Lernpfad
Dateningenieur in Python
40 Std.
Hadoop und Spark sind zwei der bekanntesten Big-Data-Frameworks, die die Verarbeitung großer Datenmengen auf sehr unterschiedliche Weise handhaben. Während Hadoop mit seinem robusten Speichersystem HDFS und dem Rechenmodell MapReduce das Paradigma des verteilten Rechnens demokratisiert hat, verändert Spark mit seiner In-Memory-Architektur und seinem flexiblen Programmiermodell das Spiel.
In diesem Tutorial werden die Unterschiede zwischen Hadoop und Spark, einschließlich ihrer Architektur, Leistung, Kostenüberlegungen und Integrationen, näher erläutert. Am Ende wird der Leser ein klares Verständnis der Vor- und Nachteile der einzelnen Frameworks und der Anwendungsfälle haben, in denen sich jedes Framework auszeichnet.
Bevor wir ins Detail gehen, wollen wir die grundlegenden Konzepte und Ursprünge von Hadoop und Spark erkunden, um zu verstehen, wie diese leistungsstarken Frameworks die Herausforderungen von Big Data angehen.

Hadoop ist ein Open-Source-Framework, das für die Speicherung und Verarbeitung großer Datenmengen in Computerclustern entwickelt wurde. Seit seiner Entwicklung im Jahr 2006 hat Hadoop es Unternehmen ermöglicht, riesige Datenmengen zu verarbeiten, die eine einzelne Maschine überfordern würden. Durch die Verteilung der Daten auf mehrere Knotenpunkte wird nicht nur die Verarbeitungskapazität verbessert, sondern auch eine Redundanz geschaffen, die die Zuverlässigkeit des Systems gewährleistet, selbst wenn einzelne Maschinen ausfallen.
Zu den wichtigsten Komponenten des Hadoop-Frameworks gehören:
Einer der Hauptvorteile von Hadoop ist seine Kosteneffizienz, da es Unternehmen ermöglicht, Standard-Hardware anstelle von teurer Spezialausrüstung zu verwenden. Dieser praktische Ansatz erstreckt sich auch auf die Verarbeitungsphilosophie.
Das stapelorientierte Design von Hadoop eignet sich hervorragend für Szenarien, in denen der Gesamtdurchsatz wichtiger ist als die reine Verarbeitungsgeschwindigkeit. Dies macht es besonders wertvoll für die Analyse historischer Daten und komplexe ETL (Extrahieren, Transformieren, Laden) Operationen, die keine sofortigen Ergebnisse erfordern.

Apache Spark entstand 2010 als Antwort auf die Grenzen des Hadoop-Ansatzes zur Verarbeitung von Big Data. Spark wurde zunächst an der UC Berkeley entwickelt, bevor es zu einem Apache-Projekt wurde, um die starke Abhängigkeit von Hadoop MapReduce von Festplattenoperationen zu beheben. Seine bahnbrechende Innovation war die Implementierung von In-Memory-Berechnungen, die die Verarbeitungszeit für viele Daten-Workloads drastisch reduzieren, indem sie die Notwendigkeit, von der Festplatte zu lesen und auf sie zu schreiben, minimieren.
Spark bietet eine einheitliche Plattform mit mehreren eng integrierten Komponenten, die um die zentrale Verarbeitungsmaschine herum aufgebaut sind:
Dieses einheitliche Design bedeutet, dass Teams verschiedene Datenherausforderungen mit einem einzigen Framework angehen können, anstatt mit mehreren spezialisierten Tools zu jonglieren.
Trotz ihrer Unterschiede arbeiten Spark und Hadoop oft als komplementäre Technologien und nicht als Konkurrenten zusammen. Da Spark kein eigenes Speichersystem hat, verlässt es sich in der Regel auf das HDFS von Hadoop zur dauerhaften Datenspeicherung.
Außerdem kann Spark auf dem YARN-Ressourcenmanager von Hadoop betrieben werden, so dass Unternehmen bestehende Hadoop-Umgebungen ganz einfach mit der Rechenleistung von Spark erweitern können. Diese Kompatibilität schafft einen praktischen Upgrade-Pfad, der es Unternehmen ermöglicht, die Vorteile von Spark zu nutzen, ohne ihre Investitionen in die Hadoop-Infrastruktur aufzugeben.
