
Curso
Introdução à Engenharia de Dados
4 h
127.6K
Você está se perguntando qual é a melhor maneira de integrar dados? Nesta seção, exploraremos as várias técnicas usadas para integrar dados. Cada técnica é adequada a diferentes tipos de ambientes e requisitos. Vamos dar uma olhada neles!
ETL é a técnica tradicional de integração de dados. Ele envolve três etapas principais:
Na fase de extração, os dados são coletados de diferentes sistemas. A fase de transformação garante que os dados sejam limpos, padronizados e formatados para se adequarem a um esquema consistente. Por fim, na fase de carregamento, os dados transformados são armazenados no sistema de destino, onde ficam disponíveis para análise e geração de relatórios.
O ETL é melhor utilizado quando você precisa integrar e estruturar dados de várias fontes diferentes para geração de relatórios, análises ou business intelligence. É ideal para organizações com dados estruturados que exigem limpeza e transformação completas antes da análise.
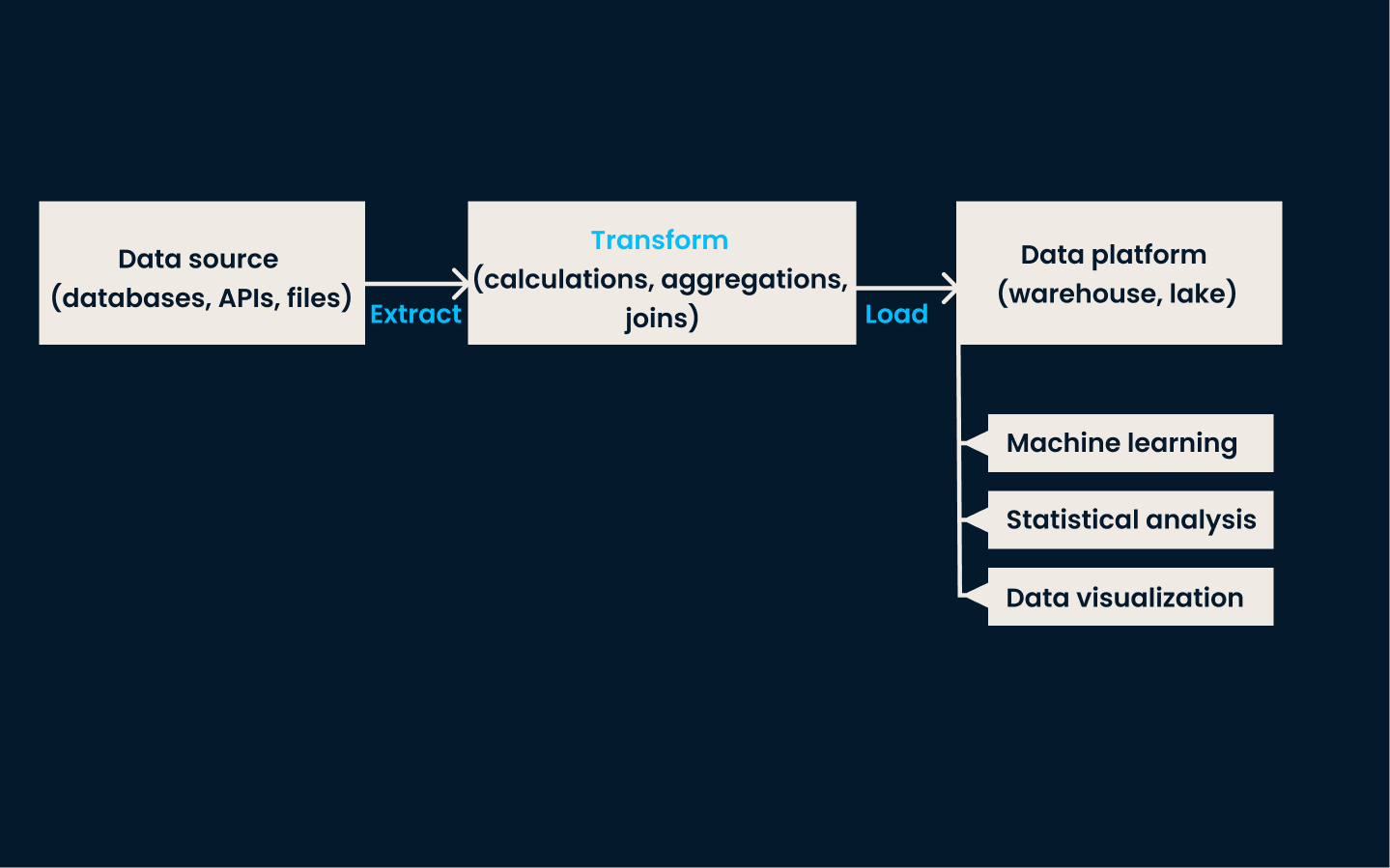
Exemplo de arquitetura ETL
Essa abordagem é especialmente eficaz em ambientes tradicionais no local com volume moderado de dados e complexidade de transformação. O ETL é o método ideal se seus dados precisarem de processamento em lote e atualizações programadas regularmente.
