Curso
Preprocesamiento para machine learning en Python
4 h
66.5K

Foto de Cederic Vandenberghe en Unsplash
Un príncipe desterrado se encuentra ante su antiguo castillo. Para volver a entrar, lo ha intentado todo para engañar al guardia del puente levadizo. Se disfrazó de campesino, solicitó la contraseña secreta e intentó sustituir a los caballeros por sus leales lacayos. Incluso envió a la muerte a corrientes de soldados para que comprendieran las nuevas defensas del castillo. Nada funcionó. Las defensas son demasiado fuertes, los guardias demasiado reservados y el proceso de investigación de los caballeros demasiado minucioso.
En los tiempos modernos, los modelos de aprendizaje automático (AM) se enfrentan a ataques similares.
Los modelos son cosas complicadas y, a menudo, no entendemos bien cómo hacen predicciones. Esto deja puntos débiles ocultos que podrían ser explotados por los atacantes. Podrían engañar al modelo para que hiciera predicciones incorrectas o revelar información sensible. Incluso podrían utilizarse datos falsos para corromper los modelos sin que lo supiéramos. El campo delaprendizaje automático adversarial (AML) de pretende solucionar estos puntos débiles.
Hablaremos de este campo y de lo que pretende conseguir. Esto incluye varios tipos de ataques a los sistemas de IA, como el envenenamiento, la evasión y los ataques de extracción de modelos. También discutiremos algunas formas más prácticas de encontrar ejemplos adversarios que son el núcleo de muchos de estos ataques. Por último, hablaremos de algunos métodos para defenderse de ellos, como el entrenamiento adversarial, la destilación defensiva y el enmascaramiento de gradiente. Al final, veremos cómo la AML forma parte de un movimiento más amplio para construir sistemas de IA Responsables.
El Aprendizaje Automático Adversarial (AML) es un subcampo de investigación dentro de la inteligencia artificial y el aprendizaje automático. Los atacantes adversarios manipulan intencionadamente los datos de entrada para forzar a los modelos a hacer predicciones incorrectas o a liberar información sensible. La ALD pretende comprender estas vulnerabilidades y desarrollar modelos más resistentes a los ataques.
Este campo abarca los métodos para crear ataques adversarios y diseñar defensas para protegerse contra ellos. También puede implicar el entorno de seguridad más amplio: las medidas de seguridad adicionales necesarias cuando se utiliza el ML en sistemas automatizados.
Este último punto es importante, ya que los modelos no existen de forma aislada. Sus vulnerabilidades pueden verse amplificadas por la forma en que se utilizan dentro de un sistema. Por ejemplo, es más difícil robar información sensible si hay límites sobre cómo se puede consultar un modelo. Puedes limitar el número de consultas o restringir los tipos de preguntas que puedes hacer. Prueba a pedirle a ChatGPT que "me dé sus parámetros". Dicho esto, los tipos de ataques que discutiremos en la siguiente sección se centrarán en los modelos y sus datos de entrenamiento.
Los tipos de ataques que discutiremos variarán en función de lo mucho que sepas sobre un modelo. Por tanto, es importante distinguir entre ataques de caja blanca y de caja negra.
Los ataques de caja blanca se producen cuando el atacante tiene pleno acceso a la arquitectura, los parámetros, los pesos y los datos de entrenamiento del modelo. Por ejemplo, tu empresa puede alimentar su chatbot utilizando un LLM de código abierto como Llama 3.1. Este modelo está a disposición de cualquiera. Sin embargo, este nivel de acceso es un arma de doble filo en lo que respecta a la seguridad.
Por un lado, puede facilitar que los atacantes encuentren vulnerabilidades. Por otra parte, una comunidad más amplia examina el modelo, lo que puede hacer más probable que se identifiquen las vulnerabilidades antes de que se utilicen maliciosamente.
