
Curso
Conceptos de MLOps
2 h
42.6K
Las operaciones de machine learning (MLOps) se han convertido en uno de los campos más solicitados en el ámbito tecnológico. A medida que los equipos de datos implementan cada vez más modelos de machine learning en entornos de producción, la demanda de profesionales de MLOps seguirá aumentando.
Si estás buscando una carrera como ingeniero de MLOps, ¡estamos aquí para ayudarte a dar ese salto!
En este artículo, te proporcionaremos las preguntas más frecuentes en las entrevistas de MLOps, junto con explicaciones detalladas y respuestas, para ayudarte a prepararte de manera eficaz para tu próxima entrevista.
MLOps, abreviatura de Machine Learning Operations (operaciones de machine learning), es una disciplina que combina machine learning con las prácticas de DevOps para optimizar y automatizar el ciclo de vida de los modelos de machine learning.
El objetivo principal de MLOps es salvar la brecha entre la ciencia de datos y las operaciones de TI, garantizando que los modelos de machine learning se desarrollen de forma eficaz y se implementen, supervisen y mantengan de manera eficiente en entornos de producción.
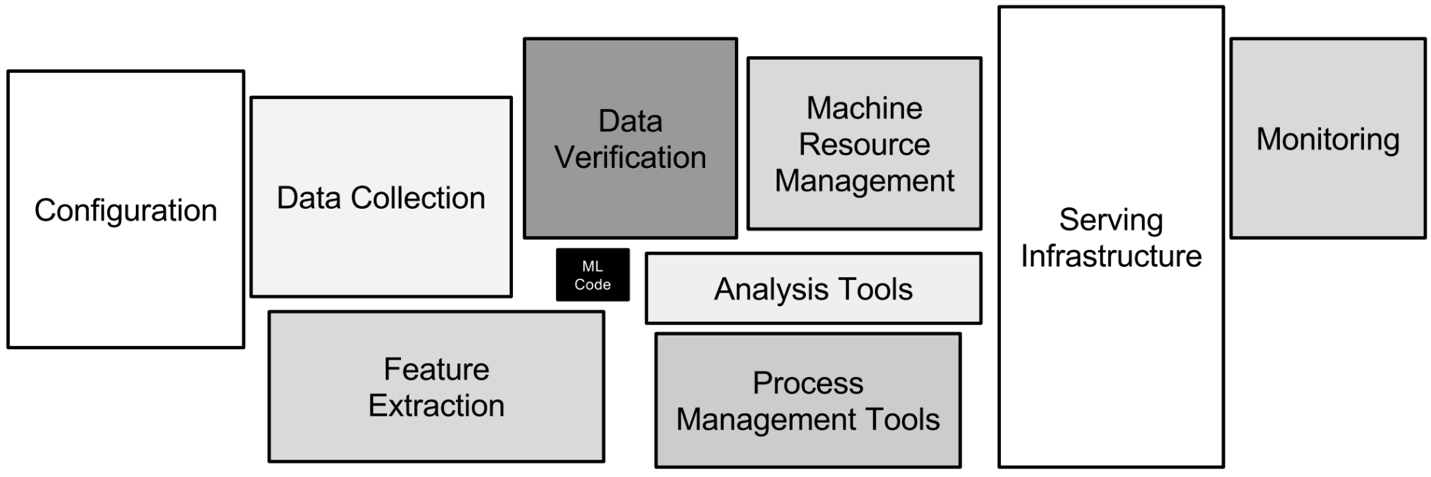
Los diferentes aspectos técnicos que intervienen en MLOps. Imagen del autor.
Esta función es importante porque permite a los equipos de datos implementar modelos de machine learning en entornos de producción, al tiempo que garantiza que se puedan escalar y mantener de manera eficaz. En esencia, MLOps acelera la innovación, mejora la eficiencia operativa y ayuda a las empresas a aprovechar todo el potencial de sus iniciativas basadas en datos.
Las habilidades necesarias para trabajar en MLOps incluyen:
Sí, ¡un ingeniero de MLOps es como un unicornio! Y esa es precisamente la razón por la que tienen tanta demanda y reciben salarios cada vez más altos.
En esta sección, exploraremos preguntas fundamentales para entrevistas sobre MLOps que evalúan tu comprensión de los conceptos y principios básicos. Estas preguntas están diseñadas para evaluar tus conocimientos sobre las responsabilidades y los retos básicos de MLOps, así como tu capacidad para comunicar tus conocimientos de forma eficaz.
Familiarízate con estas preguntas para sentar unas bases sólidas que te preparen para temas más avanzados y demostrar tu competencia en este campo.
Descripción: Esta pregunta evalúa tu comprensión de las diferencias fundamentales entre MLOps y DevOps, que a menudo se confunden.
Respuesta: MLOps y DevOps son estrategias centradas en la colaboración, pero tienen fines diferentes. DevOps se centra en automatizar el desarrollo, las pruebas y la implementación de aplicaciones de software, estandarizando los entornos para optimizar estos procesos.
Por el contrario, MLOps está diseñado para los flujos de trabajo de machine learning, haciendo hincapié en la gestión y el mantenimiento de los canales de datos y los modelos. Mientras que DevOps tiene como objetivo automatizar las tareas rutinarias y estandarizar la implementación de aplicaciones, MLOps aborda la naturaleza experimental de machine learning, incluyendo tareas como la validación de datos, la evaluación de la calidad de los modelos y la validación continua de los modelos.
Comparación y contraste entre DevOps y MLOps. Imagen creada por el autor con napkin.ai.
Descripción: Esta pregunta de la entrevista evalúa tus conocimientos sobre el impacto de la evolución de los datos en la precisión de los modelos y la importancia de supervisar y actualizar los modelos.
Respuesta: La deriva del modelo y la deriva del concepto se refieren a los cambios en el rendimiento de los modelos de machine learning a lo largo del tiempo debido a la evolución de los patrones de datos y las relaciones subyacentes:
Descripción: Esta pregunta de la entrevista evalúa tus conocimientos sobre las prácticas de prueba para garantizar que un modelo de machine learning sea fiable y funcione correctamente antes de implementarlo en un entorno de producción.