Bei der Bewertung von Big Data-Frameworks ist die Leistung oft ein entscheidender Faktor für Unternehmen, die zeitkritische Daten verarbeiten müssen.
MapReduce von Hadoop arbeitet als plattenbasiertes Verarbeitungssystem, das Daten von der Festplatte liest, sie verarbeitet und die Ergebnisse zwischen den einzelnen Berechnungsschritten wieder auf die Festplatte schreibt. Diese Festplatten-E/A verursacht erhebliche Latenzzeiten, insbesondere bei iterativen Algorithmen, die mehrere Durchläufe über dieselben Daten erfordern.
Dieser Ansatz eignet sich zwar gut für die Stapelverarbeitung großer Datenmengen, geht aber zu Lasten von Zuverlässigkeit und Durchsatz.
Spark hingegen führt die Berechnungen hauptsächlich im Arbeitsspeicher durch, wodurch der Bedarf an Festplattenoperationen drastisch reduziert wird. Für viele Arbeitslasten, insbesondere für iterative Algorithmen, wie sie beim maschinellen Lernen verwendet werden, kann Spark Aufgaben bis zu 100 Mal schneller ausführen als Hadoop MapReduce.
Dieser Leistungsvorteil wird besonders deutlich, wenn die Verarbeitung nahezu in Echtzeit erfolgen muss oder wenn Algorithmen mehrere Durchläufe durch denselben Datensatz erfordern.
Das Design von Hadoop geht von einer begrenzten Verfügbarkeit von Speicher aus, was es speichereffizient, aber langsamer macht. Es verlässt sich stark auf Festplattenspeicher, was es ihm ermöglicht, Datensätze zu verarbeiten, die viel größer sind als der verfügbare Arbeitsspeicher, indem es ständig Daten zwischen Speicher und Festplatte austauscht.
Mit diesem Ansatz eignet sich Hadoop für die Verarbeitung extrem großer Datenmengen auf Clustern mit begrenzten Speicherressourcen.
Die Leistungsvorteile von Spark ergeben sich aus der aggressiven Nutzung des Speichers. Durch die Zwischenspeicherung von Daten im Arbeitsspeicher über mehrere Verarbeitungsstufen hinweg vermeidet Spark kostspielige Festplattenoperationen. Dies erfordert jedoch genügend Speicherplatz, um die Arbeitsdatensätze zu speichern.
Wenn der Speicherplatz knapp wird, verringert sich der Leistungsvorteil von Spark, da die Daten auf die Festplatte ausgelagert werden, obwohl die intelligente Speicherverwaltung in der Regel immer noch besser ist als der Disk-First-Ansatz von Hadoop.
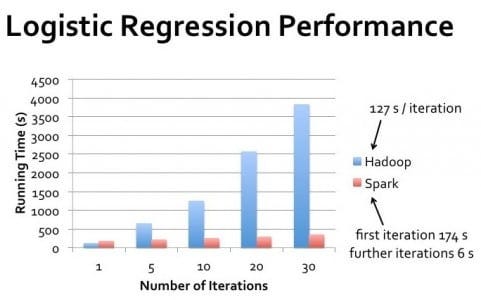
Der Leistungsunterschied zwischen Hadoop und Spark variiert in der Praxis je nach Anwendungsfall erheblich. Bei der Stapelverarbeitung riesiger Datensätze in einem Durchgang, bei der die Daten den verfügbaren Speicherplatz bei weitem übersteigen, kann die Leistung von Hadoop an die von Spark heranreichen.
Bei der iterativen Verarbeitung, bei interaktiven Abfragen und bei der Stream-Verarbeitung liefert Spark jedoch durchweg eine bessere Leistung.
Es ist wichtig zu wissen, dass es bei der Leistung nicht nur um die reine Geschwindigkeit geht. Hadoop eignet sich hervorragend für Szenarien, die eine hohe Fehlertoleranz erfordern und in denen die Verarbeitung in klar definierten Stapelfenstern erfolgen kann.
