
Curso
Introducción a la ingeniería de datos
4 h
127.6K
¿Te preguntas cuál es la mejor forma de integrar los datos? En esta sección exploraremos las distintas técnicas utilizadas para integrar datos. Cada técnica se adapta a distintos tipos de entornos y requisitos. ¡Vamos a echarles un vistazo!
ETL es la técnica tradicional de integración de datos. Implica tres pasos clave:
En la fase de extracción, se recogen datos de distintos sistemas. La fase de transformación garantiza que los datos se limpien, normalicen y formateen para ajustarse a un esquema coherente. Por último, en la fase de carga, los datos transformados se almacenan en el sistema de destino, donde quedan disponibles para el análisis y la elaboración de informes.
La mejor forma de utilizar ETL es cuando necesitas integrar y estructurar datos de fuentes múltiples y diversas para la elaboración de informes, análisis o inteligencia empresarial. Es ideal para organizaciones con datos estructurados que requieren una limpieza y transformación exhaustivas antes del análisis.
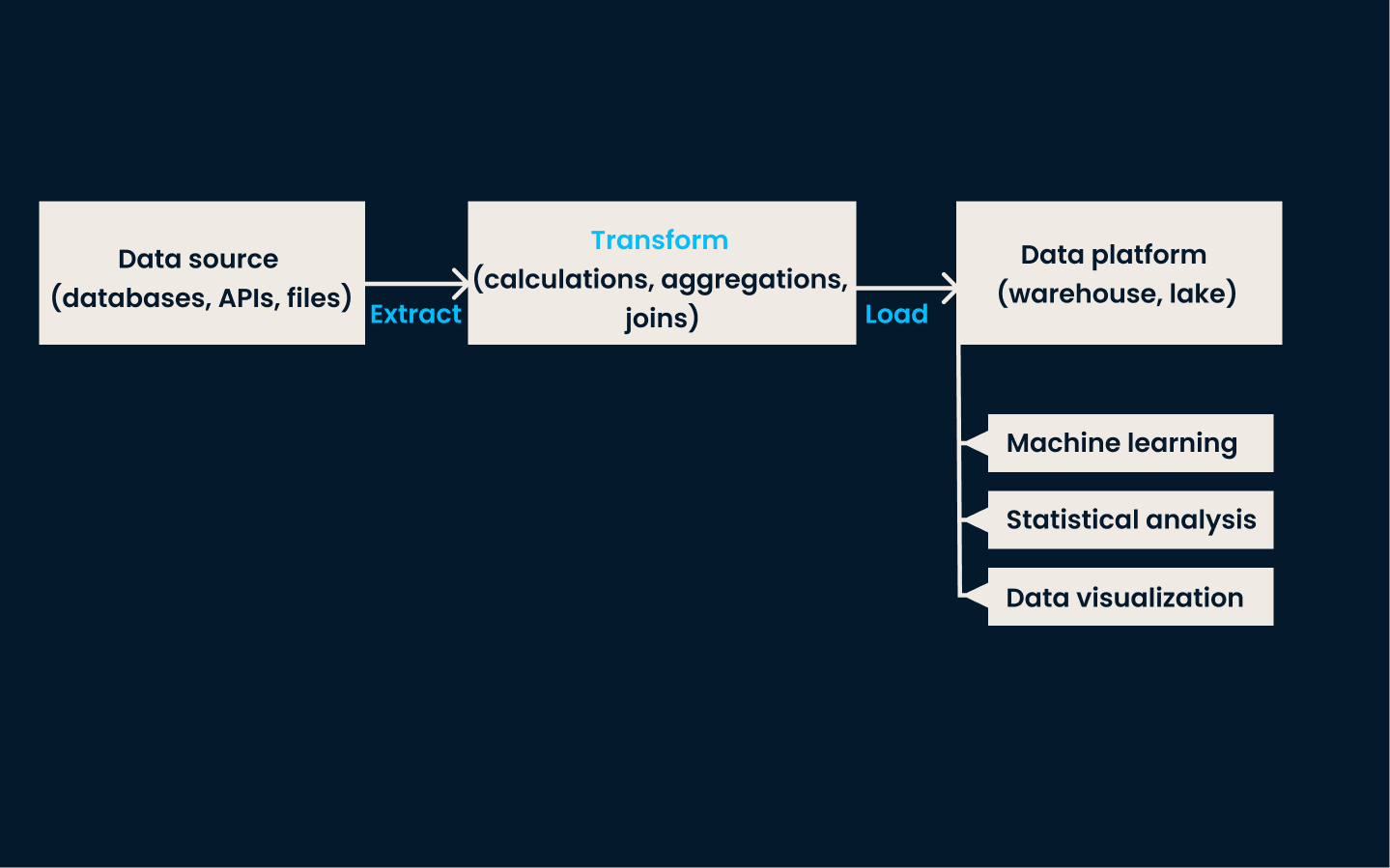
Ejemplo de arquitectura ETL
Este enfoque es especialmente eficaz en entornos tradicionales locales con un volumen de datos y una complejidad de transformación moderados. ETL es el método al que debes recurrir si tus datos necesitan procesamiento por lotes y actualizaciones programadas con regularidad.
