Programa
Engenheiro de dados Em Python
40 h
O Hadoop e o Spark são duas das estruturas mais proeminentes em Big Data e lidam com o processamento de dados em grande escala de maneiras muito diferentes. Enquanto o Hadoop pode ser creditado por democratizar o paradigma da computação distribuída por meio de um sistema de armazenamento robusto chamado HDFS e um modelo computacional chamado MapReduce, o Spark está mudando o jogo com sua arquitetura na memória e modelo de programação flexível.
Neste tutorial, você se aprofundará nas diferenças entre o Hadoop e o Spark, incluindo sua arquitetura, desempenho, considerações de custo e integrações. Ao final, o leitor terá uma compreensão clara das vantagens e desvantagens de cada uma delas e dos tipos de casos de uso em que cada estrutura se destaca; essa compreensão ajudará você a tomar decisões estratégicas ao criar suas soluções de big data.
Antes de entrar em detalhes específicos, vamos explorar os conceitos fundamentais e as origens do Hadoop e do Spark para que você entenda como essas estruturas poderosas abordam os desafios de Big Data.

O Hadoop é uma estrutura de código aberto projetada para armazenar e processar grandes conjuntos de dados em clusters de computadores. Desde o seu desenvolvimento em 2006, o Hadoop tem permitido que as organizações lidem com volumes de dados maciços que sobrecarregariam uma única máquina. Ao distribuir os dados em vários nós, ele não apenas melhora a capacidade de processamento, mas também oferece redundância, garantindo a confiabilidade do sistema mesmo quando máquinas individuais falham.
Os principais componentes da estrutura do Hadoop incluem:
Uma das principais vantagens do Hadoop é sua relação custo-benefício, pois permite que as organizações usem hardware padrão e de commodity em vez de equipamentos especializados caros. Essa abordagem prática também se estende à sua filosofia de processamento.
O design orientado a lotes do Hadoop é excelente em cenários em que o rendimento geral é mais importante do que a velocidade de processamento bruta, o que o torna particularmente valioso para análise de dados históricos e ETL (Extrair, Transformar, Carregar) complexas que não exigem resultados imediatos.

Apache Spark surgiu em 2010 como uma resposta às limitações da abordagem do Hadoop para o processamento de Big Data. Desenvolvido inicialmente na UC Berkeley antes de se tornar um projeto da Apache, o Spark abordou a forte dependência do Hadoop MapReduce em operações de disco. Sua inovação revolucionária foi a implementação da computação na memória, que reduz drasticamente o tempo de processamento de muitas cargas de trabalho de dados, minimizando a necessidade de ler e gravar no disco.
O Spark fornece uma plataforma unificada com vários componentes fortemente integrados, criados em torno de seu mecanismo de processamento principal:
Esse design coeso significa que as equipes podem lidar com vários desafios de dados usando uma única estrutura, em vez de lidar com várias ferramentas especializadas.
Apesar de suas diferenças, o Spark e o Hadoop geralmente trabalham juntos como tecnologias complementares, e não como concorrentes. Como o Spark não inclui seu próprio sistema de armazenamento, ele geralmente depende do HDFS do Hadoop para o armazenamento persistente de dados.
Além disso, o Spark pode operar no gerenciador de recursos YARN do Hadoop, o que torna mais fácil para as organizações aprimorarem os ambientes Hadoop existentes com o poder de processamento do Spark. Essa compatibilidade cria um caminho de atualização prático que permite que as empresas adotem as vantagens do Spark sem abandonar seu investimento na infraestrutura do Hadoop.
Ao avaliar as estruturas de Big Data, o desempenho geralmente se torna um fator decisivo para organizações com necessidades de processamento de dados sensíveis ao tempo.
O MapReduce do Hadoop opera como um sistema de processamento baseado em disco, lendo dados do disco, processando-os e gravando os resultados de volta no disco entre cada estágio da computação. Essa E/S de disco cria uma latência significativa, especialmente para algoritmos iterativos que exigem várias passagens sobre os mesmos dados.