Respuesta: Hay una serie de pruebas diferentes que deben realizarse antes de implementar un modelo de ML en producción. Esta tabla ofrece una visión completa de cada tipo de prueba, incluyendo sus objetivos e es, las herramientas utilizadas y cuándo debe aplicarse durante el ciclo de vida del desarrollo del machine learning:
|
Tipo de prueba |
Objetivo |
Herramientas utilizadas |
Cuándo utilizarlo |
|
Pruebas unitarias |
Verifica los componentes individuales del modelo, como los pasos de preprocesamiento y las funciones de extracción de características. |
PyTest, unittest, scikit-learn (para transformaciones) |
Durante el desarrollo, al implementar o actualizar componentes del modelo. |
|
Pruebas de integración |
Asegúrate de que el modelo interactúa correctamente con otros componentes del sistema y fuentes de datos en el entorno de producción. |
Docker, Kubernetes, Jenkins, Apache Kafka |
Después de las pruebas unitarias, al implementar el modelo en un entorno similar al de producción. |
|
Pruebas de rendimiento |
Evalúa la exactitud, precisión, recuperación y otras métricas relevantes del modelo utilizando un conjunto de datos de validación. |
Scikit-learn, TensorFlow, PyTorch, MLflow |
Después de las pruebas de integración, para garantizar que el modelo cumple con los estándares de rendimiento esperados. |
|
Pruebas de estrés |
Evalúa cómo gestiona el modelo cargas elevadas y grandes volúmenes de datos, garantizando la escalabilidad. |
Apache JMeter, Locust, Dask |
Antes de implementar en entornos con un gran volumen de datos o cuando la escalabilidad sea un factor importante. |
|
Pruebas A/B |
Compara el rendimiento del modelo con los modelos existentes o las métricas de referencia en un entorno real. |
Optimizely, SciPy, Google Optimize |
Después de la implementación, al validar el rendimiento del modelo en producción y optimizar las versiones del modelo. |
|
Pruebas de robustez |
Asegúrate de que el modelo sea resistente a las anomalías de datos y los casos extremos. |
Bibliotecas de robustez adversaria (por ejemplo, CleverHans), scripts personalizados. |
Después de las pruebas de rendimiento, para confirmar la fiabilidad en condiciones anormales o inesperadas. |
Descripción: Esta pregunta de la entrevista evalúa tu comprensión del papel y la importancia del control de versiones en las prácticas de MLOps. Se centra en cómo la gestión de diferentes versiones de modelos, datos y código contribuye a la implementación y el mantenimiento eficaces de los modelos.
Respuesta: El control de versiones es fundamental en MLOps, ya que ayuda a gestionar y realizar un seguimiento de los cambios en los modelos de machine learning, los conjuntos de datos y el código a lo largo de su ciclo de vida. El uso de sistemas de control de versiones como Git para el código y herramientas como DVC (Data Version Control) para conjuntos de datos y modelos garantiza que todos los cambios queden documentados y sean reversibles.
Esta práctica favorece la reproducibilidad, facilita la colaboración entre los miembros del equipo y permite volver fácilmente a versiones anteriores si surgen problemas. Garantiza la coherencia y la fiabilidad en el rendimiento del modelo, lo cual es importante para mantener implementaciones de alta calidad.
Para obtener más información sobre este concepto, consulta la Guía completa sobre el control de versiones de datos (DVC). ¡Te preparará para este tipo de preguntas durante tu entrevista!
Descripción: Esta pregunta de la entrevista tiene como objetivo evaluar tus conocimientos sobre los diferentes métodos para empaquetar modelos de machine learning para su implementación. Evalúa tu comprensión sobre cómo preparar modelos para su integración en diversos entornos y aplicaciones.
Respuesta: Hay varias formas eficaces de empaquetar modelos de machine learning:
Una excelente manera de aprender más sobre los modelos de empaquetado es familiarizarse con la contenedorización. Docker es una herramienta fundamental que todo ingeniero de MLOps debería conocer. Para refrescar tus conocimientos, dirígete al curso Introducción a Docker.
Descripción: Esta pregunta evalúa tus conocimientos sobre los modelos de supervisión en producción y tu comprensión de las métricas que son fundamentales para garantizar un rendimiento y una fiabilidad continuos.
Respuesta: La supervisión es esencial en MLOps para garantizar que los modelos sigan funcionando según lo previsto en producción. Las métricas que hay que seguir incluyen la exactitud, la precisión, la recuperación y otros indicadores de rendimiento para detectar la degradación del modelo.
El control de la deriva de datos también es fundamental, ya que los cambios en los patrones de datos pueden afectar a las predicciones del modelo. Además, las métricas de infraestructura, como la latencia y el uso de recursos (por ejemplo, CPU, memoria), ayudan a garantizar que el sistema siga siendo escalable y receptivo.
Descripción: Esta pregunta de la entrevista evalúa tu comprensión de los posibles obstáculos y cómo abordarlos para garantizar el éxito de la implementación del modelo.
Respuesta: Los problemas habituales en la implementación de modelos de aprendizaje automático incluyen:
Todos los empleadores buscan habilidades para resolver problemas, especialmente cuando se trata de manejar datos en un puesto como el de MLOps. Para ponerte al día con dos temas muy importantes en la era del aprendizaje automático, consulta los cursos Introducción a la calidad de los datos e Introducción a la seguridad de los datos.
Descripción: Esta pregunta de la entrevista evalúa tu capacidad para diferenciar entre los métodos de implementación Canary y Blue-Green y sus ventajas a la hora de implementar nuevos cambios.
Respuesta: Las estrategias de implementación Canary y Blue-Green se utilizan para gestionar el lanzamiento de actualizaciones, pero difieren en sus enfoques:
Ambas estrategias tienen como objetivo reducir los riesgos de implementación y el tiempo de inactividad, pero las implementaciones Canary se centran en el lanzamiento incremental y la exposición gradual, mientras que las implementaciones Blue-Green garantizan un cambio fluido entre entornos.