ELT es una variación de ETL diseñada para manejar los grandes conjuntos de datos que suelen encontrarse en los entornos de nube. En este enfoque, primero se extraen los datos y se cargan en un sistema de destino, y sólo después de cargarlos se produce la transformación.
En otras palabras, ELT es lo mejor para las organizaciones que necesitan cargar grandes cantidades de datos en bruto rápidamente y transformarlos después. Esto les otorga más flexibilidad en cómo y cuándo se aplican las transformaciones de datos. Si tu empresa trabaja con datos no estructurados o necesita una transformación casi en tiempo real, la ELT es mejor que la ETL tradicional.
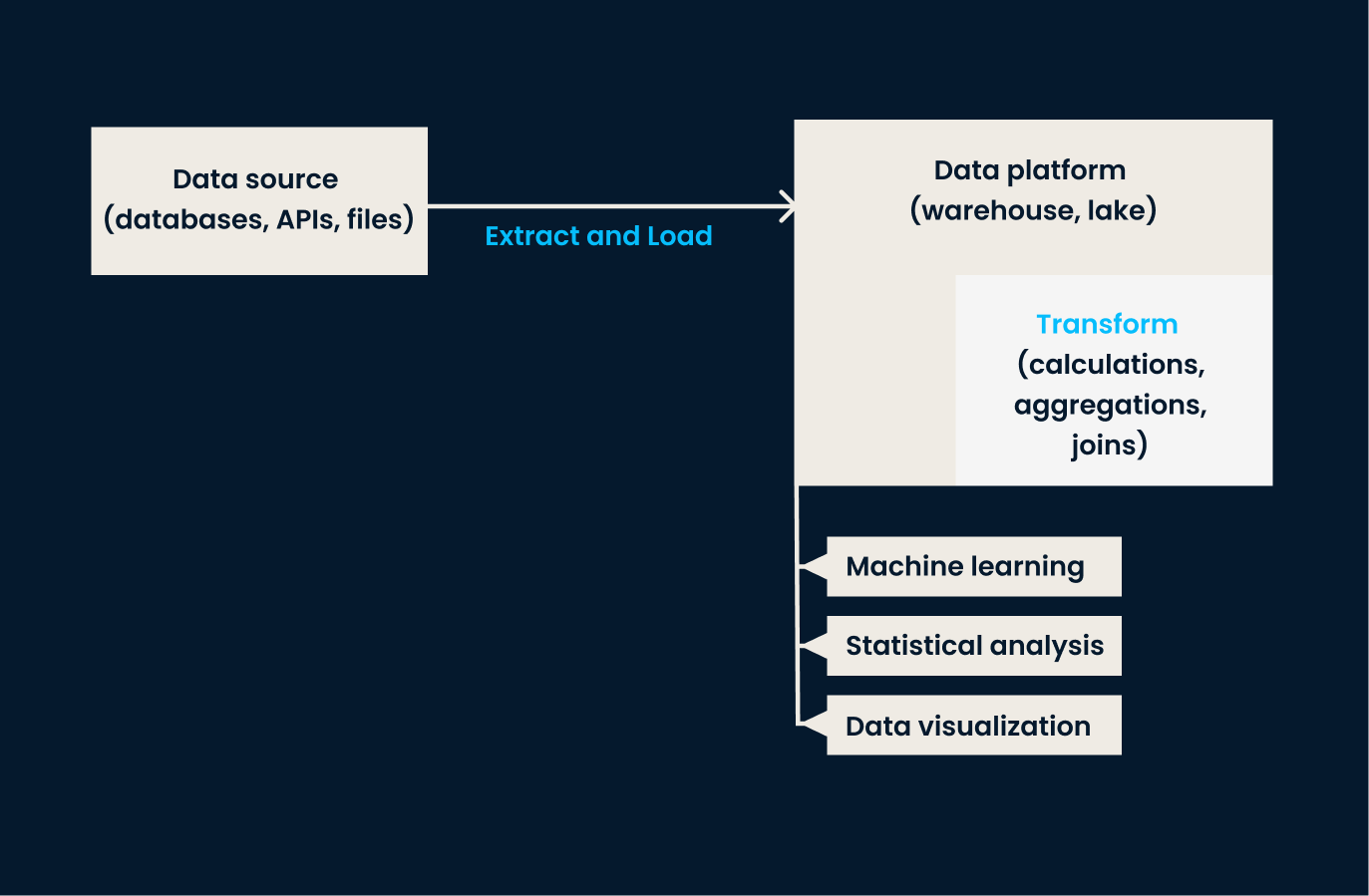
Ejemplo de arquitectura ELT
Si quieres aprender más sobre estos procesos tradicionales de ingeniería de datos, te recomiendo que eches un vistazo al curso ETL y ELT en Python.
La replicación de datos es el proceso de copiar datos de un sistema a otro. Esta técnica garantiza que todos los sistemas trabajen con los mismos datos y ayuda a mantener sincronizados los distintos entornos.
La replicación puede hacerse en tiempo real o a intervalos programados, según las necesidades específicas. Su principal ventaja es que mejora la disponibilidad y fiabilidad de los datos, garantizando que los sistemas críticos tengan acceso constante a la información más actualizada.
Este enfoque es el más adecuado para situaciones en las que la alta disponibilidad y la coherencia entre sistemas son fundamentales. Se suele utilizar para copias de seguridad, recuperación ante desastres y sincronización de datos en distintos entornos, como entre sistemas locales y en la nube.