O ELT é uma variação do ETL projetada para lidar com os grandes conjuntos de dados normalmente encontrados em ambientes de nuvem. Nessa abordagem, os dados são primeiro extraídos e carregados em um sistema de destino, e somente depois que os dados são carregados é que ocorre a transformação.
Em outras palavras, o ELT é melhor para organizações que precisam carregar grandes quantidades de dados brutos rapidamente e transformá-los posteriormente. Isso lhes dá mais flexibilidade em como e quando as transformações de dados são aplicadas. Se a sua empresa trabalha com dados não estruturados ou precisa de transformação quase em tempo real, o ELT é melhor do que o ETL tradicional.
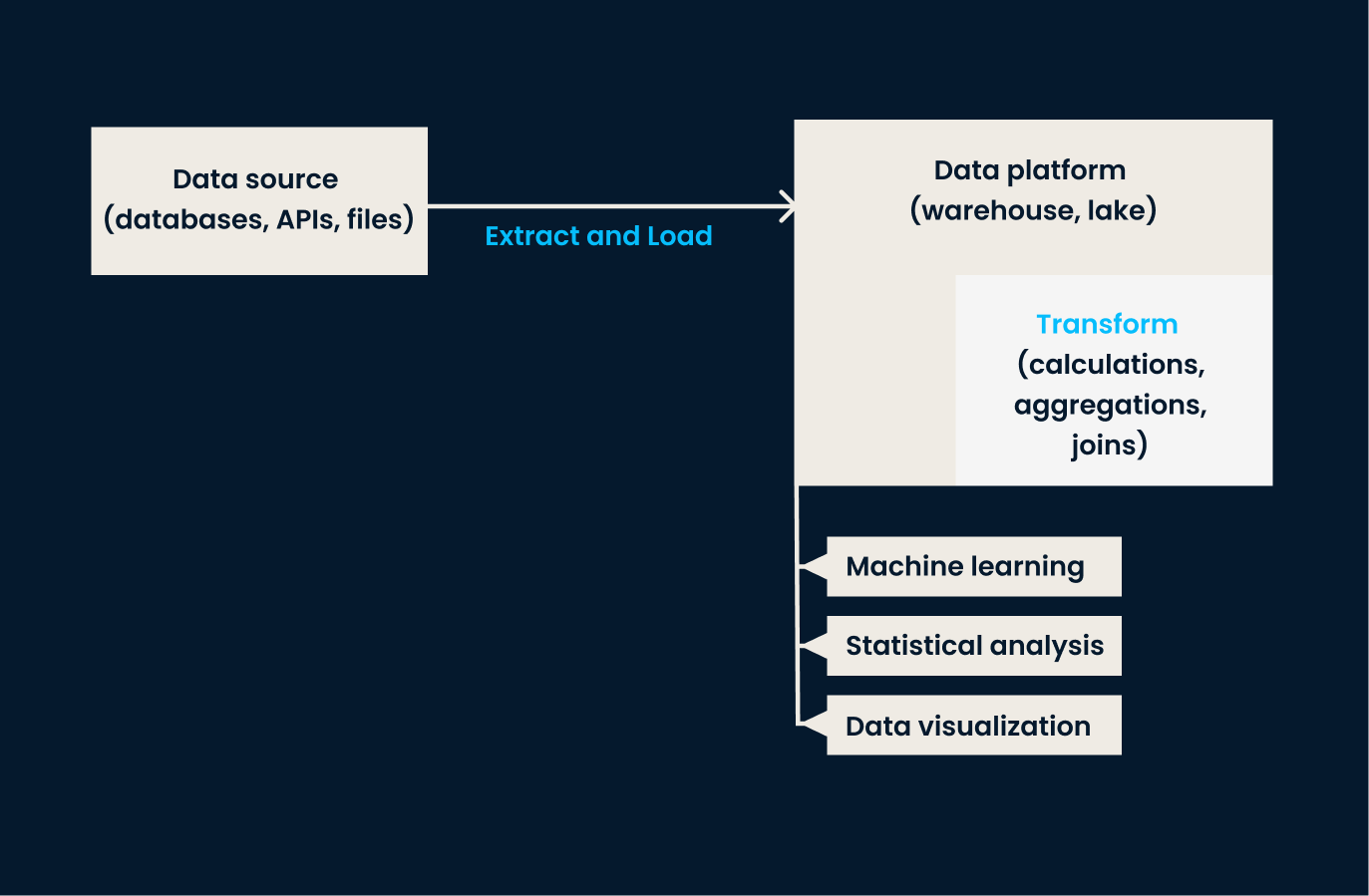
Exemplo de arquitetura ELT
Se você quiser saber mais sobre esses processos tradicionais de engenharia de dados, recomendo que confira o curso ETL e ELT em Python!
A replicação de dados é o processo de cópia de dados de um sistema para outro. Essa técnica garante que todos os sistemas trabalhem com os mesmos dados e ajuda a manter ambientes diferentes em sincronia.
A replicação pode ser feita em tempo real ou em intervalos programados, dependendo das necessidades específicas. Seu principal benefício é melhorar a disponibilidade e a confiabilidade dos dados, garantindo que os sistemas essenciais tenham acesso consistente às informações mais atuais.
Essa abordagem é mais adequada para cenários em que a alta disponibilidade e a consistência entre os sistemas são essenciais. Ele é comumente usado para backup, recuperação de desastres e sincronização de dados em diferentes ambientes, como entre sistemas locais e em nuvem.