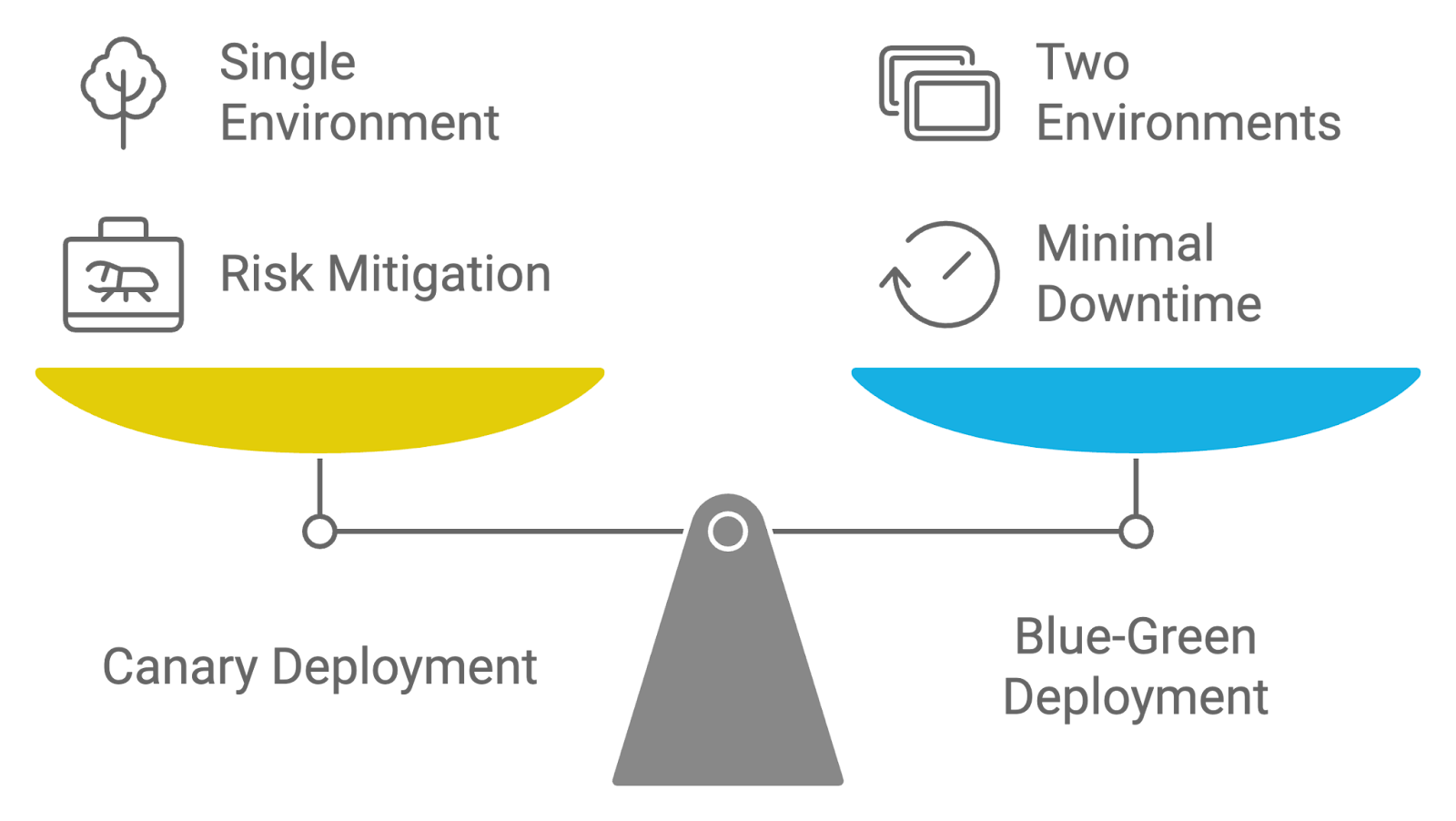
Comparación de estrategias de implementación: Canario contra azul verdoso. Imagen creada por el autor con napkin.ai.
Descripción: Esta pregunta evalúa tus conocimientos sobre las estrategias y herramientas utilizadas para automatizar el reentrenamiento de los modelos de machine learning a medida que se dispone de nuevos datos.
Respuesta: La automatización del reentrenamiento de modelos en MLOps implica configurar un proceso que active el reentrenamiento cuando se cumplan determinadas condiciones, como la degradación del rendimiento o la disponibilidad de nuevos datos.
Herramientas como Airflow o Kubeflow pueden coordinar estos flujos de trabajo, automatizando tareas como la ingesta de datos, la ingeniería de características, el entrenamiento de modelos y la evaluación. La supervisión continua es esencial para garantizar que el modelo cumpla los umbrales de rendimiento antes de su implementación, y las herramientas de control de versiones como DVC ayudan a realizar un seguimiento de las diferentes versiones del modelo durante el reentrenamiento.
En esta sección, abordaremos preguntas técnicas de entrevista sobre MLOps que evalúan tus habilidades prácticas y tu comprensión de conceptos avanzados.
Estas preguntas se centran en los aspectos técnicos de la implementación, gestión y optimización de modelos de machine learning, y están diseñadas para evaluar tu dominio de las herramientas, técnicas y mejores prácticas en este campo.
Descripción: Esta pregunta evalúa tus conocimientos sobre la configuración de canalizaciones de CI/CD específicas para flujos de trabajo de machine learning. Evalúa tu capacidad para automatizar el proceso de implementación y gestionar las actualizaciones de modelos de manera eficiente.
Respuesta: La implementación de CI/CD para modelos de machine learning implica configurar canalizaciones que automaticen el proceso, desde los cambios en el código hasta la implementación.
Por ejemplo, puedes utilizar Jenkins o GitHub Actions para activar compilaciones y pruebas cada vez que se produzca un cambio en el código o los datos del modelo. El proceso incluye etapas tales como:
Al automatizar estas etapas, te aseguras de que los modelos se actualicen de forma coherente y fiable con una intervención manual mínima.