La replicación de datos también es valiosa para aplicaciones que requieren acceso inmediato a copias idénticas de datos en varias ubicaciones. Si tu organización necesita asegurarse de que los datos están disponibles y actualizados en distintas plataformas o regiones, la replicación es una opción excelente.
Ten en cuenta que, técnicamente, la opción de replicación sólo suele estar disponible para las bases de datos tradicionales, para crear copias exactas de los datos originales.
La virtualización de datos es un enfoque más moderno de la integración de datos. Permite a los usuarios acceder a los datos y consultarlos en tiempo real, sin moverlos ni transformarlos físicamente.
En lugar de consolidar los datos en un único repositorio, esta técnica crea una capa virtual que se conecta a varias fuentes de datos y proporciona una visión unificada de los datos de múltiples sistemas, facilitando el acceso a los datos y su análisis.
Esta técnica funciona mejor cuando el acceso a los datos en tiempo real es más importante que moverlos o consolidarlos físicamente. Es ideal para organizaciones con fuentes de datos dispares que desean crear una vista unificada sin la complejidad y el retraso de los procesos ETL tradicionales.
La virtualización de datos es una solución potente si tu caso de uso requiere acceso bajo demanda a múltiples fuentes de datos, como cuando se realizan consultas en varias bases de datos o API.
La integración de datos en streaming gestiona el procesamiento de datos en tiempo real procedentes de fuentes basadas en eventos (por ejemplo, dispositivos IoT, plataformas de medios sociales, mercados financieros, etc.). En lugar de esperar a los procesos por lotes, esta técnica permite ingerir e integrar los datos en cuanto se generan.
