Track
Data Engineer in Python
40 hr
Hadoop and Spark are two of the most prominent frameworks in big data they handle the processing of large-scale data in very different ways. While Hadoop can be credited with democratizing the distributed computing paradigm through a robust storage system called HDFS and a computational model called MapReduce, Spark is changing the game with its in-memory architecture and flexible programming model.
This tutorial dives deep into the differences between Hadoop and Spark, including their architecture, performance, cost considerations, and integrations. By the end, the reader will have a clear understanding of the advantages and disadvantages of each, and the types of use cases where each framework excels; this understanding will help you with strategic decisions as you build your big data solutions.
Before diving into specific details, let’s explore the fundamental concepts and origins of Hadoop and Spark to understand how these powerful frameworks approach big data challenges.

Hadoop is an open-source framework designed to store and process large datasets across clusters of computers. Since its development in 2006, Hadoop has enabled organizations to handle massive data volumes that would overwhelm a single machine. By distributing data across multiple nodes, it not only improves processing capability but also provides redundancy, ensuring system reliability even when individual machines fail.
Key components of the Hadoop framework include:
One of Hadoop’s main advantages is its cost-effectiveness, as it allows organizations to use standard, commodity hardware instead of expensive specialized equipment. This practical approach extends to its processing philosophy as well.
Hadoop’s batch-oriented design excels in scenarios where overall throughput matters more than raw processing speed, making it particularly valuable for historical data analysis and complex ETL (Extract, Transform, Load) operations that don’t require immediate results.

Apache Spark emerged in 2010 as a response to the limitations in Hadoop’s approach to big data processing. Developed initially at UC Berkeley before becoming an Apache project, Spark addressed Hadoop MapReduce’s heavy reliance on disk operations. Its breakthrough innovation was implementing in-memory computation, which dramatically reduces processing time for many data workloads by minimizing the need to read from and write to disk.
Spark provides a unified platform with several tightly integrated components built around its core processing engine:
This cohesive design means teams can address various data challenges using a single framework rather than juggling multiple specialized tools.
Despite their differences, Spark and Hadoop often work together as complementary technologies rather than competitors. Since Spark doesn’t include its own storage system, it commonly relies on Hadoop’s HDFS for persistent data storage.
Additionally, Spark can operate on Hadoop’s YARN resource manager, making it straightforward for organizations to enhance existing Hadoop environments with Spark’s processing power. This compatibility creates a practical upgrade path that lets businesses adopt Spark’s advantages without abandoning their investment in Hadoop infrastructure.
When evaluating big data frameworks, performance often becomes a decisive factor for organizations with time-sensitive data processing needs.
Hadoop’s MapReduce operates as a disk-based processing system, reading data from disk, processing it, and writing results back to disk between each stage of computation. This disk I/O creates significant latency, particularly for iterative algorithms that require multiple passes over the same data.
While effective for batch processing of massive datasets, this approach sacrifices speed for reliability and throughput.
Spark, by contrast, performs computations primarily in memory, dramatically reducing the need for disk operations. For many workloads, particularly iterative algorithms like those used in machine learning, Spark can execute tasks up to 100 times faster than Hadoop MapReduce.
This performance advantage becomes especially pronounced when processing needs to occur in near real-time or when algorithms require multiple passes through the same dataset.
Hadoop’s design assumes limited memory availability, making it memory-efficient but slower. It relies heavily on disk storage, which allows it to process datasets much larger than available RAM by constantly swapping data between memory and disk.
This approach makes Hadoop suitable for processing extremely large datasets on clusters with limited memory resources.
Spark’s performance advantages come from its aggressive use of memory. By caching data in RAM across processing stages, Spark eliminates costly disk operations. However, this requires sufficient memory resources to hold working datasets.
When memory constraints arise, Spark’s performance advantage diminishes as it begins spilling data to disk, though its intelligent memory management still typically outperforms Hadoop’s disk-first approach.
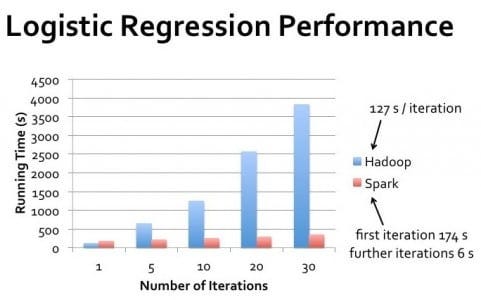
The real-world performance gap between Hadoop and Spark varies significantly based on specific use cases. For single-pass batch processing of massive datasets where data greatly exceeds available memory, Hadoop’s performance may approach Spark’s.
However, for iterative processing, interactive queries, and stream processing, Spark consistently delivers superior performance.
It’s worth noting that performance isn’t solely about raw speed. Hadoop excels in scenarios requiring high fault tolerance and where processing can happen in clearly defined batch windows.
