
Cours
Concepts MLOps
2 h
42.6K
Le domaine des opérations d'apprentissage automatique (MLOps) s'est imposé comme l'un des plus recherchés dans le secteur technologique. À mesure que les équipes chargées des données déploient de plus en plus de modèles d'apprentissage automatique dans les environnements de production, la demande de professionnels MLOps continuera d'augmenter.
Si vous envisagez une carrière en tant qu'ingénieur MLOps, nous sommes à votre disposition pour vous aider à franchir le pas.
Dans cet article, nous vous proposons les questions les plus fréquemment posées lors des entretiens MLOps, accompagnées d'explications détaillées et de réponses, afin de vous aider à vous préparer efficacement à votre prochain entretien.
MLOps, abréviation de Machine Learning Operations, est une discipline qui combine l'apprentissage automatique et les pratiques DevOps afin de rationaliser et d'automatiser le cycle de vie des modèles d'apprentissage automatique.
L'objectif principal du MLOps est de combler le fossé entre la science des données et les opérations informatiques, en veillant à ce que les modèles d'apprentissage automatique soient développés efficacement, déployés, surveillés et maintenus de manière optimale dans les environnements de production.
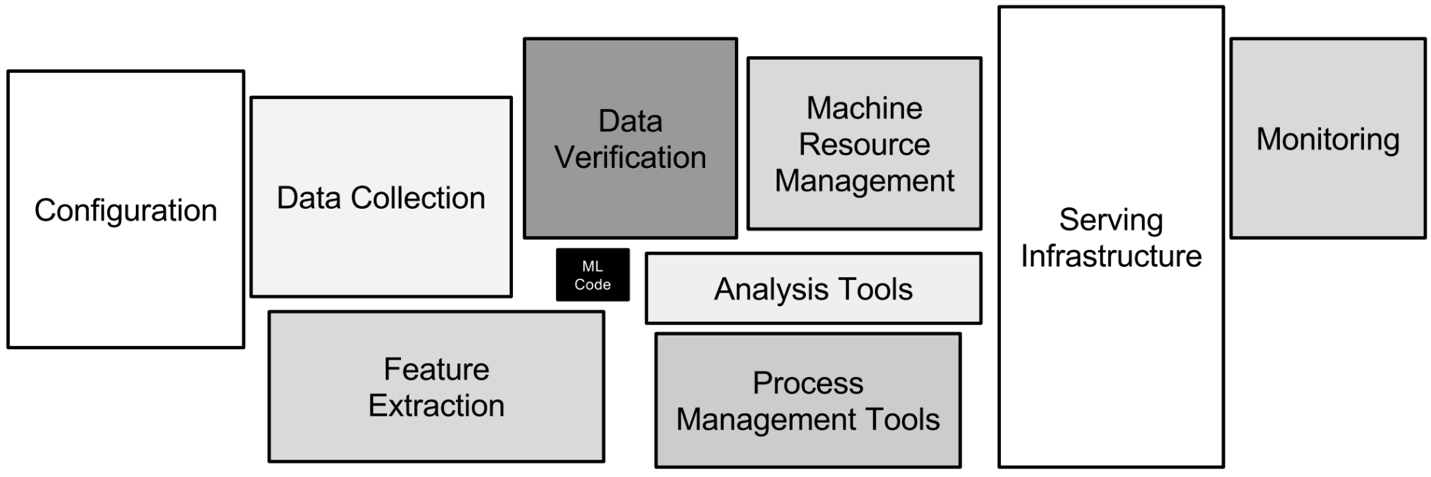
Les différents aspects techniques impliqués dans le MLOps. Image par l'auteur
Ce rôle est important car il permet aux équipes chargées des données de déployer des modèles d'apprentissage automatique dans des environnements de production tout en garantissant leur évolutivité et leur maintenance efficace. En substance, les MLOps accélèrent l'innovation, améliorent l'efficacité opérationnelle et aident les entreprises à exploiter pleinement le potentiel de leurs initiatives axées sur les données.
Les compétences requises en MLOps comprennent :
Oui, un ingénieur MLOps est aussi rare qu'une licorne. Et c'est précisément pour cette raison qu'ils sont très recherchés et bénéficient de salaires de plus en plus élevés.
Dans cette section, nous examinerons les questions fondamentales d'entretien MLOps qui évaluent votre compréhension des concepts et principes de base. Ces questions sont conçues pour évaluer votre connaissance des responsabilités et des défis fondamentaux liés au MLOps, ainsi que votre capacité à communiquer efficacement vos connaissances.
Familiarisez-vous avec ces questions afin de construire des bases solides en vue d'aborder des sujets plus avancés et de démontrer votre compétence dans ce domaine.
Description : Cette question évalue votre compréhension des différences fondamentales entre MLOps et DevOps, qui sont souvent confondus.
Réponse : MLOps et DevOps sont deux stratégies axées sur la collaboration, mais elles ont des objectifs différents. DevOps se concentre sur l'automatisation du développement, du test et du déploiement d'applications logicielles, en standardisant les environnements afin de rationaliser ces processus.
