Cursus
Ingénieur de données en Python
40 h
Hadoop et Spark sont deux des frameworks les plus en vue dans le domaine du big data ; ils gèrent le traitement des données à grande échelle de manière très différente. Si l'on peut attribuer à Hadoop la démocratisation du paradigme de l'informatique distribuée grâce à un système de stockage robuste appelé HDFS et à un modèle de calcul appelé MapReduce, Spark change la donne grâce à son architecture en mémoire et à son modèle de programmation flexible.
Ce tutoriel plonge en profondeur dans les différences entre Hadoop et Spark, notamment leur architecture, leurs performances, les considérations de coût et les intégrations. À la fin, le lecteur aura une compréhension claire des avantages et des inconvénients de chacun, et des types de cas d'utilisation où chaque cadre excelle ; cette compréhension vous aidera à prendre des décisions stratégiques lors de l'élaboration de vos solutions big data.
Avant de plonger dans des détails spécifiques, explorons les concepts fondamentaux et les origines de Hadoop et Spark pour comprendre comment ces cadres puissants abordent les défis du big data.

Hadoop est un cadre open-source conçu pour stocker et traiter de grands ensembles de données sur des grappes d'ordinateurs. Depuis son développement en 2006, Hadoop a permis aux organisations de traiter des volumes de données considérables qui dépasseraient les capacités d'une seule machine. La répartition des données sur plusieurs nœuds permet non seulement d'améliorer la capacité de traitement, mais aussi d'assurer la redondance, ce qui garantit la fiabilité du système même en cas de défaillance d'une machine.
Les principaux composants du cadre Hadoop sont les suivants :
L'un des principaux avantages de Hadoop est sa rentabilité, car il permet aux organisations d'utiliser du matériel standard de base au lieu d'équipements spécialisés coûteux. Cette approche pratique s'étend également à la philosophie de traitement.
La conception d'Hadoop, axée sur le traitement par lots, excelle dans les scénarios où le débit global importe plus que la vitesse de traitement brute, ce qui la rend particulièrement utile pour l'analyse des données historiques et les opérations complexes d'extraction, de transformation et de chargement (ETL). ETL (Extract, Transform, Load) qui n'exigent pas de résultats immédiats.

Apache Spark a vu le jour en 2010 en réponse aux limites de l'approche Hadoop en matière de traitement des données volumineuses. Développé initialement à l'UC Berkeley avant de devenir un projet Apache, Spark s'est attaqué à la forte dépendance d'Hadoop MapReduce aux opérations sur disque. Son innovation majeure a été la mise en œuvre du calcul en mémoire, qui réduit considérablement le temps de traitement pour de nombreuses charges de travail en minimisant la nécessité de lire et d'écrire sur le disque.
Spark fournit une plateforme unifiée avec plusieurs composants étroitement intégrés construits autour de son moteur de traitement central :
Cette conception cohésive permet aux équipes de relever divers défis en matière de données à l'aide d'un cadre unique plutôt que de jongler avec plusieurs outils spécialisés.
Malgré leurs différences, Spark et Hadoop travaillent souvent ensemble comme des technologies complémentaires plutôt que concurrentes. Spark n'incluant pas son propre système de stockage, il s'appuie généralement sur HDFS d'Hadoop pour le stockage des données persistantes.
En outre, Spark peut fonctionner sur le gestionnaire de ressources YARN d'Hadoop, ce qui permet aux entreprises d'améliorer facilement les environnements Hadoop existants avec la puissance de traitement de Spark. Cette compatibilité crée un chemin de mise à niveau pratique qui permet aux entreprises d'adopter les avantages de Spark sans abandonner leurs investissements dans l'infrastructure Hadoop.
Lors de l'évaluation des cadres de big data, la performance devient souvent un facteur décisif pour les organisations dont les besoins en matière de traitement des données sont sensibles au temps.
MapReduce de Hadoop fonctionne comme un système de traitement sur disque, qui lit les données sur le disque, les traite et écrit les résultats sur le disque entre chaque étape du calcul. Ces E/S sur disque entraînent une latence importante, en particulier pour les algorithmes itératifs qui nécessitent plusieurs passages sur les mêmes données.
Bien qu'efficace pour le traitement par lots de données massives, cette approche sacrifie la vitesse au profit de la fiabilité et du débit.
