama 3.2 Vision-Modelle eröffnet eine neue Welt der Möglichkeiten, insbesondere in Szenarien, in denen sowohl Bilder als auch Text benötigt werden, um relevante und genaue Ergebnisse zu liefern. Durch die Feinabstimmung mit einem benutzerdefinierten Datensatz können wir die Leistung verbessern und den Stil für Anwendungen wie Visual Question Answering (VQA), Document VQA (DocVQA), Image Captioning und Image-Text Retrieval anpassen.
In diesem Tutorial tauchen wir tief in die Llama 3.2 Vision Modelle ein. Wir stimmen die 11B-Variante des Modells auch auf den Amazon-Produktbeschreibungsdatensatz ab, um einen hochgradig angepassten Produktbeschreibungsgenerator zu erstellen, der den gewünschten Stil annimmt und genaue Produktbeschreibungen liefert.
Im nächsten Schritt lernst du, wie du die KI-Anwendung erstellst und mit einem Docker-Image in der Cloud bereitstellst, indem du der Anleitung folgst: Wie man LLM-Anwendungen mit Docker einsetzt: Eine Schritt-für-Schritt-Anleitung.
Top KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.