
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Exploramos vários guias sobre ajuste fino de modelos de linguagem grandes (LLMs), mas há muito poucos recursos que abrangem o processo de ajuste fino de modelos multimodais. Neste tutorial, exploraremos um modelo multimodal de última geração chamado Llama 3.2 Vision Model e demonstraremos como ajustá-lo usando o conjunto de dados de produtos da Amazon. Nosso objetivo é criar um gerador de descrição de produtos que forneça legendas de imagens precisas e simplificadas para produtos listados na Amazon.
Se você é novo no ajuste fino de LLMs, faça o curso Ajuste fino com a Llama 3 para que você se familiarize com as metodologias e terminologias comuns. Você também pode conferir nosso tutorial do Llama 3.2 90B, , que aborda como criar um aplicativo de legendagem de imagens usando o Streamlit para o front-end, o Llama 3.2 90B para gerar legendas e o Groq como API.

Imagem do autor
Llama 3.2 apresenta modelos multimodais que podem processar dados de imagem e texto para gerar respostas naturais e precisas. Os modelos de visão Llama 3.2 estão disponíveis em variações de parâmetros 11B e 90B e são projetados especificamente para lidar com casos de uso de raciocínio de imagem com precisão notável. Esses modelos superam o desempenho de muitos modelos multimodais fechados e de código aberto existentes em benchmarks comuns do setor.
Leia o Guia doLlama 3.2: How It Works, Use Cases, and More para que você saiba mais sobre todas as variáveis do modelo em detalhes.
Os modelos de visão do Llama 3.2 são excelentes em tarefas como compreensão em nível de documento, análise de gráficos e tabelas, legendas de imagens e fundamentação visual, em que as descrições de linguagem natural são usadas para identificar objetos em imagens.
O modelo Vision do Llama 3.2 foi desenvolvido com base no modelo somente de texto mais antigo do Llama 3.1, que é um modelo de linguagem avançado que usa uma arquitetura de transformador. Ele foi ajustado com aprendizado supervisionado (SFT) e aprendizado por reforço com feedback humano (RLHF) para se alinhar com as preferências humanas de ajuda e segurança.
Para facilitar o reconhecimento de imagens, o Llama 3.2 Vision incorpora um adaptador de visão treinado separadamente. Esse adaptador usa camadas de atenção cruzada para integrar as saídas do codificador de imagem ao modelo de linguagem pré-treinado do Llama 3.1, permitindo que ele lide efetivamente com tarefas baseadas em texto e imagem.
O Llama 3.2 Vision se destaca em casos de uso como resposta a perguntas visuais, análise de documentos, legendas de imagens, recuperação de texto-imagem e aterramento visual.
Para este projeto, usaremos o Kaggle como nosso ambiente de codificação e computação, o Unsloth como estrutura de ajuste fino e o conjunto de dados de descrição de produtos da Amazon. O Unsloth é rápido, consome menos memória da GPU e requer menos linhas de código em comparação com os métodos tradicionais.
Se você deseja ajustar os LLMs para uma solução de geração de texto, temos o tutorial perfeito para você: Ajuste fino do Llama 3.2 e uso local: Um guia passo a passo.
Crie um novo notebook do Kaggle e configure o acelerador para usar duas GPUs T4. Adicione seu token do Hugging Face como um segredo do Kaggle para que você possa enviar seu modelo com segurança para o repositório do Hugging Face posteriormente. Em seguida, instale o pacote unsloth Python usando o comando pip.
%%capture
!pip install unslothPara saber mais sobre o Unsloth, leia o Guia do Unsloth em: Otimizar e acelerar o ajuste fino do LLM.
Nessa configuração, estamos carregando o modelo Llama-3.2-11B-Vision-Instruct, especificamente a versão fornecida pelo Unsloth, que é otimizada para ajuste fino e inferência eficientes. O modelo é carregado em quantização de 4 bits para reduzir significativamente o uso da memória e os requisitos computacionais, possibilitando a execução de grandes modelos de visão nas GPUs T4.
