
Cours
Introduction au data engineering
4 h
127.6K
Vous vous demandez quelle est la meilleure façon d'intégrer les données ? Dans cette section, nous allons explorer les différentes techniques utilisées pour intégrer les données. Chaque technique est adaptée à différents types d'environnements et d'exigences. Jetons-y un coup d'œil !
L'ETL est la technique traditionnelle d'intégration des données. Elle comporte trois étapes clés :
Dans la phase d'extraction, les données sont collectées à partir de différents systèmes. La phase de transformation garantit que les données sont nettoyées, normalisées et formatées pour correspondre à un schéma cohérent. Enfin, lors de la phase de chargement, les données transformées sont stockées dans le système cible, où elles deviennent disponibles pour l'analyse et l'établissement de rapports.
L'ETL est utilisé de préférence lorsque vous devez intégrer et structurer des données provenant de sources multiples et diverses à des fins de reporting, d'analyse ou de business intelligence. Il est idéal pour les organisations disposant de données structurées qui nécessitent un nettoyage et une transformation approfondis avant d'être analysées.
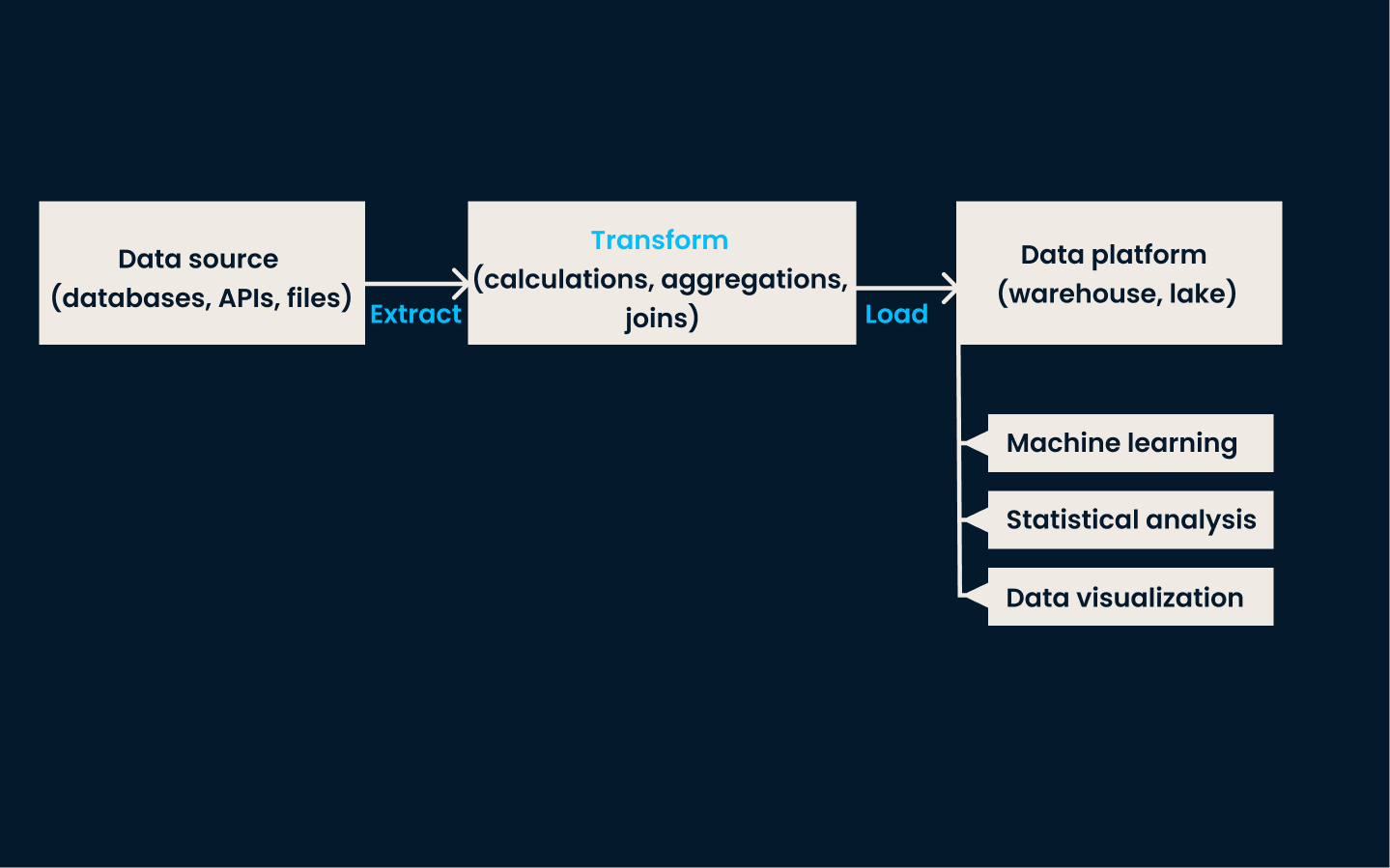
Exemple d'architecture ETL
Cette approche est particulièrement efficace dans les environnements traditionnels sur site avec un volume de données modéré et une complexité de transformation. L'ETL est la méthode à privilégier si vos données nécessitent un traitement par lots et des mises à jour régulières.