A replicação de dados também é valiosa para aplicativos que exigem acesso imediato a cópias idênticas de dados em vários locais. Se a sua organização precisa garantir que os dados estejam disponíveis e atualizados em diferentes plataformas ou regiões, a replicação é uma excelente opção.
Leve em conta que, tecnicamente, a opção de replicação geralmente só está disponível para bancos de dados tradicionais para criar cópias exatas dos dados originais.
A virtualização de dados é uma abordagem mais moderna para a integração de dados. Ele permite que os usuários acessem e consultem dados em tempo real sem movê-los ou transformá-los fisicamente.
Em vez de consolidar os dados em um único repositório, essa técnica cria uma camada virtual que se conecta a várias fontes de dados e fornece uma visão unificada dos dados de vários sistemas, facilitando o acesso e a análise dos dados.
Essa técnica funciona melhor quando o acesso aos dados em tempo real é mais importante do que a movimentação ou consolidação física dos dados. É ideal para organizações com fontes de dados díspares que desejam criar uma visão unificada sem a complexidade e o atraso dos processos tradicionais de ETL.
A virtualização de dados é uma solução eficiente se o seu caso de uso exigir acesso sob demanda a várias fontes de dados, por exemplo, ao consultar vários bancos de dados ou APIs.
A integração de dados de streaming lida com o processamento de dados em tempo real de fontes orientadas por eventos (por exemplo, dispositivos de IoT, plataformas de mídia social, mercados financeiros etc.). Em vez de esperar por processos em lote, essa técnica permite que os dados sejam ingeridos e integrados assim que forem gerados.