Spark eignet sich am besten, wenn schnelle Ergebnisse benötigt werden, z. B. bei der interaktiven Datenexploration, bei Echtzeit-Analysen und bei Anwendungen des maschinellen Lernens, bei denen Algorithmen mehrere Durchläufe durch Datensätze machen.
Sowohl Hadoop als auch Spark setzen auf Cluster, um große Datenmengen effizient zu verarbeiten, aber sie verwalten diese Ressourcen unterschiedlich, was sich sowohl auf die Leistung als auch auf die Verwaltung auswirkt.
Ein Cluster ist eine Sammlung von miteinander verbundenen Computern (Nodes), die als ein einziges System zusammenarbeiten. Bei der Verarbeitung von Big Data wird das Clustering notwendig, wenn die Datenmenge das übersteigt, was eine einzelne Maschine effizient verarbeiten kann. Durch die Verteilung von Rechenlasten auf mehrere Maschinen können Unternehmen mit Clustern Petabytes an Daten verarbeiten, die sonst nicht zu bewältigen wären.
Clustering bietet außerdem Fehlertoleranz und hohe Verfügbarkeit. Wenn eine Maschine ausfällt, können andere im Cluster ihre Arbeitslast übernehmen und so einen kontinuierlichen Betrieb sicherstellen. Diese Ausfallsicherheit ist entscheidend für Produktionsumgebungen, in denen Ausfallzeiten kostspielig sein können.
Außerdem ermöglicht das Clustering eine horizontale Skalierung, d.h. das Hinzufügen weiterer Maschinen, um die Rechenleistung zu erhöhen, was oft kostengünstiger ist als die Aufrüstung einzelner Systeme.
Für angehende Fachkräfte in diesem Bereich ist das Verständnis von Clustering eine grundlegende Fähigkeit in der Datentechnik.
Hadoop-Cluster folgen einer Master-Slave-Architektur mit spezialisierten Rollen für verschiedene Knotenpunkte. Die NameNode dient als Master für HDFSund verwaltet Metadaten über Dateispeicherorte und Berechtigungen. DataNodes speichern die eigentlichen Datenblöcke und berichten an den NameNode.
Für die Verarbeitung muss der ResourceManager die Cluster-Ressourcen zu, während die NodeManager auf den einzelnen Maschinen die Aufgaben ausführen.
HDFS repliziert Daten über mehrere DataNodes, wobei in der Regel drei Kopien jedes Datenblocks gespeichert werden. Diese Replikationsstrategie stellt die Datenverfügbarkeit sicher, auch wenn einzelne Knoten ausfallen, erfordert aber zusätzliche Speicherkapazität.
Das Cluster-Design von Hadoop legt den Schwerpunkt auf die Lokalisierung der Daten und versucht, Rechenaufgaben auf denselben Knoten zu planen, auf denen auch die Daten liegen, um die Netzwerkübertragung zu minimieren.
Die Verwaltung von Hadoop-Clustern erforderte traditionell erhebliche Fachkenntnisse (Fachleute bereiten sich oft auf Hadoop-Interview-Fragen um dieses Wissen zu demonstrieren), obwohl moderne Distributionen Management-Tools enthalten, die die Konfiguration und Überwachung vereinfachen.
Bei der Skalierung eines Hadoop-Clusters müssen neue Knoten hinzugefügt und die Daten in der erweiterten Infrastruktur neu verteilt werden, was ein manueller Prozess sein kann, der eine sorgfältige Planung erfordert.
Spark kann in verschiedenen Clusterkonfigurationen betrieben werden, darunter im Standalone-Modus, auf Hadoop YARN, Apache Mesos oder Kubernetes. Bei allen Einsätzen folgt Spark einem Treiber-Ausführenden-Modell. Das Treiberprogramm enthält die Hauptfunktion der Anwendung und erstellt einen SparkContext, der mit dem Clustermanager koordiniert wird, um Ressourcen zuzuweisen.