Embora seja eficaz para o processamento em lote de conjuntos de dados maciços, essa abordagem sacrifica a velocidade em prol da confiabilidade e do rendimento.
O Spark, por outro lado, realiza os cálculos principalmente na memória, reduzindo drasticamente a necessidade de operações em disco. Para muitas cargas de trabalho, especialmente algoritmos iterativos como os usados em machine learning, o Spark pode executar tarefas até 100 vezes mais rápido do que o Hadoop MapReduce.
Essa vantagem de desempenho torna-se especialmente acentuada quando o processamento precisa ocorrer quase em tempo real ou quando os algoritmos exigem várias passagens pelo mesmo conjunto de dados.
O projeto do Hadoop pressupõe disponibilidade limitada de memória, o que o torna eficiente em termos de memória, porém mais lento. Ele depende muito do armazenamento em disco, o que lhe permite processar conjuntos de dados muito maiores do que a RAM disponível, trocando constantemente os dados entre a memória e o disco.
Essa abordagem torna o Hadoop adequado para o processamento de conjuntos de dados extremamente grandes em clusters com recursos de memória limitados.
As vantagens de desempenho do Spark vêm de seu uso agressivo da memória. Ao armazenar em cache os dados na RAM em todos os estágios de processamento, o Spark elimina as dispendiosas operações em disco. No entanto, isso requer recursos de memória suficientes para armazenar conjuntos de dados de trabalho.
Quando surgem restrições de memória, a vantagem de desempenho do Spark diminui à medida que ele começa a enviar dados para o disco, embora seu gerenciamento inteligente de memória ainda supere a abordagem do Hadoop que prioriza o disco.
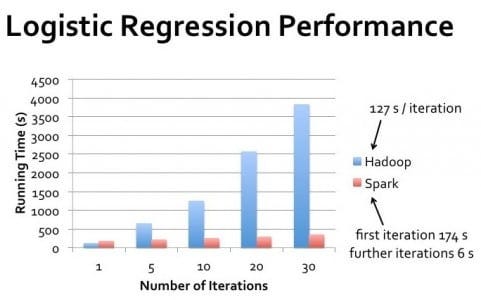
No mundo real, a diferença de desempenho entre o Hadoop e o Spark varia significativamente com base em casos de uso específicos. Para o processamento em lote de passagem única de conjuntos de dados maciços em que os dados excedem em muito a memória disponível, o desempenho do Hadoop pode se aproximar do desempenho do Spark.
No entanto, para processamento iterativo, consultas interativas e processamento de fluxo, o Spark oferece desempenho superior de forma consistente.
É importante observar que o desempenho não se refere apenas à velocidade bruta. O Hadoop é excelente em cenários que exigem alta tolerância a falhas e onde o processamento pode ocorrer em janelas de lote claramente definidas.
O Spark tem melhor desempenho quando você precisa de resultados rápidos, como exploração interativa de dados, análise em tempo real e aplicativos de machine learning em que os algoritmos fazem várias passagens pelos conjuntos de dados.
Tanto o Hadoop quanto o Spark dependem de clusters para processar grandes volumes de dados com eficiência, mas gerenciam esses recursos de forma diferente, o que afeta o desempenho e a administração.
Um cluster é um conjunto de computadores interconectados (nós) que trabalham juntos como um único sistema. No processamento de big data, o clustering se torna necessário quando os volumes de dados excedem o que uma única máquina pode manipular com eficiência. Ao distribuir cargas de trabalho computacionais em várias máquinas, os clusters permitem que as organizações processem petabytes de dados que, de outra forma, seriam impossíveis de gerenciar.
O clustering também oferece tolerância a falhas e alta disponibilidade. Se uma máquina falhar, outras no cluster poderão assumir sua carga de trabalho, garantindo uma operação contínua. Essa resiliência é crucial para ambientes de produção em que o tempo de inatividade pode ser caro.
Além disso, o clustering permite o dimensionamento horizontal, ou seja, a adição de mais máquinas para aumentar a capacidade de processamento, o que geralmente é mais econômico do que atualizar sistemas individuais.
