
Cursus
Développer des LLM
16 h
Nous avons exploré de nombreux guides sur le réglage fin des grands modèles de langage (LLM), mais très peu de ressources couvrent le processus de réglage fin des modèles multimodaux. Dans ce tutoriel, nous allons explorer un modèle multimodal de pointe appelé le modèle de vision Llama 3.2 et démontrer comment l'affiner en utilisant l'ensemble de données de produits Amazon. Notre objectif est de créer un générateur de descriptions de produits qui fournisse des légendes précises et simplifiées pour les produits listés sur Amazon.
Si vous n'avez pas l'habitude de peaufiner les LLM, veuillez suivre le cours de mise au point des LLM. Le réglage fin avec le lama 3 pour vous familiariser avec les méthodologies et les terminologies courantes. Vous pouvez également consulter notre tutoriel Llama 3.2 90B, , qui explique comment créer une application de sous-titrage d'images en utilisant Streamlit pour l'interface utilisateur, Llama 3.2 90B pour générer des légendes et Groq comme API.

Image par l'auteur
Llama 3.2 introduit des modèles multimodaux qui peuvent traiter à la fois des images et des données textuelles afin de générer des réponses naturelles et précises. Les modèles de vision Llama 3.2 sont disponibles dans les variations de paramètres 11B et 90B et sont spécialement conçus pour traiter les cas d'utilisation du raisonnement par l'image avec une précision remarquable. Ces modèles sont plus performants que de nombreux modèles multimodaux existants, qu'ils soient ouverts ou fermés, sur des critères de référence communs à l'industrie.
Lisez le guideLlama 3.2 : Fonctionnement, cas d'utilisation et autres pour découvrir en détail toutes les variables du modèle.
Les modèles de vision Llama 3.2 excellent dans des tâches telles que la compréhension de documents, l'analyse de diagrammes et de graphiques, le sous-titrage d'images et le repérage visuel, où des descriptions en langage naturel sont utilisées pour identifier des objets dans des images.
Le modèle Llama 3.2 Vision est construit sur l'ancien modèle Llama 3.1 texte seul, qui est un modèle de langage avancé utilisant une architecture de transformateur. Il a été affiné à l'aide de l'apprentissage supervisé (SFT) et de l'apprentissage par renforcement avec retour d'information humain (RLHF) afin de s'aligner sur les préférences humaines en matière de serviabilité et de sécurité.
Pour faciliter la reconnaissance d'images, Llama 3.2 Vision intègre un adaptateur de vision formé séparément. Cet adaptateur utilise des couches d'attention croisée pour intégrer les résultats de l'encodeur d'images dans le modèle linguistique Llama 3.1 pré-entraîné, ce qui lui permet de traiter efficacement les tâches basées à la fois sur le texte et sur l'image.
Llama 3.2 Vision excelle dans des cas d'utilisation tels que la réponse à des questions visuelles, l'analyse de documents, le sous-titrage d'images, l'extraction d'images et de textes, et l'ancrage visuel.
Pour ce projet, nous utiliserons Kaggle comme environnement de codage et de calcul, Unsloth comme cadre de mise au point, et l'ensemble de données de description de produits Amazon. Unsloth est rapide, consomme moins de mémoire GPU et nécessite moins de lignes de code que les méthodes traditionnelles.
Si vous cherchez à affiner les LLM pour une solution de génération de texte, nous avons le tutoriel parfait pour vous : Mise au point de Llama 3.2 et utilisation locale : Un guide étape par étape.
Créez un nouveau carnet Kaggle et configurez l'accélérateur pour utiliser deux GPU T4. Ajoutez votre jeton Hugging Face en tant que secret Kaggle afin de pouvoir pousser en toute sécurité votre modèle vers votre référentiel Hugging Face ultérieurement. Ensuite, installez le paquetage Python unsloth à l'aide de la commande pip.
%%capture
!pip install unslothPour en savoir plus sur Unsloth, lisez le guideUnsloth : Optimiser et accélérer le réglage fin du LLM.
Dans cette configuration, nous chargeons le modèle Llama-3.2-11B-Vision-Instruct, en particulier la version fournie par Unsloth, qui est optimisée pour un réglage fin et une inférence efficaces. Le modèle est chargé en quantification 4 bits afin de réduire considérablement l'utilisation de la mémoire et les exigences de calcul, ce qui permet d'exécuter de grands modèles de vision sur les GPU T4.