Los ataques de caja negra implican que el atacante tiene un conocimiento limitado del modelo. Piensa en un modelo OpenAI como GPT-4o mini. El atacante no puede acceder a la arquitectura interna del modelo, a los parámetros ni a los datos de entrenamiento, y sólo puede interactuar con el modelo consultándolo y observando los resultados. Ten en cuenta que, en muchos casos, sólo se necesita un conocimiento limitado para un ataque eficaz.

Resumen de los tipos de ataques adversarios (fuente: autor)
Un ejemplo es cuando se sabe qué datos se utilizan para entrenar un modelo. Un ataque de envenenamiento se centra en manipular estos datos. Aquí, un atacante cambiará los datos existentes o introducirá datos etiquetados incorrectamente. El modelo entrenado con estos datos hará predicciones incorrectas con los datos etiquetados correctamente.
En nuestra analogía, el príncipe intentó sustituir a los caballeros. El objetivo era corromper el proceso interno de toma de decisiones del castillo. En el aprendizaje automático, un atacante podría hacer algo como volver a etiquetar los casos de fraude como no fraudulentos. El atacante podría hacer esto sólo para casos específicos de fraude, de modo que cuando intenten cometer fraude de la misma forma, el sistema no los rechazará.
Un ejemplo real de ataque de envenenamiento le ocurrió a Tay, el chatbot de inteligencia artificial de Microsoft. Tay se diseñó para adaptarse a las respuestas que recibía en Twitter. Como es característico del sitio, el bot no tardó en inundarse de contenido ofensivo e inapropiado. Aprendiendo de esto, Tay tardó menos de 24 horas en empezar a producir tweets similares. Cualquier sistema diseñado para aprender de fuentes de datos públicas se enfrenta a riesgos similares.
El otro factor de riesgo es la frecuencia con la que se actualiza el modelo. En muchas aplicaciones, los modelos se entrenan una sola vez. En tales casos, tanto los datos como el modelo se comprobarían minuciosamente, lo que dejaría pocas oportunidades a los ataques de envenenamiento. Sin embargo, algunos sistemas, como Tay, se reentrenan continuamente. Estos modelos pueden actualizarse con nuevos datos a diario, semanalmente o incluso en tiempo real. En consecuencia, en estos entornos hay más posibilidades de ataques de envenenamiento.
Los ataques de evasión se centran en el propio modelo. Consisten en modificar los datos para que parezcan legítimos, pero conducen a una predicción incorrecta. Como cuando nuestro príncipe intentó colarse entre los guardias vestido de campesino.
Para que quede claro, el atacante modifica los datos que un modelo utiliza para hacer predicciones y no los datos utilizados para entrenar modelos. Por ejemplo, al solicitar un préstamo, un atacante podría enmascarar su verdadero país de origen utilizando una VPN. Pueden proceder de un país de riesgo, y si el atacante utilizara su verdadero país, el modelo rechazaría su solicitud.
Este tipo de ataques son más frecuentes en campos como el reconocimiento de imágenes. Los atacantes pueden crear imágenes que parezcan perfectamente normales a un humano, pero que den lugar a predicciones incorrectas. Por ejemplo investigadores de Google mostraron cómo la introducción de un ruido específico en una imagen podía cambiar la predicción de un modelo de reconocimiento de imágenes.
Si observas la Figura 1, verás que, para un humano, la capa de ruido no es perceptible. Sin embargo, el modelo, que originalmente predijo la imagen como un panda, ahora la predice incorrectamente como un gibón.

Figura 1: Ejemplo de adversario (Fuente: I. Goodfellow et al.)
Con los ataques de robo o extracción de modelos, los atacantes pretenden conocer la arquitectura y los parámetros del modelo. El objetivo es reproducir exactamente el modelo. Esta información puede dar lugar a un beneficio económico directo. Por ejemplo, un modelo de negociación de acciones podría copiarse y utilizarse para negociar acciones. Un atacante también podría utilizar esta información para crear ataques posteriores más eficaces.