Para os aspirantes a profissionais dessa área, compreender o clustering é uma habilidade fundamental na engenharia de dados.
Os clusters do Hadoop seguem uma arquitetura mestre-escravo com funções especializadas para diferentes nós. O nó NameNode serve como o mestre para o HDFSmantendo metadados sobre locais e permissões de arquivos. Os DataNodes armazenam os blocos de dados reais e informam ao NameNode.
Para o processamento, o ResourceManager aloca recursos do cluster, enquanto os NodeManagers em máquinas individuais executam tarefas.
O HDFS replica os dados em vários DataNodes, normalmente mantendo três cópias de cada bloco de dados. Essa estratégia de replicação garante a disponibilidade dos dados mesmo que os nós individuais falhem, embora exija capacidade de armazenamento adicional.
O projeto de cluster do Hadoop enfatiza a localidade dos dados, tentando agendar tarefas computacionais nos mesmos nós em que os dados residem para minimizar a transferência de rede.
Tradicionalmente, a administração de clusters do Hadoop exigia um conhecimento significativo (os profissionais geralmente se preparam para perguntas de entrevista sobre o Hadoop para demonstrar esse conhecimento), embora as distribuições modernas incluam ferramentas de gerenciamento para simplificar a configuração e o monitoramento.
O dimensionamento de um cluster do Hadoop envolve a adição de novos nós e o reequilíbrio de dados na infraestrutura expandida, o que pode ser um processo manual que exige um planejamento cuidadoso.
O Spark pode operar em várias configurações de cluster, incluindo o modo autônomo, no Hadoop YARN, no Apache Mesos ou no Kubernetes. Em todas as implantações, o Spark segue um modelo driver-executor. O programa do driver contém a função principal do aplicativo e cria um SparkContext que coordena com o gerenciador de cluster para alocar recursos.
Quando os recursos são alocados, os executores do Spark são iniciados nos nós de trabalho. Esses executores são processos JVM que executam tarefas e armazenam dados na memória ou no disco. Ao contrário do Hadoop, que mantém uma presença persistente nos nós do cluster, os executores do Spark podem ser alocados e liberados dinamicamente com base nas necessidades do aplicativo, melhorando potencialmente a utilização dos recursos.
Os leitores interessados podem explorar ainda mais os recursos do Spark por meio de tutoriais práticos, como Apache Spark para machine learning.
O Spark não inclui seu próprio sistema de armazenamento distribuído, mas aproveita soluções existentes como o HDFS, Amazon S3ou outros sistemas de armazenamento compatíveis. Essa separação de arquitetura entre computação e armazenamento oferece flexibilidade, mas exige uma configuração cuidadosa para garantir padrões ideais de acesso aos dados.
Ferramentas como Spark SQL e sparklyr oferecem maneiras convenientes de interagir com essa arquitetura.
A abordagem do Hadoop para o gerenciamento de clusters é mais centrada na infraestrutura, com alocação de recursos relativamente estática e foco na localidade dos dados. Esse design funciona bem para trabalhos em lote de longa duração em clusters estáveis em que os nós raramente mudam.
No entanto, ele pode ser menos responsivo a cargas de trabalho variáveis e requer mais intervenção manual ao ser dimensionado.
O Spark oferece um gerenciamento de recursos mais dinâmico, especialmente quando executado em plataformas de orquestração modernas, como o Kubernetes. Ele pode ajustar a alocação de recursos com base nas demandas atuais e liberar recursos quando não forem necessários.
Essa elasticidade é valiosa para organizações com cargas de trabalho flutuantes ou infraestrutura compartilhada que atende a vários aplicativos.
Compreender essas diferenças é fundamental para os profissionais que buscam uma certificação de engenheiro de dados ou se preparando para as perguntas da entrevista do Spark.
Para as organizações que estão começando a usar big data, as opções de implantação mais flexíveis e o modelo de programação mais simples do Spark geralmente facilitam o início das atividades.
No entanto, em ambientes com volumes de dados extremamente grandes em que o gerenciamento de armazenamento é a principal preocupação, o ecossistema HDFS maduro do Hadoop ainda oferece vantagens que complementam os recursos de processamento do Spark. Para uma comparação do Spark com outras tecnologias de streaming, você pode encontrar comparações como Flink vs. Spark. Spark informativo.