Sobald die Ressourcen zugewiesen sind, werden die Spark-Executors auf den Worker-Knoten gestartet. Diese Executors sind JVM-Prozesse, die Aufgaben ausführen und Daten im Speicher oder auf der Festplatte speichern. Im Gegensatz zu Hadoop, das eine dauerhafte Präsenz auf den Clusterknoten beibehält, können die Spark Executors dynamisch zugewiesen und je nach Anwendungsbedarf freigegeben werden, was die Ressourcenauslastung verbessern kann.
Interessierte Leser können die Fähigkeiten von Spark in praktischen Tutorials wie Apache Spark für maschinelles Lernen.
Spark verfügt über kein eigenes verteiltes Speichersystem, sondern nutzt bestehende Lösungen wie HDFS, Amazon S3oder andere kompatible Speichersysteme. Diese architektonische Trennung zwischen Compute und Storage bietet Flexibilität, erfordert aber eine sorgfältige Konfiguration, um optimale Datenzugriffsmuster zu gewährleisten.
Tools wie Spark SQL und sparklyr bieten bequeme Möglichkeiten, mit dieser Architektur zu interagieren.
Der Hadoop-Ansatz für die Cluster-Verwaltung ist eher infrastrukturzentriert, mit einer relativ statischen Ressourcenzuweisung und einem Schwerpunkt auf der Datenlokalität. Dieses Design eignet sich gut für lang laufende Batch-Jobs auf stabilen Clustern, bei denen die Knoten selten wechseln.
Allerdings kann sie weniger schnell auf wechselnde Arbeitslasten reagieren und erfordert mehr manuelle Eingriffe bei der Skalierung.
Spark bietet ein dynamischeres Ressourcenmanagement, insbesondere wenn es auf modernen Orchestrierungsplattformen wie Kubernetes läuft. Es kann die Ressourcenzuweisung an den aktuellen Bedarf anpassen und Ressourcen freigeben, wenn sie nicht benötigt werden.
Diese Elastizität ist wertvoll für Unternehmen mit schwankenden Arbeitslasten oder einer gemeinsam genutzten Infrastruktur, die mehrere Anwendungen bedient.
Diese Unterschiede zu verstehen, ist entscheidend für Fachleute, die eine Data Engineer Zertifizierung oder für die Vorbereitung auf Spark-Interview-Fragen.
Für Unternehmen, die gerade erst mit Big Data beginnen, erleichtern die flexibleren Einsatzmöglichkeiten und das einfachere Programmiermodell von Spark oft den Einstieg.
In Umgebungen mit extrem großen Datenmengen, in denen das Speichermanagement eine wichtige Rolle spielt, bietet das ausgereifte HDFS-Ökosystem von Hadoop jedoch immer noch Vorteile, die die Verarbeitungsmöglichkeiten von Spark ergänzen. Wenn du Spark mit anderen Streaming-Technologien vergleichen möchtest, findest du Vergleiche wie Flink vs. Spark informativ.
Während in den vorherigen Abschnitten die Auswirkungen auf die Leistung erörtert wurden, hilft das Verständnis der grundlegenden Verarbeitungsmodelle der einzelnen Frameworks zu erklären, warum sie so unterschiedlich aufgebaut sind.
MapReduce folgt einem starren Programmierparadigma mit zwei Hauptphasen: map und reduce. Die Map-Phase wendet eine Funktion parallel auf jeden Datensatz an und erzeugt dabei Schlüssel-Wert-Paare.
Diese Paare werden einer obligatorischen Misch- und Sortierphase unterzogen, in der die Daten mit denselben Schlüsseln gruppiert werden.
In der Reduktionsphase werden diese gruppierten Werte schließlich zusammengefasst, um den endgültigen Output zu erzeugen. Dieser strukturierte Ansatz bedeutet, dass für komplexe Operationen mehrere MapReduce-Jobs miteinander verkettet werden müssen.
Bei der Entwicklung von MapReduce-Anwendungen muss normalerweise Low-Level-Code geschrieben werden, der die Mapping- und Reducing-Funktionen explizit definiert.
Während Frameworks wie Apache Pig und Apache Hive eine höhere Abstraktionsebene bieten, folgt die zugrundeliegende Ausführung immer noch dem strikten MapReduce-Muster, was dem Algorithmusdesign und den Optimierungsmöglichkeiten Grenzen setzt.