Si necesitas mejorar tus conocimientos sobre CI/CD, realiza el curso CI/CD para machine learning. ¡Te hará brillar en tu entrevista!
Descripción: Esta pregunta de la entrevista se centra en tu comprensión de las prácticas eficaces de gestión de datos dentro de MLOps. Evalúa tu capacidad para gestionar la calidad, el control de versiones y la organización de los datos con el fin de respaldar flujos de trabajo de machine learning sólidos y fiables.
Respuesta: Las mejores prácticas para gestionar datos en MLOps incluyen:
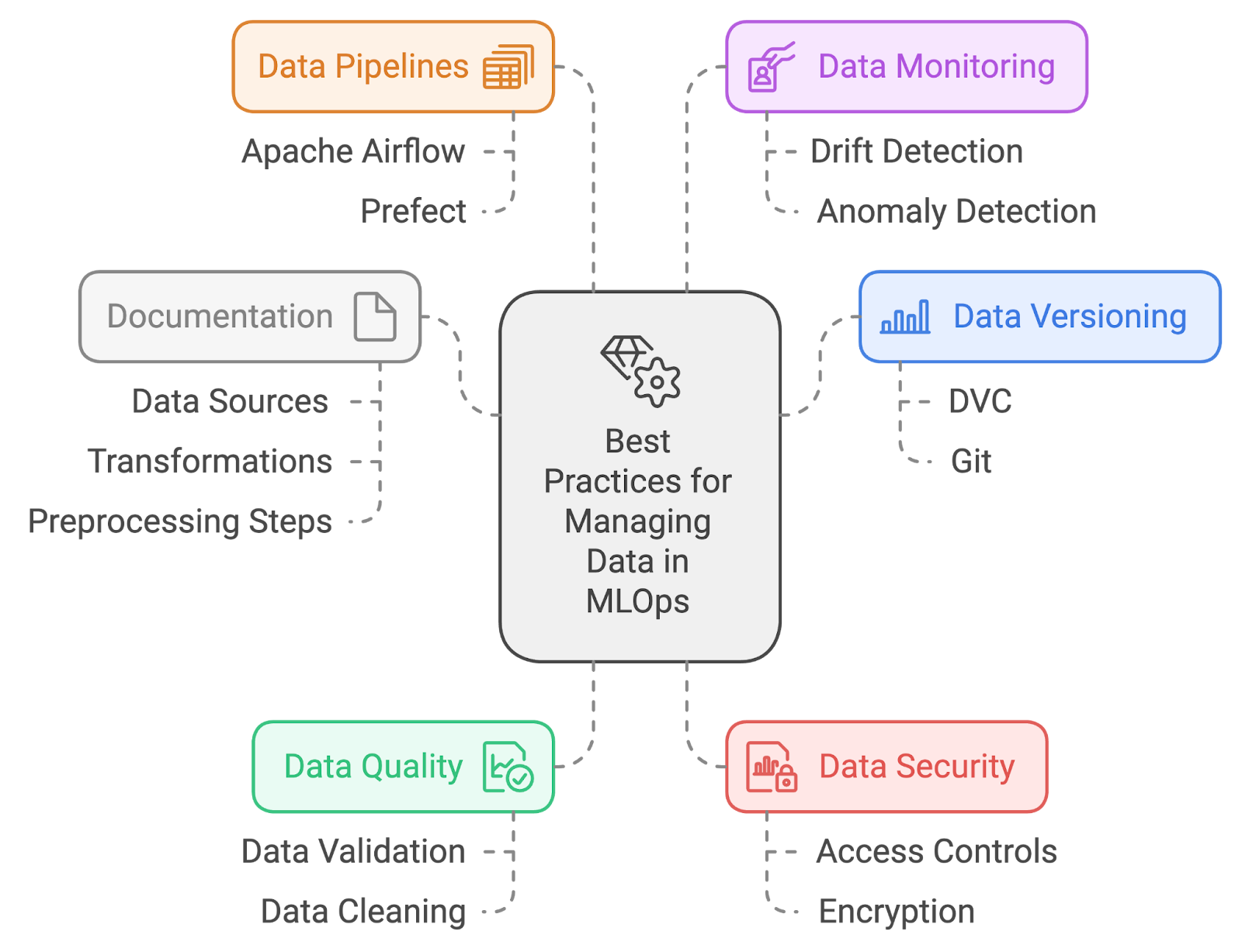
Mejores prácticas en la gestión de datos. Imagen creada por el autor con napkin.ai.
Descripción: Esta pregunta evalúa cómo integras estos procesos en flujos de trabajo automatizados.
Respuesta: La gestión de la ingeniería de características y el preprocesamiento en un proceso de MLOps implica automatizar estos pasos para garantizar la coherencia y la reproducibilidad. Puedes utilizar herramientas como Apache Airflow o Prefect para crear canalizaciones de datos que realicen tareas como:
Descripción: Esta pregunta evalúa tu comprensión sobre cómo programar y garantizar el rendimiento y la fiabilidad continuos del modelo, incluidas las herramientas y estrategias que utilizarías para una supervisión eficaz.
Respuesta: La implementación de la supervisión de modelos en un entorno de producción implica varias prácticas para garantizar que el modelo funcione según lo previsto y siga siendo fiable a lo largo del tiempo:
¡El curso de supervisión del machine learning te permitirá ponerte al día para responder a preguntas como esta con más detalle!
Descripción: Esta pregunta analiza tu enfoque para garantizar que los experimentos de machine learning se puedan replicar de forma coherente. Evalúa tu comprensión de las prácticas que favorecen la reproducibilidad.
Respuesta: Garantizar la reproducibilidad de los experimentos de machine learning implica:
Descripción: Esta pregunta evalúa tu comprensión de los retos únicos que plantea llevar los modelos de machine learning desde el entorno de desarrollo al de producción.
Respuesta: La puesta en práctica de los modelos de machine learning plantea varios retos. Una de las principales dificultades es garantizar la coherencia entre los entornos de desarrollo y producción, lo que puede dar lugar a problemas de reproducibilidad.