Spark, en revanche, effectue les calculs principalement en mémoire, ce qui réduit considérablement le besoin d'opérations sur disque. Pour de nombreuses charges de travail, en particulier les algorithmes itératifs comme ceux utilisés dans l'apprentissage automatique, Spark peut exécuter des tâches jusqu'à 100 fois plus rapidement que Hadoop MapReduce.
Cet avantage en termes de performances est particulièrement prononcé lorsque le traitement doit se faire en temps quasi réel ou lorsque les algorithmes nécessitent plusieurs passages sur le même ensemble de données.
La conception de Hadoop repose sur l'hypothèse d'une disponibilité limitée de la mémoire, ce qui le rend efficace en termes de mémoire mais plus lent. Il s'appuie fortement sur le stockage sur disque, ce qui lui permet de traiter des ensembles de données beaucoup plus importants que la mémoire vive disponible en échangeant constamment des données entre la mémoire et le disque.
Cette approche permet à Hadoop de traiter des ensembles de données extrêmement volumineux sur des clusters disposant de ressources mémoire limitées.
Les avantages de Spark en termes de performances proviennent de son utilisation agressive de la mémoire. En mettant en cache les données dans la mémoire vive au fil des étapes de traitement, Spark élimine les opérations coûteuses sur les disques. Toutefois, cela nécessite des ressources de mémoire suffisantes pour contenir les ensembles de données de travail.
Lorsque des contraintes de mémoire apparaissent, l'avantage de Spark en termes de performances diminue car il commence à déverser des données sur le disque, même si sa gestion intelligente de la mémoire reste généralement plus performante que l'approche disk-first d'Hadoop.
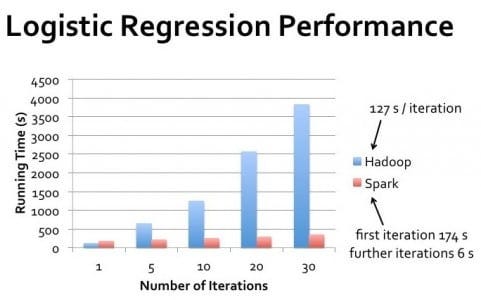
L'écart de performance dans le monde réel entre Hadoop et Spark varie considérablement en fonction des cas d'utilisation spécifiques. Pour le traitement par lots en un seul passage d'ensembles de données massifs où les données dépassent largement la mémoire disponible, les performances d'Hadoop peuvent se rapprocher de celles de Spark.
Cependant, pour les traitements itératifs, les requêtes interactives et le traitement des flux, Spark offre systématiquement des performances supérieures.
Il convient de noter que les performances ne se limitent pas à la vitesse brute. Hadoop excelle dans les scénarios nécessitant une grande tolérance aux pannes et dans lesquels le traitement peut se faire dans des fenêtres de traitement par lots clairement définies.
Spark est plus performant lorsque des résultats rapides sont nécessaires, comme l'exploration interactive des données, l'analyse en temps réel et les applications d'apprentissage automatique où les algorithmes effectuent plusieurs passages dans les ensembles de données.
Hadoop et Spark s'appuient tous deux sur des clusters pour traiter efficacement de gros volumes de données, mais ils gèrent ces ressources différemment, ce qui affecte à la fois les performances et l'administration.
Une grappe est un ensemble d'ordinateurs interconnectés (nœuds) qui fonctionnent ensemble comme un système unique. Dans le traitement des données volumineuses, le regroupement devient nécessaire lorsque les volumes de données dépassent ce qu'une seule machine peut traiter efficacement. En répartissant les charges de calcul sur plusieurs machines, les grappes permettent aux entreprises de traiter des pétaoctets de données qui seraient autrement impossibles à gérer.
La mise en grappe permet également d'assurer la tolérance aux pannes et la haute disponibilité. Si une machine tombe en panne, les autres machines de la grappe peuvent prendre en charge sa charge de travail, ce qui garantit un fonctionnement continu. Cette résilience est cruciale pour les environnements de production où les temps d'arrêt peuvent être coûteux.
En outre, la mise en grappe permet une mise à l'échelle horizontale, c'est-à-dire l'ajout de machines supplémentaires pour augmenter la puissance de traitement, ce qui est souvent plus rentable que la mise à niveau de systèmes individuels.
Pour les aspirants professionnels dans ce domaine, la compréhension du clustering est une compétence fondamentale dans l'ingénierie des données. ingénierie des données.