Embora as seções anteriores tenham discutido as implicações de desempenho, entender os modelos fundamentais de processamento de cada estrutura ajuda a explicar por que eles são arquitetados de forma tão diferente.
MapReduce segue um paradigma de programação rígido com duas fases principais: mapear e reduzir. A fase de mapa aplica uma função a cada registro em paralelo, gerando pares de valores-chave intermediários.
Esses pares passam por uma fase obrigatória de embaralhamento e classificação, em que os dados com as mesmas chaves são agrupados.
Por fim, a fase de redução agrega esses valores agrupados para produzir os resultados finais. Essa abordagem estruturada significa que operações complexas exigem o encadeamento de vários trabalhos de MapReduce.
O desenvolvimento de aplicativos MapReduce geralmente envolve a criação de código de baixo nível que define explicitamente as funções de mapeamento e redução.
Enquanto estruturas como Apache Pig e Apache Hive fornecem abstrações de nível superior, a execução subjacente ainda segue o padrão estrito do MapReduce, que impõe limitações ao design do algoritmo e às oportunidades de otimização.
Spark introduziu Conjuntos de dados distribuídos resilientes (RDDs) como sua abstração principal - coleções imutáveis e particionadas que podem rastrear sua linhagem para recuperação. Ao contrário do MapReduce, o Spark não impõe um padrão de processamento rígido, mas oferece dois tipos de operações: transformações (que criam novos RDDs) e ações (que retornam valores).
Essa flexibilidade permite diversos padrões de processamento além do paradigma map-reduce.
O Spark evoluiu além dos RDDs para oferecer abstrações de nível mais alto, como DataFrames e conjuntos de dadosque fornecem processamento com reconhecimento de esquema com otimizações semelhantes às dos bancos de dados relacionais. Essas abstrações, combinadas com bibliotecas especializadas para streaming, SQL, machine learninge processamento de gráficos, permitem que os desenvolvedores expressem fluxos de trabalho complexos com muito menos código do que as implementações equivalentes do MapReduce, mantendo um modelo de programação unificado em diferentes paradigmas de processamento.
Ao avaliar as estruturas de Big Data, as organizações devem considerar não apenas os recursos técnicos, mas também as implicações financeiras de sua implementação e operação.
O Hadoop e o Spark têm preferências de hardware fundamentalmente diferentes que afetam os custos de infraestrutura. O Hadoop foi projetado para priorizar o armazenamento em disco em relação à memória, o que o torna adequado para hardware de commodity com RAM limitada, mas com capacidade substancial de disco rígido.
Essa arquitetura pode reduzir o investimento inicial em hardware, especialmente ao processar conjuntos de dados extremamente grandes, nos quais as soluções baseadas em memória seriam proibitivamente caras.
O modelo de processamento na memória do Spark oferece benefícios de desempenho, mas requer significativamente mais RAM por nó. Em geral, um cluster Spark configurado corretamente exige servidores com configurações de memória substanciais, geralmente de 16 GB a 256 GB por nó, dependendo das características da carga de trabalho.
Embora os custos de memória tenham diminuído com o tempo, esse requisito ainda pode aumentar as despesas com hardware em comparação com as implementações do Hadoop centradas em disco.
Os custos operacionais vão além da aquisição de hardware e incluem manutenção contínua, eletricidade, refrigeração e espaço no data center. Os clusters do Hadoop tendem a ter uma área de cobertura física maior devido à sua dependência de vários servidores de commodities com armazenamento extensivo.
Essa área ocupada maior se traduz em custos mais altos de energia, resfriamento e espaço no rack.
Às vezes, os clusters do Spark podem alcançar os mesmos recursos de processamento com menos nós, devido ao uso mais eficiente dos recursos de computação, reduzindo potencialmente o espaço ocupado pelo data center e os custos associados. No entanto, as máquinas de maior especificação necessárias podem consumir mais energia por nó, compensando parcialmente essa economia.
