
Course
Introduction to Data Engineering
4 hr
127.6K
Wondering what the best way to integrate data is? In this section, we will explore the various techniques used to integrate data. Each technique is suited to different types of environments and requirements. Let’s take a look at them!
ETL is the traditional data integration technique. It involves three key steps:
In the extraction phase, data is collected from different systems. The transformation phase ensures the data is cleaned, standardized, and formatted to fit a consistent schema. Finally, in the load phase, the transformed data is stored in the target system, where it becomes available for analysis and reporting.
ETL is best used when you need to integrate and structure data from multiple, diverse sources for reporting, analytics, or business intelligence. It’s ideal for organizations with structured data that require thorough cleaning and transformation before analysis.
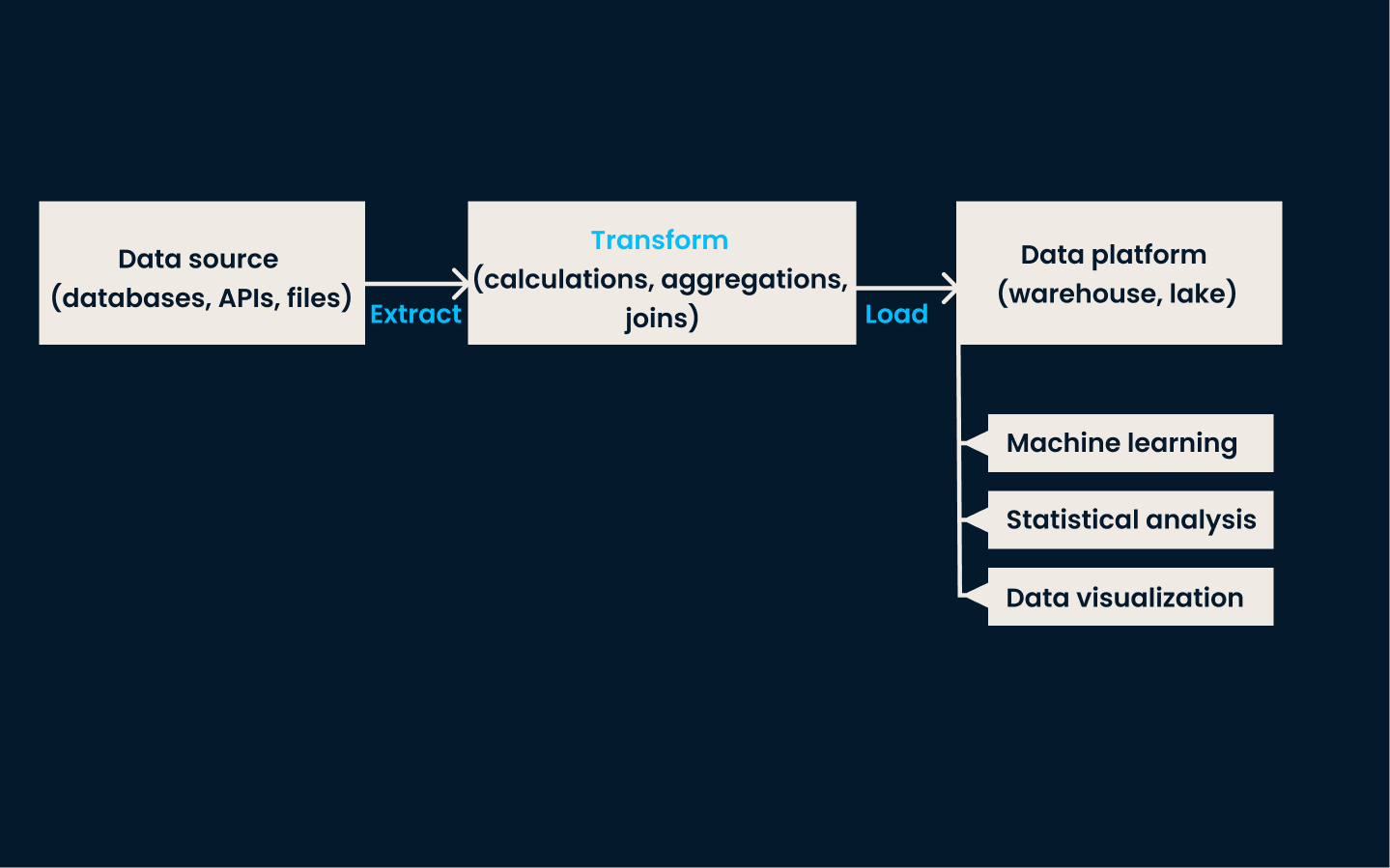
Example ETL architecture
This approach is especially effective in traditional on-premises environments with moderate data volume and transformation complexity. ETL is the go-to method if your data needs batch processing and regularly scheduled updates.
