
programa
Desarrollar grandes modelos lingüísticos
16 h
Hemos explorado numerosas guías sobre ajuste fino de grandes modelos lingüísticos (LLM), pero hay muy pocos recursos que cubran el proceso de ajuste fino de los modelos multimodales. En este tutorial, exploraremos un modelo multimodal de última generación llamado Modelo de Visión Llama 3.2 y demostraremos cómo afinarlo utilizando el conjunto de datos de productos de Amazon. Nuestro objetivo es construir un generador de descripciones de productos que proporcione pies de foto precisos y simplificados para los productos que aparecen en Amazon.
Si eres nuevo en el ajuste fino de LLMs, por favor toma el Puesta a punto con Llama 3 para familiarizarte con las metodologías y terminologías habituales. También puedes consultar nuestro tutorial sobre Llama 3.2 90B, , que explica cómo crear una aplicación de subtitulación de imágenes utilizando Streamlit para el front-end, Llama 3.2 90B para generar subtítulos y Groq como API.

Imagen del autor
Llama 3.2 introduce modelos multimodales que pueden procesar tanto datos de imagen como de texto para generar respuestas naturales y precisas. Los modelos de visión Llama 3.2 están disponibles en las variantes de parámetros 11B y 90B, y se han diseñado específicamente para manejar casos de uso de razonamiento de imágenes con notable precisión. Estos modelos superan a muchos modelos multimodales cerrados y de código abierto existentes en puntos de referencia comunes del sector.
Lee la GuíaLlama 3.2: Cómo funciona, casos de uso y más para conocer en detalle todas las variables del modelo.
Los modelos de visión de Llama 3.2 destacan en tareas como la comprensión a nivel de documento, el análisis de gráficos y diagramas, el subtitulado de imágenes y la fundamentación visual, en las que se utilizan descripciones en lenguaje natural para identificar objetos en imágenes.
El modelo Llama 3.2 Visión está construido sobre el antiguo modelo Llama 3.1 sólo texto, que es un modelo de lenguaje avanzado que utiliza una arquitectura de transformadores. Se afinó con aprendizaje supervisado (SFT) y aprendizaje de refuerzo con retroalimentación humana (RLHF) para alinearlo con las preferencias humanas de utilidad y seguridad.
Para facilitar el reconocimiento de imágenes, Llama 3.2 Visión incorpora un adaptador de visión entrenado por separado. Este adaptador utiliza capas de atención cruzada para integrar las salidas del codificador de imágenes en el modelo lingüístico preentrenado Llama 3.1, lo que le permite manejar eficazmente tanto tareas basadas en texto como en imágenes.
Llama 3.2 Visión sobresale en casos de uso como la respuesta visual a preguntas, el análisis de documentos, el subtitulado de imágenes, la recuperación imagen-texto y el enraizamiento visual.
Para este proyecto, utilizaremos Kaggle como entorno de codificación y cálculo, Unsloth como marco de ajuste y el conjunto de datos de descripción de productos de Amazon. Unsloth es rápido, consume menos memoria de la GPU y requiere menos líneas de código en comparación con los métodos tradicionales.
Si buscas afinar los LLM para una solución de generación de texto, tenemos el tutorial perfecto para ti: Puesta a punto de Llama 3.2 y uso local: Guía paso a paso.
Crea un nuevo cuaderno Kaggle y configura el acelerador para que utilice dos GPU T4. Añade tu token de Hugging Face como secreto de Kaggle para que puedas enviar de forma segura tu modelo a tu repositorio de Hugging Face más adelante. A continuación, instala el paquete unsloth Python mediante el comando pip.
%%capture
!pip install unslothDescubre más sobre Unsloth leyendo la Guía de Unsloth: Optimizar y acelerar el ajuste fino LLM.
En esta configuración, estamos cargando el modelo Llama-3.2-11B-Vision-Instruct, concretamente la versión proporcionada por Unsloth, que está optimizada para un ajuste fino y una inferencia eficientes. El modelo se carga en cuantización de 4 bits para reducir significativamente el uso de memoria y los requisitos computacionales, lo que permite ejecutar grandes modelos de visión en las GPU T4.