La deriva de datos es otra preocupación, ya que los datos en producción pueden cambiar con el tiempo, lo que reduce la precisión del modelo.
Además, integrar modelos en los sistemas existentes, supervisar su rendimiento y automatizar los flujos de trabajo de reentrenamiento suelen ser tareas complejas que requieren una colaboración eficaz entre los equipos de ciencia de datos e ingeniería.
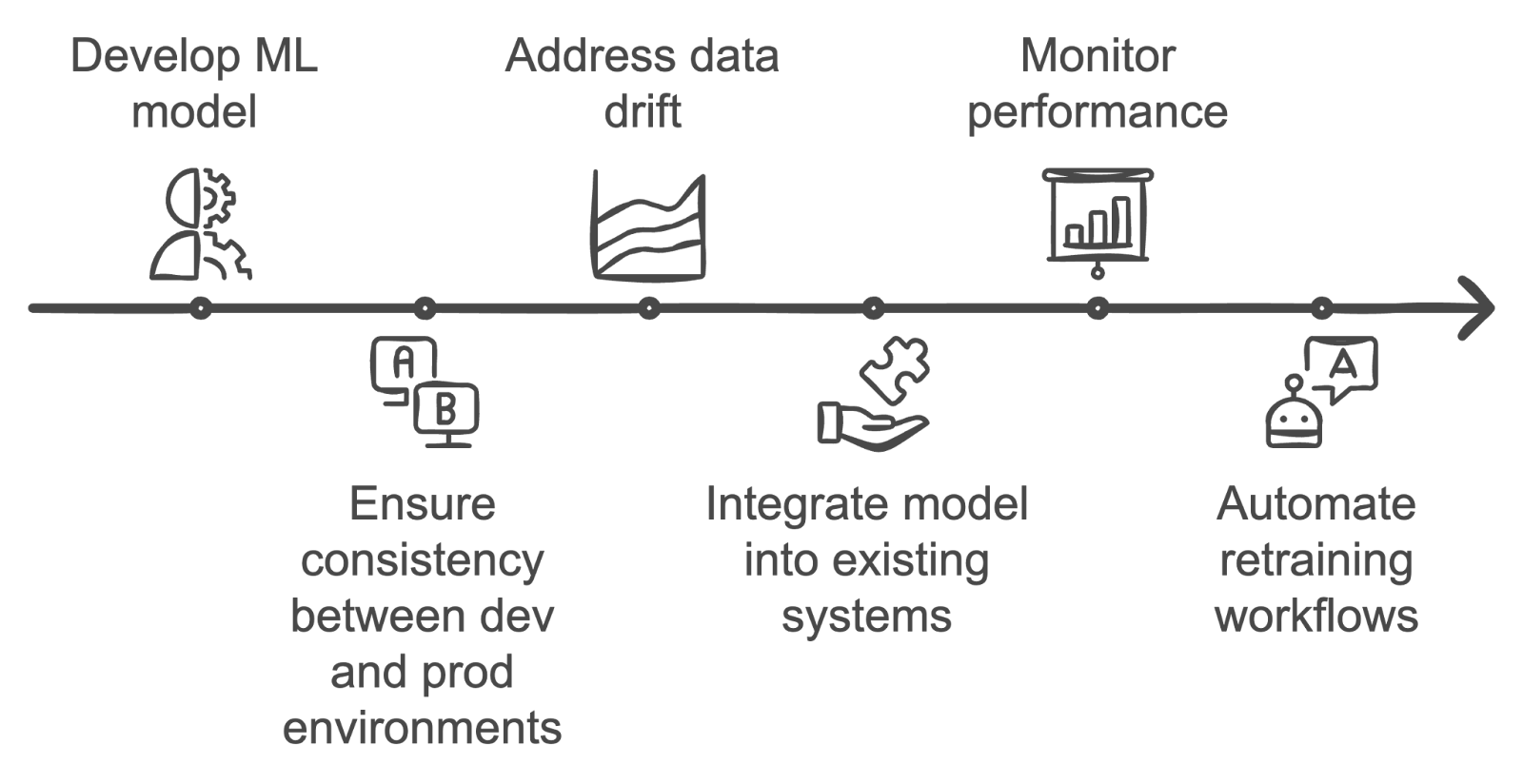
Superar los retos de la puesta en práctica de los modelos de aprendizaje automático. Imagen creada por el autor con napkin.ai.
Descripción: Esta pregunta evalúa tu comprensión de la automatización del reentrenamiento de modelos cuando hay nuevos datos disponibles o cuando el rendimiento del modelo se degrada.
Respuesta: La implementación del reentrenamiento automatizado de modelos implica la configuración de un proceso que supervise el rendimiento del modelo y la deriva de los datos. Cuando la precisión del modelo cae por debajo de un umbral o cuando hay nuevos datos disponibles, herramientas como Apache Airflow o Kubeflow pueden activar un nuevo entrenamiento.
El reentrenamiento implica obtener nuevos datos, preprocesarlos, entrenar el modelo con los mismos hiperparámetros o con hiperparámetros actualizados y validar el nuevo modelo. Tras el reentrenamiento, el modelo actualizado se implementa automáticamente en producción.
Descripción: Esta pregunta evalúa tus conocimientos sobre la interpretabilidad de los modelos y cómo garantizas la transparencia en las predicciones de los modelos.
Respuesta: Herramientas como SHAP (SHapley Additive exPlanations) o LIME (Local Interpretable Model-agnostic Explanations) se utilizan habitualmente para explicar los modelos.
Estas herramientas ayudan a desglosar las predicciones del modelo mostrando la contribución de cada una de las características. La explicabilidad es clave en MLOps porque genera confianza entre las partes interesadas y garantiza que los modelos cumplan con las normativas, especialmente en sectores como el financiero y el sanitario. También ayuda a identificar posibles sesgos o problemas relacionados con los datos dentro del modelo.
