
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Du fragst dich, wie du Daten am besten integrieren kannst? In diesem Abschnitt werden wir die verschiedenen Techniken zur Datenintegration untersuchen. Jede Technik ist für unterschiedliche Umgebungen und Anforderungen geeignet. Schauen wir sie uns an!
ETL ist die traditionelle Datenintegrationstechnik. Es umfasst drei wichtige Schritte:
In der Extraktionsphase werden Daten aus verschiedenen Systemen gesammelt. Die Transformationsphase stellt sicher, dass die Daten bereinigt, standardisiert und so formatiert werden, dass sie in ein einheitliches Schema passen. In der Ladephase schließlich werden die umgewandelten Daten im Zielsystem gespeichert, wo sie für Analysen und Berichte zur Verfügung stehen.
ETL wird am besten eingesetzt, wenn du Daten aus mehreren, unterschiedlichen Quellen für Berichte, Analysen oder Business Intelligence integrieren und strukturieren musst. Es ist ideal für Unternehmen mit strukturierten Daten, die vor der Analyse gründlich bereinigt und umgewandelt werden müssen.
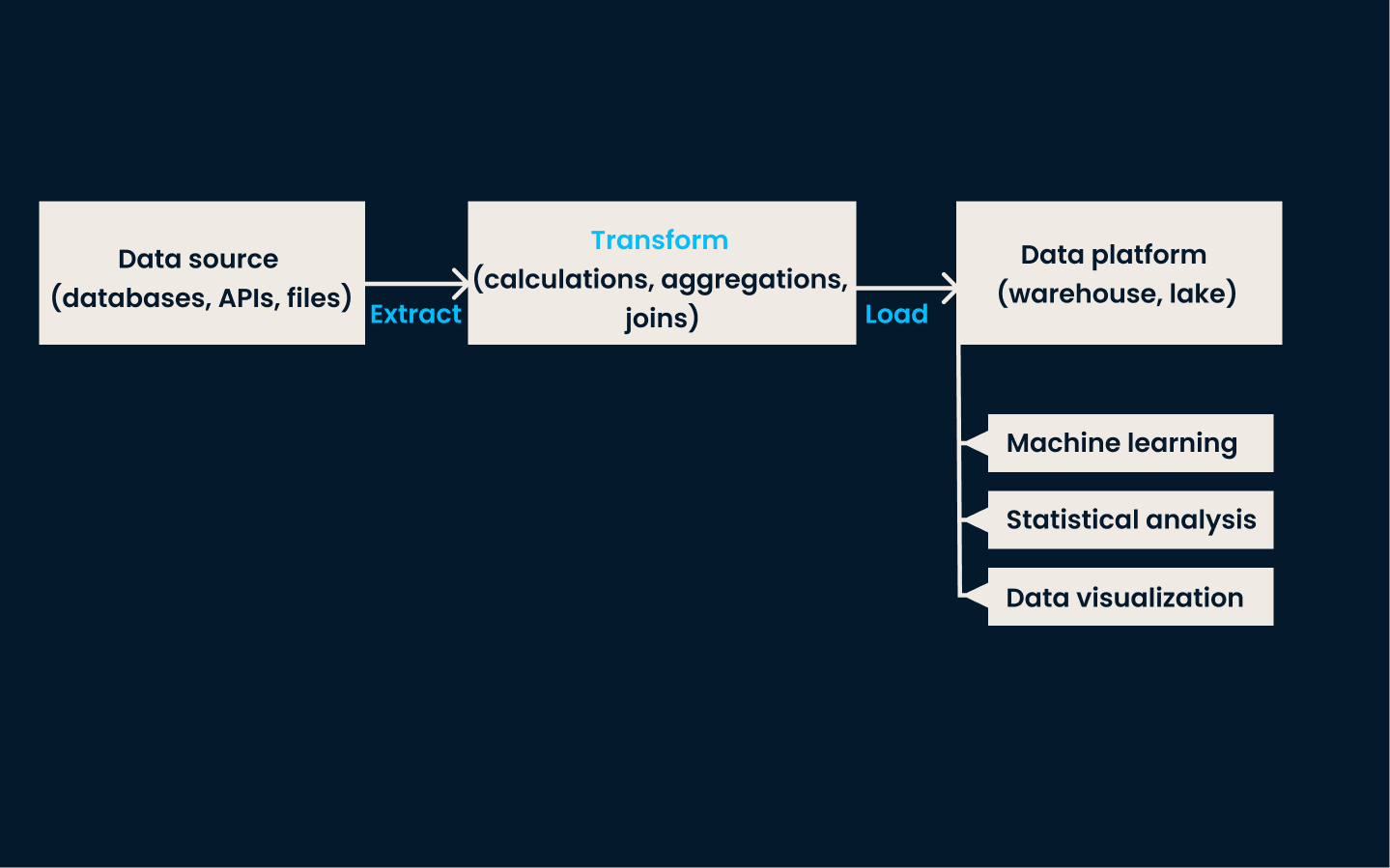
Beispiel ETL-Architektur
Dieser Ansatz ist besonders effektiv in traditionellen On-Premises-Umgebungen mit mäßigem Datenvolumen und mittlerer Komplexität der Transformation. ETL ist die beste Methode, wenn deine Daten stapelweise verarbeitet und regelmäßig aktualisiert werden müssen.