Los ataques de extracción de modelos se realizan consultando el modelo repetidamente y comparando la entrada con la salida correspondiente. Piensa en nuestro príncipe enviando soldados: uno puede ser herido por una flecha, otro empapado en aceite caliente o todo un grupo aplastado por rocas voladoras. Poco a poco, con el tiempo, podemos llegar a comprender bien qué defensas guarda el castillo tras su muralla.
A menudo, a los atacantes no les interesa todo el modelo, sino sólo alguna información concreta, como una contraseña secreta. Los ataques de inferencia se centran en los datos utilizados para entrenar el modelo. El objetivo es extraer datos confidenciales del modelo. Mediante consultas cuidadosamente elaboradas, esta información puede liberarse directamente o inferirse del resultado del modelo.
Estos tipos de ataques son especialmente preocupantes para grandes modelos lingüísticos (LLM).
En el artículo Extracción de datos de entrenamiento de grandes modelos lingüísticoslos investigadores mostraron cómo se podía extraer información sensible del GPT-2. Utilizando consultas específicas, podían extraer texto literal de los datos de entrenamiento del modelo, incluida información sensible y privada. Esto incluía datos personales, conversaciones privadas y otros datos confidenciales.
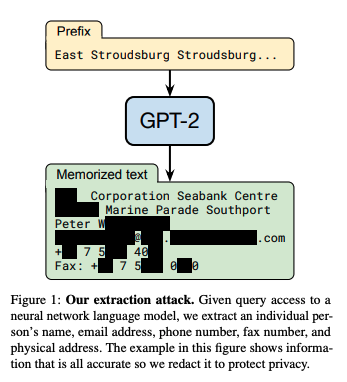
Fuente: N. Carlini et al.
Los objetivos y procesos de estos ataques difieren. Sin embargo, todas tienen algo en común: consisten en encontrar instancias que ayuden a los atacantes a engañar a un modelo. A estos ejemplos los llamamos adversarios.
Los ejemplos adversarios son entradas creadas especialmente para engañar a los modelos de aprendizaje automático. Estas entradas suelen ser indistinguibles de las entradas legítimas para un observador humano, pero contienen perturbaciones sutiles que aprovechan los puntos débiles del modelo.
Las perturbaciones suelen ser pequeños cambios en los datos de entrada, como ligeras variaciones en los valores de los píxeles. Aunque pequeñas, estas perturbaciones están diseñadas para empujar la entrada más allá del límite de decisión del modelo, lo que lleva a predicciones incorrectas o inesperadas.
Vimos un ejemplo de uno utilizado para engañar a un modelo de visión por ordenador. Con pequeños cambios, una imagen que nos parecía un panda se clasificó como un gibón. La consulta utilizada para extraer información sensible de GPT-2 también es un ejemplo adversario de un ataque de inferencia.
Para los ataques de extracción, se utilizan ejemplos adversarios para sondear más eficazmente los límites de decisión de un modelo. Para los ataques de envenenamiento, son datos de entrada utilizados para manipular el límite de decisión de un modelo.
Estos ejemplos funcionan porque los límites de decisión de los modelos de aprendizaje automático pueden ser bastante complejos y frágiles. Los ejemplos adversarios explotan esta fragilidad encontrando puntos en el espacio de entrada cercanos a estos límites. Entonces, pequeñas perturbaciones pueden empujar la entrada más allá del límite, haciendo que el modelo la clasifique erróneamente. Veamos algunas formas de hacerlo.
Los métodos basados en gradientes utilizan los gradientes de un modelo de aprendizaje automático para crear pequeñas perturbaciones en los datos de entrada que conducen a predicciones incorrectas. El Panda/Gibón es un ejemplo del resultado de uno de estos métodos. El ruido que ves puede parecer aleatorio. Sin embargo, contiene información sobre la función de pérdida del modelo que empujará una imagen a lo largo de un límite de decisión cuando se añada a la imagen.