Esta sección abarca preguntas de entrevista centradas en aspectos relacionados con la nube y la infraestructura de MLOps. Estas preguntas evalúan tu experiencia en la implementación, gestión y escalado de modelos de machine learning en entornos de nube.
Descripción: Esta pregunta evalúa tus conocimientos sobre la implementación de modelos de machine learning en un entorno de nube. Evalúa tu comprensión de las plataformas en la nube, los procesos de implementación y las herramientas utilizadas para gestionar modelos en la nube.
Respuesta: La implementación de modelos de ML en la nube implica los siguientes pasos:
Descripción: Esta pregunta explora la comprensión de la computación sin servidor y su aplicación en la implementación de modelos de aprendizaje automático, evaluando la capacidad de sopesar los beneficios frente a los retos.
Respuesta: Las arquitecturas sin servidor ofrecen varias ventajas, entre ellas la reducción de los gastos generales operativos, ya que no es necesario gestionar servidores, y el escalado automático en función de la demanda en tiempo real, lo que puede suponer un ahorro de costes, ya que los cargos se basan en el uso real de la computación.
Sin embargo, las arquitecturas sin servidor también plantean algunos retos. Por ejemplo, existen limitaciones en cuanto al tiempo de ejecución y la asignación de recursos que pueden no ser adecuadas para todos los tipos de modelos de aprendizaje automático, en particular aquellos con grandes necesidades computacionales.
La latencia de arranque en frío también puede ser un problema, ya que las solicitudes iniciales tras periodos de inactividad pueden sufrir retrasos. A pesar de estos retos, las arquitecturas sin servidor pueden resultar muy eficaces para determinadas cargas de trabajo si estos factores se gestionan adecuadamente.
Otra forma de verlo es con esta tabla que resume las ventajas y desventajas de las arquitecturas sin servidor basadas en aspectos específicos:
|
Aspecto |
Ventajas de los servidores sin servidor |
Desventajas de los servidores sin servidor |
|
Gastos generales operativos |
No es necesario gestionar servidores; se reduce la complejidad de la infraestructura. |
Requiere conocimientos sobre plataformas de nube para gestionar entornos sin servidor. |
|
Escalado |
El escalado automático se basa en la demanda en tiempo real, lo que se traduce en una mayor rentabilidad. |
Puede resultar impredecible para la elaboración de presupuestos si el escalado es frecuente. |
|
Rentabilidad |
Paga solo por los recursos que utilices, lo que te permitirá reducir costes. |
Puede resultar caro si se invocan muchas funciones con frecuencia o durante largos periodos de tiempo. |
|
Límites de ejecución |
Adecuado para tareas ligeras o de corta duración. |
Limitado por el tiempo de ejecución y la asignación de recursos, es posible que no pueda manejar modelos de ML que consumen muchos recursos. |
|
Arranque en frío |
Reduce los gastos generales operativos mediante el escalado según la demanda. |
Pueden producirse retrasos en el arranque en frío tras periodos de inactividad, lo que afecta a las aplicaciones sensibles a la latencia. |
|
Idoneidad del modelo ML |
Funciona bien para tareas de ML a pequeña escala, inferencia o procesamiento por lotes. |
Los modelos de aprendizaje automático que requieren un alto nivel de computación y tareas de larga duración no son adecuados. |
Descripción: Esta pregunta evalúa tus estrategias para optimizar y gestionar los recursos computacionales durante el entrenamiento de modelos de aprendizaje automático en la nube. Evalúa tu capacidad para garantizar un uso eficiente de los recursos en la nube.
Respuesta: La gestión de los recursos computacionales implica:
Descripción: Esta pregunta examina el enfoque para mantener la seguridad y el cumplimiento de los datos durante la implementación de modelos de aprendizaje automático en entornos de nube, centrándose en las mejores prácticas y los requisitos normativos.
Respuesta: Garantizar la seguridad y el cumplimiento de los datos implica:
La seguridad y el cumplimiento normativo pueden ser lo último en lo que un ingeniero quiere pensar, pero cada vez son más importantes. El curso «Comprender el RGPD», junto con los demás sugeridos a lo largo de este artículo, debería ponerte al día.
Descripción: Esta pregunta explora estrategias para gestionar y optimizar los costes de la nube relacionados con el entrenamiento y la implementación de modelos de aprendizaje automático, evaluando tus conocimientos sobre técnicas de gestión de costes.