En revanche, MLOps est adapté aux flux de travail du machine learning, mettant l'accent sur la gestion et la maintenance des pipelines de données et des modèles. Alors que DevOps vise à automatiser les tâches routinières et à standardiser le déploiement des applications, MLOps s'intéresse à la nature expérimentale du machine learning, notamment à des tâches telles que la validation des données, l'évaluation de la qualité des modèles et la validation continue des modèles.
Comparaison et contraste entre DevOps et MLOps. Image créée par l'auteur à l'aide de napkin.ai
Description : Cette question d'entretien évalue votre connaissance de l'impact de l'évolution des données sur la précision des modèles et l'importance de surveiller et de mettre à jour ces derniers.
Réponse : La dérive du modèle et la dérive du concept désignent les changements dans les performances des modèles d'apprentissage automatique au fil du temps, dus à l'évolution des modèles de données et des relations sous-jacentes :
Description : Cette question d'entretien évalue vos connaissances en matière de pratiques de test visant à garantir la fiabilité et les performances d'un modèle d'apprentissage automatique avant son déploiement dans un environnement de production.
Réponse : Il existe plusieurs tests différents qui doivent être effectués avant de déployer un modèle ML en production. Ce tableau présente une vue d'ensemble de chaque type de test, y compris ses objectifs d', les outils utilisés et le moment où il doit être appliqué au cours du cycle de vie du développement de l'apprentissage automatique :
|
Type de test |
Objectif |
Outils utilisés |
Quand utiliser |
|
Test unitaire |
Vérifiez les composants individuels du modèle, tels que les étapes de prétraitement et les fonctions d'extraction de caractéristiques. |
PyTest, unittest, scikit-learn (pour les transformations) |
Au cours du développement, lors de la mise en œuvre ou de la mise à jour des composants du modèle. |
|
Test d'intégration |
Veuillez vous assurer que le modèle interagit correctement avec les autres composants du système et les sources de données dans l'environnement de production. |
Docker, Kubernetes, Jenkins, Apache Kafka |
Après les tests unitaires, lors du déploiement du modèle dans un environnement similaire à celui de production. |
|
Test de performance |
Veuillez évaluer l'exactitude, la précision, le rappel et d'autres mesures pertinentes du modèle à l'aide d'un ensemble de données de validation. |
Scikit-learn, TensorFlow, PyTorch, MLflow |
Après les tests d'intégration, afin de garantir que le modèle répond aux normes de performance attendues. |
|
Test de résistance |
Évaluez la manière dont le modèle gère les charges élevées et les volumes de données importants, en garantissant l'évolutivité. |
Apache JMeter, Locust, Dask |
Avant de déployer dans des environnements avec un volume de données élevé ou lorsque la mise à l'échelle est un enjeu. |
|
Test A/B |
Veuillez comparer les performances du modèle par rapport aux modèles existants ou aux mesures de référence dans un environnement réel. |
Optimizely, SciPy, Google Optimize |
Après le déploiement, lors de la validation des performances du modèle en production et de l'optimisation des versions du modèle. |
|
Test de robustesse |
Veuillez vous assurer que le modèle est résilient face aux anomalies de données et aux cas limites. |
Bibliothèques de robustesse antagoniste (par exemple, CleverHans), scripts personnalisés |
Après les tests de performance, afin de confirmer la fiabilité dans des conditions anormales ou imprévues. |
Description : Cette question d'entretien évalue votre compréhension du rôle et de l'importance du contrôle de version dans les pratiques MLOps. Il se concentre sur la manière dont la gestion des différentes versions des modèles, des données et du code contribue à un déploiement et à une maintenance efficaces des modèles.
Réponse : Le contrôle de version est essentiel dans le domaine du MLOps, car il facilite la gestion et le suivi des modifications apportées aux modèles d'apprentissage automatique, aux ensembles de données et au code tout au long de leur cycle de vie. L'utilisation de systèmes de contrôle de version tels que Git pour le code et d'outils tels que DVC (Data Version Control) pour les ensembles de données et les modèles garantit que toutes les modifications sont documentées et réversibles.
Cette pratique favorise la reproductibilité, facilite la collaboration entre les membres de l'équipe et permet de revenir facilement aux versions précédentes en cas de problème. Il garantit la cohérence et la fiabilité des performances du modèle, ce qui est essentiel pour maintenir des déploiements de haute qualité.
Pour en savoir plus sur ce concept, veuillez consulter le Guide complet du contrôle de version des données (DVC). Cela vous préparera à répondre à ce type de questions lors de votre entretien.
Description : Cette question d'entretien vise à évaluer votre connaissance des différentes méthodes de packaging des modèles d'apprentissage automatique en vue de leur déploiement. Il évalue votre compréhension de la manière de préparer des modèles en vue de leur intégration dans divers environnements et applications.
Réponse : Il existe plusieurs méthodes efficaces pour intégrer des modèles d'apprentissage automatique :
Une excellente façon d'approfondir vos connaissances sur les modèles d'empaquetage consiste à vous familiariser avec la conteneurisation. Docker est un outil essentiel que tout ingénieur MLOps devrait maîtriser. Pour rafraîchir vos connaissances, veuillez vous rendre sur le cours Introduction à Docker.
Description : Cette question évalue vos connaissances des modèles de surveillance en production et votre compréhension des indicateurs essentiels pour garantir des performances et une fiabilité continues.