L'ELT est une variante de l'ETL conçue pour gérer les grands ensembles de données que l'on trouve généralement dans les environnements cloud. Dans cette approche, les données sont d'abord extraites et chargées dans un système cible, et ce n'est qu'après le chargement des données que la transformation a lieu.
En d'autres termes, l'ELT convient mieux aux organisations qui ont besoin de charger rapidement de grandes quantités de données brutes et de les transformer par la suite. Ils bénéficient ainsi d'une plus grande souplesse quant à la manière et au moment d'appliquer les transformations de données. Si votre entreprise travaille avec des données non structurées ou a besoin d'une transformation en temps quasi réel, l'ELT est préférable à l'ETL traditionnel.
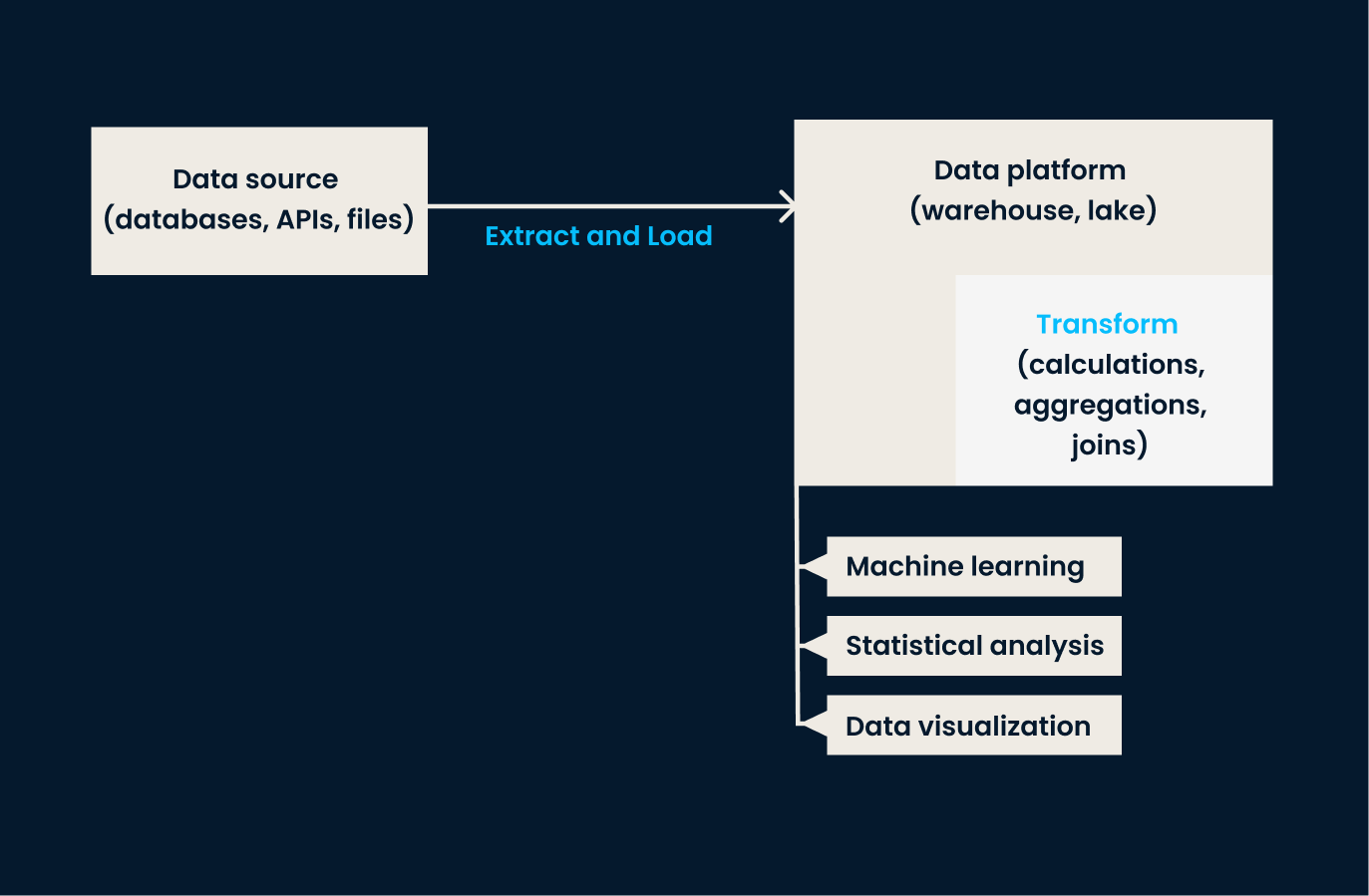
Exemple d'architecture d'un ELT
Si vous souhaitez en savoir plus sur ces processus traditionnels d'ingénierie des données, je vous recommande de consulter le cours ETL et ELT en Python!
La réplication des données est le processus de copie des données d'un système à un autre. Cette technique permet de s'assurer que tous les systèmes travaillent avec les mêmes données et de maintenir la synchronisation entre les différents environnements.
La réplication peut se faire en temps réel ou à intervalles programmés, en fonction des besoins spécifiques. Son principal avantage est d'améliorer la disponibilité et la fiabilité des données, en veillant à ce que les systèmes critiques aient un accès constant aux informations les plus récentes.
Cette approche est particulièrement adaptée aux scénarios dans lesquels la haute disponibilité et la cohérence entre les systèmes sont essentielles. Il est couramment utilisé pour la sauvegarde, la reprise après sinistre et la synchronisation des données entre différents environnements, par exemple entre des systèmes sur site et des systèmes cloud.
La réplication des données est également utile pour les applications qui nécessitent un accès immédiat à des copies identiques des données à plusieurs endroits. Si votre organisation doit s'assurer que les données sont disponibles et à jour sur différentes plateformes ou dans différentes régions, la réplication est une excellente option.