ELT ist eine Variante von ETL, die für den Umgang mit großen Datenmengen entwickelt wurde, die typischerweise in Cloud-Umgebungen vorkommen. Bei diesem Ansatz werden die Daten zunächst extrahiert und in ein Zielsystem geladen. Erst nachdem die Daten geladen wurden, erfolgt die Transformation.
Mit anderen Worten: ELT eignet sich am besten für Unternehmen, die große Mengen an Rohdaten schnell laden und später umwandeln müssen. Das gibt ihnen mehr Flexibilität bei der Art und Weise, wie und wann die Daten umgewandelt werden. Wenn dein Unternehmen mit unstrukturierten Daten arbeitet oder diese nahezu in Echtzeit umwandeln muss, ist ELT besser als herkömmliche ETL.
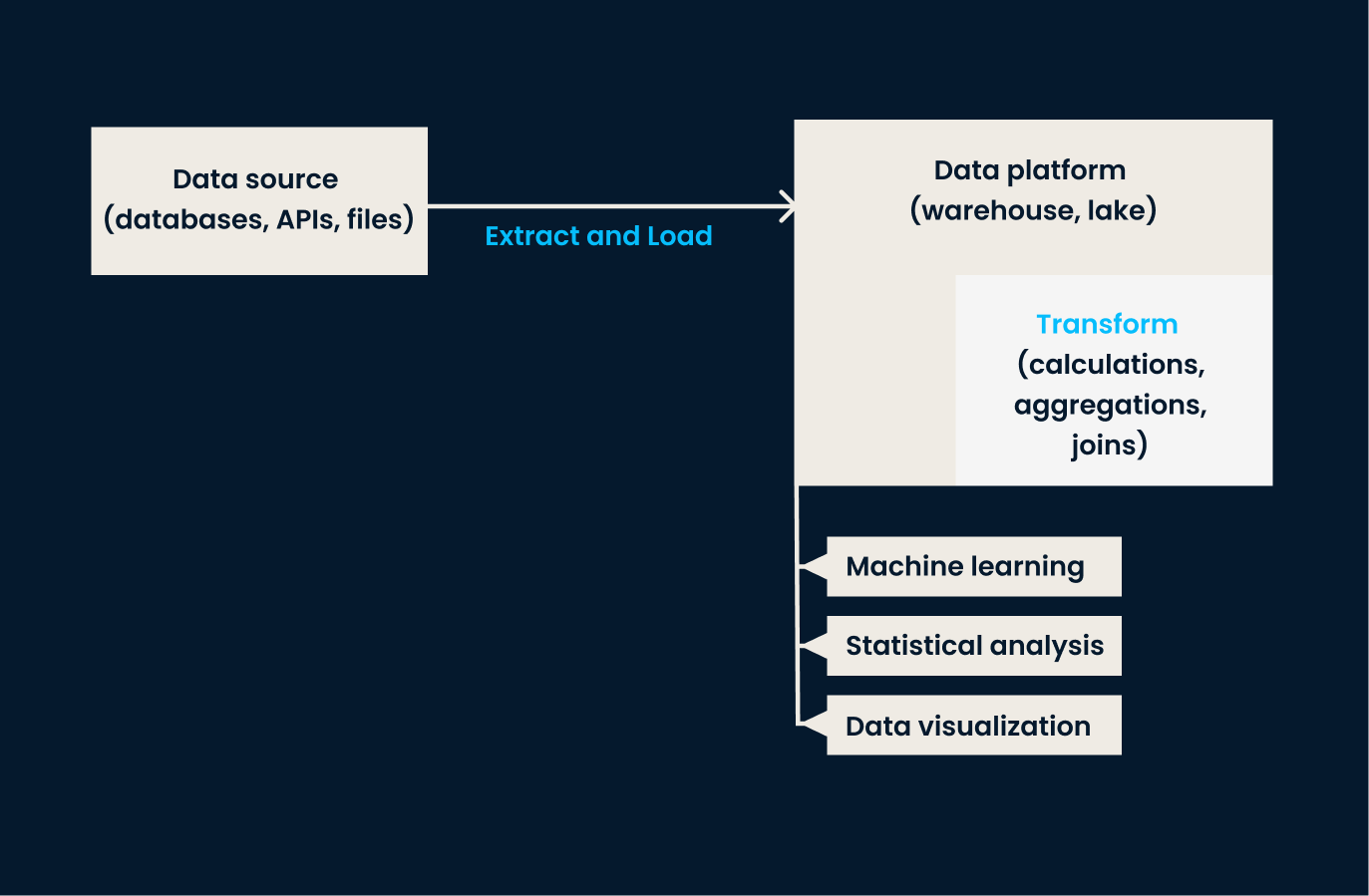
Beispiel ELT-Architektur
Wenn du mehr über diese traditionellen Data-Engineering-Prozesse erfahren möchtest, empfehle ich dir den Kurs ETL und ELT in Python!
Unter Datenreplikation versteht man das Kopieren von Daten von einem System auf ein anderes. Diese Technik stellt sicher, dass alle Systeme mit denselben Daten arbeiten und hilft dabei, verschiedene Umgebungen synchron zu halten.
Die Replikation kann je nach Bedarf in Echtzeit oder in regelmäßigen Abständen erfolgen. Sein Hauptvorteil ist, dass er die Datenverfügbarkeit und -zuverlässigkeit verbessert und sicherstellt, dass kritische Systeme stets auf die aktuellsten Informationen zugreifen können.