Réponse : La surveillance est essentielle dans le cadre des MLOps afin de garantir que les modèles continuent de fonctionner comme prévu en production. Les indicateurs à suivre comprennent l'exactitude, la précision, le rappel et d'autres indicateurs de performance permettant de détecter la dégradation du modèle.
Il est également essentiel de surveiller la dérive des données, car les changements dans les modèles de données peuvent affecter les prévisions du modèle. De plus, les indicateurs d'infrastructure tels que la latence et l'utilisation des ressources (par exemple, le processeur, la mémoire) contribuent à garantir que le système reste évolutif et réactif.
Description : Cette question d'entretien évalue votre compréhension des obstacles potentiels et la manière de les surmonter afin de garantir le déploiement réussi du modèle.
Réponse : Les problèmes courants liés au déploiement de modèles d'apprentissage automatique comprennent :
Tous les employeurs recherchent des compétences en résolution de problèmes, en particulier lorsqu'il s'agit de traiter des données dans un poste tel que celui de MLOps. Pour vous familiariser avec deux sujets très importants à l'ère du ML, veuillez consulter les cours Introduction à la qualité des données et Introduction à la sécurité des données.
Description : Cette question d'entretien évalue votre capacité à distinguer les méthodes de déploiement Canary et Blue-Green, ainsi que leurs avantages respectifs pour la mise en œuvre de nouvelles modifications.
Réponse : Les stratégies de déploiement Canary et Blue-Green sont toutes deux utilisées pour gérer le déploiement des mises à jour, mais elles diffèrent dans leur approche :
Les deux stratégies visent à réduire les risques liés au déploiement et les temps d'arrêt, mais les déploiements Canary se concentrent sur les versions incrémentielles et l'exposition progressive, tandis que les déploiements Blue-Green garantissent une transition transparente entre les environnements.
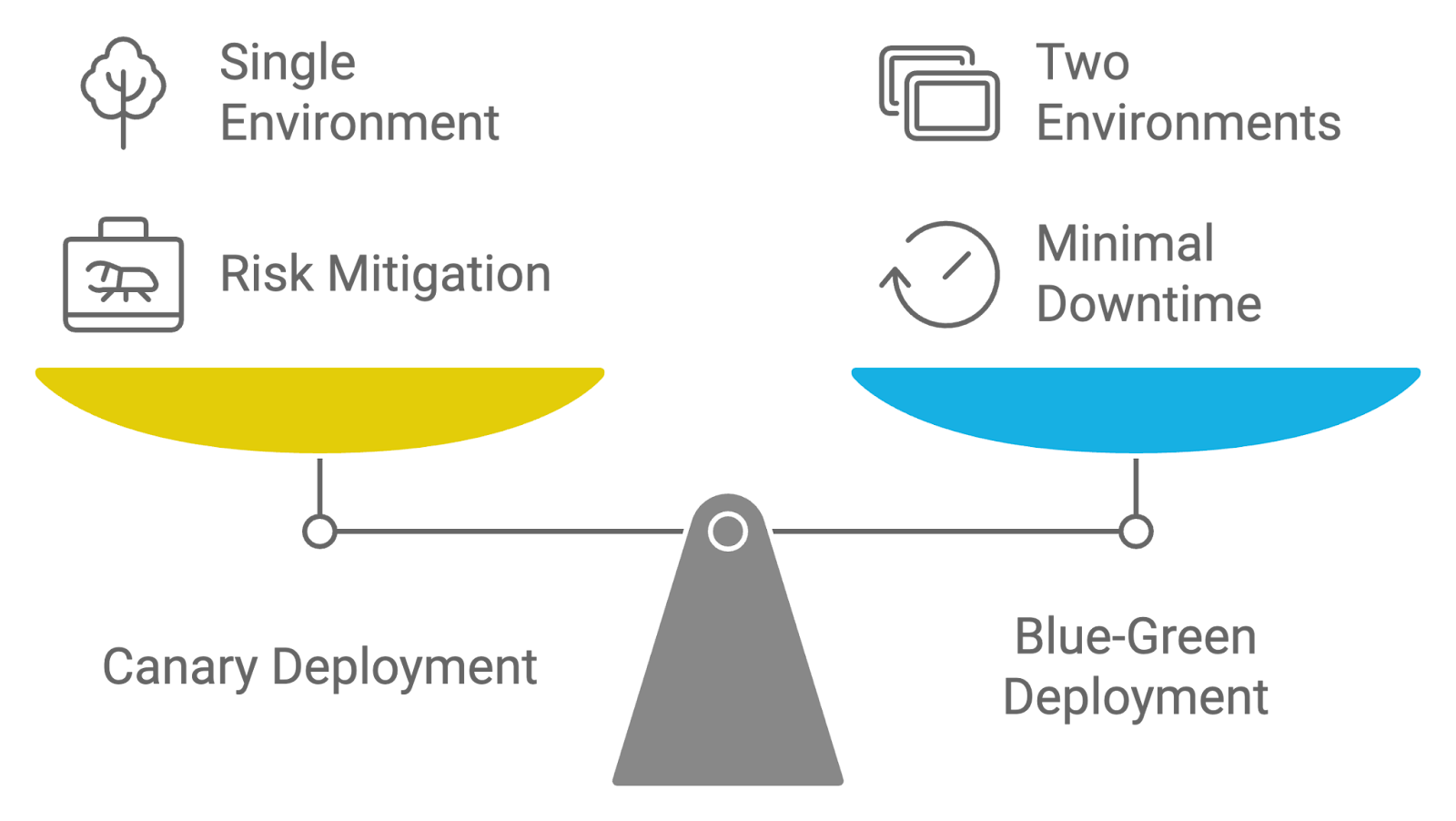
Comparaison des stratégies de déploiement : Canari contre Bleu-Vert. Image créée par l'auteur à l'aide de napkin.ai
Description : Cette question évalue votre connaissance des stratégies et des outils utilisés pour automatiser le réentraînement des modèles d'apprentissage automatique lorsque de nouvelles données deviennent disponibles.