Tenez compte du fait que, techniquement, l'option de réplication n'est généralement disponible que pour les bases de données traditionnelles afin de créer des copies exactes des données d'origine.
La virtualisation des données est une approche plus moderne de l'intégration des données. Il permet aux utilisateurs d'accéder aux données et de les interroger en temps réel sans les déplacer ou les transformer physiquement.
Au lieu de consolider les données dans un référentiel unique, cette technique crée une couche virtuelle qui se connecte à diverses sources de données et fournit une vue unifiée des données provenant de plusieurs systèmes, ce qui facilite l'accès aux données et leur analyse.
Cette technique est la plus efficace lorsque l'accès aux données en temps réel est plus important que le déplacement physique ou la consolidation des données. Il est idéal pour les organisations disposant de sources de données disparates et souhaitant créer une vue unifiée sans la complexité et les délais des processus ETL traditionnels.
La virtualisation des données est une solution puissante si votre cas d'utilisation nécessite un accès à la demande à plusieurs sources de données, par exemple lorsque vous effectuez des requêtes dans différentes bases de données ou API.
L'intégration de données en continu permet de traiter des données en temps réel à partir de sources événementielles (par exemple, dispositifs IoT, plateformes de médias sociaux, marchés financiers, etc.) Au lieu d'attendre les processus par lots, cette technique permet d'ingérer et d'intégrer les données dès qu'elles sont générées.
Cette approche est utilisée dans les scénarios où il est nécessaire d'obtenir des informations en temps utile et de réagir rapidement. L'intégration de données en continu est optimale si votre organisation a besoin de prendre des décisions rapides basées sur les informations les plus récentes ou si la latence est un problème.