Dieser Ansatz eignet sich am besten für Szenarien, in denen hohe Verfügbarkeit und Konsistenz zwischen den Systemen entscheidend sind. Sie wird häufig für Backups, Disaster Recovery und die Synchronisierung von Daten in verschiedenen Umgebungen, z. B. zwischen On-Premises- und Cloud-Systemen, verwendet.
Die Datenreplikation ist auch für Anwendungen nützlich, die sofortigen Zugriff auf identische Kopien von Daten an verschiedenen Orten benötigen. Wenn dein Unternehmen sicherstellen muss, dass die Daten über verschiedene Plattformen oder Regionen hinweg verfügbar und aktuell sind, ist die Replikation eine hervorragende Option.
Bedenke, dass die Replikationsoption technisch gesehen normalerweise nur für traditionelle Datenbanken verfügbar ist, um exakte Kopien der Originaldaten zu erstellen.
Datenvirtualisierung ist ein modernerer Ansatz zur Datenintegration. Sie ermöglicht den Zugriff und die Abfrage von Daten in Echtzeit, ohne sie zu bewegen oder physisch zu verändern.
Anstatt die Daten in einem einzigen Repository zu konsolidieren, schafft diese Technik eine virtuelle Ebene, die eine Verbindung zu verschiedenen Datenquellen herstellt und eine einheitliche Sicht auf die Daten aus mehreren Systemen bietet, was den Zugriff und die Analyse der Daten erleichtert.