Respuesta: Las estrategias para gestionar los costes de la nube incluyen:
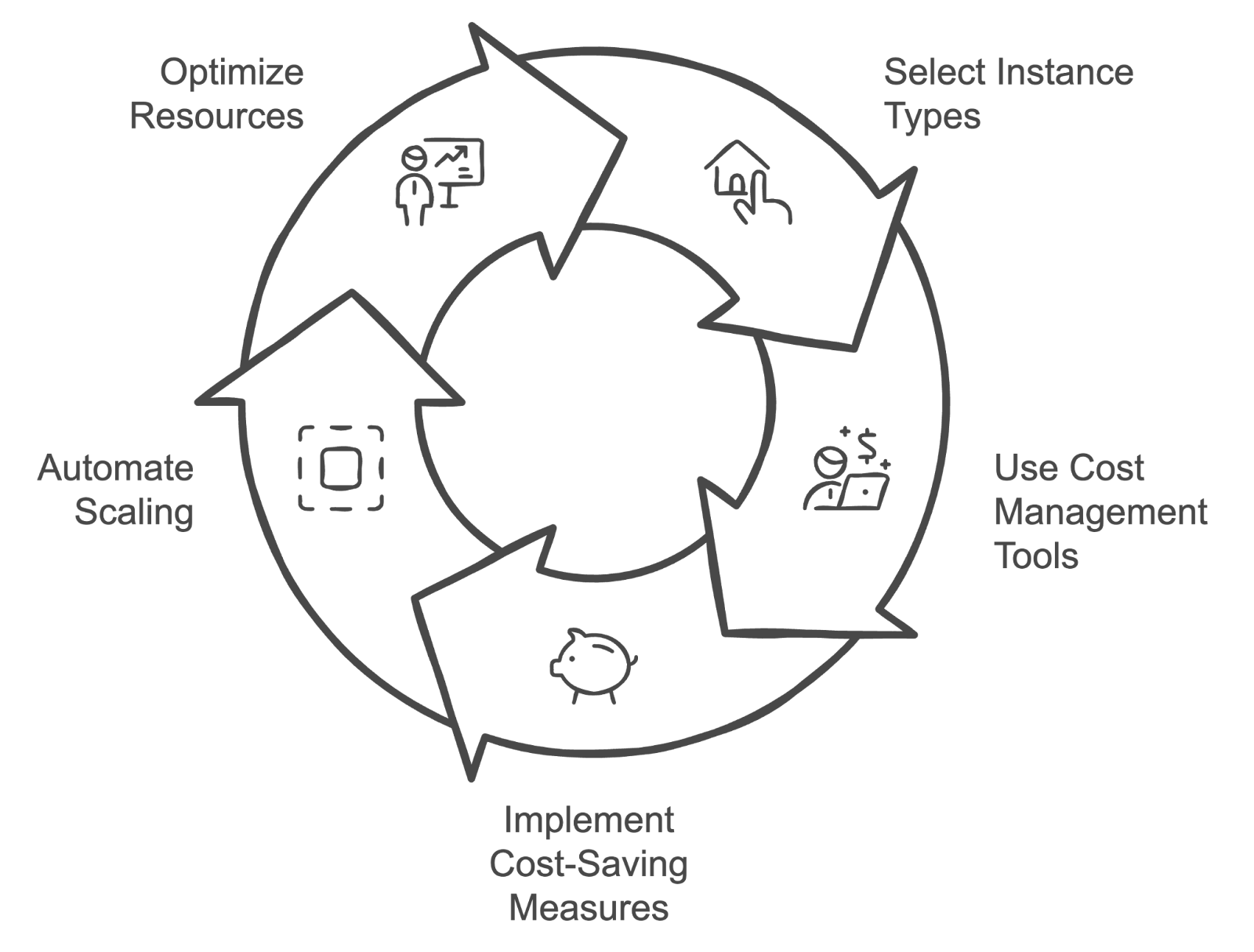
Ciclo de gestión de costes de la nube. Imagen creada por el autor con napkin.ai.
Descripción: Esta pregunta evalúa tu comprensión de las ventajas e inconvenientes de implementar modelos en dispositivos periféricos frente a la nube.
Respuesta: La implementación en la nube implica ejecutar modelos en servidores centralizados, lo que ofrece escalabilidad y un mantenimiento más sencillo, pero con posibles problemas de latencia.
La implementación en el borde implica ejecutar modelos directamente en dispositivos como teléfonos inteligentes o dispositivos IoT, lo que reduce la latencia y mejora la privacidad de los datos, pero puede verse limitada por los recursos computacionales. La implementación en el borde es ideal para aplicaciones de procesamiento en tiempo real, mientras que la implementación en nube es más adecuada para modelos que requieren una gran potencia computacional y flexibilidad.
Descripción: Esta pregunta evalúa tus conocimientos sobre la creación de sistemas resilientes para implementar modelos de machine learning.
Respuesta: Garantizar una alta disponibilidad implica implementar modelos en múltiples zonas o regiones de disponibilidad y configurar mecanismos de conmutación por error automatizados.
Los equilibradores de carga pueden distribuir el tráfico para evitar cuellos de botella. Para garantizar la tolerancia a fallos, las copias de seguridad periódicas, la redundancia y las comprobaciones de estado pueden evitar fallos del sistema. Aprovechar servicios en la nube como AWS Elastic Load Balancing y las funciones de autoescalado también ayuda a garantizar que, si una instancia falla, otras puedan tomar el relevo sin tiempo de inactividad.
Esta sección profundiza en los aspectos conductuales y de resolución de problemas de MLOps, evaluando cómo los candidatos abordan los retos del mundo real, colaboran con los equipos y gestionan diversas cuestiones relacionadas con la implementación y la gestión de modelos de machine learning.
Descripción: Esta pregunta evalúa las habilidades para resolver problemas en situaciones de la vida real.
Ejemplo de respuesta: Se dio una situación en la que un modelo implementado en producción comenzó a mostrar una caída significativa en el rendimiento. El primer paso fue analizar los registros y métricas del modelo para identificar cualquier anomalía. Se hizo evidente que el canal de datos estaba introduciendo datos cuya estructura había cambiado debido a actualizaciones recientes en los sistemas de origen.
El siguiente paso fue validar los datos con respecto a la información esperada por el modelo y comprobar si había discrepancias. Tras confirmar el problema con los datos, coordiné con el equipo de ingeniería de datos para rectificar el flujo de datos. A continuación, implementé una revisión para actualizar el modelo con el manejo corregido de las entradas.
Por último, supervisé de cerca el modelo tras su implementación para garantizar que el rendimiento volviera a los niveles esperados y comuniqué los resultados y la resolución a las partes interesadas.
Descripción: Esta pregunta evalúa tu enfoque para gestionar diferentes versiones de modelos de machine learning cuando trabajas en equipo.
Ejemplo de respuesta: «Utilizo sistemas de control de versiones como MLflow o DVC para gestionar y realizar un seguimiento de las diferentes versiones de los modelos. A cada versión se le asigna un identificador único y se proporciona documentación detallada para cada actualización con el fin de garantizar que los miembros del equipo comprendan los cambios.
Además, me aseguro de que los nuevos modelos se prueben exhaustivamente en un entorno de ensayo antes de implementarlos en producción, lo que ayuda a evitar interrupciones y a mantener el rendimiento del modelo.
Descripción: Esta pregunta evalúa tu capacidad para trabajar eficazmente con diferentes equipos, como científicos de datos, ingenieros y gestores de productos, y cómo afrontas y resuelves los retos en un entorno interfuncional.
Ejemplo de respuesta: Una situación difícil fue la coordinación entre científicos de datos, ingenieros y gestores de productos para implementar un nuevo modelo con dependencias complejas. La clave para una colaboración eficaz fue establecer canales de comunicación claros desde el principio.