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)LoRA O LoRA (Low-Rank Adaptation) é uma técnica para o ajuste fino eficiente de grandes modelos pré-treinados por meio da introdução de matrizes de baixa classificação aprendidas em partes específicas do modelo. Essa abordagem é leve e eficiente do ponto de vista computacional e permite o ajuste fino específico da tarefa sem modificar a estrutura central do modelo pré-treinado.
Para treinar um modelo usando o LoRA, concentramo-nos na seleção e no ajuste fino de componentes específicos, como camadas de visão, camadas de linguagem, módulos de atenção e módulos MLP. Isso nos permite adaptar o modelo para tarefas específicas com alterações mínimas na arquitetura original.
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3443,
use_rslora = False,
loftq_config = None,
)Carregue o arquivo philschmid/amazon-product-descriptions-vlm do Hugging Face Hub e selecione apenas as primeiras 500 amostras. O conjunto de dados contém imagens e descrições de produtos, além de outras informações necessárias.
from datasets import load_dataset
dataset = load_dataset("philschmid/amazon-product-descriptions-vlm",
split = "train[0:500]")
datasetDataset({
features: ['image', 'Uniq Id', 'Product Name', 'Category', 'Selling Price', 'Model Number', 'About Product', 'Product Specification', 'Technical Details', 'Shipping Weight', 'Variants', 'Product Url', 'Is Amazon Seller', 'description'],
num_rows: 500
})Esta é uma das imagens do produto.
dataset[45]["image"]
Aqui está sua descrição.
dataset[45]["description"]'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'Agora, processaremos o conjunto de dados que contém apenas o texto e as imagens. Os modelos de prompt contêm perguntas do usuário, imagens e descrições de produtos.
instruction = """
You are an expert Amazon worker who is good at writing product descriptions.
Write the product description accurately by looking at the image.
"""
def convert_to_conversation(sample):
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": instruction},
{"type": "image", "image": sample["image"]},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": sample["description"]}],
},
]
return {"messages": conversation}
pass
converted_dataset = [convert_to_conversation(sample) for sample in dataset]O novo conjunto de dados não é tabular; em vez disso, ele segue um estilo de prompt semelhante ao formato da OpenAI.
converted_dataset[45]{'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': '\nYou are an expert Amazon worker who is good at writing product descriptions. \nWrite the product description accurately by looking at the image.\n'},
{'type': 'image',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x302>}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': 'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'}]}]}Selecionaremos a 46ª amostra do conjunto de dados e executaremos a inferência nela para avaliar se ela escreve bem a descrição do produto sem ajustes finos.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)A descrição gerada é longa e imprecisa. Até mesmo o estilo de escrita é diferente.
The image showcases a race car featuring the well-known sponsorship branding "Nationwide," likely the primary vehicle in the Nationwide Series. The vehicle has a blue hood with the "Nationwide" logo prominently displayed and white text that reads, "on your side," on the windscreen. The car is predominantly white and grey, adorned with sponsor decals on various parts of the vehicle.
The front grille showcases the Chevrolet "Bowtie" logo, and the car is equipped with Chevrolet emblems and other sponsor decals, including:
• A white 88 logo on the front windscreen
Notably, the vehicle's wheels are equipped with "GoodYearAgora, definiremos o modelo para treinamento e inicializaremos um treinador de ajuste fino supervisionado (SFT) para preparar um modelo de visão para treinamento em um coletor de dados personalizado, conjunto de dados e configuração de treinamento otimizados para um ajuste fino eficiente.
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
fp16=not is_bf16_supported(),
bf16=is_bf16_supported(),
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none", # For Weights and Biases
remove_unused_columns=False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
dataset_num_proc=4,
max_seq_length=2048,
),
)Inicie o processo de treinamento executando o código trainer.train().
trainer_stats = trainer.train()O modelo completou uma época em 16 minutos, e a perda de treinamento foi gradualmente reduzida. Esse é um bom resultado.