Essa abordagem é usada para cenários em que são necessárias percepções oportunas e respostas rápidas. A integração de dados em streaming é ideal se a sua organização precisar tomar decisões rápidas com base nas informações mais atualizadas ou se a latência for uma preocupação.
Confira o curso Conceitos de streaming para saber mais sobre essa técnica.
A tabela a seguir resume as diferentes técnicas que acabamos de discutir:
|
Técnica |
Descrição |
Mais adequado para |
Exemplos de casos de uso |
Benefícios |
|
ETL (Extrair, Transformar, Carregar) |
Método tradicional que envolve extração, transformação e carregamento de dados em um sistema de destino. |
Dados estruturados que exigem limpeza e transformação completas para geração de relatórios, análises ou BI. |
Consolidação de dados de várias fontes em um data warehouse para processamento em lote e atualizações programadas. |
Garante dados limpos, padronizados e estruturados, prontos para análise. |
|
ELT (Extrair, Carregar, Transformar) |
Variação moderna de ETL em que os dados são transformados após o carregamento no sistema de destino. |
Grandes conjuntos de dados em ambientes de nuvem, dados não estruturados ou necessidades de transformação quase em tempo real. |
Carregamento de dados brutos em um data lake ou data warehouse baseado em nuvem para transformação flexível e sob demanda. |
Oferece flexibilidade em quando e como as transformações são aplicadas. |
|
Replicação de dados |
Copia dados de um sistema para outro para manter a consistência e a disponibilidade entre ambientes. |
Requisitos de alta disponibilidade e consistência, recuperação de desastres e cenários de sincronização de dados. |
Manter os sistemas no local e na nuvem sincronizados ou criar cópias de backup para recuperação de desastres. |
Melhora a confiabilidade dos dados e garante a disponibilidade dos dados atuais nos sistemas. |
|
Virtualização de dados |
Permite o acesso e a consulta de dados em tempo real sem movimentação ou transformação física. |
Fontes de dados separadas onde o acesso em tempo real é necessário, sem a complexidade da consolidação. |
Consulta de dados em vários bancos de dados ou APIs para fornecer uma visão unificada para análise sem mover os dados. |
Fornece visualizações unificadas e em tempo real de dados de diversas fontes. |
|
Integração de dados em fluxo contínuo |
Processa e integra dados em tempo real à medida que são gerados a partir de fontes orientadas por eventos. |
Cenários que exigem percepções oportunas, respostas rápidas ou processamento de dados com baixa latência. |
Processar dados de dispositivos IoT, monitorar a atividade do mercado financeiro ou analisar fluxos de mídia social em tempo real. |
Permite que você tome decisões rápidas com base em informações atualizadas. |
As arquiteturas de integração de dados são estruturas que determinam como os dados são consolidados e gerenciados. Essas arquiteturas variam de acordo com o tipo de dados, seus requisitos de armazenamento e os objetivos comerciais. Vamos verificar os dois mais comuns.
A integração do data warehouse concentra-se na centralização de dados de várias fontes em um repositório estruturado e unificado para análises e relatórios. Nessa arquitetura, os dados de vários sistemas operacionais são extraídos, transformados e carregados (ETL) no data warehouse, onde são limpos e organizados.
Um data warehouse permite que você faça análises e relatórios detalhados para garantir que todas as unidades de negócios acessem informações precisas e atualizadas. Essa arquitetura é ideal para dados estruturados e quando a geração de relatórios abrangentes é um objetivo fundamental.
Recomendo quevocê faça o excelentecurso Data Warehousing Concepts (Conceitos de armazenamento de dados ) para saber mais sobre essa arquitetura onipresente.
Os data lakes são adequados para equipes que trabalham com diversos tipos e formatos de dados. Eles são projetados para armazenar grandes volumes de dados não estruturados, semiestruturados e estruturados em sua forma bruta. Os data lakes integram dados de várias fontes (por exemplo, dispositivos de IoT, mídia social e sistemas operacionais) sem a necessidade de serem processados ou transformados primeiro.
Essa arquitetura é benéfica para casos de uso que lidam com big data, pois permite o armazenamento flexível e a capacidade de aplicar análises avançadas, aprendizado de máquina ou análise exploratória.