Les grappes Hadoop suivent une architecture maître-esclave avec des rôles spécialisés pour les différents nœuds. Le NameNode sert de maître pour HDFSen conservant les métadonnées relatives à l'emplacement et aux autorisations des fichiers. Les nœuds de données (DataNodes) stockent les blocs de données réels et les transmettent au nœud de nom (NameNode).
Pour le traitement, le ResourceManager alloue les ressources du cluster, tandis que les NodeManagers des machines individuelles exécutent les tâches.
HDFS réplique les données sur plusieurs DataNodes, en conservant généralement trois copies de chaque bloc de données. Cette stratégie de réplication garantit la disponibilité des données même en cas de défaillance d'un nœud individuel, bien qu'elle nécessite une capacité de stockage supplémentaire.
La conception du cluster Hadoop met l'accent sur la localité des données, en essayant de programmer les tâches de calcul sur les mêmes nœuds que ceux où résident les données, afin de minimiser les transferts sur le réseau.
L'administration des clusters Hadoop nécessitait traditionnellement une expertise importante (les professionnels se préparent souvent à des entretiens d'embauche). questions d'entretien Hadoop pour démontrer ces connaissances), bien que les distributions modernes incluent des outils de gestion pour simplifier la configuration et la surveillance.
La mise à l'échelle d'un cluster Hadoop implique l'ajout de nouveaux nœuds et le rééquilibrage des données dans l'infrastructure étendue, ce qui peut être un processus manuel nécessitant une planification minutieuse.
Spark peut fonctionner dans différentes configurations de cluster, notamment en mode autonome, sur Hadoop YARN, Apache Mesos ou Kubernetes. Dans tous les déploiements, Spark suit un modèle pilote-exécutant. Le programme pilote contient la fonction principale de l'application et crée un SparkContext qui coordonne l'allocation des ressources avec le gestionnaire de cluster.
Une fois les ressources allouées, les exécuteurs Spark sont lancés sur les nœuds de travail. Ces exécuteurs sont des processus de la JVM qui exécutent des tâches et stockent des données dans la mémoire ou sur le disque. Contrairement à Hadoop, qui maintient une présence persistante sur les nœuds du cluster, les exécuteurs de Spark peuvent être alloués et libérés dynamiquement en fonction des besoins de l'application, ce qui améliore potentiellement l'utilisation des ressources.
Les lecteurs intéressés peuvent explorer plus avant les capacités de Spark grâce à des tutoriels pratiques tels que Apache Spark pour l'apprentissage automatique.
Spark n'inclut pas son propre système de stockage distribué, s'appuyant plutôt sur des solutions existantes comme HDFS, Amazon S3ou d'autres systèmes de stockage compatibles. Cette séparation de l'architecture entre le calcul et le stockage offre une certaine flexibilité, mais nécessite une configuration minutieuse pour garantir des schémas d'accès aux données optimaux.
Outils tels que Spark SQL et sparklyr offrent des moyens pratiques d'interagir avec cette architecture.
L'approche de Hadoop en matière de gestion de grappes est plus centrée sur l'infrastructure, avec une allocation de ressources relativement statique et un accent mis sur la localité des données. Cette conception fonctionne bien pour les travaux par lots de longue durée sur des grappes stables où les nœuds changent rarement.
Cependant, il peut être moins réactif aux variations de la charge de travail et nécessite davantage d'interventions manuelles lors de la mise à l'échelle.
Spark offre une gestion plus dynamique des ressources, en particulier lorsqu'il est exécuté sur des plateformes d'orchestration modernes comme Kubernetes. Il peut ajuster l'allocation des ressources en fonction des demandes actuelles et libérer les ressources lorsqu'elles ne sont pas nécessaires.
Cette élasticité est précieuse pour les organisations dont les charges de travail fluctuent ou dont l'infrastructure partagée sert plusieurs applications.
Il est essentiel de comprendre ces différences pour les professionnels qui souhaitent obtenir une certification d'ingénieur en données. certification d'ingénieur de données ou qui se préparent à répondre à des questions d'entretien avec questions d'entretien avec Spark.
Pour les organisations qui débutent dans le big data, les options de déploiement plus flexibles et le modèle de programmation plus simple de Spark facilitent souvent le démarrage.