ELT is a variation of ETL designed to handle the large datasets typically found in cloud environments. In this approach, data is first extracted and loaded into a target system, and only after the data is loaded does the transformation take place.
In other words, ELT is best for organizations that need to load vast amounts of raw data quickly and transform it later. This grants them more flexibility in how and when data transformations are applied. If your business works with unstructured data or needs near-real-time transformation, ELT is better than traditional ETL.
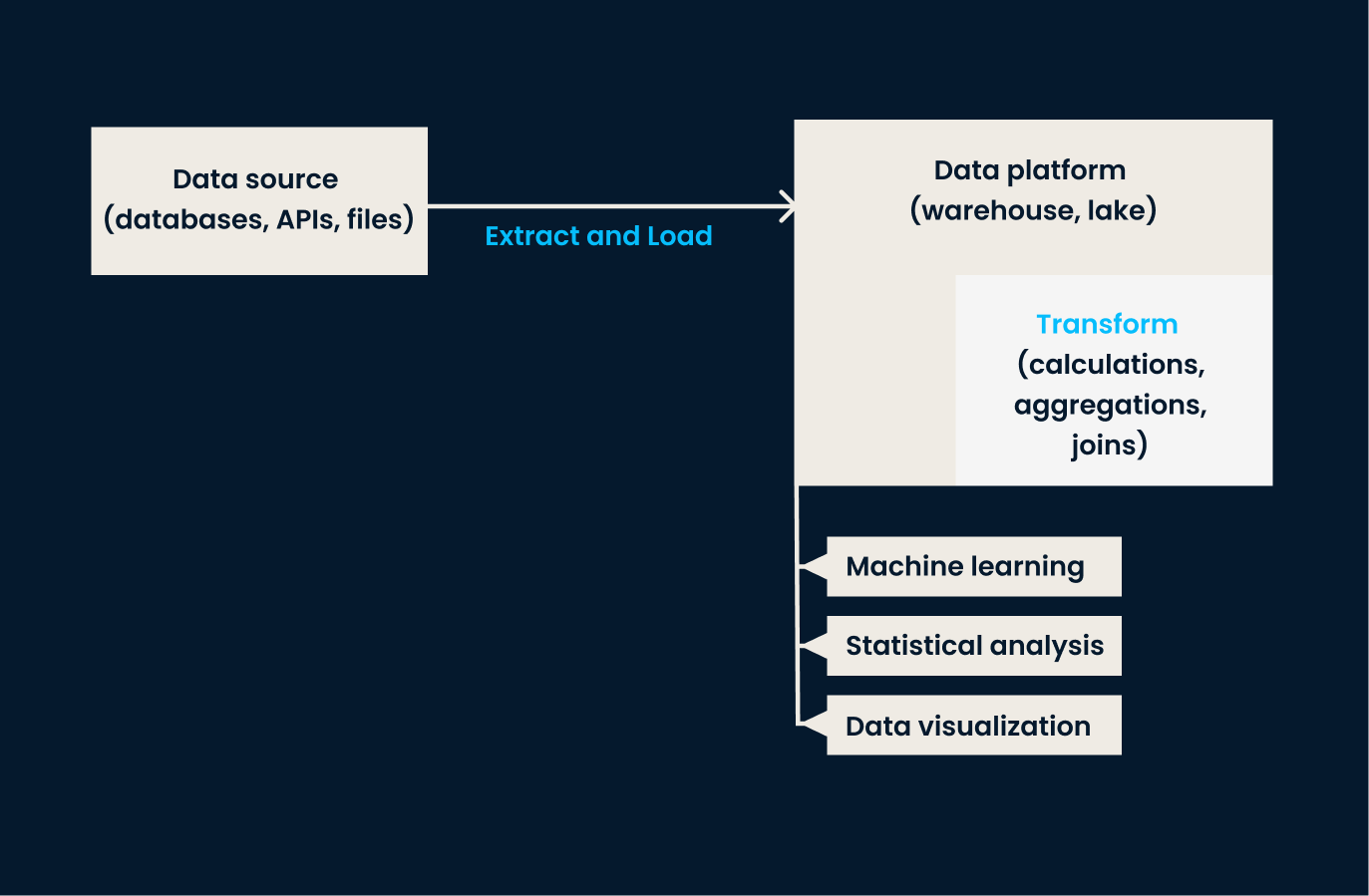
Example ELT architecture
If you’d like to learn more about these traditional data engineering processes, I recommend checking out the ETL and ELT in Python course!
Data replication is the process of copying data from one system to another. This technique ensures that all systems work with the same data and helps keep different environments in sync.
Replication can be done in real time or at scheduled intervals, depending on specific needs. Its main benefit is that it improves data availability and reliability, ensuring that critical systems have consistent access to the most current information.
This approach is most suitable for scenarios where high availability and consistency across systems are critical. It is commonly used for backup, disaster recovery, and data synchronization across different environments, such as between on-premises and cloud systems.
Data replication is also valuable for applications that require immediate access to identical copies of data in multiple locations. If your organization needs to ensure data is available and up-to-date across different platforms or regions, replication is an excellent option.
Take into account that, technically, the replication option is usually only available for traditional databases to create exact copies of the original data.
Data virtualization is a more modern approach to data integration. It enables users to access and query data in real time without moving or physically transforming it.
Instead of consolidating data into a single repository, this technique creates a virtual layer that connects to various data sources and provides a unified view of data from multiple systems, making the data easier to access and analyze.
This technique works best when real-time data access is more important than physically moving or consolidating data. It’s ideal for organizations with disparate data sources that want to create a unified view without the complexity and delay of traditional ETL processes.
Data virtualization is a powerful solution if your use case requires on-demand access to multiple data sources, such as when querying across various databases or APIs.
Streaming data integration handles real-time data processing from event-driven sources (e.g., IoT devices, social media platforms, financial markets, etc.). Instead of waiting for batch processes, this technique allows data to be ingested and integrated as soon as it is generated.
This approach is used for scenarios where timely insights and rapid responses are needed. Streaming data integration is optimal if your organization needs to make rapid decisions based on the most up-to-date information or if latency is a concern.
Check out the Streaming Concepts course to learn more about this technique.
