
Curso
Conceitos de MLOps
2 h
42.6K
As operações de machine learning (MLOps) surgiram como uma das áreas mais procuradas na tecnologia. À medida que as equipes de dados implementam cada vez mais modelos de machine learning em ambientes de produção, a procura por profissionais de MLOps vai continuar a aumentar.
Se você está buscando uma carreira como engenheiro de MLOps, estamos aqui para ajudá-lo a dar esse salto!
Neste artigo, vamos apresentar as principais perguntas de entrevista sobre MLOps, com explicações detalhadas e respostas, pra te ajudar a se preparar bem pra sua próxima entrevista.
MLOps, que é a abreviação de Machine Learning Operations, é uma área que junta machine learning com as práticas de DevOps pra otimizar e automatizar o ciclo de vida dos modelos de machine learning.
O principal objetivo do MLOps é fazer a ponte entre a ciência de dados e as operações de TI, garantindo que os modelos de machine learning sejam desenvolvidos de forma eficaz, implantados, monitorados e mantidos com eficiência em ambientes de produção.
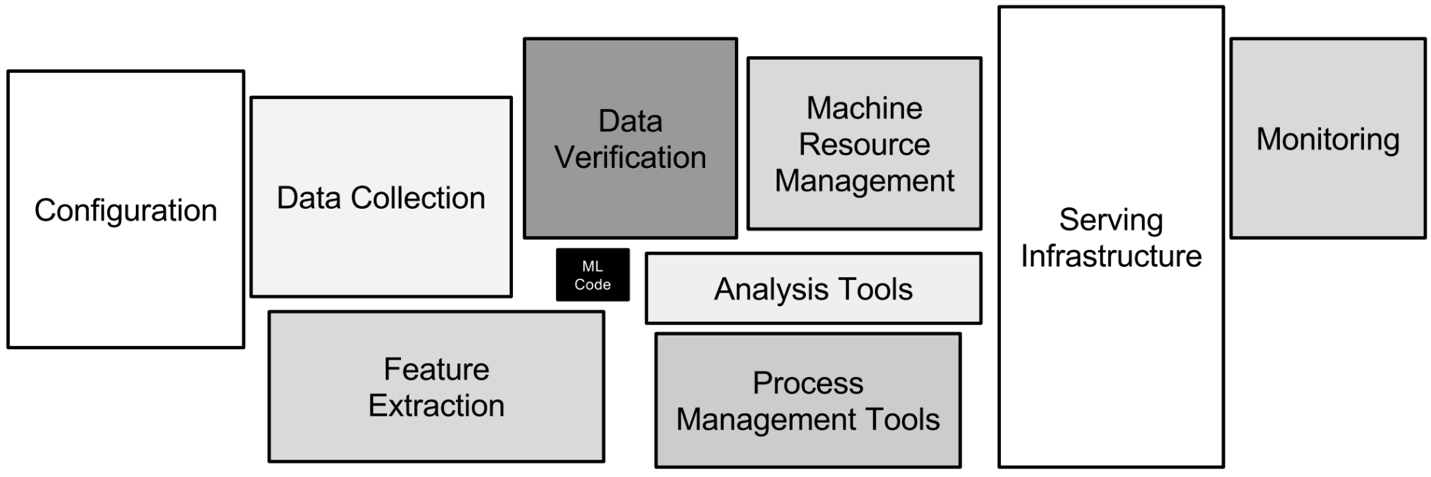
Os diferentes aspectos técnicos envolvidos no MLOps. Imagem do autor
Essa função é importante porque permite que as equipes de dados implementem modelos de machine learning em ambientes de produção, garantindo que eles possam ser dimensionados e mantidos de forma eficaz. Basicamente, o MLOps acelera a inovação, melhora a eficiência operacional e ajuda as empresas a aproveitar todo o potencial das suas iniciativas baseadas em dados.
As habilidades necessárias em MLOps incluem:
Sim, um engenheiro de MLOps é como um unicórnio! E é exatamente por isso que eles são tão procurados e recebem salários cada vez mais altos.
Nesta seção, vamos ver as perguntas básicas de entrevista sobre MLOps que avaliam o quanto você entende dos conceitos e princípios fundamentais. Essas perguntas foram feitas pra testar o seu conhecimento sobre as responsabilidades e desafios básicos do MLOps e a sua capacidade de comunicar esse conhecimento de forma eficaz.
Familiarize-se com essas perguntas para construir uma base sólida na preparação para tópicos mais avançados e para mostrar sua competência na área.
Descrição: Essa pergunta testa o quanto você entende as diferenças básicas entre MLOps e DevOps, que muitas vezes são confundidas.
Resposta: MLOps e DevOps são estratégias focadas na colaboração, mas têm objetivos diferentes. O DevOps foca em automatizar o desenvolvimento, teste e implantação de aplicativos de software, padronizando ambientes para simplificar esses processos.