Este enfoque se utiliza en situaciones en las que se necesitan conocimientos oportunos y respuestas rápidas. La integración de datos en streaming es óptima si tu organización necesita tomar decisiones rápidas basadas en la información más actualizada o si la latencia es una preocupación.
Consulta el curso Conceptos de streaming para saber más sobre esta técnica.
La siguiente tabla resume las distintas técnicas que acabamos de comentar:
|
Técnica |
Descripción |
Más adecuado para |
Ejemplos de casos prácticos |
Beneficios |
|
ETL (Extraer, Transformar, Cargar) |
Método tradicional que implica la extracción, transformación y carga de datos en un sistema de destino. |
Datos estructurados que requieren una limpieza y transformación exhaustivas para la elaboración de informes, análisis o BI. |
Consolidar datos de múltiples fuentes en un almacén de datos para su procesamiento por lotes y actualizaciones programadas. |
Garantiza datos limpios, normalizados y estructurados, listos para el análisis. |
|
ELT (Extraer, Cargar, Transformar) |
Variante moderna de ETL en la que los datos se transforman después de cargarse en el sistema de destino. |
Grandes conjuntos de datos en entornos de nube, datos no estructurados o necesidades de transformación casi en tiempo real. |
Carga de datos sin procesar en un lago de datos o almacén de datos basado en la nube para una transformación flexible y bajo demanda. |
Proporciona flexibilidad en cuándo y cómo se aplican las transformaciones. |
|
Replicación de datos |
Copia los datos de un sistema a otro para mantener la coherencia y la disponibilidad en todos los entornos. |
Requisitos de alta disponibilidad y coherencia, recuperación ante desastres y escenarios de sincronización de datos. |
Mantener sincronizados los sistemas locales y en la nube, o crear copias de seguridad para la recuperación ante desastres. |
Mejora la fiabilidad de los datos y garantiza su disponibilidad actual en todos los sistemas. |
|
Virtualización de datos |
Permite el acceso y la consulta de datos en tiempo real, sin movimientos ni transformaciones físicas. |
Fuentes de datos dispares donde se necesita acceso en tiempo real, sin la complejidad de la consolidación. |
Consulta de datos en varias bases de datos o API para proporcionar una vista unificada para el análisis sin mover los datos. |
Proporciona vistas unificadas y en tiempo real de los datos de diversas fuentes. |
|
Integración de datos en streaming |
Procesa e integra los datos en tiempo real a medida que se generan a partir de fuentes basadas en eventos. |
Escenarios que requieran conocimientos oportunos, respuestas rápidas o procesamiento de datos de baja latencia. |
Procesar datos de dispositivos IoT, supervisar la actividad de los mercados financieros o analizar flujos de medios sociales en tiempo real. |
Permite tomar decisiones rápidas basadas en información actualizada. |
Las arquitecturas de integración de datos son marcos que determinan cómo se consolidan y gestionan los datos. Estas arquitecturas varían en función del tipo de datos, sus requisitos de almacenamiento y los objetivos empresariales. Veamos las dos más comunes.
La integración de almacenes de datos se centra en centralizar los datos de múltiples fuentes en un repositorio estructurado y unificado para el análisis y la elaboración de informes. En esta arquitectura, los datos de varios sistemas operativos se extraen, transforman y cargan (ETL) en el almacén de datos, donde se limpian y organizan.
Un almacén de datos te permite realizar análisis e informes en profundidad para garantizar que todas las unidades de negocio acceden a información precisa y actualizada. Esta arquitectura es ideal para los datos estructurados y cuando la elaboración de informes exhaustivos es un objetivo clave.
Recomiendo seguir el excelentecurso Conceptos de Almacenamiento de Datos para aprender más sobre esta arquitectura omnipresente.
Los lagos de datos son muy adecuados para los equipos que trabajan con diversos tipos y formatos de datos. Están diseñados para almacenar grandes volúmenes de datos no estructurados, semiestructurados y estructurados en su forma bruta. Los lagos de datos integran datos de diversas fuentes (por ejemplo, dispositivos IoT, redes sociales y sistemas operativos) sin necesidad de procesarlos o transformarlos antes.
Esta arquitectura es beneficiosa para los casos de uso que manejan big data, ya que permite un almacenamiento flexible y la capacidad de aplicar análisis avanzados, aprendizaje automático o análisis exploratorio.