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)LoRA (Adaptación de Bajo Rango) es una técnica para ajustar eficazmente grandes modelos preentrenados introduciendo matrices de bajo rango aprendibles en partes específicas del modelo. Este enfoque es ligero y eficiente desde el punto de vista informático, y permite un ajuste fino específico de la tarea sin modificar la estructura central del modelo preentrenado.
Para entrenar un modelo utilizando LoRA, nos centramos en seleccionar y ajustar componentes específicos, como las capas de visión, las capas de lenguaje, los módulos de atención y los módulos MLP. Esto nos permite adaptar el modelo a tareas específicas con cambios mínimos en la arquitectura original.
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3443,
use_rslora = False,
loftq_config = None,
)Carga el philschmid/descripciones-producto-amazon-vlm del Hub Cara Abrazada y selecciona sólo las 500 primeras muestras. El conjunto de datos contiene imágenes y descripciones de los productos, junto con otra información necesaria.
from datasets import load_dataset
dataset = load_dataset("philschmid/amazon-product-descriptions-vlm",
split = "train[0:500]")
datasetDataset({
features: ['image', 'Uniq Id', 'Product Name', 'Category', 'Selling Price', 'Model Number', 'About Product', 'Product Specification', 'Technical Details', 'Shipping Weight', 'Variants', 'Product Url', 'Is Amazon Seller', 'description'],
num_rows: 500
})Esta es una de las imágenes del producto.
dataset[45]["image"]
He aquí su descripción.
dataset[45]["description"]'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'Ahora, procesaremos el conjunto de datos que sólo contiene el texto y las imágenes. Las plantillas de avisos contienen preguntas de usuario, imágenes y descripciones de productos.
instruction = """
You are an expert Amazon worker who is good at writing product descriptions.
Write the product description accurately by looking at the image.
"""
def convert_to_conversation(sample):
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": instruction},
{"type": "image", "image": sample["image"]},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": sample["description"]}],
},
]
return {"messages": conversation}
pass
converted_dataset = [convert_to_conversation(sample) for sample in dataset]El nuevo conjunto de datos no es tabular, sino que sigue un estilo de consulta similar al formato de OpenAI.
converted_dataset[45]{'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': '\nYou are an expert Amazon worker who is good at writing product descriptions. \nWrite the product description accurately by looking at the image.\n'},
{'type': 'image',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x302>}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': 'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'}]}]}Seleccionaremos la muestra 46 del conjunto de datos y ejecutaremos la inferencia sobre ella para evaluar lo bien que escribe la descripción del producto sin ajuste fino.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)La descripción generada es larga e inexacta. Incluso el estilo de escritura es diferente.
The image showcases a race car featuring the well-known sponsorship branding "Nationwide," likely the primary vehicle in the Nationwide Series. The vehicle has a blue hood with the "Nationwide" logo prominently displayed and white text that reads, "on your side," on the windscreen. The car is predominantly white and grey, adorned with sponsor decals on various parts of the vehicle.
The front grille showcases the Chevrolet "Bowtie" logo, and the car is equipped with Chevrolet emblems and other sponsor decals, including:
• A white 88 logo on the front windscreen
Notably, the vehicle's wheels are equipped with "GoodYearAhora configuraremos el modelo para el entrenamiento e inicializaremos un entrenador de ajuste fino supervisado (SFT) para preparar un modelo de visión para el entrenamiento en un recopilador de datos personalizado, un conjunto de datos y una configuración de entrenamiento optimizados para un ajuste fino eficaz.
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
fp16=not is_bf16_supported(),
bf16=is_bf16_supported(),
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none", # For Weights and Biases
remove_unused_columns=False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
dataset_num_proc=4,
max_seq_length=2048,
),
)Inicia el proceso de entrenamiento ejecutando el código trainer.train().
trainer_stats = trainer.train()El modelo ha completado una época en 16 minutos, y la pérdida de entrenamiento se ha reducido gradualmente. Es un buen resultado.