Spark eingeführt Resilient Distributed Datasets (RDDs) als Kernabstraktion eingeführt - unveränderliche, partitionierte Sammlungen, die ihre Abstammung zur Wiederherstellung nachverfolgen können. Anders als MapReduce erzwingt Spark kein starres Verarbeitungsmuster, sondern bietet stattdessen zwei Arten von Operationen: Transformationen (die neue RDDs erstellen) und Aktionen (die Werte zurückgeben).
Diese Flexibilität ermöglicht verschiedene Verarbeitungsmuster, die über das Map-Reduce-Paradigma hinausgehen.
Spark hat sich über RDDs hinaus weiterentwickelt und bietet Abstraktionen auf höherer Ebene wie DataFrames und Datasetsdie eine schemaabhängige Verarbeitung mit ähnlichen Optimierungen wie bei relationalen Datenbanken ermöglichen. Diese Abstraktionen, kombiniert mit speziellen Bibliotheken für Streaming, SQL, maschinelles Lernenund Graphenverarbeitung ermöglichen es Entwicklern, komplexe Arbeitsabläufe mit deutlich weniger Code auszudrücken als entsprechende MapReduce-Implementierungen und gleichzeitig ein einheitliches Programmiermodell für verschiedene Verarbeitungsparadigmen beizubehalten.
Bei der Bewertung von Big Data-Frameworks müssen Unternehmen nicht nur die technischen Möglichkeiten, sondern auch die finanziellen Auswirkungen ihrer Einführung und ihres Betriebs berücksichtigen.
Hadoop und Spark haben grundlegend unterschiedliche Hardware-Vorlieben, die sich auf die Infrastrukturkosten auswirken. Hadoop wurde so konzipiert, dass Festplattenspeicher Vorrang vor Arbeitsspeicher hat, wodurch es sich gut für handelsübliche Hardware mit begrenztem RAM, aber großer Festplattenkapazität eignet.
Diese Architektur kann die anfänglichen Hardware-Investitionen reduzieren, insbesondere bei der Verarbeitung extrem großer Datenmengen, bei denen speicherbasierte Lösungen unerschwinglich teuer wären.
Das In-Memory-Verarbeitungsmodell von Spark bietet Leistungsvorteile, erfordert aber deutlich mehr Arbeitsspeicher pro Knoten. Ein richtig konfigurierter Spark-Cluster erfordert in der Regel Server mit umfangreichen Speicherkonfigurationen - oft 16 GB bis 256 GB pro Knoten, je nach Arbeitslast.
Obwohl die Speicherkosten im Laufe der Zeit gesunken sind, kann diese Anforderung die Hardwarekosten im Vergleich zu festplattenbasierten Hadoop-Implementierungen immer noch erhöhen.
Die Betriebskosten gehen über die Anschaffung der Hardware hinaus und umfassen auch die laufende Wartung, Strom, Kühlung und den Platz im Rechenzentrum. Hadoop-Cluster haben in der Regel einen größeren physischen Fußabdruck, da sie auf zahlreiche Commodity-Server mit umfangreichem Speicher angewiesen sind.
Dieser größere Platzbedarf führt zu höheren Kosten für Strom, Kühlung und Rack-Platz.
Spark-Cluster können manchmal die gleiche Verarbeitungsleistung mit weniger Knoten erreichen, da sie die Rechenressourcen effizienter nutzen und so den Platzbedarf im Rechenzentrum und die damit verbundenen Kosten reduzieren. Allerdings verbrauchen die benötigten Maschinen mit höherer Spezifikation möglicherweise mehr Strom pro Knoten, was diese Einsparungen teilweise wieder ausgleicht.
Die Komplexität der Implementierung und Wartung kann sich erheblich auf die Gesamtbetriebskosten auswirken. Das Hadoop-Ökosystem erforderte traditionell spezielle Kenntnisse in der Java-Programmierung und Unix-Administration, wobei die Entwicklungszyklen aufgrund der ausführlichen MapReduce-Programmierung sehr lang sein konnten.