The following table summarizes the different techniques we just discussed:
|
Technique |
Description |
Best suited for |
Example use cases |
Benefits |
|
ETL (Extract, Transform, Load) |
Traditional method involving extraction, transformation, and loading of data into a target system. |
Structured data requiring thorough cleaning and transformation for reporting, analytics, or BI. |
Consolidating data from multiple sources into a data warehouse for batch processing and scheduled updates. |
Ensures clean, standardized, and structured data ready for analysis. |
|
ELT (Extract, Load, Transform) |
Modern variation of ETL where data is transformed after loading into the target system. |
Large datasets in cloud environments, unstructured data, or near-real-time transformation needs. |
Loading raw data into a cloud-based data lake or data warehouse for flexible, on-demand transformation. |
Provides flexibility in when and how transformations are applied. |
|
Data Replication |
Copies data from one system to another to maintain consistency and availability across environments. |
High availability and consistency requirements, disaster recovery, and data synchronization scenarios. |
Keeping on-premises and cloud systems in sync or creating backup copies for disaster recovery. |
Improves data reliability and ensures current data availability across systems. |
|
Data Virtualization |
Enables real-time access and querying of data without physical movement or transformation. |
Disparate data sources where real-time access is needed, without the complexity of consolidation. |
Querying data across multiple databases or APIs to provide a unified view for analytics without moving data. |
Provides real-time, unified views of data across diverse sources. |
|
Streaming Data Integration |
Processes and integrates data in real time as it is generated from event-driven sources. |
Scenarios requiring timely insights, rapid responses, or low-latency data processing. |
Processing data from IoT devices, monitoring financial market activity, or analyzing social media streams in real time. |
Enables rapid decision-making based on up-to-date information. |
Data integration architectures are frameworks that determine how data is consolidated and managed. These architectures vary depending on the type of data, its storage requirements, and the business objectives. Let’s check out the two most common.
Data warehouse integration focuses on centralizing data from multiple sources into a structured, unified repository for analytics and reporting. In this architecture, data from various operational systems is extracted, transformed, and loaded (ETL) into the data warehouse, where it’s cleaned and organized.
A data warehouse allows you to perform in-depth analysis and reporting to ensure all business units access accurate, up-to-date information. This architecture is ideal for structured data and when comprehensive reporting is a key objective.
I recommend taking the excellent Data Warehousing Concepts course to learn more about this ubiquitous architecture.
Data lakes are well-suited for teams that work with diverse data types and formats. They are designed to store large volumes of unstructured, semi-structured, and structured data in their raw form. Data lakes integrate data from various sources (e.g., IoT devices, social media, and operational systems) without needing to be processed or transformed first.
This architecture is beneficial for use cases that handle big data, as it allows flexible storage and the ability to apply advanced analytics, machine learning, or exploratory analysis.
Here’s a comparison table highlighting the differences between data warehouses and data lakes in terms of data integration:
|
Feature |
Data Warehouse |
Data Lake |
|
Data types |
Structured data (e.g., relational tables). |
Structured, semi-structured (e.g., JSON, XML), and unstructured data (e.g., audio, video, logs). |
|
Data schema |
Schema-on-write: Data must conform to a predefined schema. |
Schema-on-read: Data can be ingested in raw form and structured when read. |
|
ETL/ELT process |
Requires complex ETL processes to clean and transform data before loading. |
Allows ELT: Raw data is ingested and transformations occur during analysis or retrieval. |
|
Data sources |
Typically integrates with transactional systems, CRM, ERP, etc. |
Supports integration from diverse sources, including IoT devices, social media, and big data systems. |
|
Data volume |
Designed to handle smaller volumes of clean, high-quality data. |
Handles massive volumes of raw and diverse data at scale. |
|
Integration tools |
Specialized ETL tools like Informatica, Talend, or dbt. |
Big data tools like Apache Spark, Kafka, Flume, and ELT frameworks. |
|
Latency |
Focuses on low-latency queries for business intelligence. |
Often prioritizes high-throughput data ingestion over low-latency query responses. |
|
Data governance |
Strict data governance with well-defined data quality checks. |
Flexible governance, but requires additional tools for robust data quality and lineage tracking. |
|
Real-time Data |
Less suitable for real-time data integration. |
Supports real-time data ingestion and streaming. |
|
Data formats |
Relies on tabular formats (e.g., CSV, Excel, SQL tables). |
Supports varied formats, including Parquet, Avro, ORC, text files, and multimedia. |
Data integration offers many benefits, but it’s not without its challenges. To implement this feat effectively and efficiently, you must know how to overcome these challenges.
One of the primary challenges businesses face in data integration is ensuring data quality.