Consultez le cours Concepts de streaming pour en savoir plus sur cette technique.
Le tableau suivant résume les différentes techniques que nous venons d'aborder :
|
Technique |
Description |
Convient le mieux à |
Exemples de cas d'utilisation |
Avantages |
|
ETL (extraction, transformation, chargement) |
Méthode traditionnelle impliquant l'extraction, la transformation et le chargement de données dans un système cible. |
Données structurées nécessitant un nettoyage et une transformation approfondis pour l'établissement de rapports, l'analyse ou la BI. |
Consolidation des données provenant de sources multiples dans un entrepôt de données en vue d'un traitement par lots et de mises à jour programmées. |
Veille à ce que les données soient propres, normalisées et structurées, prêtes à être analysées. |
|
ELT (Extract, Load, Transform) |
Variante moderne de l'ETL où les données sont transformées après avoir été chargées dans le système cible. |
Des ensembles de données volumineux dans des environnements cloud, des données non structurées ou des besoins de transformation en temps quasi réel. |
Chargement des données brutes dans un lac de données ou un entrepôt de données basé sur le cloud pour une transformation flexible et à la demande. |
Permet de déterminer avec souplesse quand et comment les transformations sont appliquées. |
|
Réplication des données |
Copie les données d'un système à l'autre pour maintenir la cohérence et la disponibilité entre les environnements. |
Exigences en matière de haute disponibilité et de cohérence, reprise après sinistre et scénarios de synchronisation des données. |
Maintenir la synchronisation des systèmes sur site et dans le cloud ou créer des copies de sauvegarde pour la reprise après sinistre. |
Améliore la fiabilité des données et garantit la disponibilité des données actuelles dans tous les systèmes. |
|
Virtualisation des données |
Permet d'accéder aux données en temps réel et de les interroger sans déplacement ni transformation physique. |
Des sources de données disparates pour lesquelles un accès en temps réel est nécessaire, sans la complexité de la consolidation. |
Interroger les données dans plusieurs bases de données ou API afin d'obtenir une vue unifiée pour l'analyse sans déplacer les données. |
Fournit en temps réel des vues unifiées des données provenant de diverses sources. |
|
Intégration de données en continu |
Traite et intègre les données en temps réel au fur et à mesure qu'elles sont générées par des sources événementielles. |
Scénarios nécessitant des informations en temps opportun, des réponses rapides ou un traitement des données à faible latence. |
Traiter les données des appareils IoT, surveiller l'activité des marchés financiers ou analyser les flux des médias sociaux en temps réel. |
Permet une prise de décision rapide sur la base d'informations actualisées. |
Les architectures d'intégration des données sont des cadres qui déterminent la manière dont les données sont consolidées et gérées. Ces architectures varient en fonction du type de données, des exigences en matière de stockage et des objectifs de l'entreprise. Voyons les deux plus courantes.
L'intégration des entrepôts de données vise à centraliser les données provenant de sources multiples dans un référentiel structuré et unifié, à des fins d'analyse et de reporting. Dans cette architecture, les données provenant de divers systèmes opérationnels sont extraites, transformées et chargées (ETL) dans l'entrepôt de données, où elles sont nettoyées et organisées.
Un entrepôt de données vous permet d'effectuer des analyses et des rapports approfondis afin de garantir que toutes les unités commerciales ont accès à des informations précises et actualisées. Cette architecture est idéale pour les données structurées et lorsque l'établissement de rapports complets est un objectif clé.
Je vous recommande de suivre l'excellentcours Data Warehousing Concepts pour en savoir plus sur cette architecture omniprésente .
Les lacs de données sont bien adaptés aux équipes qui travaillent avec différents types et formats de données. Ils sont conçus pour stocker de grands volumes de données non structurées, semi-structurées et structurées sous leur forme brute. Les lacs de données intègrent des données provenant de diverses sources (par exemple, les appareils IoT, les médias sociaux et les systèmes opérationnels) sans avoir besoin d'être traitées ou transformées au préalable.
Cette architecture est bénéfique pour les cas d'utilisation qui traitent des données volumineuses, car elle permet un stockage flexible et la possibilité d'appliquer des analyses avancées, l'apprentissage automatique ou l'analyse exploratoire.