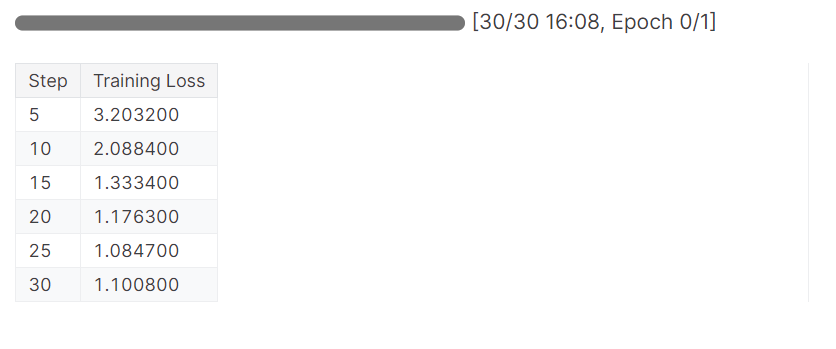
Ahora pondremos a prueba nuestro modelo para comprobar si el ajuste ha tenido éxito. Vamos a seleccionar la misma imagen de muestra del conjunto de datos y a realizar la inferencia sobre ella.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)Los resultados son magníficos, pero no totalmente precisos. Los hashtags eran innecesarios. Para obtener resultados óptimos, tendremos que entrenar el modelo en el conjunto de datos completo con al menos 3 Eposh.
Bring the thrill of NASCAR racing to your desk or shelf with the 1/64 Die-Cast 2016 NASCAR 88 Dale Earnhardt Jr. Nationwide Chevrolet SS! Highly detailed and precision engineered, this collectible die-cast car captures the iconic look of Earnhardt's famous No. 88 ride. Perfect for kids and adults alike, this miniature masterpiece makes a great gift. #NASCAR #DieCast #CollectibleCars #DaleEarnhardtJr #Nationwide<|eot_id|>Guardemos el modelo localmente y, a continuación, enviémoslo al Hub Cara Abrazada. Para subir el modelo al servidor de Hugging Face, tenemos que iniciar sesión utilizando nuestro token de Hugging Face.
Explora el mundo transformador de H ugging Face, el centro de código abierto de la comunidad de IA para el aprendizaje automático y los grandes modelos lingüísticos (LLM), leyendo el blog ¿Qué es Hugging Face? El oasis de código abierto de la comunidad de IA.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Después, guarda el modelo y el tokenizador localmente.
model.save_pretrained("llama_3.2_vision_amazon_product") # Local saving
tokenizer.save_pretrained("llama_3.2_vision_amazon_product")A continuación, utiliza push_to_hub para guardar el modelo en el hub Cara Abrazada.
model.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online saving
tokenizer.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online savingSaved model to https://huggingface.co/kingabzpro/llama_3.2_vision_amazon_productEl comando anterior creará el nuevo repositorio de modelos y enviará todos los archivos a Cara Abrazada.
Fuente: kingabzpro/llama_3.2_vision_amazon_product
Si tienes problemas para ejecutar el código anterior, consulta el cuaderno Kaggle: Ajuste de la visión de Llama 3.2 en el conjunto de datos de Amazon
Afinar los modelos de visión de Llama 3.2 abre un nuevo mundo de posibilidades, sobre todo en escenarios en los que se necesitan tanto imágenes como texto para ofrecer resultados relevantes y precisos. Afinándolo en un conjunto de datos personalizado, podemos mejorar el rendimiento y adaptar el estilo a aplicaciones como la Respuesta Visual a Preguntas (VQA), el VQA de Documentos (DocVQA), el Subtitulado de Imágenes y la Recuperación Imagen-Texto.
En este tutorial, nos sumergimos de lleno en el aprendizaje de los modelos de Visión de Llama 3.2. También afinamos la variante 11B del modelo en el conjunto de datos de descripciones de productos de Amazon para construir un generador de descripciones de productos altamente personalizado que adopte el estilo deseado y proporcione descripciones precisas de los productos.
El siguiente paso en tu viaje es aprender a crear la aplicación de IA y desplegarla en la nube utilizando una imagen Docker siguiendo la guía: Cómo desplegar aplicaciones LLM utilizando Docker: Guía paso a paso.
Los mejores cursos de IA
programa
Curso
Curso
blog
Bhavishya Pandit
8 min
blog
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