Diese Technik funktioniert am besten, wenn der Datenzugriff in Echtzeit wichtiger ist als die physische Verschiebung oder Konsolidierung von Daten. Es ist ideal für Unternehmen mit unterschiedlichen Datenquellen, die eine einheitliche Ansicht ohne die Komplexität und Verzögerung herkömmlicher ETL-Prozesse erstellen wollen.
Datenvirtualisierung ist eine leistungsstarke Lösung, wenn dein Anwendungsfall einen On-Demand-Zugriff auf mehrere Datenquellen erfordert, z. B. bei Abfragen über verschiedene Datenbanken oder APIs.
Die Integration von Streaming-Daten ermöglicht die Verarbeitung von Echtzeitdaten aus ereignisgesteuerten Quellen (z. B. IoT-Geräte, Social-Media-Plattformen, Finanzmärkte usw.). Anstatt auf Batch-Prozesse zu warten, ermöglicht diese Technik die Aufnahme und Integration von Daten, sobald sie erzeugt werden.
Dieser Ansatz wird für Szenarien verwendet, in denen zeitnahe Erkenntnisse und schnelle Reaktionen erforderlich sind. Die Integration von Streaming-Daten ist optimal, wenn dein Unternehmen schnelle Entscheidungen auf der Grundlage der aktuellsten Informationen treffen muss oder wenn Latenzzeiten ein Problem darstellen.
Schau dir den Kurs Streaming-Konzepte an, um mehr über diese Technik zu erfahren.
Die folgende Tabelle fasst die verschiedenen Techniken zusammen, die wir gerade besprochen haben:
|
Technique |
Beschreibung |
Am besten geeignet für |
Beispielhafte Anwendungsfälle |
Vorteile |
|
ETL (Extrahieren, Transformieren, Laden) |
Traditionelle Methode, die das Extrahieren, Umwandeln und Laden von Daten in ein Zielsystem beinhaltet. |
Strukturierte Daten, die für Berichte, Analysen oder BI gründlich bereinigt und umgewandelt werden müssen. |
Konsolidierung von Daten aus verschiedenen Quellen in einem Data Warehouse für Stapelverarbeitung und geplante Aktualisierungen. |
Sorgt für saubere, standardisierte und strukturierte Daten, die für die Analyse bereit sind. |
|
ELT (Extrahieren, Laden, Transformieren) |
Moderne Variante von ETL, bei der die Daten nach dem Laden in das Zielsystem transformiert werden. |
Große Datenmengen in Cloud-Umgebungen, unstrukturierte Daten oder Umwandlungsbedarf in Echtzeit. |
Laden von Rohdaten in einen Cloud-basierten Data Lake oder ein Data Warehouse zur flexiblen, bedarfsgerechten Transformation. |
Bietet Flexibilität, wann und wie Transformationen angewendet werden. |
|
Datenreplikation |
Kopiert Daten von einem System in ein anderes, um die Konsistenz und Verfügbarkeit in verschiedenen Umgebungen zu gewährleisten. |
Hochverfügbarkeits- und Konsistenzanforderungen, Disaster Recovery und Datensynchronisationsszenarien. |
Synchronisierung von On-Premises- und Cloud-Systemen oder Erstellung von Sicherungskopien für die Notfallwiederherstellung. |
Verbessert die Zuverlässigkeit der Daten und stellt die aktuelle Verfügbarkeit der Daten in allen Systemen sicher. |
|
Datenvirtualisierung |
Ermöglicht den Echtzeitzugriff und die Abfrage von Daten ohne physische Bewegung oder Umwandlung. |
Unterschiedliche Datenquellen, auf die in Echtzeit zugegriffen werden muss, ohne die Komplexität einer Konsolidierung. |
Abfrage von Daten über mehrere Datenbanken oder APIs hinweg, um eine einheitliche Ansicht für Analysen zu erhalten, ohne Daten zu verschieben. |
Bietet in Echtzeit eine einheitliche Sicht auf Daten aus verschiedenen Quellen. |
|
Integration von Streaming-Daten |
Verarbeitet und integriert Daten in Echtzeit, wenn sie aus ereignisgesteuerten Quellen generiert werden. |
Szenarien, die zeitnahe Erkenntnisse, schnelle Reaktionen oder eine Datenverarbeitung mit geringer Latenz erfordern. |
Die Verarbeitung von Daten aus IoT-Geräten, die Überwachung von Finanzmarktaktivitäten oder die Analyse von Social Media Streams in Echtzeit. |
Ermöglicht schnelle Entscheidungen auf der Grundlage aktueller Informationen. |
Datenintegrationsarchitekturen sind Rahmenwerke, die festlegen, wie Daten konsolidiert und verwaltet werden. Diese Architekturen variieren je nach Art der Daten, ihren Speicheranforderungen und den Geschäftszielen. Schauen wir uns die beiden häufigsten an.