Aqui está uma tabela de comparação que destaca as diferenças entre data warehouses e data lakes em termos de integração de dados:
|
Recurso |
Armazém de dados |
Lago de dados |
|
Tipos de dados |
Dados estruturados (por exemplo, tabelas relacionais). |
Dados estruturados, semiestruturados (por exemplo, JSON, XML) e não estruturados (por exemplo, áudio, vídeo, registros). |
|
Esquema de dados |
Esquema na gravação: Os dados devem estar em conformidade com um esquema predefinido. |
Esquema em leitura: Os dados podem ser ingeridos na forma bruta e estruturados quando lidos. |
|
Processo ETL/ELT |
Requer processos complexos de ETL para limpar e transformar os dados antes do carregamento. |
Allows ELT: Os dados brutos são ingeridos e as transformações ocorrem durante a análise ou a recuperação. |
|
Fontes de dados |
Normalmente, integra-se a sistemas transacionais, CRM, ERP etc. |
Oferece suporte à integração de diversas fontes, incluindo dispositivos de IoT, mídia social e sistemas de big data. |
|
Volume de dados |
Projetado para lidar com volumes menores de dados limpos e de alta qualidade. |
Lida com grandes volumes de dados brutos e diversos em escala. |
|
Ferramentas de integração |
Ferramentas ETL especializadas, como Informatica, Talend ou dbt. |
Ferramentas de Big Data, como Apache Spark, Kafka, Flume e estruturas ELT. |
|
Latência |
Concentra-se em consultas de baixa latência para business intelligence. |
Frequentemente, prioriza a ingestão de dados de alta taxa de transferência em detrimento de respostas de consulta de baixa latência. |
|
Governança de dados |
Governança de dados rigorosa com verificações de qualidade de dados bem definidas. |
Governança flexível, mas requer ferramentas adicionais para qualidade de dados robusta e rastreamento de linhagem. |
|
Dados em tempo real |
Menos adequado para integração de dados em tempo real. |
Oferece suporte à ingestão e ao streaming de dados em tempo real. |
|
Formatos de dados |
Depende de formatos tabulares (por exemplo, CSV, Excel, tabelas SQL). |
Oferece suporte a vários formatos, incluindo Parquet, Avro, ORC, arquivos de texto e multimídia. |
A integração de dados oferece muitos benefícios, mas não está isenta de desafios. Paraimplementar esse feito de forma eficaz e eficiente, você deve saber como superar esses desafios.
Um dos principais desafios que as empresas enfrentam na integração de dados é garantir a qualidade dos dados.
Quando os dados são provenientes de várias fontes diferentes, geralmente são inconsistentes, ausentes ou incorretos. Esses problemas podem levar a análises imprecisas e a uma tomada de decisão falha. Para superar isso, as equipes devem implementar processos de limpeza de dados que validem, padronizem e corrijam os dados antes de serem integrados. Isso pode envolver a configuração de verificações automatizadas da qualidade dos dados, o uso de ferramentas de perfil de dados e a aplicação de regras de transformação para garantir a consistência em todas as fontes de dados.
À medida que entramos na era da IA, a qualidade dos dados é mais importante do que nunca. Agora é a hora de você aprender mais sobree fazer o curso Introdução à qualidade dos dados.
Outro desafio na integração de dados é lidar com vários formatos de dados em diferentes sistemas.
Os dados podem vir em formatos JSON, XML, CSV ou proprietários, cada um com diferentes esquemas ou modelos de dados. A integração de dados tão diversos requer ferramentas e técnicas para transformar e mapear dados de seu formato original em uma estrutura comum e utilizável.
Soluções como transformação de dados e mapeamento de esquemas ajudam a padronizar os dados.
À medida que os volumes de dados aumentam, a escalabilidade se torna uma preocupação fundamental na integração. Grandes quantidades de dados, demandas de integração em tempo real e a crescente complexidade das fontes de dados podem sobrecarregar os sistemas tradicionais de integração de dados.
Para enfrentar os desafios de escalabilidade, você pode aproveitar as plataformas de nuvem, a computação distribuída e as modernas tecnologias de integração que podem lidar com as crescentes necessidades de dados.