Spark performs best when rapid results are needed, such as interactive data exploration, real-time analytics, and machine learning applications where algorithms make multiple passes through datasets.
Both Hadoop and Spark rely on clusters to process large volumes of data efficiently, but they manage these resources differently, affecting both performance and administration.
A cluster is a collection of interconnected computers (nodes) that work together as a single system. In big data processing, clustering becomes necessary when data volumes exceed what a single machine can efficiently handle. By distributing computational workloads across multiple machines, clusters enable organizations to process petabytes of data that would otherwise be impossible to manage.
Clustering also provides fault tolerance and high availability. If one machine fails, others in the cluster can take over its workload, ensuring continuous operation. This resilience is crucial for production environments where downtime can be costly.
Additionally, clustering allows for horizontal scaling — adding more machines to increase processing power — which is often more cost-effective than upgrading individual systems.
For aspiring professionals in this field, understanding clustering is a fundamental skill in data engineering.
Hadoop clusters follow a master-slave architecture with specialized roles for different nodes. The NameNode serves as the master for HDFS, maintaining metadata about file locations and permissions. DataNodes store the actual data blocks and report to the NameNode.
For processing, the ResourceManager allocates cluster resources, while NodeManagers on individual machines execute tasks.
HDFS replicates data across multiple DataNodes, typically maintaining three copies of each data block. This replication strategy ensures data availability even if individual nodes fail, though it requires additional storage capacity.
Hadoop’s cluster design emphasizes data locality, attempting to schedule computational tasks on the same nodes where data resides to minimize network transfer.
Administration of Hadoop clusters traditionally required significant expertise (professionals often prepare for Hadoop interview questions to demonstrate this knowledge), though modern distributions include management tools to simplify configuration and monitoring.
Scaling a Hadoop cluster involves adding new nodes and rebalancing data across the expanded infrastructure, which can be a manual process requiring careful planning.
Spark can operate in various cluster configurations, including standalone mode, on Hadoop YARN, Apache Mesos, or Kubernetes. In all deployments, Spark follows a driver-executor model. The driver program contains the application’s main function and creates a SparkContext that coordinates with the cluster manager to allocate resources.
Once resources are allocated, Spark executors are launched on worker nodes. These executors are JVM processes that run tasks and store data in memory or disk. Unlike Hadoop, which keeps a persistent presence on cluster nodes, Spark executors can be dynamically allocated and released based on application needs, potentially improving resource utilization.
Interested readers can explore Spark’s capabilities further through practical tutorials like Apache Spark for Machine Learning.
Spark doesn’t include its own distributed storage system, instead leveraging existing solutions like HDFS, Amazon S3, or other compatible storage systems. This architecture separation between compute and storage provides flexibility but requires careful configuration to ensure optimal data access patterns.
Tools like Spark SQL and sparklyr offer convenient ways to interact with this architecture.
Hadoop’s approach to cluster management is more infrastructure-centric, with relatively static resource allocation and a focus on data locality. This design works well for long-running batch jobs on stable clusters where nodes rarely change.
However, it can be less responsive to varying workloads and requires more manual intervention when scaling.
Spark offers more dynamic resource management, particularly when running on modern orchestration platforms like Kubernetes. It can adjust resource allocation based on current demands and release resources when not needed.
This elasticity is valuable for organizations with fluctuating workloads or shared infrastructure serving multiple applications.
Understanding these differences is crucial for professionals pursuing a Data Engineer certification or preparing for Spark interview questions.
For organizations just beginning with big data, Spark’s more flexible deployment options and simpler programming model often make it easier to get started.
However, in environments with extremely large data volumes where storage management is a primary concern, Hadoop’s mature HDFS ecosystem still offers advantages that complement Spark’s processing capabilities. For a comparison of Spark with other streaming technologies, readers might find comparisons like Flink vs. Spark informative.
While previous sections discussed performance implications, understanding the fundamental processing models of each framework helps explain why they’re architected so differently.
MapReduce follows a rigid programming paradigm with two primary phases: map and reduce. The map phase applies a function to each record in parallel, generating intermediate key-value pairs.
These pairs undergo a mandatory shuffling and sorting phase, where data with the same keys is grouped.
Finally, the reduce phase aggregates these grouped values to produce final outputs. This structured approach means complex operations require chaining multiple MapReduce jobs together.
Developing MapReduce applications typically involves writing low-level code that explicitly defines the mapping and reducing functions.
While frameworks like Apache Pig and Apache Hive provide higher-level abstractions, the underlying execution still follows the strict MapReduce pattern, which imposes limitations on algorithm design and optimization opportunities.
Spark introduced Resilient Distributed Datasets (RDDs) as its core abstraction — immutable, partitioned collections that can track their lineage for recovery. Unlike MapReduce, Spark doesn’t enforce a rigid processing pattern but instead offers two types of operations: transformations (which create new RDDs) and actions (which return values).