Bei der Data-Warehouse-Integration liegt der Schwerpunkt auf der Zentralisierung von Daten aus verschiedenen Quellen in einem strukturierten, einheitlichen Repository für Analysen und Berichte. Bei dieser Architektur werden Daten aus verschiedenen operativen Systemen extrahiert, transformiert und in das Data Warehouse geladen (ETL), wo sie bereinigt und organisiert werden.
Mit einem Data Warehouse kannst du eingehende Analysen und Berichte erstellen, um sicherzustellen, dass alle Geschäftsbereiche auf genaue, aktuelle Informationen zugreifen können. Diese Architektur ist ideal für strukturierte Daten und wenn umfassende Berichterstattung ein wichtiges Ziel ist.
Ich empfehle, den ausgezeichnetenKurs Data Warehousing Concepts zu besuchen, um mehr über diese allgegenwärtige Architektur zu erfahren.
Data Lakes sind gut geeignet für Teams, die mit verschiedenen Datentypen und -formaten arbeiten. Sie sind dafür ausgelegt, große Mengen an unstrukturierten, halbstrukturierten und strukturierten Daten in ihrer Rohform zu speichern. Data Lakes integrieren Daten aus verschiedenen Quellen (z. B. IoT-Geräte, soziale Medien und betriebliche Systeme), ohne dass sie erst verarbeitet oder umgewandelt werden müssen.
Diese Architektur ist vorteilhaft für Anwendungsfälle, in denen große Datenmengen verarbeitet werden, da sie eine flexible Speicherung und die Möglichkeit bietet, erweiterte Analysen, maschinelles Lernen oder explorative Analysen anzuwenden.
Die folgende Tabelle zeigt die Unterschiede zwischen Data Warehouses und Data Lakes in Bezug auf die Datenintegration auf:
|
Feature |
Data Warehouse |
Datensee |
|
Datentypen |
Strukturierte Daten (z. B. relationale Tabellen). |
Strukturierte, halbstrukturierte (z. B. JSON, XML) und unstrukturierte Daten (z. B. Audio, Video, Protokolle). |
|
Datenschema |
Schema-on-write: Die Daten müssen einem vordefinierten Schema entsprechen. |
Schema-auf-Lese: Die Daten können in Rohform aufgenommen und beim Lesen strukturiert werden. |
|
ETL/ELT-Prozess |
Erfordert komplexe ETL-Prozesse, um Daten vor dem Laden zu bereinigen und umzuwandeln. |
Erlaubt ELT: Die Rohdaten werden eingelesen und bei der Analyse oder beim Abruf umgewandelt. |
|
Datenquellen |
Typischerweise wird es mit Transaktionssystemen, CRM, ERP usw. integriert. |
Unterstützt die Integration von verschiedenen Quellen, einschließlich IoT-Geräten, sozialen Medien und Big-Data-Systemen. |
|
Datenvolumen |
Entwickelt, um kleinere Mengen an sauberen, hochwertigen Daten zu verarbeiten. |
Verarbeitet riesige Mengen an rohen und vielfältigen Daten in großem Umfang. |
|
Integrationstools |
Spezialisierte ETL-Tools wie Informatica, Talend oder dbt. |
Big Data-Tools wie Apache Spark, Kafka, Flume und ELT-Frameworks. |
|
Latenz |
Konzentriert sich auf Abfragen mit geringer Latenz für Business Intelligence. |
Oft hat die Datenaufnahme mit hohem Durchsatz Vorrang vor der Beantwortung von Abfragen mit geringer Latenz. |
|
Datenverwaltung |
Strenge Datenverwaltung mit gut definierten Datenqualitätsprüfungen. |
Flexible Governance, erfordert aber zusätzliche Tools für robuste Datenqualität und Lernpfade. |
|
Daten in Echtzeit |
Weniger geeignet für die Integration von Echtzeitdaten. |
Unterstützt Dateneingabe und Streaming in Echtzeit. |
|
Datenformate |
Verlässt sich auf Tabellenformate (z. B. CSV, Excel, SQL-Tabellen). |
Unterstützt verschiedene Formate, darunter Parkett, Avro, ORC, Textdateien und Multimedia. |
Die Datenintegration bietet viele Vorteile, aber sie ist nicht ohne Herausforderungen. Umdieses Kunststück effektiv und effizient umzusetzen, musst du wissen, wie du diese Herausforderungen meistern kannst.