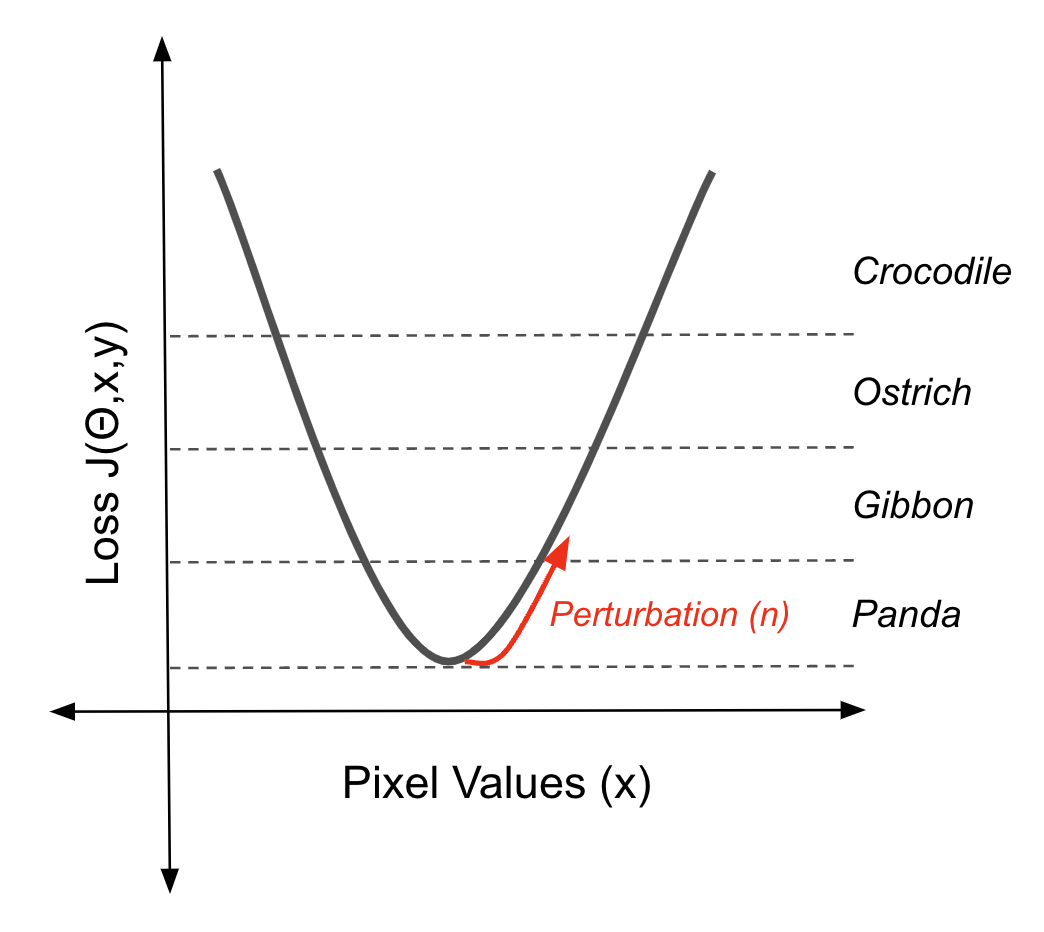
Utilizar el gradiente de la función de pérdida para desplazar una instancia fuera de un límite de decisión (fuente: autor)
Este ejemplo adversarial concreto se creó utilizando elMétodo del Signo Gradiente Rápido (FGSM). El ruido (η) se calcula tomando primero el gradiente(∇x) de la función de pérdida (J(θ,x,y)) con respecto a los datos de entrada (x).