Já o MLOps é feito sob medida para os fluxos de trabalho de machine learning, com foco em gerenciar e manter pipelines de dados e modelos. Enquanto o DevOps quer automatizar tarefas rotineiras e padronizar a implantação de aplicativos, o MLOps lida com a natureza experimental do machine learning, incluindo tarefas como validação de dados, avaliação da qualidade do modelo e validação contínua do modelo.
Comparando e contrastando DevOps e MLOps. Imagem criada pelo autor com napkin.ai
Descrição: Essa pergunta da entrevista avalia o seu conhecimento sobre o impacto da evolução dos dados na precisão dos modelos e a importância de monitorar e atualizar os modelos.
Resposta: Desvio do modelo e desvio do conceito são mudanças no desempenho dos modelos de machine learning ao longo do tempo, por causa de padrões de dados e relações subjacentes que estão sempre mudando:
Descrição: Essa pergunta da entrevista analisa o seu conhecimento sobre práticas de teste para garantir que um modelo de machine learning seja confiável e tenha um bom desempenho antes de ser implantado em um ambiente de produção.
Resposta: Tem vários testes diferentes que precisam ser feitos antes de colocar um modelo de ML em produção. Esta tabela dá uma visão geral de cada tipo de teste, incluindo seus objetivos , as ferramentas usadas e quando deve ser aplicado durante o ciclo de vida do desenvolvimento do machine learning:
|
Tipo de teste |
Objetivo |
Ferramentas usadas |
Quando usar |
|
Teste de unidade |
Verifique os componentes individuais do modelo, como etapas de pré-processamento e funções de extração de características. |
PyTest, unittest, scikit-learn (para transformações) |
Durante o desenvolvimento, ao implementar ou atualizar componentes do modelo. |
|
Teste de integração |
Garanta que o modelo interaja corretamente com outros componentes do sistema e fontes de dados no ambiente de produção. |
Docker, Kubernetes, Jenkins, Apache Kafka |
Depois dos testes unitários, quando você estiver colocando o modelo em um ambiente parecido com o de produção. |
|
Teste de desempenho |
Avalie a exatidão, precisão, recall e outras métricas relevantes do modelo usando um conjunto de dados de validação. |
Scikit-learn, TensorFlow, PyTorch, MLflow |
Depois dos testes de integração, para garantir que o modelo atinge os padrões de desempenho esperados. |
|
Teste de estresse |
Veja como o modelo lida com cargas pesadas e grandes volumes de dados, garantindo escalabilidade. |
Apache JMeter, Locust, Dask |
Antes de implantar em ambientes com grande volume de dados ou quando o dimensionamento for uma preocupação. |
|
Teste A/B |
Compare o desempenho do modelo com os modelos existentes ou métricas de referência em um ambiente real. |
Optimizely, SciPy, Google Optimize |
Após a implantação, ao validar o desempenho do modelo em produção e otimizar as versões do modelo. |
|
Teste de robustez |
Garanta que o modelo seja resistente a anomalias de dados e casos extremos. |
Bibliotecas de robustez adversária (por exemplo, CleverHans), scripts personalizados |
Depois de testar o desempenho, pra confirmar a confiabilidade em condições anormais ou inesperadas. |
Descrição: Essa pergunta da entrevista avalia o quanto você entende o papel e a importância do controle de versão nas práticas de MLOps. Ele foca em como gerenciar diferentes versões de modelos, dados e códigos ajuda a implantar e manter modelos de forma eficaz.
Resposta: O controle de versão é essencial no MLOps porque ajuda a gerenciar e acompanhar as mudanças nos modelos de machine learning, conjuntos de dados e código durante todo o seu ciclo de vida. Usar sistemas de controle de versão como o Git para código e ferramentas como o DVC (Controle de Versão de Dados) para conjuntos de dados e modelos garante que todas as alterações sejam documentadas e reversíveis.
Essa prática ajuda na reprodução, facilita a colaboração entre os membros da equipe e permite voltar facilmente para versões anteriores se surgirem problemas. Isso garante consistência e confiabilidade no desempenho do modelo, o que é importante para manter implantações de alta qualidade.
Para saber mais sobre esse conceito, confira o Guia Completo para Controle de Versões de Dados (DVC). Isso vai te preparar para esse tipo de pergunta durante a entrevista!
Descrição: Essa pergunta da entrevista quer saber o quanto você sabe sobre os diferentes jeitos de empacotar modelos de machine learning para implantação. Ele testa o seu entendimento sobre como preparar modelos para integração em vários ambientes e aplicações.
Resposta: Tem várias maneiras legais de empacotar modelos de machine learning:
Uma ótima maneira de aprender mais sobre modelos de empacotamento é se familiarizar com a conteinerização. O Docker é uma ferramenta essencial que todo engenheiro de MLOps precisa conhecer. Para refrescar seus conhecimentos, vá para o curso Introdução ao Docker.