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)LoRA (Low-Rank Adaptation) est une technique permettant d'affiner efficacement de grands modèles pré-entraînés en introduisant des matrices de faible rang pouvant être apprises dans des parties spécifiques du modèle. Cette approche est légère et efficace sur le plan informatique et permet un réglage fin spécifique à la tâche sans modifier la structure de base du modèle pré-entraîné.
Pour former un modèle à l'aide de LoRA, nous nous concentrons sur la sélection et le réglage fin de composants spécifiques, tels que les couches de vision, les couches de langage, les modules d'attention et les modules MLP. Cela nous permet d'adapter le modèle à des tâches spécifiques avec un minimum de modifications de l'architecture originale.
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3443,
use_rslora = False,
loftq_config = None,
)Chargez le fichier philschmid/amazon-product-descriptions-vlm du Hugging Face Hub et ne sélectionnez que les 500 premiers échantillons. L'ensemble de données contient des images et des descriptions de produits ainsi que d'autres informations nécessaires.
from datasets import load_dataset
dataset = load_dataset("philschmid/amazon-product-descriptions-vlm",
split = "train[0:500]")
datasetDataset({
features: ['image', 'Uniq Id', 'Product Name', 'Category', 'Selling Price', 'Model Number', 'About Product', 'Product Specification', 'Technical Details', 'Shipping Weight', 'Variants', 'Product Url', 'Is Amazon Seller', 'description'],
num_rows: 500
})Voici l'une des images du produit.
dataset[45]["image"]
Voici sa description.
dataset[45]["description"]'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'Nous allons maintenant traiter l'ensemble de données qui ne contient que du texte et des images. Les modèles d'invite contiennent des questions d'utilisateurs, des images et des descriptions de produits.
instruction = """
You are an expert Amazon worker who is good at writing product descriptions.
Write the product description accurately by looking at the image.
"""
def convert_to_conversation(sample):
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": instruction},
{"type": "image", "image": sample["image"]},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": sample["description"]}],
},
]
return {"messages": conversation}
pass
converted_dataset = [convert_to_conversation(sample) for sample in dataset]Le nouvel ensemble de données n'est pas présenté sous forme de tableau, mais suit un style d'invite similaire au format de l'OpenAI.
converted_dataset[45]{'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': '\nYou are an expert Amazon worker who is good at writing product descriptions. \nWrite the product description accurately by looking at the image.\n'},
{'type': 'image',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x302>}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': 'Authentic Dale Earnhardt Jr. 1:24 scale diecast car. Nationwide Raw Finish. Collectible model car for racing fans. Perfect gift for NASCAR enthusiasts.'}]}]}Nous sélectionnerons le 46e échantillon de l'ensemble de données et l'utiliserons pour évaluer la qualité de la rédaction de la description du produit sans ajustement.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)La description générée est longue et imprécise. Même le style d'écriture est différent.
The image showcases a race car featuring the well-known sponsorship branding "Nationwide," likely the primary vehicle in the Nationwide Series. The vehicle has a blue hood with the "Nationwide" logo prominently displayed and white text that reads, "on your side," on the windscreen. The car is predominantly white and grey, adorned with sponsor decals on various parts of the vehicle.
The front grille showcases the Chevrolet "Bowtie" logo, and the car is equipped with Chevrolet emblems and other sponsor decals, including:
• A white 88 logo on the front windscreen
Notably, the vehicle's wheels are equipped with "GoodYearNous allons maintenant configurer le modèle pour l'entraînement et initialiser un entraîneur de réglage fin supervisé (SFT) afin de préparer un modèle de vision pour l'entraînement sur un collecteur de données personnalisé, un ensemble de données et une configuration d'entraînement optimisés pour un réglage fin efficace.
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
fp16=not is_bf16_supported(),
bf16=is_bf16_supported(),
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none", # For Weights and Biases
remove_unused_columns=False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
dataset_num_proc=4,
max_seq_length=2048,
),
)Lancez le processus de formation en exécutant le code trainer.train().
trainer_stats = trainer.train()Le modèle a effectué une épochè en 16 minutes et la perte d'entraînement a progressivement diminué. C'est un bon résultat.