Este gradiente indica la dirección en la que debe cambiarse la entrada para aumentar al máximo la pérdida. A continuación, el FGSM toma el signo de este gradiente, lo que simplifica la dirección del cambio a sólo positivo o negativo para cada píxel. Por último, escala este signo en un pequeño factor (ε). Este ruido (η) es la perturbación que, añadida a la entrada original, empuja la predicción del modelo hacia una clasificación incorrecta.
η = ε sign(∇xJ(θ,x,y))
Puedes pensar en esto como lo contrario de retropropagación. Este algoritmo utiliza los gradientes de la función de pérdida para calcular los parámetros del modelo que nos dan predicciones precisas. El resultado son límites de decisión que clasificarán las imágenes como la clase dada cuando los valores de los píxeles caigan dentro de esos límites. Ahora utilizaremos los degradados para invertir la imagen fuera de esos límites.
El FGSM es una forma sencilla de hacerlo. También hay formas más complejas y eficaces de superar los límites de la decisión. Por ejemplo, Projected Gradient Descent (PGD) es un método iterativo basado en el gradiente para generar ejemplos adversarios. Amplía el Método del Signo Gradiente Rápido (FGSM) aplicando el FGSM varias veces con tamaños de paso más pequeños. A medida que se da cada paso, el signo de los gradientes puede cambiar, alterando la dirección ideal para alejarse del límite de decisión. Así, utilizando muchos pasos más pequeños, el PGD puede encontrar ejemplos adversarios con perturbaciones menores que el FGSM.
La página Carlini y Wagner (C&W) aborda este problema desde un ángulo diferente. Con los ataques anteriores, pretendemos cambiar la predicción por cualquier predicción incorrecta. El ataque C&W pretende encontrar la perturbación más pequeña(δ) que, añadida a una imagen, cambie la predicción (f(x+δ)) para un objetivo dado (t).
min||δ||p s.t. f(x + δ) = t
Para ello, plantean el problema como un problema de optimización. En la práctica, esto requiere que el objetivo anterior se formule de manera diferenciable. Se trata de utilizar los logits Z(x) del del modelo. Éstos proporcionan un gradiente suave que es esencial para el proceso de optimización.
Todos los ataques descritos anteriormente requieren acceso total a un modelo. Por tanto, puedes pensar que si los parámetros de tu modelo se mantienen en secreto, estás a salvo. ¡Te equivocarías!
Hay que tener en cuenta que a menudo sólo se necesitan estimaciones de los gradientes para que el ataque tenga éxito. Hemos visto que para el ataque FGSM sólo se necesita la dirección de los gradientes. Se pueden estimar mediante unos cuantos pings a una API que devuelva probabilidades de clasificación. Para empeorar las cosas, incluso se pueden encontrar ejemplos adversarios exitosos sin interacción con un modelo.
Los investigadores han descubierto que los ejemplos contradictorios son transferibles. En concreto, tomaron 5 arquitecturas populares de aprendizaje profundo preentrenadas. Descubrieron que si un ejemplo adversario engañaba a cuatro de los modelos, había una alta probabilidad de que engañara al 5º modelo. Esto es una probabilidad superior al 96% e incluso al 100% para una de las arquitecturas.
Del mismo modo, ejemplos adversarios universales se demostró que se generalizaban entre arquitecturas. Se trata de una perturbación que, si se añade a muchas imágenes de, cambiará la predicción para esas imágenes. Es importante destacar que los ejemplos universales se encuentran con un conocimiento total de caja blanca de una sola red. En la Figura 2, puedes ver lo similares que son para las distintas arquitecturas. Su existencia sugiere similitudes entre los límites de decisión de las distintas arquitecturas.

Figura 2: ordenador de perturbaciones universales para distintas redes neuronales profundas (fuente: Moosavi-Dezfooli et al.)
La consecuencia de estos hallazgos es que ninguna red es segura. Puedes atacar a un clasificador desconocido entrenando el tuyo propio y ejecutando un método de caja blanca.