Manter a segurança e a conformidade dos dados emé um desafio significativo, especialmente quando você integra dados confidenciais ou regulamentados. Os processos de integração de dados devem proteger os dados durante o armazenamento, a transferência e o acesso para evitar o uso não autorizado ou violações.
As organizações devem implementar criptografia e controles de acesso e cumprir as normas. Ao priorizar as medidas de segurança e os protocolos de conformidade, você pode reduzir o risco de violações de dados e garantir que os dados atendam aos padrões do setor.
Vamos explorar algumas das mais populares e poderosas ferramentas de integração de dados disponíveis atualmente. Cada um deles é adequado a diferentes ambientes de negócios e necessidades de gerenciamento de dados.
O Apache NiFi foi criado por a Apache Software Foundation em 2014. É uma ferramenta de código aberto projetada para automatizar o fluxo de dados entre sistemas. O NiFi oferece uma interface amigável de arrastar e soltar para a criação de pipelines de dados e suporta uma ampla variedade de formatos de dados.
As empresas que precisam que os dados sejam movidos sem problemas entre sistemas em tempo real acharão essa ferramenta particularmente vantajosa. Ele é adequado para setores como saúde e finanças, em que os dados fluem constantemente e precisam ser processados rapidamente, com o mínimo de atrasos ou erros.
A Fivetran, fundada em 2013, é uma solução ELT (Extract, Load, Transform) baseada em nuvem da que automatiza a movimentação e a sincronização de dados em várias plataformas. Seu foco principal é simplificar o processo de ETL, permitindo que os usuários configurem pipelines de dados que se adaptam automaticamente às alterações de esquema.
Essa ferramenta é particularmente útil para as empresas que estão migrando para arquiteturas de dados baseadas na nuvem ou ampliando suas práticas de gerenciamento de dados sem despesas gerais significativas. Como o Fivetran lida com as transformações de dados pós-carregamento (ELT), ele é ideal para organizações que priorizam a simplicidade e a escalabilidade em seus ambientes de nuvem.
O Microsoft Azure Data Factory é um serviço de integração de dados baseado na nuvem lançado pela Microsoft em 2015. Ele permite que os usuários criem, programem e orquestrem fluxos de trabalho de dados em vários ambientes na nuvem e no local.
O Azure Data Factory se integra bem ao conjunto de serviços em nuvem da Microsoft e oferece uma ampla gama de conectores para integrar dados de diferentes fontes. Essa ferramenta é ideal para empresas que já estão no ecossistema do Microsoft Azure, especialmente aquelas que exigem integração de dados complexa em ambientes de nuvem híbrida ou sistemas locais.
Confira o tutorial sobre como criar seu primeiro pipeline do Azure Data Factory.
Fundada em 1993, a Informatica é uma plataforma líder de integração de dados em nível empresarial. Conhecida por seus recursos robustos de transformação de dados, a Informatica oferece suporte a processos complexos de integração de dados e é amplamente utilizada por grandes organizações que lidam com volumes significativos de dados.
A plataforma oferece ferramentas que facilitam a migração, a governança e a limpeza de dados em vários sistemas. A Informatica é ideal para os setores financeiro, de saúde e de telecomunicações, onde a conformidade, a transformação e a alta disponibilidade dos dados são essenciais.
Se você quiser explorar mais, confira nossa lista das melhores ferramentas de ETL.
Neste artigo, exploramos os principais aspectos da integração de dados, desde seus componentes e técnicas até as ferramentas e arquiteturas que a impulsionam.
Vimos como a integração de dados ajuda as organizações a consolidar fontes de dados diferentes em um formato unificado e acessível para garantir que elas possam tomar decisões com confiança. Além disso, discutimos os desafios que as equipes enfrentam durante a integração e abordamos algumas ferramentas importantes para ajudar você a iniciar a integração de dados e tornar a viagem mais tranquila.
Para aprofundar ainda mais seu conhecimento sobre integração de dados, recomendo que você explore os seguintes recursos:
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
15 min
blog
Joleen Bothma
9 min