He aquí una tabla comparativa que destaca las diferencias entre los almacenes de datos y los lagos de datos en términos de integración de datos:
|
Función |
Almacén de datos |
Lago de datos |
|
Tipos de datos |
Datos estructurados (por ejemplo, tablas relacionales). |
Datos estructurados, semiestructurados (por ejemplo, JSON, XML) y no estructurados (por ejemplo, audio, vídeo, registros). |
|
Esquema de datos |
Esquema en escritura: Los datos deben ajustarse a un esquema predefinido. |
Esquema en lectura: Los datos pueden ingerirse en bruto y estructurarse cuando se leen. |
|
Proceso ETL/ELT |
Requiere procesos ETL complejos para limpiar y transformar los datos antes de cargarlos. |
Permite ELT: Los datos en bruto se ingieren y las transformaciones se producen durante el análisis o la recuperación. |
|
Fuentes de datos |
Normalmente se integra con sistemas transaccionales, CRM, ERP, etc. |
Admite la integración desde diversas fuentes, como dispositivos IoT, redes sociales y sistemas de big data. |
|
Volumen de datos |
Diseñado para manejar pequeños volúmenes de datos limpios y de alta calidad. |
Maneja volúmenes masivos de datos brutos y diversos a escala. |
|
Herramientas de integración |
Herramientas ETL especializadas como Informatica, Talend o dbt. |
Herramientas de big data como Apache Spark, Kafka, Flume y marcos ELT. |
|
Latencia |
Se centra en las consultas de baja latencia para la inteligencia empresarial. |
A menudo prioriza la ingestión de datos de alto rendimiento sobre las respuestas de consulta de baja latencia. |
|
Gobernanza de datos |
Estricta gobernanza de datos con controles de calidad de datos bien definidos. |
Gobernanza flexible, pero requiere herramientas adicionales para una calidad de datos sólida y un seguimiento del linaje. |
|
Datos en tiempo real |
Menos adecuado para la integración de datos en tiempo real. |
Admite la ingesta y el flujo de datos en tiempo real. |
|
Formatos de datos |
Se basa en formatos tabulares (por ejemplo, CSV, Excel, tablas SQL). |
Admite formatos variados, como Parquet, Avro, ORC, archivos de texto y multimedia. |
La integración de datos ofrece muchas ventajas, pero no está exenta de dificultades. Parallevar a cabo esta hazaña con eficacia y eficiencia, debes saber cómo superar estos retos.
Uno de los principales retos a los que se enfrentan las empresas en la integración de datos es garantizar su calidad.
Cuando los datos proceden de fuentes múltiples y dispares, a menudo son incoherentes, faltan o son incorrectos. Estos problemas pueden dar lugar a análisis inexactos y a una toma de decisiones errónea. Para superarlo, los equipos deben implantar procesos de limpieza de datos que los validen, normalicen y corrijan antes de integrarlos. Esto puede implicar establecer comprobaciones automatizadas de la calidad de los datos, utilizar herramientas de perfilado de datos y aplicar reglas de transformación para garantizar la coherencia en todas las fuentes de datos.
A medida que nos adentramos en la era de la IA, la calidad de los datos es más importante que nunca. Ahora es el momento de aprender máse sobre ello realizando el curso Introducción a la Calidad de Datos.
Otro reto en la integración de datos es tratar con varios formatos de datos en diferentes sistemas.
Los datos pueden venir en formatos JSON, XML, CSV o propietarios, cada uno con diferentes esquemas o modelos de datos. Integrar datos tan diversos requiere herramientas y técnicas para transformar y mapear los datos desde su formato original a una estructura común y utilizable.
Soluciones como la transformación de datos y el mapeo de esquemas ayudan a normalizar los datos.
A medida que crecen los volúmenes de datos, la escalabilidad se convierte en una preocupación crítica en la integración. Las grandes cantidades de datos, las exigencias de integración en tiempo real y la creciente complejidad de las fuentes de datos pueden poner a prueba los sistemas tradicionales de integración de datos.