Réponse : L'automatisation du réentraînement des modèles dans MLOps implique la mise en place d'un pipeline qui déclenche le réentraînement lorsque certaines conditions sont remplies, telles que la dégradation des performances ou la disponibilité de nouvelles données.
Des outils tels qu'Airflow ou Kubeflow peuvent orchestrer ces flux de travail, en automatisant des tâches telles que l'ingestion de données, l'ingénierie des fonctionnalités, l'entraînement des modèles et l'évaluation. Une surveillance continue est essentielle pour garantir que le modèle respecte les seuils de performance avant son déploiement. Des outils de gestion des versions tels que DVC facilitent le suivi des différentes versions du modèle pendant le réentraînement.
Dans cette section, nous aborderons les questions techniques d'entretien MLOps qui évaluent vos compétences pratiques et votre compréhension des concepts avancés.
Ces questions se concentrent sur les aspects techniques du déploiement, de la gestion et de l'optimisation des modèles d'apprentissage automatique. Elles sont conçues pour évaluer votre maîtrise des outils, des techniques et des meilleures pratiques dans ce domaine.
Description : Cette question évalue vos connaissances en matière de configuration de pipelines CI/CD spécifiquement destinés aux workflows d'apprentissage automatique. Il évalue votre capacité à automatiser le processus de déploiement et à gérer efficacement les mises à jour des modèles.
Réponse : La mise en œuvre du CI/CD pour les modèles d'apprentissage automatique implique la configuration de pipelines qui automatisent le processus, depuis les modifications du code jusqu'au déploiement.
Par exemple, vous pouvez utiliser Jenkins ou GitHub Actions pour déclencher des compilations et des tests chaque fois qu'il y a une modification dans le code ou les données du modèle. Le pipeline comprend les étapes suivantes :
En automatisant ces étapes, vous garantissez que les modèles sont mis à jour de manière cohérente et fiable, avec un minimum d'intervention manuelle.
Si vous souhaitez approfondir vos connaissances en matière de CI/CD, nous vous recommandons de suivre le cours CI/CD pour l'apprentissage automatique. Cela vous permettra de vous distinguer lors de votre entretien !
Description : Cette question d'entretien porte sur votre compréhension des pratiques efficaces de gestion des données dans le cadre du MLOps. Il évalue votre capacité à gérer la qualité, la gestion des versions et l'organisation des données afin de prendre en charge des workflows d'apprentissage automatique robustes et fiables.