Descrição: Essa pergunta avalia o seu conhecimento sobre modelos de monitoramento em produção e a sua compreensão sobre quais métricas são essenciais para garantir desempenho e confiabilidade contínuos.
Resposta: O monitoramento é essencial no MLOps para garantir que os modelos continuem funcionando como esperado na produção. As métricas a serem programadas incluem exatidão, precisão, recuperação e outros indicadores de desempenho para detectar a degradação do modelo.
Monitorar o desvio dos dados também é super importante, já que mudanças nos padrões dos dados podem afetar as previsões do modelo. Além disso, métricas de infraestrutura como latência e uso de recursos (por exemplo, CPU, memória) ajudam a garantir que o sistema continue escalável e responsivo.
Descrição: Essa pergunta da entrevista avalia o quanto você entende sobre possíveis obstáculos e como lidar com eles para garantir uma implementação bem-sucedida do modelo.
Resposta: Problemas comuns na implantação de modelos de ML incluem:
Todos os empregadores estão procurando habilidades de resolução de problemas, principalmente quando se trata de lidar com dados em uma função como MLOps. Para se atualizar sobre dois temas super importantes na era do ML, dá uma olhada nos cursos Introdução à Qualidade dos Dados e Introdução à Segurança dos Dados.
Descrição: Essa pergunta da entrevista testa sua capacidade de diferenciar entre os métodos de implantação Canary e Blue-Green e seus benefícios para implementar novas mudanças.
Resposta: As estratégias de implantação Canary e Blue-Green são usadas para gerenciar o lançamento de atualizações, mas têm abordagens diferentes:
Ambas as estratégias têm como objetivo reduzir os riscos de implantação e o tempo de inatividade, mas as implantações Canary se concentram no lançamento incremental e na exposição gradual, enquanto as implantações Blue-Green garantem uma transição perfeita entre os ambientes.
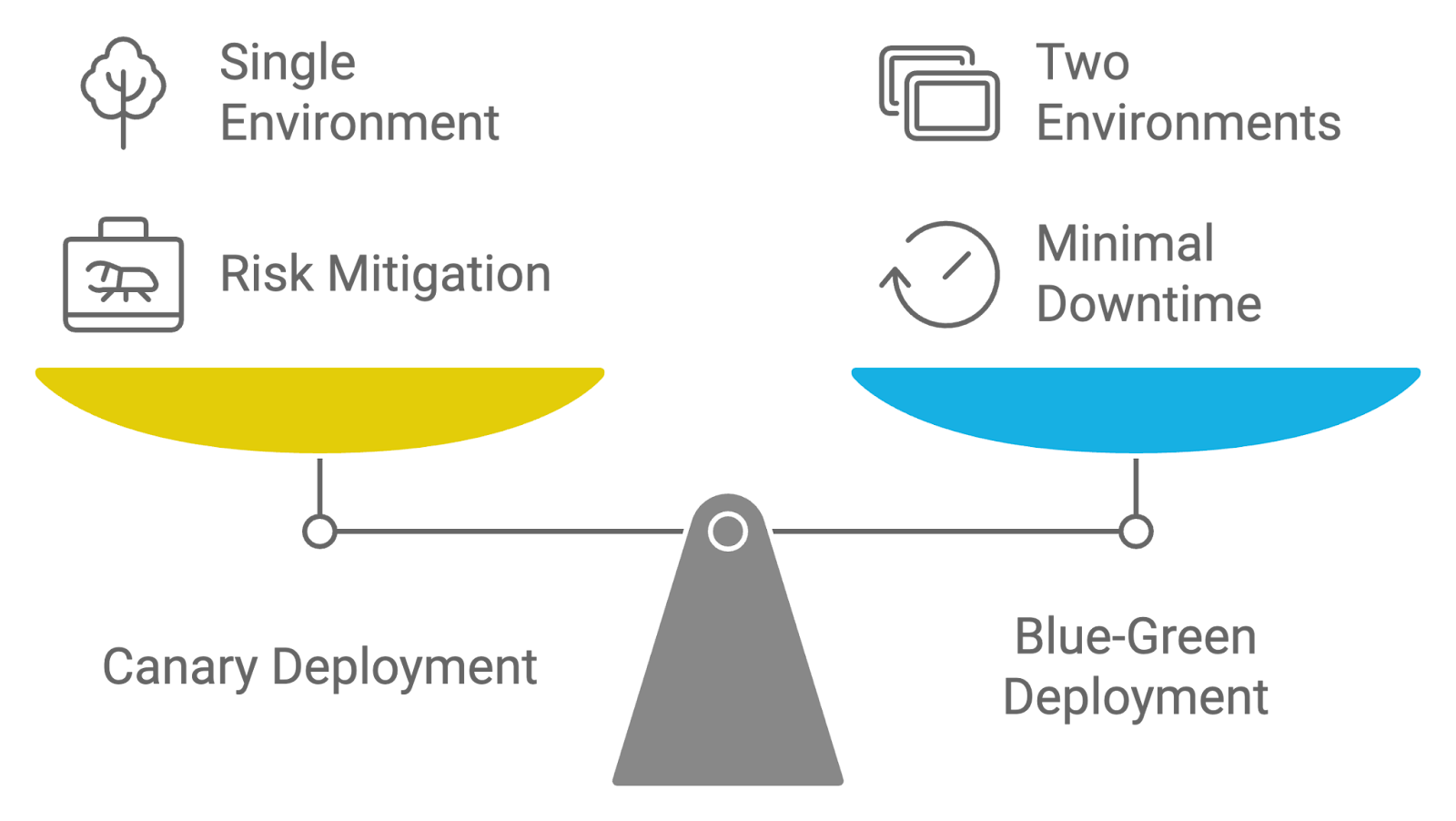
Comparando estratégias de implantação: Canário versus Azul-Verde. Imagem criada pelo autor com napkin.ai
Descrição: Essa pergunta testa o seu conhecimento sobre as estratégias e ferramentas usadas para automatizar o retreinamento de modelos de machine learning à medida que novos dados ficam disponíveis.
Resposta: Automatizar o retreinamento de modelos em MLOps envolve configurar um pipeline que aciona o retreinamento quando certas condições são atendidas, como queda no desempenho ou a disponibilidade de novos dados.
Ferramentas como Airflow ou Kubeflow podem organizar esses fluxos de trabalho, automatizando tarefas como ingestão de dados, engenharia de recursos, treinamento de modelos e avaliação. O monitoramento contínuo é essencial para garantir que o modelo atinja os limites de desempenho antes da implantação, e ferramentas de controle de versão como o DVC ajudam a acompanhar as diferentes versões do modelo durante o retreinamento.
Nesta seção, vamos abordar questões técnicas de entrevista sobre MLOps que avaliam suas habilidades práticas e compreensão de conceitos avançados.
Essas perguntas focam nos aspectos técnicos de implantar, gerenciar e otimizar modelos de machine learning, e foram feitas pra avaliar sua habilidade com ferramentas, técnicas e melhores práticas na área.
Descrição: Essa pergunta testa o seu conhecimento sobre como configurar pipelines de CI/CD especificamente para fluxos de trabalho de machine learning. Ele avalia sua capacidade de automatizar o processo de implantação e gerenciar atualizações de modelos de forma eficiente.
Resposta: Implementar CI/CD para modelos de machine learning envolve configurar pipelines que automatizam o processo, desde as alterações no código até a implantação.
Por exemplo, você pode usar o Jenkins ou o GitHub Actions para acionar compilações e testes sempre que houver uma alteração no código ou nos dados do modelo. O pipeline inclui etapas como:
Ao automatizar essas etapas, você garante que os modelos sejam atualizados de forma consistente e confiável, com o mínimo de intervenção manual.
Se você precisa melhorar seus conhecimentos sobre CI/CD, faça o curso CI/CD para machine learning. Isso vai fazer você se destacar na entrevista!
Descrição: Essa pergunta da entrevista foca na sua compreensão das práticas eficazes de gerenciamento de dados dentro do MLOps. Ele avalia sua habilidade de lidar com a qualidade, o controle de versões e a organização dos dados para dar suporte a fluxos de trabalho de machine learning robustos e confiáveis.
Resposta: As melhores práticas para gerenciar dados em MLOps incluem:
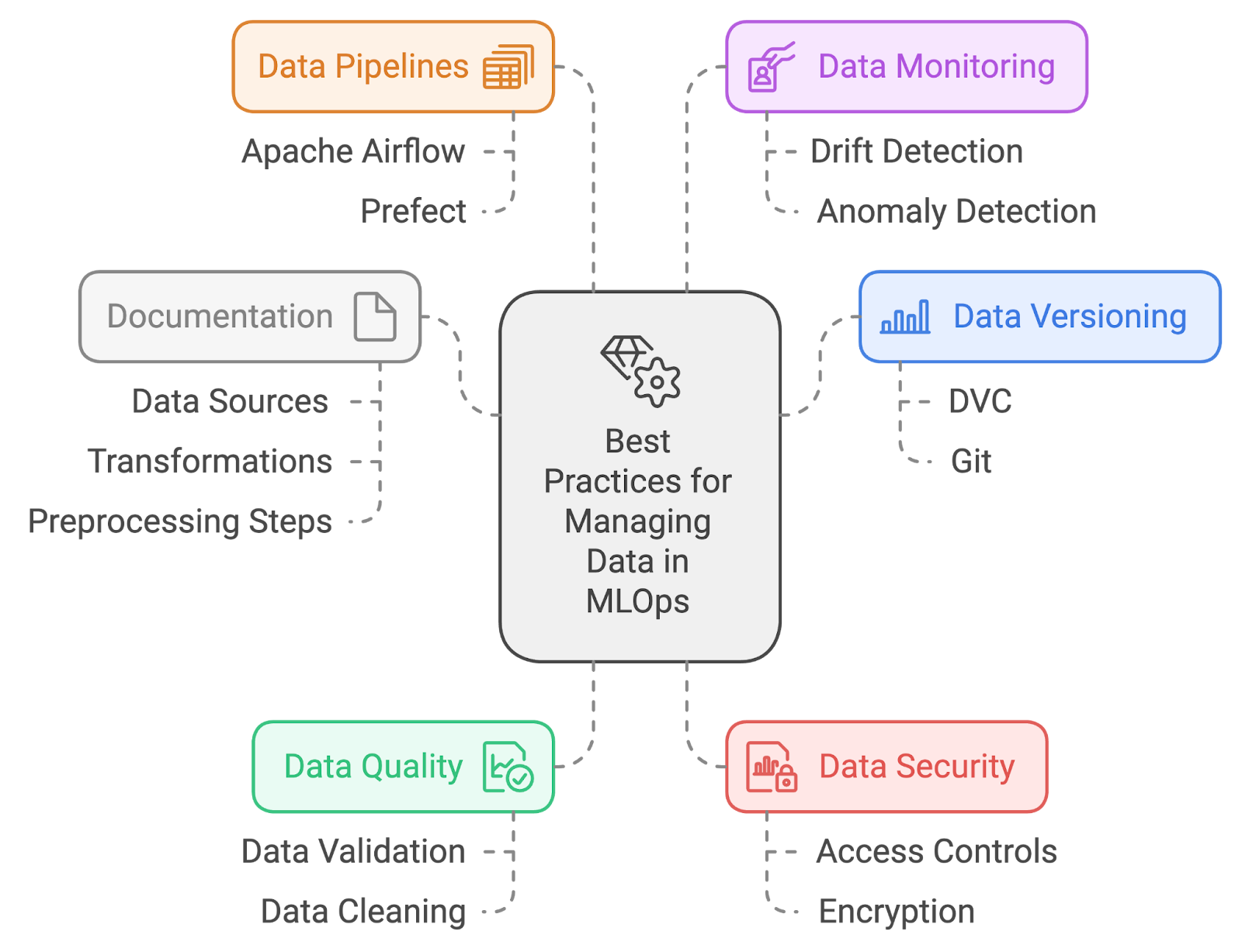
Melhores práticas de gerenciamento de dados. Imagem criada pelo autor com napkin.ai
Descrição: Essa pergunta avalia como você integra esses processos em fluxos de trabalho automatizados.
Resposta: Lidar com engenharia de recursos e pré-processamento em um pipeline de MLOps envolve automatizar essas etapas para garantir consistência e reprodutibilidade. Você pode usar ferramentas como Apache Airflow ou Prefect para criar pipelines de dados que realizam tarefas como:
Descrição: Essa pergunta avalia o quanto você entende sobre como programar e garantir o desempenho e a confiabilidade contínuos do modelo, incluindo as ferramentas e estratégias que você usaria para um monitoramento eficaz.
Resposta: Implementar o monitoramento do modelo em um ambiente de produção envolve várias práticas para garantir que o modelo funcione como esperado e continue confiável ao longo do tempo:
O curso Monitoramento de Machine Learning deve te ajudar a responder perguntas como essa com mais detalhes!
Descrição: Essa pergunta quer saber como você faz pra garantir que os experimentos de machine learning possam ser repetidos de forma consistente. Ele avalia o quanto você entende das práticas que ajudam na reprodutibilidade.
Resposta: Garantir que os experimentos de machine learning possam ser repetidos envolve:
Descrição: Essa pergunta avalia o quanto você entende dos desafios únicos de levar modelos de machine learning do desenvolvimento para ambientes de produção.
Resposta: Colocar em prática modelos de machine learning traz vários desafios. Uma das principais dificuldades é garantir a consistência entre os ambientes de desenvolvimento e produção, o que pode causar problemas de reprodutibilidade.
A deriva de dados é outra preocupação, já que os dados em produção podem mudar com o tempo, reduzindo a precisão do modelo.
Além disso, integrar modelos em sistemas já existentes, monitorar seu desempenho e automatizar fluxos de trabalho de retreinamento costumam ser tarefas complicadas que exigem uma colaboração eficaz entre as equipes de ciência de dados e engenharia.
Superando desafios na operacionalização de modelos de ML. Imagem criada pelo autor com napkin.ai
Descrição: Essa pergunta avalia o quanto você entende sobre automatizar o retreinamento do modelo quando novos dados aparecem ou o desempenho do modelo piora.
Resposta: Implementar o retreinamento automatizado do modelo envolve configurar um pipeline que monitora o desempenho do modelo e o desvio dos dados. Quando a precisão do modelo cai abaixo de um limite ou quando novos dados estão disponíveis, ferramentas como Apache Airflow ou Kubeflow podem fazer um novo treinamento.
O retreinamento envolve buscar novos dados, fazer o pré-processamento, treinar o modelo com os mesmos hiperparâmetros ou com os atualizados e validar o novo modelo. Depois do retreinamento, o modelo atualizado é automaticamente implementado na produção.
Descrição: Essa pergunta testa o seu conhecimento sobre interpretabilidade de modelos e como você garante a transparência nas previsões dos modelos.
Resposta: Ferramentas como SHAP (SHapley Additive exPlanations) ou LIME (Local Interpretable Model-agnostic Explanations) são comumente usadas para explicar modelos.
Essas ferramentas ajudam a detalhar as previsões do modelo, mostrando a contribuição de cada recurso. A explicabilidade é fundamental no MLOps porque cria confiança com as partes interessadas e garante que os modelos cumpram as regulamentações, especialmente em setores como finanças e saúde. Isso também ajuda a identificar possíveis vieses ou problemas relacionados aos dados dentro do modelo.
Essa seção fala sobre perguntas de entrevista que focam nos aspectos de nuvem e infraestrutura do MLOps. Essas perguntas avaliam sua experiência na implantação, gerenciamento e dimensionamento de modelos de machine learning em ambientes de nuvem.
Descrição: Essa pergunta testa o que você sabe sobre como usar modelos de machine learning em um ambiente de nuvem. Ele avalia o seu entendimento sobre plataformas em nuvem, processos de implantação e ferramentas usadas para gerenciar modelos na nuvem.
Resposta: A implantação de modelos de ML na nuvem envolve as seguintes etapas:
Descrição: Essa pergunta quer saber se você entende o que é computação sem servidor e como ela pode ser usada na implantação de modelos de ML, avaliando se você consegue ver os prós e os contras.
Resposta: As arquiteturas sem servidor oferecem várias vantagens, como menos custos operacionais, já que não precisa cuidar dos servidores, e escalabilidade automática com base na demanda em tempo real, o que pode ajudar a economizar, já que os custos são baseados no uso real de computação.
Mas também tem desafios associados às arquiteturas sem servidor. Por exemplo, tem limitações no tempo de execução e na alocação de recursos que podem não ser adequadas para todos os tipos de modelos de ML, principalmente aqueles com grandes necessidades computacionais.
A latência de inicialização a frio também pode ser um problema, em que as solicitações iniciais após períodos de inatividade podem sofrer atrasos. Apesar desses desafios, as arquiteturas sem servidor podem ser super eficazes para certas cargas de trabalho se esses fatores forem gerenciados da maneira certa.
Outra forma de ver isso é com essa tabela que resume os prós e contras das arquiteturas sem servidor com base em aspectos específicos:
|
Aspecto |
Vantagens do servidor sem servidor |
Contras do servidor sem servidor |
|
Despesas operacionais |
Não precisa se preocupar com gerenciamento de servidor; a complexidade da infraestrutura é menor. |
Precisa saber sobre plataformas em nuvem pra cuidar de ambientes sem servidor. |
|
Escalonamento |
O dimensionamento automático é baseado na demanda em tempo real, o que traz eficiência de custos. |
Pode ser imprevisível para o orçamento se o dimensionamento for frequente. |
|
Eficiência de custos |
Pague só pelos recursos que você usar, o que pode ajudar a reduzir os custos. |
Pode ficar caro se muitas funções forem chamadas com frequência ou por muito tempo. |
|
Limites de execução |
Ótimo para tarefas leves ou de curta duração. |
Limitado pelo tempo de execução e pela alocação de recursos, pode não dar conta de modelos de ML que exigem muitos recursos. |
|
Partida a frio |
Reduz os custos operacionais com escalabilidade sob demanda. |
Pode rolar atrasos na inicialização a frio depois de um tempo sem usar o computador, o que pode afetar aplicativos que dependem muito da latência. |
|
Adequação do modelo ML |
Funciona bem para tarefas de ML em pequena escala, inferência ou processamento em lote. |
Modelos de ML que exigem muita computação e têm tarefas que demoram muito não são adequados. |
Descrição: Essa pergunta avalia suas estratégias para otimizar e gerenciar recursos computacionais durante o treinamento de modelos de ML na nuvem. Ele avalia sua capacidade de garantir o uso eficiente dos recursos da nuvem.
Resposta: Gerenciar recursos computacionais envolve:
Descrição: Essa pergunta fala sobre como manter a segurança e a conformidade dos dados durante a implantação de modelos de ML em ambientes de nuvem, com foco nas melhores práticas e nos requisitos regulatórios.
Resposta: Garantir a segurança e a conformidade dos dados envolve:
Segurança e conformidade podem ser a última coisa em que um engenheiro quer pensar, mas estão se tornando cada vez mais importantes. O curso Entendendo o GDPR, junto com os outros sugeridos ao longo deste artigo, deve te ajudar a ficar por dentro do assunto.
Descrição: Essa pergunta fala sobre estratégias para gerenciar e otimizar os custos da nuvem relacionados ao treinamento e à implantação de modelos de ML, avaliando o conhecimento sobre técnicas de gerenciamento de custos.
Resposta: As estratégias para gerenciar os custos da nuvem incluem:
Ciclo de gerenciamento de custos da nuvem. Imagem criada pelo autor com napkin.ai
Descrição: Essa pergunta quer saber o que você entende sobre as vantagens e desvantagens de usar modelos em dispositivos de ponta ou na nuvem.
Resposta: A implantação em nuvem envolve a execução de modelos em servidores centralizados, oferecendo escalabilidade e manutenção mais fácil, mas com possíveis problemas de latência.
A implantação de borda envolve a execução de modelos diretamente em dispositivos como smartphones ou dispositivos IoT, o que reduz a latência e melhora a privacidade dos dados, mas pode ser limitada pelos recursos computacionais. A implantação em borda é ideal para aplicativos de processamento em tempo real, enquanto a implantação em nuvem é mais adequada para modelos que exigem bastante poder computacional e flexibilidade.
Descrição: Essa pergunta avalia o seu conhecimento sobre como criar sistemas resilientes para implementar modelos de machine learning.
Resposta: Garantir alta disponibilidade envolve implantar modelos em várias zonas ou regiões de disponibilidade e configurar mecanismos de failover automatizados.
Os balanceadores de carga podem distribuir o tráfego para evitar gargalos. Para ter tolerância a falhas, fazer backups regulares, ter redundância e fazer verificações de integridade pode evitar que o sistema pare de funcionar. Aproveitar serviços em nuvem como o AWS Elastic Load Balancing e recursos de autoescalonamento também ajuda a garantir que, se uma instância falhar, outras possam assumir sem tempo de inatividade.
Essa seção fala sobre os aspectos comportamentais e de resolução de problemas do MLOps, vendo como os candidatos lidam com desafios reais, trabalham em equipe e resolvem várias questões na implantação e gestão de modelos de machine learning.
Descrição: Essa pergunta avalia as habilidades de resolução de problemas em situações reais.
Exemplo de resposta: Teve uma situação em que um modelo que estava em produção começou a apresentar uma queda significativa no desempenho. O primeiro passo foi analisar os registros e métricas do modelo para ver se tinha alguma coisa fora do normal. Ficou claro que o pipeline de dados estava recebendo dados que tinham mudado de estrutura por causa de atualizações recentes nos sistemas de origem.
O próximo passo foi validar os dados em relação à entrada esperada do modelo e verificar se havia discrepâncias. Depois de confirmar o problema com os dados, conversei com a equipe de engenharia de dados para consertar o pipeline de dados. Então, lancei uma correção rápida para atualizar o modelo com o tratamento de entrada corrigido.
Por fim, acompanhei de perto o modelo após a implementação para garantir que o desempenho voltasse aos níveis esperados e comuniquei as conclusões e a resolução às partes interessadas.
Descrição: Essa pergunta avalia como você lida com diferentes versões de modelos de machine learning quando trabalha em equipe.
Exemplo de resposta: Eu uso sistemas de controle de versão como MLflow ou DVC para gerenciar e acompanhar diferentes versões do modelo. Cada versão recebe um identificador único e é fornecida documentação detalhada para cada atualização, a fim de garantir que os membros da equipe entendam as alterações.
Além disso, eu garanto que os novos modelos sejam testados exaustivamente em um ambiente de teste antes de serem implementados na produção, o que ajuda a evitar interrupções e manter o desempenho do modelo.
Descrição: Essa pergunta avalia sua capacidade de trabalhar de forma eficaz com diferentes equipes, como cientistas de dados, engenheiros e gerentes de produto, e como você lida e resolve desafios em um ambiente multifuncional.
Exemplo de resposta: Uma situação desafiadora envolveu a coordenação entre cientistas de dados, engenheiros e gerentes de produto para implementar um novo modelo com dependências complexas. O segredo para uma colaboração eficaz foi criar canais de comunicação claros desde o início.
Reuniões regulares foram marcadas para alinhar objetivos, programar o progresso e resolver quaisquer obstáculos. Para preencher as lacunas de conhecimento, organizei sessões de compartilhamento de conhecimento onde os membros da equipe podiam discutir suas respectivas áreas de especialização.
Além disso, usar ferramentas de gerenciamento de projetos para programar tarefas e marcos ajudou a manter todo mundo atualizado sobre o status do projeto. Essa abordagem garantiu que as contribuições de cada membro da equipe fossem consideradas e que trabalhássemos juntos para uma implementação bem-sucedida.
Descrição: Essa pergunta analisa suas estratégias para dimensionar modelos de machine learning para atender às crescentes demandas, avaliando sua compreensão dos aspectos técnicos e operacionais da escalabilidade.
Exemplo de resposta: Aumentar a escala dos modelos de ML para lidar com o aumento da carga de usuários envolve algumas etapas importantes.
Primeiro, eu analisaria as métricas de desempenho do modelo atual para identificar possíveis gargalos. Para lidar com o aumento da demanda, eu usaria soluções de autoescalonamento baseadas em nuvem para ajustar os recursos com base no tráfego de forma dinâmica.
Além disso, otimizar o próprio modelo com técnicas como quantização ou poda pode ajudar a reduzir o consumo de recursos sem prejudicar o desempenho.
Eu também faria testes de carga pra simular um tráfego maior e garantir que o sistema aguente tudo.
E por último, mas não menos importante, eu implementaria um monitoramento contínuo para ficar por dentro do desempenho dos modelos, assim eu poderia ajustar a alocação de recursos conforme necessário e manter o desempenho sob cargas variáveis.
Descrição: Essa pergunta avalia sua capacidade de lidar com a comunicação e as expectativas quando um modelo não consegue entregar os resultados esperados.
Exemplo de resposta: Quando o desempenho do modelo não atinge as expectativas, eu me concentro em uma comunicação transparente com as partes interessadas. Explico as limitações do modelo e os motivos do seu desempenho, seja por causa de problemas com a qualidade dos dados, sobreajuste ou expectativas iniciais que não são realistas.
Depois, eu trabalho com eles para definir metas mais realistas, dar insights baseados em dados e sugerir melhorias, como juntar mais dados de treinamento ou ajustar a arquitetura do modelo.
Descrição: Essa pergunta avalia sua capacidade de priorizar a manutenção da qualidade do código a longo prazo e o cumprimento dos prazos do projeto a curto prazo.
Exemplo de resposta: Teve uma época em que a gente tinha um prazo apertado pra implementar um modelo pra um novo recurso de produto. A gente priorizou a entrega rápida, pulando certas partes não essenciais do código, como documentação detalhada e testes desnecessários.
Depois do lançamento, a gente reservou um tempo pra revisar o código e resolver esses problemas, garantindo que a dívida técnica fosse minimizada depois do lançamento. Isso nos permitiu cumprir o prazo e manter a estabilidade do projeto a longo prazo.
A preparação para uma entrevista de MLOps envolve uma combinação de conhecimento técnico, compreensão do ambiente da empresa e comunicação clara de suas experiências anteriores. Aqui estão algumas dicas essenciais para te ajudar a se preparar:
Certifique-se de que você entende bem os conceitos básicos de MLOps. Familiarize-se com as ferramentas e plataformas populares usadas em MLOps, como MLflow, Kubernetes e serviços baseados em nuvem, como AWS SageMaker ou Google AI Platform.
O programa de habilidades MLOps é o recurso perfeito, pois contém quatro cursos relevantes que garantem que você esteja atualizado com os conceitos e práticas de MLOps.
Pesquise as tecnologias e ferramentas específicas que a empresa que você está entrevistando usa. Entender a pilha de tecnologias deles vai te ajudar a adaptar suas respostas para se alinhar com o ambiente deles e mostrar que você é uma boa opção. Dá uma olhada nos serviços de nuvem, sistemas de controle de versão e práticas de gerenciamento de modelos que eles preferem pra mostrar que você está pronto pra se integrar perfeitamente ao fluxo de trabalho deles.
Esteja pronto para falar sobre projetos ou experiências específicas em que você aplicou práticas de MLOps. Prepare exemplos que mostrem suas habilidades para resolver problemas, sua capacidade de trabalhar com equipes multifuncionais e sua experiência com implantação e dimensionamento de modelos (se possível). Use esses exemplos para mostrar seu conhecimento prático e como você lidou com desafios em cargos anteriores.
Pratique regularmente exercícios de codificação relacionados ao MLOps, como escrever scripts para implantação de modelos, automatizar fluxos de trabalho ou desenvolver pipelines de dados.
O campo de MLOps está evoluindo rapidamente, por isso é importante manter-se atualizado sobre as últimas tendências, ferramentas e melhores práticas. Siga blogs do setor, participe de fóruns ou webinars relevantes e interaja com a comunidade MLOps para manter seus conhecimentos atualizados e relevantes.
MLOps é uma área que une a ciência de dados e as operações, garantindo que os modelos de machine learning sejam implementados, mantidos e dimensionados de forma eficaz.
Neste artigo, falamos sobre várias perguntas de entrevista que abrangem conceitos gerais de MLOps, aspectos técnicos, considerações sobre nuvem e infraestrutura e habilidades comportamentais para resolver problemas. Praticar essas perguntas vai aumentar bastante suas chances de sucesso nas entrevistas e te dar mais chances de conseguir o emprego!
Dá uma olhada nos recursos a seguir para continuar aprendendo:
Aprenda mais sobre MLOps com esses cursos!
Curso
Curso
Curso
blog
Zoumana Keita
12 min
blog
Hesam Sheikh Hassani
15 min
blog
Austin Chia
15 min