Para hacer frente a los retos de la escalabilidad, puedes aprovechar las plataformas en la nube, la informática distribuida y las modernas tecnologías de integración que pueden gestionar las crecientes necesidades de datos.
Mantener la seguridad de los datos y la conformidad is un reto importante, especialmente cuando se integran datos sensibles o regulados. Los procesos de integración de datos deben proteger los datos durante su almacenamiento, transferencia y acceso, para evitar usos no autorizados o infracciones.
Las organizaciones deben implantar controles de encriptación y acceso y cumplir la normativa. Al dar prioridad a las medidas de seguridad y a los protocolos de cumplimiento, puedes mitigar el riesgo de violación de datos y garantizar que éstos cumplen las normas del sector.
Exploremos algunas de las herramientas de integración de datos más populares y potentes de la actualidad. Cada uno se adapta a diferentes entornos empresariales y necesidades de gestión de datos.
Apache NiFi fue creado por la Fundación del Software Apache en 2014. Es una herramienta de código abierto diseñada para automatizar el flujo de datos entre sistemas. NiFi proporciona una interfaz de arrastrar y soltar fácil de usar para construir canalizaciones de datos y admite una amplia gama de formatos de datos.
Las empresas que necesitan que los datos se muevan sin problemas entre sistemas en tiempo real encontrarán esta herramienta especialmente beneficiosa. Es muy adecuado para sectores como la sanidad y las finanzas, donde los datos fluyen constantemente y deben procesarse con rapidez, con retrasos o errores mínimos.
Fivetran, fundada en 2013, es una solución ELT (Extraer, Cargar, Transformar) basada en la nube que automatiza el movimiento y la sincronización de datos en varias plataformas. Su principal objetivo es simplificar el proceso ETL, permitiendo a los usuarios configurar canalizaciones de datos que se adaptan automáticamente a los cambios de esquema.
Esta herramienta es especialmente útil para las empresas que pasan a arquitecturas de datos basadas en la nube o que amplían sus prácticas de gestión de datos sin grandes gastos generales. Como Fivetran gestiona las transformaciones de datos después de la carga (ELT), es ideal para las organizaciones que priorizan la simplicidad y la escalabilidad en sus entornos en la nube.
Microsoft Azure Data Factory es un servicio de integración de datos basado en la nubelanzado por Microsoft en 2015. Permite a los usuarios crear, programar y orquestar flujos de trabajo de datos en varios entornos en la nube y locales.
Azure Data Factory se integra bien con el conjunto de servicios en la nube de Microsoft y proporciona una amplia gama de conectores para integrar datos de distintas fuentes. Esta herramienta es ideal para las empresas que ya están en el ecosistema de Microsoft Azure, especialmente las que necesitan una integración de datos compleja en entornos de nube híbrida o sistemas locales.
Consulta el tutorial sobre cómo crear tu primera canalización de Azure Data Factory.
Fundada en 1993, Informatica es una plataforma líder de integración de datos a nivel empresarial. Conocida por sus sólidas capacidades de transformación de datos, Informatica admite procesos complejos de integración de datos y es ampliamente utilizada por grandes organizaciones que manejan volúmenes importantes de datos.
La plataforma ofrece herramientas que facilitan la migración, la gobernanza y la limpieza de datos en múltiples sistemas. Informatica es ideal en los sectores de las finanzas, la sanidad y las telecomunicaciones, donde la conformidad, la transformación y la alta disponibilidad de los datos son fundamentales.
Si quieres saber más, consulta nuestra lista de las mejores herramientas ETL.
En este artículo, hemos explorado los aspectos fundamentales de la integración de datos, desde sus componentes y técnicas hasta las herramientas y arquitecturas que la impulsan.
Hemos visto cómo la integración de datos ayuda a las organizaciones a consolidar fuentes de datos dispares en un formato unificado y accesible para garantizar que puedan tomar decisiones con confianza. Además, hemos hablado de los retos a los que se enfrentan los equipos durante la integración y hemos tocado algunas herramientas clave para ayudarte a empezar con la integración de datos y hacer que el camino sea más suave.
Para profundizar en tu comprensión de la integración de datos, te recomiendo que explores los siguientes recursos:
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
14 min