Réponse : Les meilleures pratiques pour la gestion des données dans MLOps comprennent :
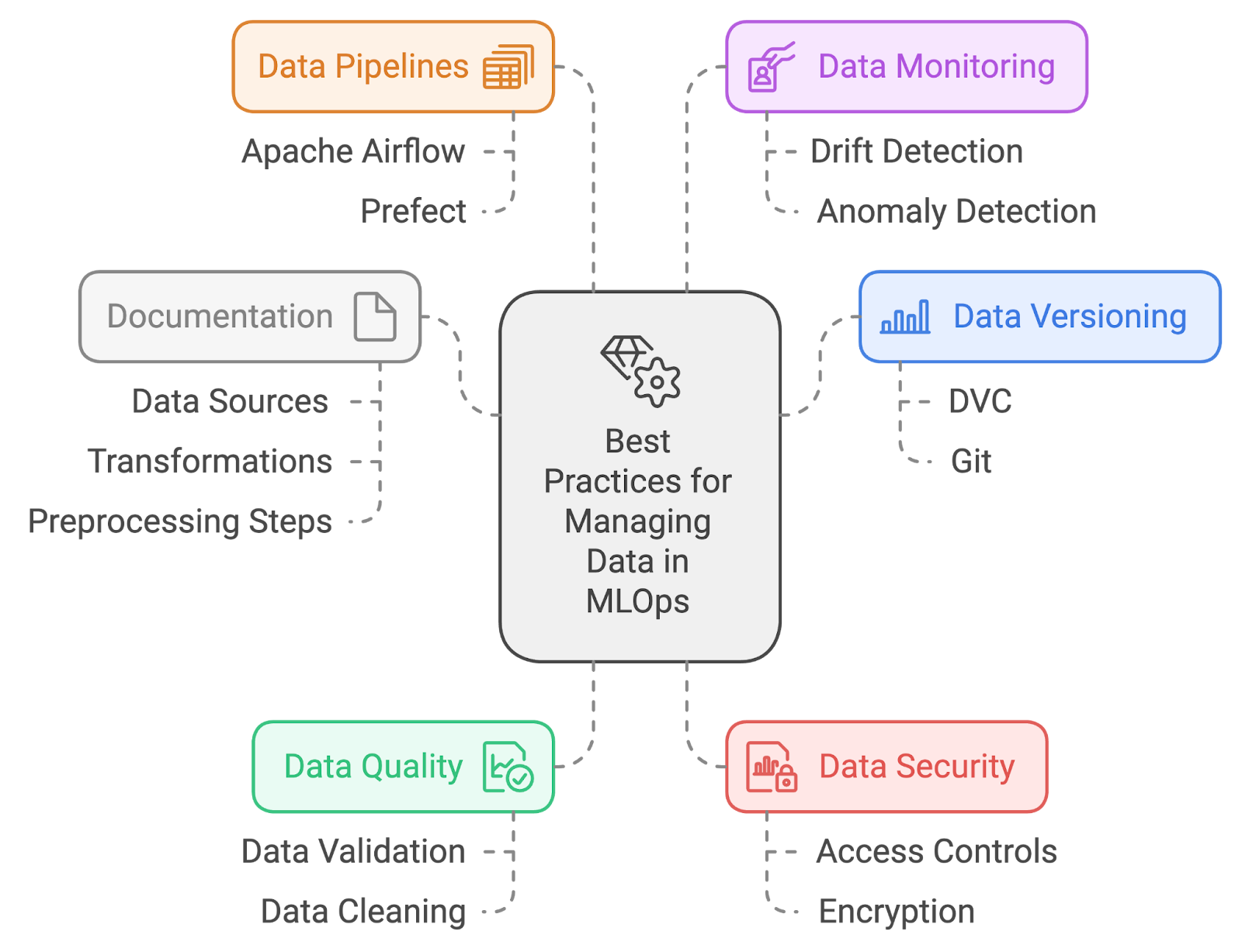
Meilleures pratiques en matière de gestion des données. Image créée par l'auteur à l'aide de napkin.ai
Description : Cette question évalue la manière dont vous intégrez ces processus dans des flux de travail automatisés.
Réponse : La gestion de l'ingénierie des caractéristiques et du prétraitement dans un pipeline MLOps implique l'automatisation de ces étapes afin de garantir la cohérence et la reproductibilité. Vous pouvez utiliser des outils tels qu'Apache Airflow ou Prefect pour créer des pipelines de données qui effectuent des tâches telles que :
Description : Cette question évalue votre compréhension de la manière dont vous pouvez suivre et garantir les performances et la fiabilité continues du modèle, y compris les outils et les stratégies que vous utiliseriez pour assurer un suivi efficace.
Réponse : La mise en œuvre de la surveillance des modèles dans un environnement de production implique plusieurs pratiques visant à garantir que le modèle fonctionne comme prévu et reste fiable au fil du temps :
Le cours sur la surveillance par apprentissage automatique devrait vous permettre de répondre à ce type de questions de manière plus détaillée.
Description : Cette question examine votre approche pour garantir que les expériences d'apprentissage automatique puissent être reproduites de manière cohérente. Il évalue votre compréhension des pratiques qui favorisent la reproductibilité.
Réponse : Garantir la reproductibilité des expériences d'apprentissage automatique implique :
Description : Cette question évalue votre compréhension des défis particuliers liés au passage des modèles d'apprentissage automatique de l'environnement de développement à l'environnement de production.
Réponse : La mise en œuvre opérationnelle des modèles d'apprentissage automatique présente plusieurs défis. L'une des principales difficultés consiste à garantir la cohérence entre les environnements de développement et de production, ce qui peut entraîner des problèmes de reproductibilité.
La dérive des données constitue un autre sujet de préoccupation, car les données en production peuvent évoluer au fil du temps, ce qui réduit la précision du modèle.
De plus, l'intégration de modèles dans des systèmes existants, la surveillance de leurs performances et l'automatisation des workflows de réentraînement sont souvent des tâches complexes qui nécessitent une collaboration efficace entre les équipes de science des données et d'ingénierie.