Voici un tableau comparatif mettant en évidence les différences entre les entrepôts de données et les lacs de données en termes d'intégration des données :
|
Fonctionnalité |
Entrepôt de données |
Lac de données |
|
Types de données |
Données structurées (tableaux relationnels, par exemple). |
Données structurées, semi-structurées (par exemple, JSON, XML) et non structurées (par exemple, audio, vidéo, journaux). |
|
Schéma de données |
Schema-on-write : Les données doivent être conformes à un schéma prédéfini. |
Schema-on-read : Les données peuvent être ingérées sous forme brute et structurées lorsqu'elles sont lues. |
|
Processus ETL/ELT |
Nécessite des processus ETL complexes pour nettoyer et transformer les données avant leur chargement. |
Permet l'ELT : Les données brutes sont ingérées et des transformations ont lieu lors de l'analyse ou de la recherche. |
|
Sources de données |
S'intègre généralement aux systèmes transactionnels, CRM, ERP, etc. |
Prend en charge l'intégration de diverses sources, y compris les appareils IoT, les médias sociaux et les systèmes de big data. |
|
Volume de données |
Conçu pour traiter de petits volumes de données propres et de haute qualité. |
Traite des volumes massifs de données brutes et diverses à l'échelle. |
|
Outils d'intégration |
Outils ETL spécialisés comme Informatica, Talend ou dbt. |
Des outils de big data comme Apache Spark, Kafka, Flume, et des frameworks ELT. |
|
Temps de latence |
Se concentre sur les requêtes à faible latence pour l'intelligence économique. |
Il donne souvent la priorité à l'ingestion de données à haut débit plutôt qu'aux réponses aux requêtes à faible latence. |
|
Gouvernance des données |
Une gouvernance stricte des données avec des contrôles de qualité bien définis. |
Gouvernance flexible, mais nécessite des outils supplémentaires pour une qualité de données robuste et un suivi du cursus. |
|
Données en temps réel |
Moins adapté à l'intégration de données en temps réel. |
Prise en charge de l'ingestion et de la diffusion de données en temps réel. |
|
Formats de données |
S'appuie sur des formats de tableaux (par exemple, CSV, Excel, tableaux SQL). |
Prend en charge divers formats, y compris Parquet, Avro, ORC, les fichiers texte et les multimédias. |
L'intégration des données offre de nombreux avantages, mais elle n'est pas sans poser de problèmes. Pourréaliser cette prouesse de manière efficace et efficiente, vous devez savoir comment surmonter ces défis.
L'un des principaux défis auxquels les entreprises sont confrontées en matière d'intégration des données est d'assurer la qualité des données.
Lorsque les données proviennent de sources multiples et disparates, elles sont souvent incohérentes, manquantes ou incorrectes. Ces problèmes peuvent conduire à des analyses inexactes et à des prises de décision erronées. Pour y remédier, les équipes doivent mettre en œuvre des processus de nettoyage des données qui les valident, les normalisent et les corrigent avant de les intégrer. Cela peut impliquer la mise en place de contrôles automatisés de la qualité des données, l'utilisation d'outils de profilage des données et l'application de règles de transformation pour garantir la cohérence entre toutes les sources de données.
Alors que nous entrons dans l'ère de l'IA, la qualité des données est plus importante que jamais. C'est le moment d'en savoir pluse en suivant le cours Introduction à la qualité des données.
Un autre défi de l'intégration des données est la gestion des différents formats de données dans les différents systèmes.
Les données peuvent être fournies dans des formats JSON, XML, CSV ou propriétaires, chacun avec des schémas ou des modèles de données différents. L'intégration de données aussi diverses nécessite des outils et des techniques pour transformer et cartographier les données à partir de leur format d'origine dans une structure commune et utilisable.
Des solutions telles que la transformation des données et le mappage des schémas permettent de normaliser les données.
Avec l'augmentation des volumes de données, l'évolutivité devient une préoccupation essentielle en matière d'intégration. Les grandes quantités de données, les demandes d'intégration en temps réel et la complexité croissante des sources de données peuvent mettre à rude épreuve les systèmes d'intégration de données traditionnels.