Eine der größten Herausforderungen für Unternehmen bei der Datenintegration ist die Sicherstellung der Datenqualität.
Wenn Daten aus verschiedenen, unterschiedlichen Quellen stammen, sind sie oft inkonsistent, fehlen oder sind falsch. Diese Probleme können zu ungenauen Analysen und fehlerhaften Entscheidungen führen. Um dies zu vermeiden, müssen die Teams Datenbereinigungsprozesse implementieren, die die Daten vor der Integration validieren, standardisieren und korrigieren. Dies kann die Einrichtung automatischer Datenqualitätsprüfungen, die Verwendung von Tools zur Datenprofilierung und die Anwendung von Transformationsregeln beinhalten, um die Konsistenz aller Datenquellen sicherzustellen.
Auf dem Weg in das Zeitalter der KI ist die Datenqualität wichtiger denn je. Jetzt ist es an der Zeit, mehre darüber zu erfahren, indem du den Kurs Einführung in die Datenqualität belegst.
Eine weitere Herausforderung bei der Datenintegration ist der Umgang mit verschiedenen Datenformaten in unterschiedlichen Systemen.
Die Daten können in JSON-, XML-, CSV- oder proprietären Formaten vorliegen, die jeweils unterschiedliche Schemata oder Datenmodelle haben. Die Integration solch unterschiedlicher Daten erfordert Werkzeuge und Techniken, um Daten aus ihrem ursprünglichen Format in eine gemeinsame, nutzbare Struktur umzuwandeln und abzubilden.
Lösungen wie Datentransformation und Schema Mapping helfen, Daten zu standardisieren.
Wenn das Datenvolumen wächst, wird die Skalierbarkeit zu einem wichtigen Thema bei der Integration. Große Datenmengen, Integrationsanforderungen in Echtzeit und die zunehmende Komplexität der Datenquellen können herkömmliche Datenintegrationssysteme überfordern.
Um die Herausforderungen der Skalierbarkeit zu bewältigen, kannst du Cloud-Plattformen, verteiltes Computing und moderne Integrationstechnologien nutzen, die den wachsenden Datenbedarf bewältigen können.
Die Aufrechterhaltung von Datensicherheit und Compliance is eine große Herausforderung - vor allem, wenn sensible oder regulierte Daten integriert werden. Datenintegrationsprozesse müssen die Daten während der Speicherung, der Übertragung und des Zugriffs schützen, um eine unbefugte Nutzung oder Verstöße zu verhindern.
Unternehmen müssen Verschlüsselung und Zugangskontrollen einführen und sich an die Vorschriften halten. Indem du Sicherheitsmaßnahmen und Compliance-Protokolle priorisierst, kannst du das Risiko von Datenschutzverletzungen mindern und sicherstellen, dass die Daten den Branchenstandards entsprechen.
Sehen wir uns einige der beliebtesten und leistungsfähigsten Datenintegrationstools an, die heute verfügbar sind. Jede ist für unterschiedliche Geschäftsumgebungen und Datenverwaltungsanforderungen geeignet.