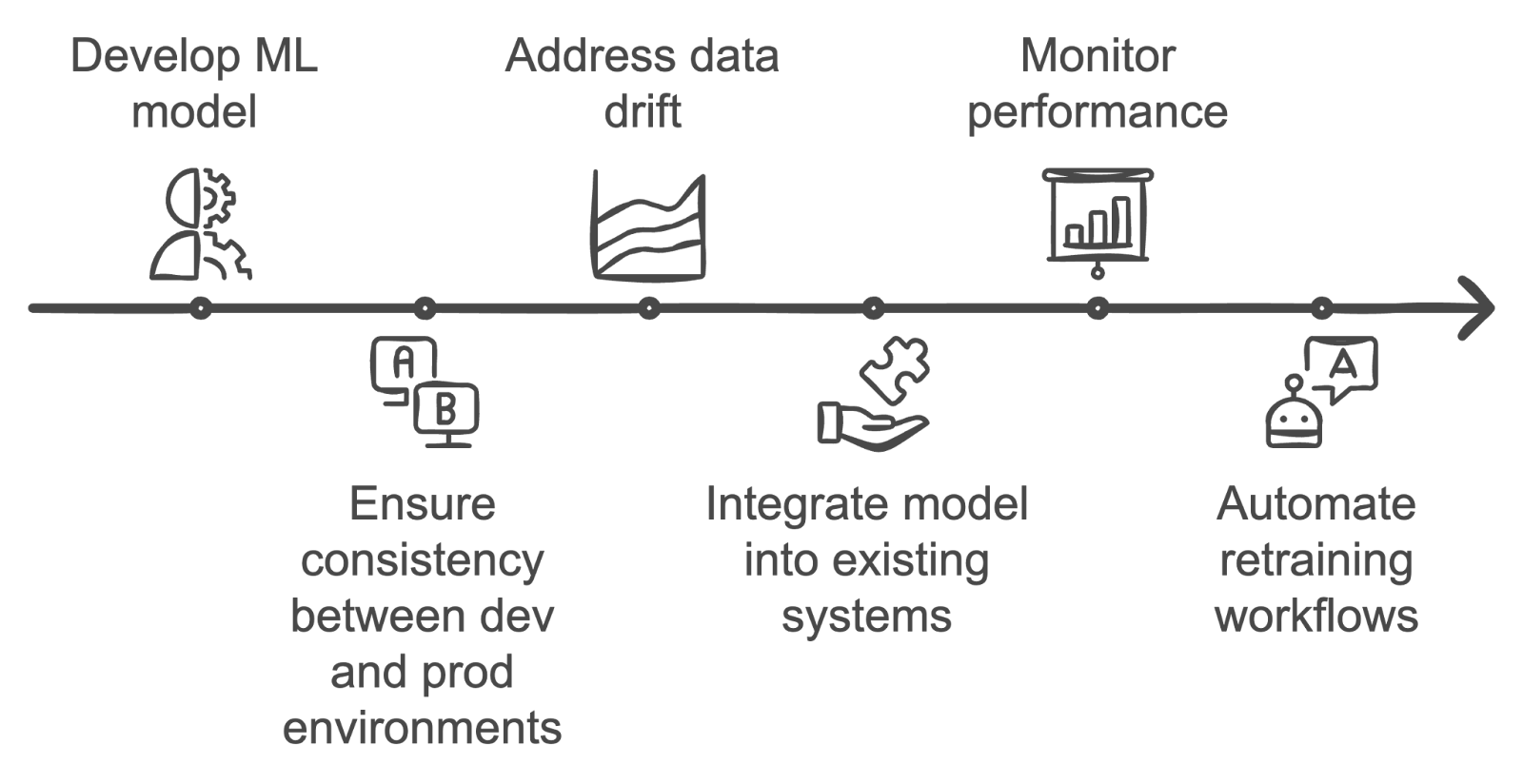
Surmonter les défis liés à la mise en œuvre des modèles d'apprentissage automatique. Image créée par l'auteur à l'aide de napkin.ai
Description : Cette question évalue votre compréhension de l'automatisation du réentraînement des modèles lorsque de nouvelles données sont disponibles ou que les performances du modèle se dégradent.
Réponse : La mise en œuvre du réentraînement automatisé des modèles implique la configuration d'un pipeline qui surveille les performances des modèles et la dérive des données. Lorsque la précision du modèle descend en dessous d'un seuil ou lorsque de nouvelles données sont disponibles, des outils tels qu'Apache Airflow ou Kubeflow peuvent déclencher un nouveau processus d'apprentissage.
Le réentraînement implique la collecte de nouvelles données, le prétraitement, l'entraînement du modèle avec les mêmes hyperparamètres ou des hyperparamètres mis à jour, et la validation du nouveau modèle. Après le réentraînement, le modèle mis à jour est automatiquement déployé en production.
Description : Cette question évalue vos connaissances en matière d'interprétabilité des modèles et la manière dont vous garantissez la transparence des prévisions des modèles.
Réponse : Des outils tels que SHAP (SHapley Additive exPlanations) ou LIME (Local Interpretable Model-agnostic Explanations) sont couramment utilisés pour expliquer les modèles.
Ces outils permettent de décomposer les prédictions du modèle en montrant la contribution de chaque caractéristique. L'explicabilité est essentielle dans le domaine du MLOps, car elle permet d'instaurer la confiance auprès des parties prenantes et de garantir la conformité des modèles avec les réglementations, en particulier dans des secteurs tels que la finance et la santé. Cela permet également d'identifier les biais potentiels ou les problèmes liés aux données au sein du modèle.
Cette section traite des questions d'entretien axées sur les aspects liés au cloud et à l'infrastructure des MLOps. Ces questions évaluent votre expertise dans le déploiement, la gestion et la mise à l'échelle de modèles d'apprentissage automatique dans des environnements cloud.
Description : Cette question évalue vos connaissances en matière de déploiement de modèles d'apprentissage automatique dans un environnement cloud. Il évalue votre compréhension des plateformes cloud, des processus de déploiement et des outils utilisés pour gérer les modèles dans le cloud.
Réponse : Le déploiement de modèles ML sur le cloud implique les étapes suivantes :
Description : Cette question examine la compréhension du calcul sans serveur et son application dans le déploiement de modèles d'apprentissage automatique, en évaluant la capacité à mettre en balance les avantages et les défis.
Réponse : Les architectures sans serveur offrent plusieurs avantages, notamment une réduction des frais généraux opérationnels, car elles ne nécessitent aucune gestion de serveur, et une mise à l'échelle automatique en fonction de la demande en temps réel, ce qui peut entraîner des économies, les frais étant basés sur l'utilisation réelle des ressources informatiques.