Un último resquicio de esperanza es que estos ataques sólo pueden realizarse virtualmente. Tienes que cambiar los valores de los píxeles para que funcionen. Entonces, ¿no puede hacerse lo mismo con los modelos que interactúan con el mundo real?
No hables demasiado pronto.
Los investigadores desarrollaron un método llamado parches adversarios. Se pueden imprimir y añadir a cualquier escena en tiempo real para engañar a un clasificador de imágenes.
Los parches son universales porque pueden utilizarse para atacar cualquier escena, robustos porque funcionan bajo una amplia variedad de transformaciones, y dirigidos porque pueden hacer que un clasificador dé como resultado cualquier clase objetivo.
T. B. Brown et al.
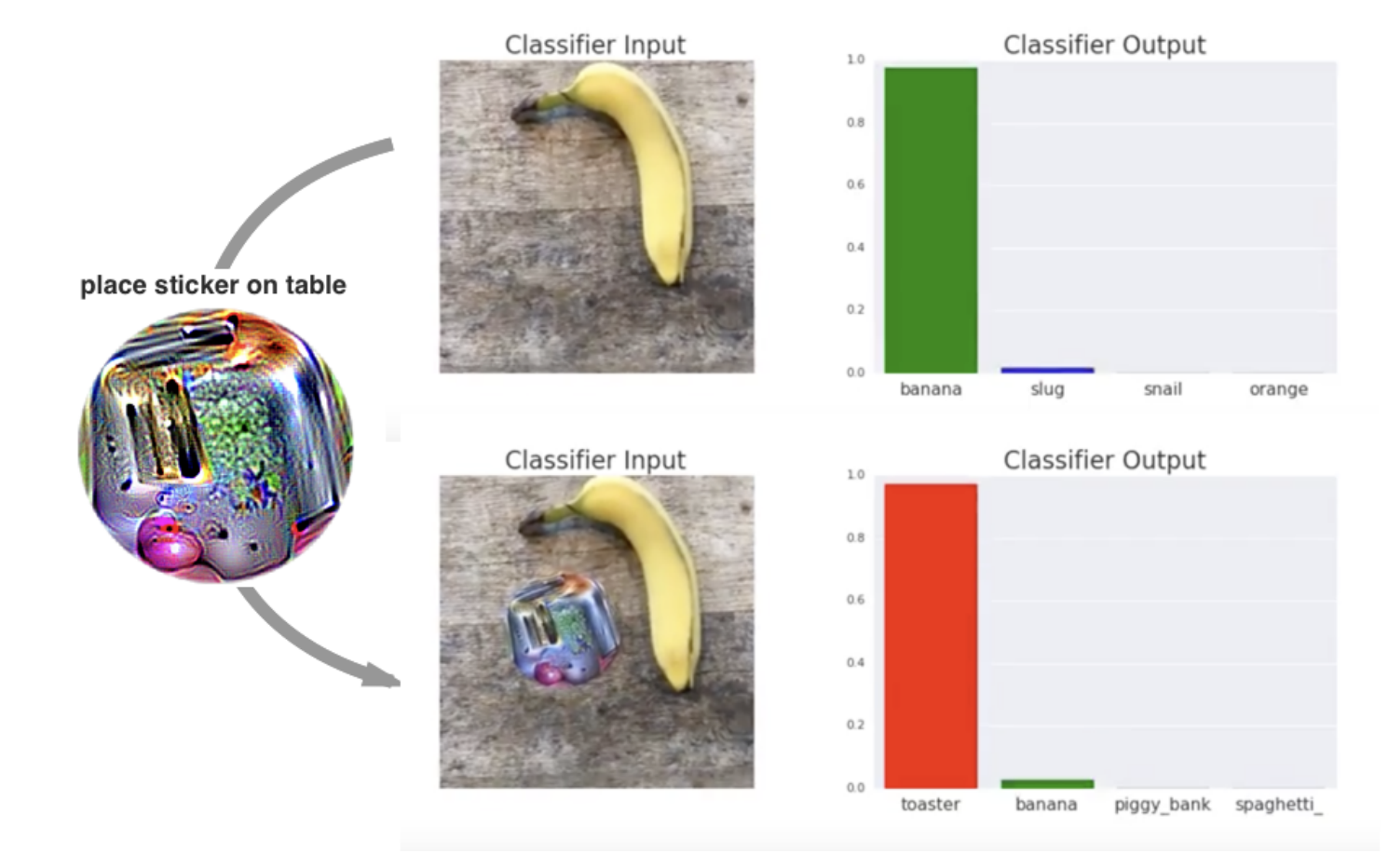
Un parche adversario en acción (fuente: T. B. Brown et al. )
Una investigación similar ha demostrado cómo podemos cambiar la predicción de una señal de stop con unas pegatinas y engañar a un modelo de reconocimiento facial con unas gafas. Así que, realmente, ninguna red es segura. Para protegerlos de los ataques adversarios, pasamos a la otra cara de la ALD: los métodos para defenderlos.