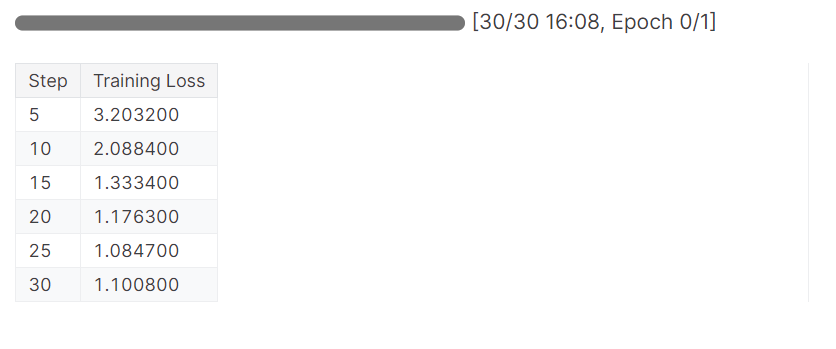
Agora, testaremos nosso modelo para verificar se o ajuste fino foi bem-sucedido. Vamos selecionar a mesma imagem de amostra do conjunto de dados e executar a inferência nela.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)Os resultados são ótimos, mas não totalmente precisos. As hashtags eram desnecessárias. Para obter os melhores resultados, precisaremos treinar o modelo no conjunto de dados completo com pelo menos 3 Eposh.
Bring the thrill of NASCAR racing to your desk or shelf with the 1/64 Die-Cast 2016 NASCAR 88 Dale Earnhardt Jr. Nationwide Chevrolet SS! Highly detailed and precision engineered, this collectible die-cast car captures the iconic look of Earnhardt's famous No. 88 ride. Perfect for kids and adults alike, this miniature masterpiece makes a great gift. #NASCAR #DieCast #CollectibleCars #DaleEarnhardtJr #Nationwide<|eot_id|>Vamos salvar o modelo localmente e, em seguida, enviá-lo para o Hugging Face Hub. Para fazer upload do modelo para o servidor Hugging Face, precisamos fazer login usando nosso token Hugging Face.
Explore o mundo transformador do Hugging Face, o centro de código aberto da comunidade de IA para aprendizado de máquina e modelos de linguagem grandes (LLMs), lendo o blog . O que é o Hugging Face? O oásis de código aberto da comunidade de IA.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Depois disso, salve o modelo e o tokenizador localmente.
model.save_pretrained("llama_3.2_vision_amazon_product") # Local saving
tokenizer.save_pretrained("llama_3.2_vision_amazon_product")Em seguida, use push_to_hub para salvar o modelo no hub Hugging Face.
model.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online saving
tokenizer.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online savingSaved model to https://huggingface.co/kingabzpro/llama_3.2_vision_amazon_productO comando acima criará o novo repositório de modelos e enviará todos os arquivos para o Hugging Face.
Fonte: kingabzpro/llama_3.2_vision_amazon_product
Se você estiver enfrentando problemas para executar o código acima, consulte o notebook da Kaggle: Ajuste fino da visão do Llama 3.2 no conjunto de dados da Amazon
O ajuste fino dos modelos do Llama 3.2 Vision abre um novo mundo de possibilidades, especialmente em cenários em que imagens e textos são necessários para fornecer resultados relevantes e precisos. Ao fazer o ajuste fino em um conjunto de dados personalizado, podemos melhorar o desempenho e adaptar o estilo para aplicativos como Visual Question Answering (VQA), Document VQA (DocVQA), Image Captioning e Image-Text Retrieval.
Neste tutorial, vamos nos aprofundar no aprendizado dos modelos de visão do Llama 3.2. Também ajustamos a variante 11B do modelo no conjunto de dados de descrições de produtos da Amazon para criar um gerador de descrição de produtos altamente personalizado que adota o estilo desejado e fornece descrições precisas dos produtos.
A próxima etapa da sua jornada é aprender a criar o aplicativo de IA e implantá-lo na nuvem usando uma imagem do Docker, seguindo o guia: Como implantar aplicativos LLM usando o Docker: Um guia passo a passo.
Principais cursos de IA
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Aashi Dutt
Tutorial
Zoumana Keita
Tutorial
Moez Ali