Cependant, les architectures sans serveur présentent également des défis. Par exemple, il existe des contraintes en matière de temps d'exécution et d'allocation des ressources qui peuvent ne pas convenir à tous les types de modèles d'apprentissage automatique, en particulier ceux qui ont des besoins informatiques élevés.
La latence au démarrage à froid peut également constituer un problème, les requêtes initiales après des périodes d'inactivité pouvant subir des retards. Malgré ces défis, les architectures sans serveur peuvent être très efficaces pour certaines charges de travail si ces facteurs sont gérés de manière appropriée.
Une autre manière d'appréhender cela est de consulter ce tableau qui résume les avantages et les inconvénients des architectures sans serveur en fonction d'aspects spécifiques :
|
Aspect |
Avantages du sans serveur |
Inconvénients du sans serveur |
|
Frais généraux opérationnels |
Aucune gestion de serveur n'est nécessaire ; complexité réduite de l'infrastructure. |
Nécessite une connaissance des plateformes cloud pour gérer des environnements sans serveur. |
|
Mise à l'échelle |
La mise à l'échelle automatique est basée sur la demande en temps réel, ce qui permet de réaliser des économies. |
Peut être imprévisible pour la budgétisation si les ajustements sont fréquents. |
|
Rentabilité |
Ne payez que pour les ressources utilisées, ce qui peut réduire les coûts. |
Peut s'avérer coûteux si de nombreuses fonctions sont invoquées fréquemment ou pendant de longues durées. |
|
Limites d'exécution |
Convient pour les tâches légères ou de courte durée. |
En raison des contraintes liées au temps d'exécution et à l'allocation des ressources, il est possible que les modèles ML gourmands en ressources ne soient pas pris en charge. |
|
Démarrage à froid |
Réduit les frais généraux opérationnels grâce à une évolutivité à la demande. |
Des retards au démarrage à froid peuvent survenir après des périodes d'inactivité, ce qui peut affecter les applications sensibles à la latence. |
|
Pertinence du modèle ML |
Convient parfaitement aux tâches de ML à petite échelle, à l'inférence ou au traitement par lots. |
Les modèles ML à forte intensité de calcul avec des tâches de longue durée ne sont pas adaptés. |
Description : Cette question évalue vos stratégies d'optimisation et de gestion des ressources informatiques lors de l'entraînement de modèles ML dans le cloud. Il évalue votre capacité à garantir une utilisation efficace des ressources cloud.
Réponse : La gestion des ressources informatiques implique :
Description : Cette question examine l'approche adoptée pour garantir la sécurité et la conformité des données lors du déploiement de modèles d'apprentissage automatique dans des environnements cloud, en mettant l'accent sur les meilleures pratiques et les exigences réglementaires.
Réponse : Garantir la sécurité et la conformité des données implique :
La sécurité et la conformité peuvent être les derniers aspects auxquels un ingénieur souhaite réfléchir, mais ils revêtent une importance croissante. Le cours Comprendre le RGPD, ainsi que les autres cours suggérés dans cet article, devraient vous permettre de vous mettre à niveau.
Description : Cette question examine les stratégies de gestion et d'optimisation des coûts liés au cloud pour la formation et le déploiement de modèles d'apprentissage automatique, évaluant ainsi les connaissances en matière de techniques de gestion des coûts.
Réponse : Les stratégies de gestion des coûts du cloud comprennent :