Las formas en que podemos defender las redes son tan diversas como las formas en que pueden ser atacadas. Podemos ajustar los datos de entrenamiento, el proceso de entrenamiento o incluso la propia red. Como comentamos al final de esta sección, a veces la solución más sencilla es no utilizar el aprendizaje profundo en absoluto.
Este primer enfoque se centra en los datos de entrenamiento. El entrenamiento adversarial consiste en aumentar el conjunto de datos de entrenamiento con ejemplos adversariales para mejorar la robustez del modelo frente a los ataques. Estos ejemplos se encuentran utilizando los ataques conocidos mencionados anteriormente. La idea central es exponer el modelo a perturbaciones adversas durante la fase de entrenamiento para que aprenda a reconocer y resistir dichas entradas.
La destilación defensiva consiste en entrenar un modelo para que imite las probabilidades de salida suavizadas de otro modelo. Primero entrenamos un modelo estándar (modelo del profesor) en el conjunto de datos original. El modelo del profesor genera etiquetas blandas (distribuciones de probabilidad sobre las clases) para los datos de entrenamiento. A continuación, se entrena un modelo de alumno con estas etiquetas blandas. El resultado es un modelo con límites de decisión más suaves y resistentes a pequeñas perturbaciones.
El enmascaramiento de degradados incluye diversas técnicas que oscurecen u ocultan los degradados del modelo. Por ejemplo, podemos añadir una capa no diferencial a la red, como una función de activación binaria. Convierte los valores continuos de entrada en salidas binarias.
El cambio de modelo es un enfoque rudimentario de enmascaramiento de gradiente. Esto implica utilizar varios modelos dentro de tu sistema. El modelo utilizado para hacer predicciones se cambia aleatoriamente. Esto crea un blanco móvil, ya que un atacante no sabría qué modelo se está utilizando en ese momento. También tendrán que comprometer a todos los modelos para que un ataque tenga éxito.
La ALD está relacionada con otro campo de la IA: Inteligencia Artificial Explicable (XAI). Los métodos de perturbación que hemos discutido aquí son similares a los utilizados para encontrar explicaciones sobre cómo los modelos hacen predicciones. Sin embargo, la similitud clave es que los modelos sencillos no sólo son más fáciles de explicar, sino que también son más fáciles de defender.
Muchos problemas pueden resolverse con modelos sencillos como la regresión lineal o la regresión logística. Muchos de los ataques que hemos descrito son ineficaces o irrelevantes cuando se trata de éstos.
Esto se debe a que estos modelos son intrínsecamente interpretables, lo que significa que podemos entender fácilmente cómo funcionan. Los puntos débiles no se ocultan como en las arquitecturas complejas de aprendizaje profundo. Por lo tanto, una defensa directa es simplemente no utilizar el aprendizaje profundo a menos que sea necesario para el problema.