A complexidade da implementação e da manutenção pode afetar significativamente o custo total de propriedade. Tradicionalmente, o ecossistema do Hadoop exigia conhecimento especializado em programação Java e administração Unix, com ciclos de desenvolvimento que podiam ser longos devido à natureza verbosa da programação do MapReduce.
O Spark oferece APIs mais acessíveis em PythonScala, R e Java, o que pode reduzir o tempo de desenvolvimento e os custos de pessoal associados.
O modelo de programação mais intuitivo pode reduzir a curva de aprendizado e o tempo de desenvolvimento, permitindo que as organizações implementem soluções mais rapidamente com menos pessoal especializado.
Para organizações sensíveis ao custo, as abordagens híbridas geralmente oferecem o melhor valor. Usando o HDFS para armazenamento e aproveitando o Spark para processamento, você pode combinar o armazenamento econômico do Hadoop com a eficiência de processamento do Spark. As implementações baseadas em nuvem em serviços como AWS EMR, Azure HDInsight ou Google Dataproc permitem que as organizações paguem apenas pelos recursos usados, sem grandes despesas de capital iniciais.
As organizações também devem considerar os custos de escalabilidade. Tradicionalmente, o Hadoop requer intervenção manual para dimensionamento, o que aumenta a sobrecarga operacional. A compatibilidade do Spark com plataformas de orquestração de contêineres, como Kubernetes permite um dimensionamento mais automatizado e elástico que pode combinar melhor o provisionamento de recursos com a demanda real, reduzindo potencialmente o desperdício de capacidade.
Aqui está uma tabela de comparação que resume suas diferenças:
|
Recurso |
Hadoop |
Spark |
|
Modelo de processamento |
Processamento em lote usando o MapReduce |
Processamento na memória usando RDDs, DataFrames e conjuntos de dados |
|
Desempenho |
Mais lento devido à E/S do disco entre os estágios |
Até 100 vezes mais rápido para cargas de trabalho iterativas e na memória |
|
Uso da memória |
Centrado em disco, com poucos requisitos de memória |
Requisitos de memória intensiva e alta quantidade de RAM |
|
Facilidade de desenvolvimento |
Verboso; requer escrever explicitamente a lógica de mapa e redução |
APIs de alto nível em Python, Scala, R, Java; menos boilerplate |
|
Tolerância a falhas |
Replicação de dados via HDFS |
A linhagem RDD permite a recomputação em caso de falha |
|
Processamento em tempo real |
Não é ideal; somente em lote |
Você tem suporte para processamento em tempo real via Spark Streaming |
|
Gerente de cluster |
YARN |
Autônomo, YARN, Mesos ou Kubernetes |
|
Armazenamento |
Vem com HDFS |
Depende do armazenamento externo (por exemplo, HDFS, S3, GCS) |
|
Custo |
Menor custo de hardware (máquinas de commodities, baseadas em disco) |
Maior custo de memória, mas melhor utilização de recursos por carga de trabalho |
|
Melhor para |
Trabalhos em lote, armazenamento em grande escala, análise de dados históricos |
Machine learning, processamento de fluxo, análise interativa |
|
Integração |
Forte ecossistema Hadoop (Hive, Pig, etc.) |
APIs unificadas para SQL, MLlib, GraphX e Streaming em uma única plataforma |
O Hadoop e o Spark representam abordagens complementares ao processamento de big data, e não concorrentes estritos. O Hadoop se destaca por seu sistema de armazenamento econômico (HDFS) e pelo processamento orientado a lotes para conjuntos de dados maciços em que o rendimento é mais importante do que a velocidade.
O Spark se destaca por seus recursos de processamento na memória que oferecem desempenho superior para algoritmos iterativos, análises interativas e necessidades de processamento em tempo real.
A DataCamp oferece vários recursos se você quiser saber mais sobre essas duas tecnologias:
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Tim Lu
11 min
blog
DataCamp Team
12 min
blog
Austin Chia
8 min
blog
Joleen Bothma
4 min
blog
Moez Ali
11 min
Tutorial
Natassha Selvaraj