Se programaron reuniones periódicas para alinear los objetivos, programar el progreso y abordar cualquier obstáculo. Para salvar las lagunas de conocimiento, organicé sesiones de intercambio de conocimientos en las que los miembros del equipo podían debatir sobre sus respectivas áreas de especialización.
Además, el uso de herramientas de gestión de proyectos para programar las tareas y los hitos ayudó a mantener a todos informados sobre el estado del proyecto. Este enfoque garantizó que se tuvieran en cuenta las aportaciones de cada miembro del equipo y que trabajáramos juntos para lograr una implementación satisfactoria.
Descripción: Esta pregunta explora tus estrategias para escalar modelos de machine learning con el fin de adaptarse a las crecientes demandas, evaluando tu comprensión de los aspectos técnicos y operativos de la escalabilidad.
Ejemplo de respuesta: El escalado de modelos de ML para gestionar el aumento de la carga de usuarios implica varios pasos críticos.
En primer lugar, analizaría los indicadores de rendimiento del modelo actual para identificar posibles cuellos de botella. Para gestionar el aumento de la demanda, utilizaría soluciones de autoescalado de nube para ajustar los recursos de forma dinámica en función del tráfico.
Además, optimizar el modelo en sí mismo mediante técnicas como la cuantificación o la poda puede ayudar a reducir su consumo de recursos sin sacrificar el rendimiento.
También implementaría pruebas de carga para simular un mayor tráfico y garantizar la solidez del sistema.
Por último, pero no menos importante, implementaría un monitoreo continuo para mantenerme al día con el rendimiento de los modelos, de modo que pueda ajustar la asignación de recursos según sea necesario y mantener el rendimiento bajo cargas variables.
Descripción: Esta pregunta evalúa tu capacidad para gestionar la comunicación y las expectativas cuando un modelo no ofrece los resultados esperados.
Ejemplo de respuesta: Cuando el rendimiento del modelo no cumple con las expectativas, me centro en mantener una comunicación transparente con las partes interesadas. Explico las limitaciones del modelo y las razones de su rendimiento, ya sea debido a problemas de calidad de los datos, sobreajuste o expectativas iniciales poco realistas.
A continuación, trabajo con ustedes para establecer objetivos más realistas, proporcionar información basada en datos y proponer mejoras, como recopilar más datos de entrenamiento o ajustar la arquitectura del modelo.
Descripción: Esta pregunta evalúa tu capacidad para priorizar el mantenimiento de la calidad del código a largo plazo y el cumplimiento de los plazos de los proyectos a corto plazo.
Ejemplo de respuesta: Hubo un momento en el que teníamos un plazo muy ajustado para implementar un modelo para una nueva función del producto. Dimos prioridad a una entrega rápida omitiendo ciertas partes no críticas del código base, como la documentación exhaustiva y las pruebas no esenciales.
Tras el lanzamiento, dedicamos tiempo a revisar el código fuente y solucionar estos problemas, asegurándonos de minimizar la deuda técnica tras el lanzamiento. Esto nos permitió cumplir con el plazo y mantener la estabilidad del proyecto a largo plazo.
Prepararse para una entrevista de MLOps implica una combinación de conocimientos técnicos, comprensión del entorno de la empresa y comunicación clara de tus experiencias pasadas. Aquí tienes algunos consejos esenciales que te ayudarán a prepararte:
Asegúrate de comprender bien los conceptos básicos de MLOps. Familiarízate con las herramientas y plataformas más utilizadas en MLOps, como MLflow, Kubernetes y servicios en la nube como AWS SageMaker o Google AI Platform.
El programa de habilidades MLOps es el recurso perfecto, ya que contiene cuatro cursos relevantes que te garantizan estar al día con los conceptos y prácticas de MLOps.
Investiga las tecnologías y herramientas específicas que utiliza la empresa en la que te vas a entrevistar. Comprender su infraestructura tecnológica te ayudará a adaptar tus respuestas para que se ajusten a su entorno y demostrar que eres un buen candidato. Investiga cuáles son tus servicios en la nube, sistemas de control de versiones y prácticas de gestión de modelos preferidos para demostrar que estás preparado para integrarte a la perfección en tu flujo de trabajo.
Prepárate para hablar sobre proyectos o experiencias concretos en los que hayas aplicado prácticas de MLOps. Prepara ejemplos que destaquen tus habilidades para resolver problemas, tu capacidad para trabajar con equipos multifuncionales y tu experiencia en la implementación y el escalado de modelos (si es posible). Utiliza estos ejemplos para ilustrar tus conocimientos prácticos y cómo has abordado con éxito los retos en puestos anteriores.
Practica regularmente ejercicios de programación relacionados con MLOps, como escribir scripts para la implementación de modelos, automatizar flujos de trabajo o desarrollar canalizaciones de datos.
El campo de MLOps está evolucionando rápidamente, por lo que es importante mantenerse al día sobre las últimas tendencias, herramientas y mejores prácticas. Sigue blogs del sector, participa en foros o seminarios web relevantes e interactúa con la comunidad MLOps para mantener tus conocimientos actualizados y relevantes.
MLOps es un campo que tiende un puente entre la ciencia de datos y las operaciones, garantizando que los modelos de machine learning se implementen, mantengan y escalen de manera eficaz.
A lo largo de este artículo, hemos abordado una serie de preguntas de entrevista que abarcan conceptos generales de MLOps, aspectos técnicos, consideraciones sobre la nube y la infraestructura, y habilidades conductuales para la resolución de problemas. Practicar estas preguntas aumentará significativamente las probabilidades de éxito durante tus entrevistas y te dará más posibilidades de conseguir el trabajo.
Consulta los siguientes recursos para continuar tu aprendizaje:
¡Aprende más sobre MLOps con estos cursos!
Curso
Curso
Curso
blog
Josep Ferrer
15 min
blog
Tim Lu
9 min
blog
Austin Chia
15 min
blog
Abid Ali Awan
15 min