Esto está relacionado con el punto del principio del artículo: el AML también afecta al entorno de seguridad más amplio en el que operan los modelos. Como resultado, muchos métodos de defensa adicionales implican a este entorno más amplio. Esto incluye la validación y el saneamiento de los datos de entrada antes de utilizarlos para entrenar un modelo. La detección de anomalías También se han utilizado modelos de detección de anomalías para identificar ejemplos adversos antes de que pasen a la red. Todos ellos requieren procesos que funcionen junto al sistema de IA.
A medida que la IA y el ML adquieren mayor protagonismo en nuestras vidas, la AML adquiere cada vez más importancia. Es crucial que los sistemas que toman decisiones sobre nuestra salud y nuestras finanzas no puedan ser engañados fácilmente. Esto es intencionado o accidental. Yo, desde luego, no me fiaría de un coche automatizado al que unas cuantas pegatinas pudieran engañar. Un ataque de este tipo podría pasar desapercibido para un conductor, pero hacer que el coche tomara decisiones incorrectas y potencialmente mortales.
 Figura X: La detección de objetos v2 de Yolo no reconoce una señal de stop (fuente: K. Eykholt et al.)
Figura X: La detección de objetos v2 de Yolo no reconoce una señal de stop (fuente: K. Eykholt et al.)
Al diseñar estos sistemas, debemos reconocer que la AML forma parte de un movimiento más amplio de IA Responsable. Para dirigir un buen castillo, un rey debe actuar con justicia, justificar las decisiones, proteger la intimidad de su pueblo y garantizar su seguridad y protección. Son estos dos últimos aspectos los que pretende abordar la AML.
Dicho esto, también debemos reconocer que la seguridad y la protección son fundamentalmente diferentes de los demás aspectos de la IA Responsable. La imparcialidad, la interpretabilidad y la privacidad son pasivas. La AML opera en un entorno en el que los malos actores tratan activamente de socavar sus métodos.
Por eso, contraintuitivamente, gran parte de la investigación en este campo tiene como objetivo encontrar vulnerabilidades y ataques. Entre ellos están los ataques de envenenamiento, evasión, extracción de modelos e inferencia. También incluyen los métodos más prácticos para encontrar ejemplos adversarios, como FGSM, PGD, C&W y parches adversarios que hemos comentado.
El objetivo es descubrirlos antes de que lo hagan los malos actores. A continuación, se pueden desarrollar defensas adecuadas, como el entrenamiento adversarial, la destilación de defensas y el enmascaramiento de gradientes, para contrarrestar estos ataques antes de que causen daños.
En este sentido, la lucha contra el blanqueo de capitales también forma parte de la carrera armamentística más amplia de la ciberseguridad. Siempre surgirán nuevas vulnerabilidades, ataques y defensas, y los investigadores y profesionales del AML tendrán que luchar para ir por delante de los atacantes adversarios.
Si quieres participar en esta carrera, aquí tienes algunos frameworks de Python para empezar:
En este artículo, hemos explorado el campo del aprendizaje automático adversarial, examinando sus objetivos, los distintos tipos de ataques (envenenamiento, evasión, extracción de modelos e inferencia) y cómo se utilizan los ejemplos adversariales para explotar las vulnerabilidades de los modelos.
También hablamos de varios mecanismos de defensa, como el entrenamiento adversarial, la destilación defensiva y el enmascaramiento de gradiente, así como de la importancia de utilizar modelos más sencillos cuando proceda.
Si te interesa saber más sobre este tema, consulta esta Introducción a la Seguridad de Datos sobre seguridad de datos.
Más información sobre el aprendizaje automático
Curso
Curso
Curso
blog
Natasha Al-Khatib
14 min
blog
Kurtis Pykes
8 min
blog
Matt Crabtree
14 min
blog
Zoumana Keita
14 min
blog
Natassha Selvaraj
15 min
Tutorial
Joanne Xiong