Cependant, dans les environnements avec des volumes de données extrêmement importants où la gestion du stockage est une préoccupation majeure, l'écosystème HDFS mature d'Hadoop offre encore des avantages qui complètent les capacités de traitement de Spark. Pour une comparaison de Spark avec d'autres technologies de streaming, les lecteurs pourront trouver des comparaisons comme Flink vs. Spark informatif.
Alors que les sections précédentes ont abordé les implications en termes de performances, la compréhension des modèles de traitement fondamentaux de chaque cadre permet d'expliquer pourquoi leur architecture est si différente.
MapReduce suit un paradigme de programmation rigide avec deux phases principales : map et reduce. La phase de mappage applique une fonction à chaque enregistrement en parallèle, générant des paires clé-valeur intermédiaires.
Ces paires sont soumises à une phase obligatoire de mélange et de tri, au cours de laquelle les données ayant les mêmes clés sont regroupées.
Enfin, la phase de réduction agrège ces valeurs groupées pour produire les résultats finaux. Cette approche structurée signifie que les opérations complexes nécessitent l'enchaînement de plusieurs tâches MapReduce.
Le développement d'applications MapReduce implique généralement l'écriture d'un code de bas niveau qui définit explicitement les fonctions de mappage et de réduction.
Alors que des frameworks comme Apache Pig et Apache Hive fournissent des abstractions de plus haut niveau, l'exécution sous-jacente suit toujours le modèle MapReduce strict, ce qui impose des limites à la conception des algorithmes et aux possibilités d'optimisation.
Introduction de Spark RDD (Resilient Distributed Datasets, ensembles de données distribuées résilientes) comme abstraction de base - des collections immuables et partitionnées qui peuvent suivre leur lignage pour la récupération. Contrairement à MapReduce, Spark n'impose pas de schéma de traitement rigide, mais propose deux types d'opérations : les transformations (qui créent de nouveaux RDD) et les actions (qui renvoient des valeurs).
Cette flexibilité permet d'appliquer divers modèles de traitement au-delà du paradigme map-reduce.
Spark a évolué au-delà des RDD pour offrir des abstractions de plus haut niveau telles que. DataFrame et Datasetsqui permettent un traitement tenant compte des schémas avec des optimisations similaires à celles des bases de données relationnelles. Ces abstractions, combinées à des bibliothèques spécialisées pour le streaming, SQL, l'apprentissage automatiqueet le traitement des graphes, permettent aux développeurs d'exprimer des flux de travail complexes avec beaucoup moins de code que les implémentations MapReduce équivalentes, tout en conservant un modèle de programmation unifié pour les différents paradigmes de traitement.
Lorsqu'elles évaluent les cadres de big data, les organisations doivent tenir compte non seulement des capacités techniques, mais aussi des implications financières de leur déploiement et de leur fonctionnement.
Hadoop et Spark ont des préférences matérielles fondamentalement différentes qui ont un impact sur les coûts d'infrastructure. Hadoop a été conçu pour donner la priorité au stockage sur disque plutôt qu'à la mémoire, ce qui le rend bien adapté au matériel de base doté d'une mémoire vive limitée mais d'une capacité de disque dur substantielle.
Cette architecture permet de réduire l'investissement initial en matériel, en particulier lors du traitement d'ensembles de données extrêmement volumineux pour lesquels les solutions à base de mémoire seraient d'un coût prohibitif.
Le modèle de traitement en mémoire de Spark offre des avantages en termes de performances, mais nécessite beaucoup plus de mémoire vive par nœud. Un cluster Spark correctement configuré exige généralement des serveurs avec des configurations de mémoire substantielles - souvent de 16 Go à 256 Go par nœud en fonction des caractéristiques de la charge de travail.
Bien que les coûts de mémoire aient diminué au fil du temps, cette exigence peut encore augmenter les dépenses matérielles par rapport aux déploiements Hadoop centrés sur le disque.
Les coûts opérationnels vont au-delà de l'acquisition de matériel et comprennent la maintenance courante, l'électricité, le refroidissement et l'espace du centre de données. Les clusters Hadoop ont tendance à avoir des empreintes physiques plus importantes en raison de leur dépendance à l'égard de nombreux serveurs de base dotés d'un vaste espace de stockage.
Cet encombrement plus important se traduit par des coûts plus élevés en termes d'alimentation, de refroidissement et d'espace de stockage.