Pour relever les défis de l'évolutivité, vous pouvez tirer parti des plateformes cloud, de l'informatique distribuée et des technologies d'intégration modernes qui peuvent gérer les besoins croissants en matière de données.
Le maintien de la sécurité et de la conformité des données iest un défi de taille, surtout lorsqu'il s'agit d'intégrer des données sensibles ou réglementées. Les processus d'intégration des données doivent protéger les données lors du stockage, du transfert et de l'accès afin d'éviter toute utilisation non autorisée ou toute violation.
Les organisations doivent mettre en place des contrôles de cryptage et d'accès et se conformer aux réglementations. En donnant la priorité aux mesures de sécurité et aux protocoles de conformité, vous pouvez réduire le risque de violation des données et vous assurer que les données sont conformes aux normes du secteur.
Examinons quelques-uns des outils d'intégration de données les plus populaires et les plus puissants disponibles aujourd'hui. Chacun d'entre eux est adapté à des environnements professionnels et à des besoins de gestion de données différents.
Apache NiFi a été créé par la Apache Software Foundation en 2014. Il s'agit d'un outil open-source conçu pour automatiser le flux de données entre les systèmes. NiFi offre une interface conviviale de type "glisser-déposer" pour la construction de pipelines de données et prend en charge un large éventail de formats de données.
Les entreprises qui ont besoin que les données soient transférées de manière transparente entre les systèmes en temps réel trouveront cet outil particulièrement utile. Il convient parfaitement à des secteurs tels que les soins de santé et la finance, où les données circulent constamment et doivent être traitées rapidement, avec un minimum de retards ou d'erreurs.
Fivetran, fondée en 2013, est une solution ELT (Extract, Load, Transform) basée sur le cloud qui automatise le mouvement et la synchronisation des données sur diverses plateformes. Son objectif principal est de simplifier le processus ETL en permettant aux utilisateurs de mettre en place des pipelines de données qui s'adaptent automatiquement aux changements de schémas.
Cet outil est particulièrement utile pour les entreprises qui passent à des architectures de données basées sur le cloud ou qui mettent à l'échelle leurs pratiques de gestion des données sans frais généraux importants. Fivetran gérant les transformations de données post-chargement (ELT), il est idéal pour les entreprises qui privilégient la simplicité et l'évolutivité dans leurs environnements cloud.
Microsoft Azure Data Factory est un service d'intégration de données basé sur le cloudlancé par Microsoft en 2015. Elle permet aux utilisateurs de créer, de planifier et d'orchestrer des flux de données dans divers environnements cloud et sur site.
Azure Data Factory s'intègre bien à la suite de services cloud de Microsoft et fournit une large gamme de connecteurs pour intégrer des données provenant de différentes sources. Cet outil est idéal pour les entreprises déjà présentes dans l'écosystème Microsoft Azure, en particulier celles qui ont besoin d'une intégration de données complexe entre des environnements cloud hybrides ou des systèmes sur site.
Consultez le tutoriel sur la création de votre premier pipeline Azure Data Factory.
Fondée en 1993, Informatica est une plate-forme d'intégration de données de premier plan pour les entreprises. Connu pour ses capacités de transformation des données, Informatica prend en charge des processus d'intégration de données complexes et est largement utilisé par les grandes entreprises traitant d'importants volumes de données.
La plateforme offre des outils qui facilitent la migration, la gouvernance et le nettoyage des données entre plusieurs systèmes. Informatica est idéal pour les secteurs de la finance, de la santé et des télécommunications, où la conformité, la transformation et la haute disponibilité des données sont essentielles.
Si vous souhaitez en savoir plus, consultez notre liste des meilleurs outils ETL.
Dans cet article, nous avons exploré les principaux aspects de l'intégration des données, de ses composants et techniques aux outils et architectures qui la sous-tendent.
Nous avons vu comment l'intégration des données aide les organisations à consolider des sources de données disparates dans un format unifié et accessible pour leur permettre de prendre des décisions en toute confiance. En outre, nous avons abordé les défis auxquels les équipes sont confrontées lors de l'intégration et évoqué quelques outils clés pour vous aider à démarrer l'intégration des données et à la rendre plus fluide.
Pour approfondir votre compréhension de l'intégration des données, je vous recommande d'explorer les ressources suivantes :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours