
Course
MLOps Concepts
2 hr
42.6K
Machine Learning Operations (MLOps) has emerged as one of the most sought-after fields in tech. As data teams increasingly deploy machine learning models into production environments, the demand for MLOps professionals will continue to rise.
If you’re seeking a career as an MLOps engineer, we are here to help you make that leap!
In this article, we will provide the top MLOps interview questions, along with detailed explanations and answers, to help you prepare effectively for your upcoming interview.
MLOps, short for Machine Learning Operations, is a discipline that combines machine learning with DevOps practices to streamline and automate the lifecycle of machine learning models.
The primary goal of MLOps is to bridge the gap between data science and IT operations, ensuring that machine learning models are developed effectively, deployed, monitored, and maintained efficiently in production environments.
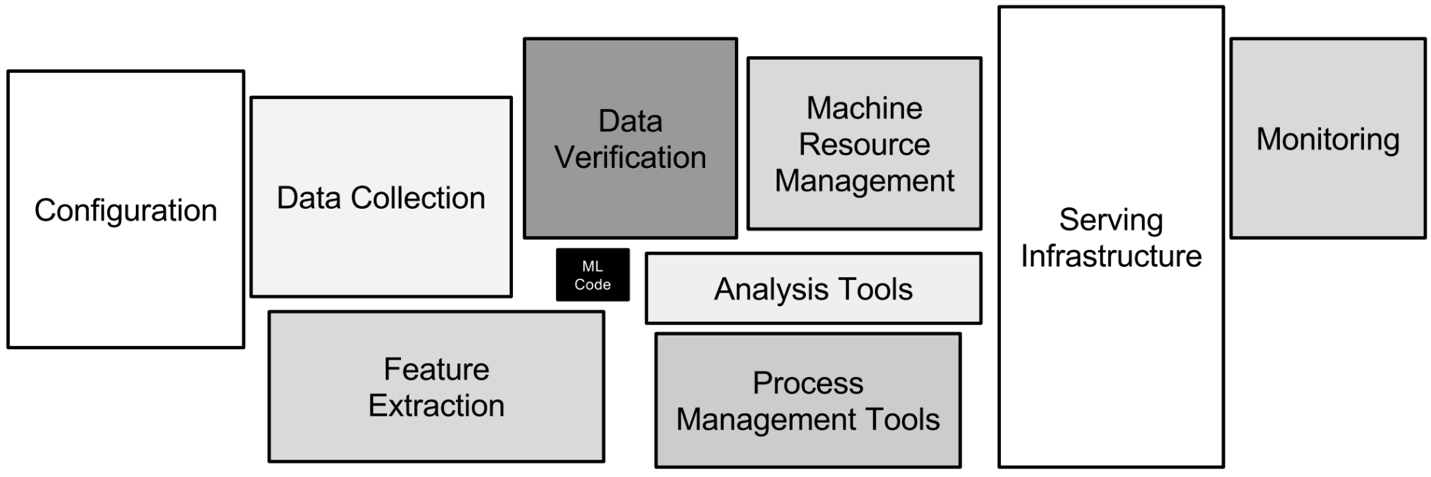
The different technical aspects involved in MLOps. Image by author
This role is important because it enables data teams to deploy machine learning models in production environments while ensuring they can be scaled and maintained effectively. In essence, MLOps accelerate innovation, enhance operational efficiency, and help companies unlock the full potential of their data-driven initiatives.
The skills required in MLOps include:
Yes, an MLOps engineer is like a unicorn! And that’s precisely the reason why they’re in high demand and receive increasingly high salaries.
In this section, we will explore fundamental MLOps interview questions that assess your understanding of core concepts and principles. These questions are designed to test your knowledge of the basic responsibilities and challenges of MLOps and your ability to communicate your knowledge effectively.
Familiarize yourself with these questions to build a strong foundation in preparation for more advanced topics and to demonstrate your competence in the field.
Description: This question tests your understanding of the fundamental differences between MLOps and DevOps, which are often confused.
Answer: MLOps and DevOps are both collaboration-focused strategies but serve different purposes. DevOps centers on automating software application development, testing, and deployment, standardizing environments to streamline these processes.
In contrast, MLOps is tailored to machine learning workflows, emphasizing managing and maintaining data pipelines and models. While DevOps aims to automate routine tasks and standardize application deployment, MLOps addresses the experimental nature of machine learning, including tasks like data validation, model quality evaluation, and ongoing model validation.
Comparing and contrasting DevOps and MLOps. Image by author created with napkin.ai
Description: This interview question evaluates your knowledge of the impact of evolving data on model accuracy and the importance of monitoring and updating models.
Answer: Model drift and concept drift refer to changes in the performance of machine learning models over time due to evolving data patterns and underlying relationships:
Description: This interview question examines your knowledge of testing practices to ensure a machine learning model is reliable and performs well before being deployed into a production environment.
Answer: There are a number of different tests that must be conducted before deploying an ML model into production. This table provides a comprehensive view of each testing type, including its objectives, tools used, and when it should be applied during the machine learning development lifecycle:
|
Testing type |
Objective |
Tools used |
When to use |
|
Unit testing |
Verify individual model components, such as preprocessing steps and feature extraction functions. |
PyTest, unittest, scikit-learn (for transformations) |
During development, when implementing or updating model components. |
|
Integration testing |
Ensure the model interacts correctly with other system components and data sources in the production environment. |
Docker, Kubernetes, Jenkins, Apache Kafka |
After unit testing, when deploying the model into a production-like environment. |
|
Performance testing |
Evaluate the model's accuracy, precision, recall, and other relevant metrics using a validation dataset. |
Scikit-learn, TensorFlow, PyTorch, MLflow |
After integration testing, to ensure the model meets expected performance standards. |
|
Stress testing |
Assess how the model handles high loads and large data volumes, ensuring scalability. |
Apache JMeter, Locust, Dask |
Before deploying in environments with high data volume or when scaling is a concern. |
|
A/B testing |
Compare the model's performance against existing models or baseline metrics in a live environment. |
Optimizely, SciPy, Google Optimize |
Post-deployment, when validating model performance in production and optimizing model versions. |
|
Robustness testing |
Ensure the model is resilient to data anomalies and edge cases. |
Adversarial robustness libraries (e.g., CleverHans), custom scripts |
After performance testing, to confirm reliability under abnormal or unexpected conditions. |
Description: This interview question evaluates your understanding of the role and significance of version control in MLOps practices. It focuses on how managing different versions of models, data, and code contributes to effective model deployment and maintenance.
Answer: Version control is vital in MLOps because it helps manage and track changes to machine learning models, datasets, and code throughout their lifecycle. Using version control systems like Git for code and tools like DVC (Data Version Control) for datasets and models ensures that all changes are documented and reversible.
This practice supports reproducibility, facilitates collaboration among team members, and allows for easy rollback to previous versions if issues arise. It ensures consistency and reliability in model performance, which is important for maintaining high-quality deployments.
To learn more about this concept, review The Complete Guide to Data Version Control (DVC). It will prepare you for these types of questions during your interview!
Description: This interview question aims to assess your knowledge of different methods for packaging machine learning models for deployment. It tests your understanding of how to prepare models for integration into various environments and applications.
Answer: There are several effective ways to package machine learning models:
A great way to learn more about packaging models is to become familiar with containerization. Docker is a fundamental tool that every MLOps engineer should know. To brush up on your knowledge, head to the Introduction to Docker course.
Description: This question evaluates your knowledge of monitoring models in production and understanding which metrics are critical for ensuring ongoing performance and reliability.
Answer: Monitoring is essential in MLOps to ensure models continue performing as expected in production. Metrics to track include accuracy, precision, recall, and other performance indicators to detect model degradation.
Monitoring for data drift is also critical, as changes in data patterns can affect the model’s predictions. Additionally, infrastructure metrics like latency and resource usage (e.g., CPU, memory) help ensure the system remains scalable and responsive.
Description: This interview question assesses your understanding of potential obstacles and how to address them to ensure successful model deployment.
Answer: Common issues in ML model deployment include:
All employers are looking for problem-solving skills, particularly when it comes to handling data in a role like MLOps. To get up to speed with two very important topics in the era of ML, check out the Introduction to Data Quality and the Introduction to Data Security courses.
Description: This interview question tests your ability to differentiate between Canary and Blue-Green deployment methods and their benefits for rolling out new changes.
Answer: Canary and Blue-Green deployment strategies are both used to manage the rollout of updates, but they differ in their approaches:
Both strategies aim to reduce deployment risks and downtime, but Canary deployments focus on incremental release and gradual exposure, while Blue-Green deployments ensure a seamless switch between environments.
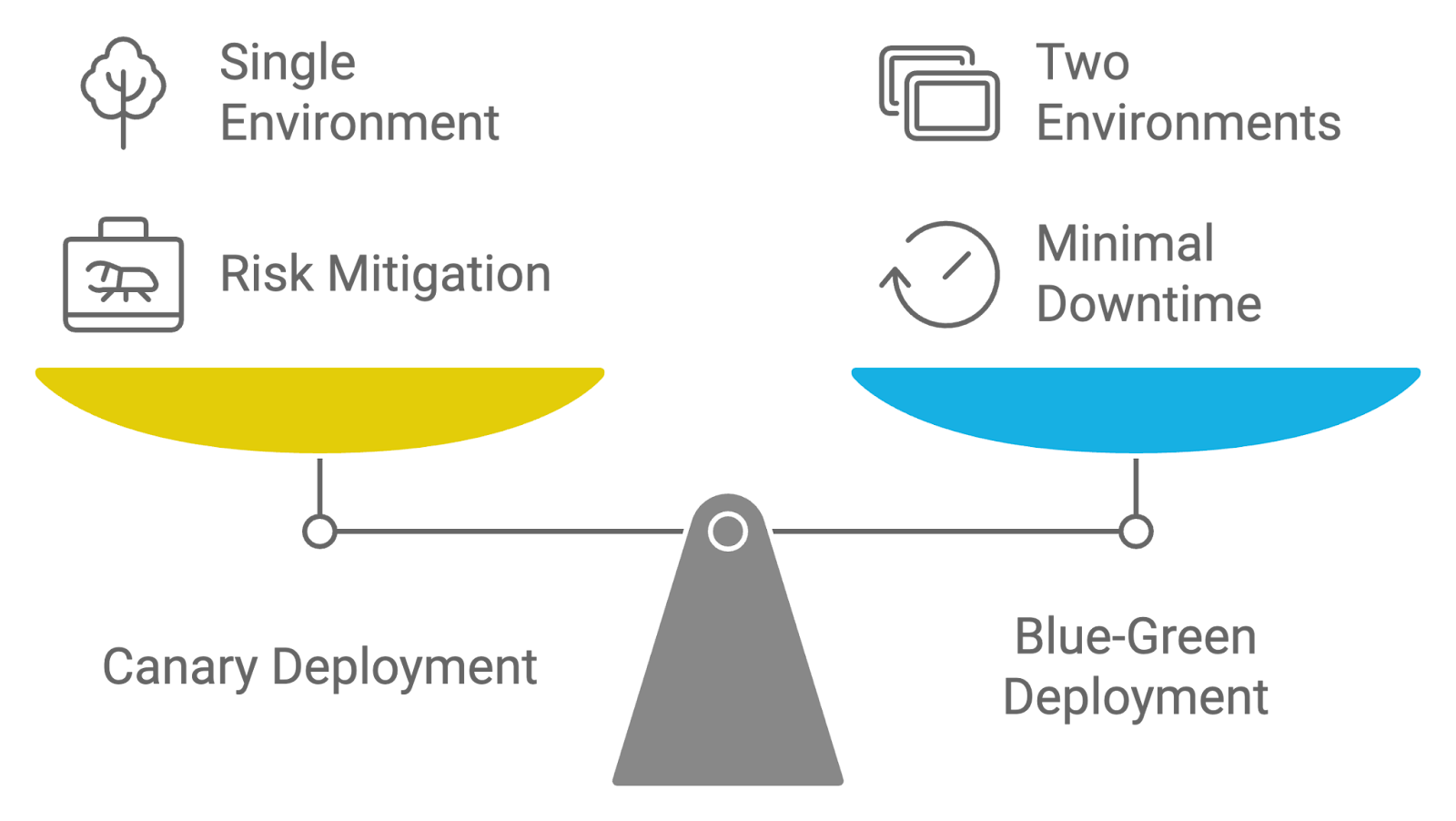
Comparing deployment strategies: Canary versus Blue-Green. Image by author created with napkin.ai
Description: This question tests your knowledge of the strategies and tools used to automate the retraining of machine learning models as new data becomes available.
Answer: Automating model retraining in MLOps involves setting up a pipeline that triggers retraining when certain conditions are met, such as performance degradation or the availability of new data.
Tools like Airflow or Kubeflow can orchestrate these workflows, automating tasks like data ingestion, feature engineering, model training, and evaluation. Continuous monitoring is essential to ensure the model meets performance thresholds before deployment, and versioning tools like DVC help track different model versions during retraining.
In this section, we will go into technical MLOps interview questions that assess your practical skills and understanding of advanced concepts.
These questions focus on the technical aspects of deploying, managing, and optimizing machine learning models, and they are designed to evaluate your proficiency with tools, techniques, and best practices in the field.
Description: This question tests your knowledge of setting up CI/CD pipelines specifically for machine learning workflows. It assesses your ability to automate the deployment process and manage model updates efficiently.
Answer: Implementing CI/CD for machine learning models involves setting up pipelines that automate the process from code changes to deployment.
For example, you can use Jenkins or GitHub Actions to trigger builds and tests whenever there is a change in the model code or data. The pipeline includes stages such as:
By automating these stages, you ensure that models are consistently and reliably updated with minimal manual intervention.
If you need to improve your CI/CD knowledge, take the CI/CD for Machine Learning course. It will make you shine in your interview!
Description: This interview question focuses on your understanding of effective data management practices within MLOps. It assesses your ability to handle data quality, versioning, and organization to support robust and reliable machine learning workflows.
Answer: Best practices for managing data in MLOps include:
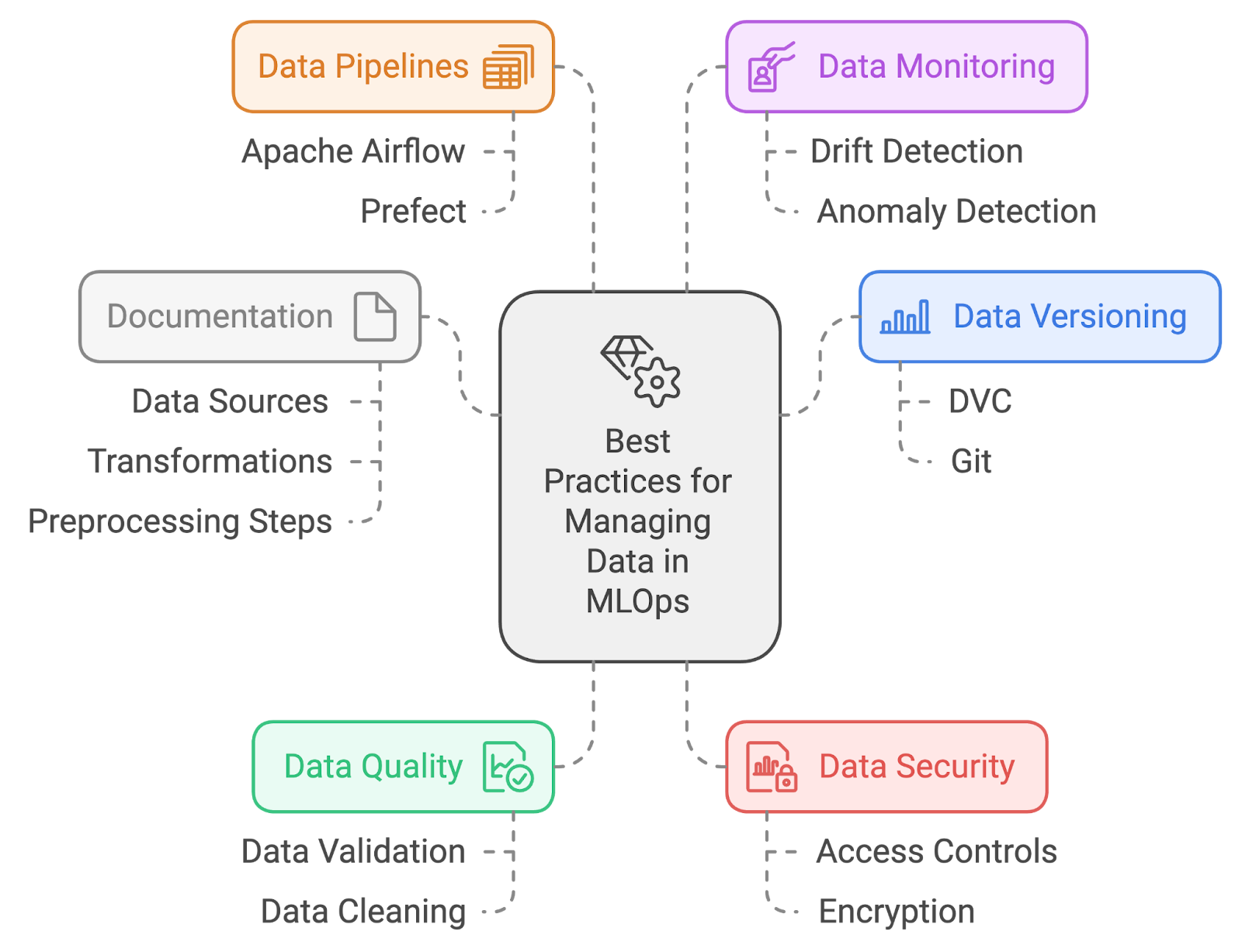
Data management best practices. Image by author created with napkin.ai
Description: This question evaluates how you integrate these processes into automated workflows.
Answer: Handling feature engineering and preprocessing in an MLOps pipeline involves automating these steps to ensure consistency and reproducibility. You can use tools like Apache Airflow or Prefect to create data pipelines that perform tasks such as:
Description: This question assesses your understanding of how to track and ensure the ongoing performance and reliability of the model, including the tools and strategies you would use for effective monitoring.
Answer: Implementing model monitoring in a production environment involves several practices to guarantee that the model performs as expected and remains reliable over time:
The Machine Learning Monitoring course should get you up to speed to answer questions like this in more detail!
Description: This question explores your approach to ensuring that machine learning experiments can be replicated consistently. It assesses your understanding of practices that support reproducibility.
Answer: Ensuring the reproducibility of machine learning experiments involves:
Description: This question assesses your understanding of the unique challenges of taking machine learning models from development to production environments.
Answer: Operationalizing machine learning models presents several challenges. One of the primary difficulties is ensuring consistency between the development and production environments, which can lead to issues in reproducibility.
Data drift is another concern, as the data in production can change over time, reducing the model’s accuracy.
Additionally, integrating models into existing systems, monitoring their performance, and automating retraining workflows are often complex tasks that require effective collaboration between data science and engineering teams.
Overcoming challenges in operationalizing ML models. Image by author created with napkin.ai
Description: This question evaluates your understanding of automating model retraining when new data is available or the model’s performance degrades.
Answer: Implementing automated model retraining involves setting up a pipeline that monitors model performance and data drift. When the model's accuracy drops below a threshold or when new data is available, tools like Apache Airflow or Kubeflow can trigger retraining.
Retraining involves fetching new data, preprocessing, training the model with the same or updated hyperparameters, and validating the new model. After retraining, the updated model is automatically deployed to production.
Description: This question tests your knowledge of model interpretability and how you ensure transparency in model predictions.
Answer: Tools like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) are commonly used for model explainability.
These tools help break down model predictions by showing the contribution of individual features. Explainability is key in MLOps because it builds trust with stakeholders and ensures models comply with regulations, especially in industries like finance and healthcare. It also helps identify potential biases or data-related issues within the model.
This section covers interview questions focused on cloud and infrastructure aspects of MLOps. These questions evaluate your expertise in deploying, managing, and scaling machine learning models within cloud environments.
Description: This question examines your knowledge of deploying machine learning models in a cloud environment. It assesses your understanding of cloud platforms, deployment processes, and tools used for managing models in the cloud.
Answer: Deploying ML models on the cloud involves the following steps:
Description: This question explores the understanding of serverless computing and its application in ML model deployment, evaluating the ability to weigh benefits against challenges.
Answer: Serverless architectures offer several benefits, including reduced operational overhead, as there is no need for server management, and automatic scaling based on real-time demand, which can lead to cost savings since charges are based on actual compute usage.
However, there are also challenges associated with serverless architectures. For instance, there are limitations on execution time and resource allocation that may not be suitable for all types of ML models, particularly those with high computational needs.
Cold start latency can also be an issue, where initial requests after periods of inactivity may experience delays. Despite these challenges, serverless architectures can be highly effective for certain workloads if these factors are managed appropriately.
Another way to see this is with this table that summarizes the pros and cons of serverless architectures based on specific aspects:
|
Aspect |
Serverless pros |
Serverless cons |
|
Operational overhead |
No need for server management; reduced infrastructure complexity. |
Requires knowledge of cloud platforms to manage serverless environments. |
|
Scaling |
Automatic scaling is based on real-time demand, leading to cost efficiency. |
Can be unpredictable for budgeting if scaling is frequent. |
|
Cost efficiency |
Pay only for the resources used, potentially reducing costs. |
Can become expensive if many functions are invoked frequently or for long durations. |
|
Execution limits |
Suitable for lightweight or short-running tasks. |
Limited by execution time and resource allocation, may not handle resource-intensive ML models. |
|
Cold start |
Reduces operational overhead by scaling on demand. |
Cold start delays may occur after periods of inactivity, affecting latency-sensitive applications. |
|
ML model suitability |
Works well for small-scale ML tasks, inference, or batch processing. |
High-computation ML models with long-running tasks are not suitable. |
Description: This question assesses your strategies for optimizing and managing computational resources during ML model training in the cloud. It evaluates your ability to ensure efficient use of cloud resources.
Answer: Managing computational resources involves:
Description: This question examines the approach to maintaining data security and compliance during ML model deployment in cloud environments, focusing on best practices and regulatory requirements.
Answer: Ensuring data security and compliance involves:
Security and compliance may be the last thing an engineer wants to think about, but they’re becoming increasingly important. The course Understanding GDPR, along with the others suggested throughout this article, should get you up to speed.
Description: This question explores strategies for managing and optimizing cloud costs related to ML model training and deployment, assessing knowledge of cost management techniques.
Answer: Strategies for managing cloud costs include:
Cloud cost management cycle. Image by author created with napkin.ai
Description: This question explores your understanding of the trade-offs between deploying models on edge devices versus the cloud.
Answer: Cloud deployment involves running models on centralized servers, offering scalability and easier maintenance but with potential latency issues.
Edge deployment involves running models directly on devices like smartphones or IoT devices, which reduces latency and improves data privacy but can be limited by computational resources. Edge deployment is ideal for real-time processing applications, while cloud deployment is better suited for models requiring significant computational power and flexibility.
Description: This question assesses your knowledge of building resilient systems for deploying machine learning models.
Answer: Ensuring high availability involves deploying models across multiple availability zones or regions and setting up automated failover mechanisms.
Load balancers can distribute traffic to avoid bottlenecks. For fault tolerance, regular backups, redundancy, and health checks can prevent system failures. Leveraging cloud services like AWS Elastic Load Balancing and autoscaling features also helps to ensure that if one instance fails, others can take over without downtime.
This section delves into behavioral and problem-solving aspects of MLOps, assessing how candidates approach real-world challenges, collaborate with teams, and handle various issues in the deployment and management of machine learning models.
Description: This question assesses problem-solving skills in real-world scenarios.
Example response: "There was a situation where a model deployed in production started showing a significant drop in performance. The first step was to troubleshoot the model's logs and metrics to identify any anomalies. It became apparent that the data pipeline was feeding in data that had changed in structure due to recent updates in the source systems.
The next step was to validate the data against the model’s expected input and check for discrepancies. After confirming the data issue, I coordinated with the data engineering team to rectify the data pipeline. Then I rolled out a hotfix to update the model with the corrected input handling.
Finally, I monitored the model closely post-deployment to ensure that performance returned to expected levels and communicated the findings and resolution to stakeholders."
Description: This question evaluates your approach to managing different versions of machine learning models when working in a team setting.
Example response: “I use version control systems like MLflow or DVC to manage and track different model versions. Each version is assigned a unique identifier, and detailed documentation is provided for each update to ensure team members understand the changes.
Additionally, I ensure that new models are thoroughly tested in a staging environment before being deployed to production, which helps avoid disruptions and maintain model performance.”
Description: This question assesses your ability to work effectively with different teams, such as data scientists, engineers, and product managers, and how you navigate and resolve challenges in a cross-functional setting.
Example response: "One challenging situation involved coordinating between data scientists, engineers, and product managers to deploy a new model with complex dependencies. The key to effective collaboration was to establish clear communication channels from the start.
Regular meetings were scheduled to align on goals, track progress, and address any roadblocks. To bridge knowledge gaps, I facilitated knowledge-sharing sessions where team members could discuss their respective areas of expertise.
Additionally, using project management tools to track tasks and milestones helped keep everyone updated on the project status. This approach ensured that each team member's input was considered and that we worked together towards a successful deployment."
Description: This question explores your strategies for scaling machine learning models to accommodate growing demands, assessing their understanding of scalability's technical and operational aspects.
Example response: "Scaling ML models to handle increased user load involves a few critical steps.
First, I would analyze the current model's performance metrics to identify any potential bottlenecks. To handle increased demand, I would leverage cloud-based auto-scaling solutions to adjust resources based on traffic dynamically.
Additionally, optimizing the model itself through techniques like quantization or pruning can help reduce its resource consumption without sacrificing performance.
I would also implement load testing to simulate higher traffic and ensure the system's robustness.
And last, but not least, I would implement continuous monitoring to stay up to date with the models performance, so I can adjust resource allocation as needed and maintain performance under varying loads.”
Description: This question assesses your ability to manage communication and expectations when a model fails to deliver expected outcomes.
Example response: "When model performance doesn’t meet expectations, I focus on transparent communication with stakeholders. I explain the model's limitations and the reasons for its performance, whether it's due to data quality issues, overfitting, or unrealistic initial expectations.
I then work with them to set more realistic goals, provide data-driven insights, and propose improvements, such as gathering more training data or adjusting the model architecture."
Description: This question evaluates your ability to prioritize maintaining long-term code quality and meeting short-term project deadlines.
Example response: "There was a time when we had a tight deadline to deploy a model for a new product feature. We prioritized fast delivery by skipping certain non-critical parts of the codebase, such as comprehensive documentation and non-essential testing.
After the release, we allocated time to revisit the codebase and address these issues, ensuring that the technical debt was minimized post-launch. This allowed us to meet the deadline while maintaining long-term project stability."
Preparing for an MLOps interview involves a combination of technical knowledge, understanding of the company's environment, and clear communication of your past experiences. Here are some essential tips to help you get ready:
Ensure you have a solid grasp of core MLOps concepts. Familiarize yourself with popular tools and platforms used in MLOps, such as MLflow, Kubernetes, and cloud-based services like AWS SageMaker or Google AI Platform.
The MLOps skill track is the perfect resource because it contains four relevant courses that ensure you’re up-to-date with MLOps concepts and practices.
Research the specific technologies and tools used by the company you’re interviewing. Understanding their tech stack will help you tailor your responses to align with their environment and demonstrate that you’re a good fit. Look into their preferred cloud services, version control systems, and model management practices to show that you’re prepared to integrate seamlessly into their workflow.
Be ready to discuss specific projects or experiences where you applied MLOps practices. Prepare examples that highlight your problem-solving skills, your ability to work with cross-functional teams, and your experience with model deployment and scaling (if possible). Use these examples to illustrate your practical knowledge and how you’ve successfully addressed challenges in previous roles.
Regularly practice coding exercises related to MLOps, such as writing scripts for model deployment, automating workflows, or developing data pipelines.
The field of MLOps is rapidly evolving, so it’s important to stay updated on the latest trends, tools, and best practices. Follow industry blogs, participate in relevant forums or webinars, and engage with the MLOps community to keep your knowledge current and relevant.
MLOps is a field that bridges the gap between data science and operations, ensuring that machine learning models are deployed, maintained, and scaled effectively.
Throughout this post, we covered a range of interview questions that span general MLOps concepts, technical aspects, cloud and infrastructure considerations, and behavioral problem-solving skills. Practicing these questions will significantly boost the likelihood of success during your interviews and give you a better chance of landing the job!
Check out the following resources to continue your learning:
Learn more about MLOps with these courses!
Course
Course
Course
blog
Laiba Siddiqui
15 min
blog
Patrick Brus
15 min
blog
Thalia Barrera
15 min
blog
Abid Ali Awan
15 min
blog
Srujana Maddula
12 min
blog
Patrick Brus
15 min