Spark bietet mehr zugängliche APIs in PythonScala, R und Java, was die Entwicklungszeit und die damit verbundenen Personalkosten verringern kann.
Das intuitivere Programmiermodell kann sowohl die Lernkurve als auch die Entwicklungszeit verkürzen, so dass die Unternehmen ihre Lösungen schneller und mit weniger Fachpersonal umsetzen können.
Für kostenbewusste Organisationen bieten hybride Ansätze oft den besten Wert. Durch die Verwendung von HDFS für die Speicherung und Spark für die Verarbeitung kann die kostengünstige Speicherung von Hadoop mit der Verarbeitungseffizienz von Spark kombiniert werden. Cloud-basierte Bereitstellungen auf Diensten wie AWS EMR, Azure HDInsight oder Google Dataproc ermöglichen es Unternehmen, nur für die genutzten Ressourcen zu zahlen, ohne große Vorabinvestitionen zu tätigen.
Unternehmen sollten auch die Kosten für die Skalierbarkeit berücksichtigen. Hadoop erfordert traditionell manuelle Eingriffe für die Skalierung, was den betrieblichen Aufwand erhöht. Die Kompatibilität von Spark mit Container-Orchestrierungsplattformen wie Kubernetes ermöglicht eine automatisierte, elastische Skalierung, die die Ressourcenbereitstellung besser an den tatsächlichen Bedarf anpasst und so die Kapazitätsverschwendung reduziert.
Hier ist eine Tabelle, die die Unterschiede zusammenfasst:
|
Feature |
Hadoop |
Spark |
|
Verarbeitungsmodell |
Stapelverarbeitung mit MapReduce |
In-Memory-Verarbeitung mit RDDs, DataFrames und Datasets |
|
Leistung |
Langsamer aufgrund der Festplatten-E/A zwischen den Stufen |
Bis zu 100x schneller für iterative und In-Memory-Workloads |
|
Speichernutzung |
Festplattenorientiert, geringer Speicherbedarf |
Speicherintensiv, hohe RAM-Anforderungen |
|
Einfachheit der Entwicklung |
Ausführlich; erfordert das explizite Schreiben von Map- und Reduce-Logik |
High-Level-APIs in Python, Scala, R, Java; weniger Boilerplate |
|
Fehlertoleranz |
Datenreplikation über HDFS |
RDD Lineage ermöglicht Neuberechnung im Falle eines Fehlers |
|
Verarbeitung in Echtzeit |
Nicht ideal; nur Batch |
Unterstützt Echtzeitverarbeitung über Spark Streaming |
|
Cluster Manager |
YARN |
Eigenständig, YARN, Mesos oder Kubernetes |
|
Lagerung |
Wird mit HDFS geliefert |
Abhängig von externem Speicher (z. B. HDFS, S3, GCS) |
|
Kosten |
Geringere Hardwarekosten (handelsübliche Maschinen, festplattenbasiert) |
Höhere Speicherkosten, aber bessere Ressourcennutzung pro Arbeitslast |
|
Am besten für |
Batch-Jobs, Massenspeicher, historische Datenanalyse |
Maschinelles Lernen, Stream Processing, interaktive Analysen |
|
Integration |
Starkes Hadoop-Ökosystem (Hive, Pig, etc.) |
Einheitliche APIs für SQL, MLlib, GraphX und Streaming in einer einzigen Plattform |
Hadoop und Spark sind eher komplementäre Ansätze für die Verarbeitung von Big Data als strikte Konkurrenten. Hadoop zeichnet sich durch sein kosteneffizientes Speichersystem (HDFS) und seine stapelorientierte Verarbeitung für große Datenmengen aus, bei denen der Durchsatz wichtiger ist als die Geschwindigkeit.
Spark glänzt mit seinen In-Memory-Verarbeitungsfunktionen, die eine überragende Leistung für iterative Algorithmen, interaktive Analysen und Echtzeitverarbeitungsanforderungen bieten.
DataCamp bietet verschiedene Ressourcen, wenn du mehr über diese beiden Technologien erfahren möchtest:
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