This flexibility allows for diverse processing patterns beyond the map-reduce paradigm.
Spark has evolved beyond RDDs to offer higher-level abstractions like DataFrames and Datasets, which provide schema-aware processing with optimizations similar to relational databases. These abstractions, combined with specialized libraries for streaming, SQL, machine learning, and graph processing, allow developers to express complex workflows with significantly less code than equivalent MapReduce implementations, while maintaining a unified programming model across different processing paradigms.
When evaluating big data frameworks, organizations must consider not just technical capabilities but also financial implications of their deployment and operation.
Hadoop and Spark have fundamentally different hardware preferences that impact infrastructure costs. Hadoop was designed to prioritize disk storage over memory, making it well-suited for commodity hardware with limited RAM but substantial hard drive capacity.
This architecture can reduce initial hardware investment, especially when processing extremely large datasets where memory-based solutions would be prohibitively expensive.
Spark’s in-memory processing model delivers performance benefits but requires significantly more RAM per node. A properly configured Spark cluster typically demands servers with substantial memory configurations — often 16GB to 256GB per node depending on workload characteristics.
While memory costs have decreased over time, this requirement can still increase hardware expenses compared to disk-centric Hadoop deployments.
Operational costs extend beyond hardware acquisition to include ongoing maintenance, electricity, cooling, and data center space. Hadoop clusters tend to have larger physical footprints due to their reliance on numerous commodity servers with extensive storage.
This larger footprint translates to higher costs for power, cooling, and rack space.
Spark clusters can sometimes achieve the same processing capabilities with fewer nodes due to their more efficient use of computing resources, potentially reducing data center footprint and associated costs. However, the higher-specification machines required may consume more power per node, partially offsetting these savings.
The complexity of implementation and maintenance can significantly impact the total cost of ownership. Hadoop’s ecosystem traditionally required specialized expertise in Java programming and Unix administration, with development cycles that could be lengthy due to the verbose nature of MapReduce programming.
Spark offers more accessible APIs in Python, Scala, R, and Java, potentially reducing development time and associated personnel costs.
The more intuitive programming model can decrease both the learning curve and development time, allowing organizations to implement solutions faster with less specialized personnel.
For cost-sensitive organizations, hybrid approaches often provide the best value. Using HDFS for storage while leveraging Spark for processing can combine Hadoop’s cost-effective storage with Spark’s processing efficiency. Cloud-based deployments on services like AWS EMR, Azure HDInsight, or Google Dataproc allow organizations to pay only for resources used without large upfront capital expenditures.
Organizations should also consider scalability costs. Hadoop traditionally requires manual intervention for scaling, which adds operational overhead. Spark’s compatibility with container orchestration platforms like Kubernetes enables more automated, elastic scaling that can better match resource provisioning with actual demand, potentially reducing wasted capacity.
Here is a comparison table summarizing their differences:
|
Feature |
Hadoop |
Spark |
|
Processing Model |
Batch processing using MapReduce |
In-memory processing using RDDs, DataFrames, and Datasets |
|
Performance |
Slower due to disk I/O between stages |
Up to 100x faster for iterative and in-memory workloads |
|
Memory Usage |
Disk-centric, low memory requirements |
Memory-intensive, high RAM requirements |
|
Ease of Development |
Verbose; requires writing map & reduce logic explicitly |
High-level APIs in Python, Scala, R, Java; less boilerplate |
|
Fault Tolerance |
Data replication via HDFS |
RDD lineage enables recomputation in case of failure |
|
Real-time Processing |
Not ideal; batch only |
Supports real-time processing via Spark Streaming |
|
Cluster Manager |
YARN |
Standalone, YARN, Mesos, or Kubernetes |
|
Storage |
Comes with HDFS |
Depends on external storage (e.g., HDFS, S3, GCS) |
|
Cost |
Lower hardware cost (commodity machines, disk-based) |
Higher memory cost but better resource utilization per workload |
|
Best For |
Batch jobs, massive-scale storage, historical data analysis |
Machine learning, stream processing, interactive analytics |
|
Integration |
Strong Hadoop ecosystem (Hive, Pig, etc.) |
Unified APIs for SQL, MLlib, GraphX, and Streaming in a single platform |
Hadoop and Spark represent complementary approaches to big data processing rather than strict competitors. Hadoop excels with its cost-effective storage system (HDFS) and batch-oriented processing for massive datasets where throughput matters more than speed.
Spark shines with its in-memory processing capabilities that deliver superior performance for iterative algorithms, interactive analytics, and real-time processing needs.
DataCamp offers various resources if you want to learn more about these two technologies:
Top DataCamp Courses
Track
Course
Course
blog
Maria Eugenia Inzaugarat
8 min
blog
Tim Lu
15 min
blog
Emmanuel Akor
11 min
blog
Austin Chia
10 min
blog
Tim Lu
12 min
Tutorial
Karlijn Willems