Les clusters Spark peuvent parfois atteindre les mêmes capacités de traitement avec moins de nœuds en raison de leur utilisation plus efficace des ressources informatiques, ce qui permet potentiellement de réduire l'empreinte des centres de données et les coûts associés. Toutefois, les machines plus sophistiquées requises peuvent consommer plus d'énergie par nœud, ce qui annule en partie ces économies.
La complexité de la mise en œuvre et de la maintenance peut avoir un impact significatif sur le coût total de possession. L'écosystème Hadoop nécessitait traditionnellement des compétences spécialisées en programmation Java et en administration Unix, avec des cycles de développement qui pouvaient être longs en raison de la nature verbeuse de la programmation MapReduce.
Spark offre des API plus accessibles en PythonScala, R et Java, ce qui peut réduire le temps de développement et les coûts de personnel associés.
Le modèle de programmation plus intuitif peut réduire à la fois la courbe d'apprentissage et le temps de développement, ce qui permet aux organisations de mettre en œuvre des solutions plus rapidement avec un personnel moins spécialisé.
Pour les organisations sensibles aux coûts, les approches hybrides offrent souvent le meilleur rapport qualité-prix. Utiliser HDFS pour le stockage tout en tirant parti de Spark pour le traitement peut permettre de combiner le stockage rentable d'Hadoop et l'efficacité de traitement de Spark. Les déploiements dans le cloud sur des services tels que AWS EMR, Azure HDInsight ou Google Dataproc permettent aux organisations de ne payer que pour les ressources utilisées, sans grandes dépenses initiales.
Les organisations doivent également tenir compte des coûts d'évolutivité. Hadoop nécessite traditionnellement une intervention manuelle pour la mise à l'échelle, ce qui ajoute des frais généraux opérationnels. La compatibilité de Spark avec les plateformes d'orchestration de conteneurs comme Kubernetes permet une mise à l'échelle plus automatisée et plus élastique qui peut mieux faire correspondre le provisionnement des ressources à la demande réelle, réduisant potentiellement la capacité gaspillée.
Voici un tableau comparatif résumant leurs différences :
|
Fonctionnalité |
Hadoop |
Spark |
|
Modèle de traitement |
Traitement par lots à l'aide de MapReduce |
Traitement en mémoire à l'aide de RDD, DataFrame et Datasets |
|
Performance |
Ralentissement dû aux E/S sur disque entre les étapes |
Jusqu'à 100 fois plus rapide pour les charges de travail itératives et en mémoire |
|
Utilisation de la mémoire |
Centré sur le disque, peu d'exigences en matière de mémoire |
Mémoire intensive, exigences élevées en matière de RAM |
|
Facilité de développement |
Verbeux ; nécessite l'écriture explicite de la logique map & reduce |
API de haut niveau en Python, Scala, R, Java ; moins de "boilerplate". |
|
Tolérance de panne |
Réplication des données via HDFS |
Le lignage RDD permet de recalculer les données en cas d'échec. |
|
Traitement en temps réel |
Pas idéal ; uniquement par lots |
Prise en charge du traitement en temps réel via Spark Streaming. |
|
Gestionnaire de cluster |
YARN |
Autonome, YARN, Mesos ou Kubernetes |
|
Stockage |
Livré avec HDFS |
Dépend du stockage externe (par exemple, HDFS, S3, GCS) |
|
Coût |
Coût inférieur du matériel (machines de base, sur disque) |
Coût de mémoire plus élevé mais meilleure utilisation des ressources par charge de travail |
|
Meilleur pour |
Travaux par lots, stockage à grande échelle, analyse de données historiques |
Apprentissage automatique, traitement des flux, analyse interactive |
|
Intégration |
Solide écosystème Hadoop (Hive, Pig, etc.) |
API unifiées pour SQL, MLlib, GraphX et Streaming dans une plateforme unique |
Hadoop et Spark représentent des approches complémentaires du traitement des big data plutôt que des concurrents stricts. Hadoop excelle grâce à son système de stockage rentable (HDFS) et à son traitement par lots pour les données massives où le débit compte plus que la vitesse.
Spark brille par ses capacités de traitement en mémoire qui offrent des performances supérieures pour les algorithmes itératifs, les analyses interactives et les besoins de traitement en temps réel.
DataCamp propose différentes ressources si vous souhaitez en savoir plus sur ces deux technologies :
Les meilleurs cours de DataCamp
Cursus
Cours
Cours