When data comes from multiple, disparate sources, it is often inconsistent, missing, or incorrect. These issues can lead to inaccurate analyses and flawed decision-making. To overcome this, teams must implement data-cleaning processes that validate, standardize, and correct the data before it is integrated. This can involve setting up automated data quality checks, using data profiling tools, and applying transformation rules to ensure consistency across all data sources.
As we move into the AI era, data quality is more important than ever. Now is the time to learn more about it by taking the Introduction to Data Quality course.
Another challenge in data integration is dealing with various data formats across different systems.
Data may come in JSON, XML, CSV, or proprietary formats, each with different schemas or data models. Integrating such diverse data requires tools and techniques to transform and map data from its original format into a common, usable structure.
Solutions like data transformation and schema mapping help to standardize data.
As data volumes grow, scalability becomes a critical concern in integration. Large amounts of data, real-time integration demands, and the increasing complexity of data sources can strain traditional data integration systems.
To tackle scalability challenges, you can leverage cloud platforms, distributed computing, and modern integration technologies that can handle growing data needs.
Maintaining data security and compliance is a significant challenge – especially when integrating sensitive or regulated data. Data integration processes must protect data during storage, transfer, and access to prevent unauthorized use or breaches.
Organizations must implement encryption and access controls and adhere to regulations. By prioritizing security measures and compliance protocols, you can mitigate the risk of data breaches and ensure data meets industry standards.
Let’s explore some of the most popular and powerful data integration tools available today. Each is suited to different business environments and data management needs.
Apache NiFi was created by the Apache Software Foundation in 2014. It’s an open-source tool designed to automate the flow of data between systems. NiFi provides a user-friendly, drag-and-drop interface for building data pipelines and supports a wide range of data formats.
Businesses that require data to be moved seamlessly between systems in real time will find this tool particularly beneficial. It’s well suited for industries like healthcare and finance, where data flows constantly and needs to be processed quickly, with minimal delays or errors.
Fivetran, founded in 2013, is a cloud-based ELT (Extract, Load, Transform) solution that automates data movement and synchronization across various platforms. Its main focus is simplifying the ETL process by allowing users to set up data pipelines that automatically adapt to schema changes.
This tool is particularly useful for businesses moving to cloud-based data architectures or scaling their data management practices without significant overhead. Since Fivetran handles data transformations post-load (ELT), it’s ideal for organizations prioritizing simplicity and scalability in their cloud environments.
Microsoft Azure Data Factory is a cloud-based data integration service launched by Microsoft in 2015. It enables users to create, schedule, and orchestrate data workflows across various cloud and on-premises environments.
Azure Data Factory integrates well with Microsoft’s suite of cloud services and provides a broad range of connectors for integrating data from different sources. This tool is ideal for enterprises already in the Microsoft Azure ecosystem, especially those requiring complex data integration across hybrid cloud environments or on-premises systems.
Check out the tutorial on building your first Azure Data Factory pipeline.
Established in 1993, Informatica is a leading enterprise-level data integration platform. Known for its robust data transformation capabilities, Informatica supports complex data integration processes and is widely used by large organizations handling significant volumes of data.
The platform offers tools that facilitate data migration, governance, and cleansing across multiple systems. Informatica is ideal in finance, healthcare, and telecommunications industries, where data compliance, transformation, and high availability are critical.
If you’d like to explore more, check out our list of the best ETL tools.
In this article, we’ve explored the core aspects of data integration, from its components and techniques to the tools and architectures that drive it.
We’ve seen how data integration helps organizations consolidate disparate data sources into a unified, accessible format to ensure they can confidently make decisions. Additionally, we’ve discussed the challenges teams face during integration and touched on some key tools to help you get started with data integration and make the ride smoother.
To further deepen your understanding of data integration, I recommend exploring the following resources:
Learn more about data engineering with these courses!
Course
Course
Course
blog
Austin Chia
7 min
blog
Joleen Bothma
11 min
blog
Srujana Maddula
9 min
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
15 min
Tutorial
Amberle McKee