Apache NiFi wurde 2014 von der Apache Software Foundation gegründet. Es ist ein Open-Source-Tool zur Automatisierung des Datenflusses zwischen Systemen. NiFi bietet eine benutzerfreundliche Drag-and-Drop-Oberfläche für den Aufbau von Datenpipelines und unterstützt eine breite Palette von Datenformaten.
Für Unternehmen, die Daten nahtlos und in Echtzeit zwischen verschiedenen Systemen austauschen müssen, ist dieses Tool besonders nützlich. Sie eignet sich gut für Branchen wie das Gesundheits- und Finanzwesen, in denen Daten ständig fließen und schnell verarbeitet werden müssen, ohne dass es zu Verzögerungen oder Fehlern kommt.
Fivetran wurde 2013 gegründet und ist eine cloudbasierte ELT (Extract, Load, Transform)-Lösung, die das Verschieben und Synchronisieren von Daten über verschiedene Plattformen hinweg automatisiert. Sein Hauptaugenmerk liegt auf der Vereinfachung des ETL-Prozesses, indem er es Nutzern ermöglicht, Datenpipelines einzurichten, die sich automatisch an Schemaänderungen anpassen.
Dieses Tool ist besonders nützlich für Unternehmen, die auf Cloud-basierte Datenarchitekturen umsteigen oder ihre Datenmanagementpraktiken ohne großen Aufwand skalieren wollen. Da Fivetran die Datentransformationen nach dem Laden (ELT) übernimmt, ist es ideal für Unternehmen, die Wert auf Einfachheit und Skalierbarkeit in ihren Cloud-Umgebungen legen.
Microsoft Azure Data Factory ist ein Cloud-basierterDatenintegrationsdienst, der 2015 von Microsoft eingeführt wurde. Sie ermöglicht es Nutzern, Daten-Workflows in verschiedenen Cloud- und On-Premises-Umgebungen zu erstellen, zu planen und zu orchestrieren.
Azure Data Factory lässt sich gut in Microsofts Suite von Cloud-Diensten integrieren und bietet eine breite Palette von Konnektoren für die Integration von Daten aus verschiedenen Quellen. Dieses Tool ist ideal für Unternehmen, die bereits im Microsoft Azure-Ökosystem sind, insbesondere für solche, die eine komplexe Datenintegration über hybride Cloud-Umgebungen oder On-Premises-Systeme hinweg benötigen.
Schau dir das Tutorial zum Aufbau deiner ersten Azure Data Factory Pipeline an.
Informatica wurde 1993 gegründet und ist eine führende Plattform für die Datenintegration in Unternehmen. Informatica ist bekannt für seine robusten Datenumwandlungsfunktionen, unterstützt komplexe Datenintegrationsprozesse und wird häufig von großen Unternehmen eingesetzt, die große Datenmengen verarbeiten.
Die Plattform bietet Tools, die die Datenmigration, -verwaltung und -bereinigung über mehrere Systeme hinweg erleichtern. Informatica ist ideal für das Finanzwesen, das Gesundheitswesen und die Telekommunikationsbranche, wo die Einhaltung von Vorschriften, die Umwandlung von Daten und hohe Verfügbarkeit entscheidend sind.
Wenn du mehr erfahren möchtest, sieh dir unsere Liste der besten ETL-Tools an.
In diesem Artikel haben wir uns mit den wichtigsten Aspekten der Datenintegration befasst, von den Komponenten und Techniken bis hin zu den Tools und Architekturen, die sie ermöglichen.
Wir haben gesehen, wie die Datenintegration Unternehmen dabei hilft, unterschiedliche Datenquellen in einem einheitlichen, zugänglichen Format zu konsolidieren, um sicherzustellen, dass sie sichere Entscheidungen treffen können. Außerdem haben wir uns mit den Herausforderungen befasst, denen Teams bei der Integration gegenüberstehen, und einige wichtige Tools vorgestellt, die dir den Einstieg in die Datenintegration erleichtern und für einen reibungsloseren Ablauf sorgen.
Um dein Verständnis von Datenintegration weiter zu vertiefen, empfehle ich dir die folgenden Ressourcen zu lesen:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