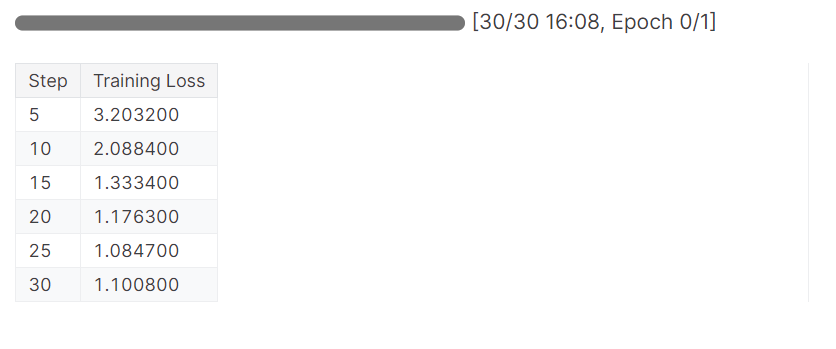
Nous allons maintenant tester notre modèle pour vérifier si l'ajustement a été réussi. Nous allons sélectionner le même échantillon d'image dans l'ensemble de données et exécuter l'inférence sur celui-ci.
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset[45]["image"]
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}
]
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)Les résultats sont excellents mais ne sont pas totalement exacts. Les hashtags n'étaient pas nécessaires. Pour obtenir des résultats optimaux, nous devrons entraîner le modèle sur l'ensemble du jeu de données avec au moins 3 Eposh.
Bring the thrill of NASCAR racing to your desk or shelf with the 1/64 Die-Cast 2016 NASCAR 88 Dale Earnhardt Jr. Nationwide Chevrolet SS! Highly detailed and precision engineered, this collectible die-cast car captures the iconic look of Earnhardt's famous No. 88 ride. Perfect for kids and adults alike, this miniature masterpiece makes a great gift. #NASCAR #DieCast #CollectibleCars #DaleEarnhardtJr #Nationwide<|eot_id|>Sauvegardons le modèle localement, puis envoyons-le au Hugging Face Hub. Pour télécharger le modèle sur le serveur Hugging Face, nous devons nous connecter à l'aide de notre jeton Hugging Face.
Explorez le monde transformateur de Hugging Face, le hub open-source de la communauté de l'IA pour l'apprentissage automatique et les grands modèles de langage (LLM), en lisant le blog Qu'est-ce que Hugging Face ? L'oasis de la communauté de l'IA en matière de logiciels libres.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Ensuite, sauvegardez le modèle et le tokenizer localement.
model.save_pretrained("llama_3.2_vision_amazon_product") # Local saving
tokenizer.save_pretrained("llama_3.2_vision_amazon_product")Utilisez ensuite push_to_hub pour enregistrer le modèle sur le concentrateur Hugging Face.
model.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online saving
tokenizer.push_to_hub(
"kingabzpro/llama_3.2_vision_amazon_product"
) # Online savingSaved model to https://huggingface.co/kingabzpro/llama_3.2_vision_amazon_productLa commande ci-dessus créera le nouveau référentiel de modèles et transférera tous les fichiers vers Hugging Face.
Source : kingabzpro/llama_3.2_vision_amazon_product
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer au carnet Kaggle : Affiner la vision du Llama 3.2 sur l'ensemble de données d'Amazon
L'affinement des modèles de vision Llama 3.2 ouvre un nouveau monde de possibilités, en particulier dans les scénarios où les images et le texte sont nécessaires pour fournir des résultats pertinents et précis. En l'affinant sur un ensemble de données personnalisé, nous pouvons améliorer les performances et adapter le style à des applications telles que la réponse aux questions visuelles (VQA), la VQA de documents (DocVQA), le légendage d'images et la recherche d'images et de textes.
Dans ce tutoriel, nous allons nous plonger dans l'apprentissage des modèles de vision de Llama 3.2. Nous avons également affiné la variante 11B du modèle sur l'ensemble de données de descriptions de produits Amazon afin de construire un générateur de descriptions de produits hautement personnalisé qui adopte le style souhaité et fournit des descriptions précises des produits.
La prochaine étape de votre parcours consiste à apprendre à construire l'application d'IA et à la déployer sur le cloud à l'aide d'une image Docker en suivant le guide : Comment déployer des applications LLM en utilisant Docker : Un guide étape par étape.
Principaux cours sur l'IA
Cursus
Cours
Cours