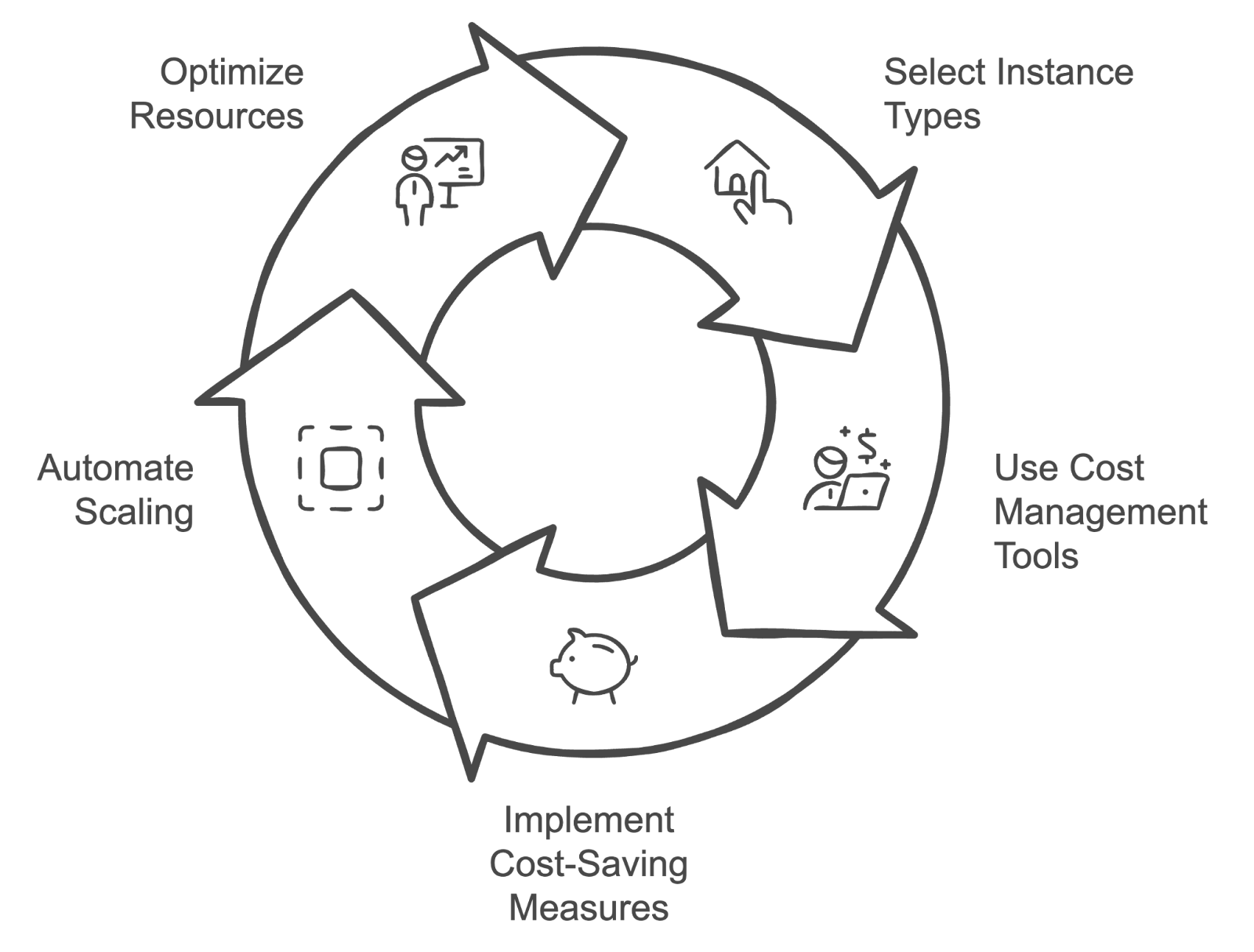
Cycle de gestion des coûts du cloud. Image créée par l'auteur à l'aide de napkin.ai
Description : Cette question évalue votre compréhension des compromis entre le déploiement de modèles sur des appareils périphériques et dans le cloud.
Réponse : Le déploiement dans le cloud implique l'exécution de modèles sur des serveurs centralisés, offrant une évolutivité et une maintenance plus facile, mais avec des problèmes de latence potentiels.
Le déploiement en périphérie consiste à exécuter des modèles directement sur des appareils tels que des smartphones ou des appareils IoT, ce qui réduit la latence et améliore la confidentialité des données, mais peut être limité par les ressources informatiques. Le déploiement en périphérie est idéal pour les applications de traitement en temps réel, tandis que le déploiement dans le cloud convient mieux aux modèles nécessitant une puissance de calcul et une flexibilité importantes.
Description : Cette question évalue vos connaissances en matière de création de systèmes résilients pour le déploiement de modèles d'apprentissage automatique.
Réponse : Pour garantir une haute disponibilité, il est nécessaire de déployer des modèles dans plusieurs zones ou régions de disponibilité et de mettre en place des mécanismes de basculement automatisés.
Les équilibreurs de charge peuvent répartir le trafic afin d'éviter les goulots d'étranglement. En matière de tolérance aux pannes, des sauvegardes régulières, une redondance et des contrôles de santé peuvent prévenir les défaillances du système. L'utilisation de services cloud tels que AWS Elastic Load Balancing et les fonctionnalités d'autoscaling permet également de garantir que, en cas de défaillance d'une instance, d'autres peuvent prendre le relais sans interruption de service.
Cette section explore les aspects comportementaux et liés à la résolution de problèmes du MLOps, en évaluant la manière dont les candidats abordent les défis du monde réel, collaborent avec les équipes et gèrent divers problèmes liés au déploiement et à la gestion des modèles d'apprentissage automatique.
Description : Cette question évalue les compétences en matière de résolution de problèmes dans des scénarios réels.
Exemple de réponse : Il est arrivé qu'un modèle déployé en production commence à présenter une baisse significative de ses performances. La première étape consistait à analyser les journaux et les métriques du modèle afin d'identifier toute anomalie. Il est apparu que le pipeline de données alimentait des données dont la structure avait été modifiée en raison de récentes mises à jour dans les systèmes sources.
L'étape suivante consistait à valider les données par rapport aux données attendues par le modèle et à vérifier s'il existait des divergences. Après avoir confirmé le problème lié aux données, j'ai collaboré avec l'équipe d'ingénierie des données afin de rectifier le pipeline de données. Ensuite, j'ai déployé un correctif pour mettre à jour le modèle avec la gestion corrigée des entrées.
Enfin, j'ai surveillé de près le modèle après son déploiement afin de m'assurer que ses performances revenaient aux niveaux attendus, puis j'ai communiqué les conclusions et la résolution aux parties prenantes.
Description : Cette question évalue votre approche de la gestion des différentes versions des modèles d'apprentissage automatique lorsque vous travaillez en équipe.
Exemple de réponse : , j'utilise des systèmes de contrôle de version tels que MLflow ou DVC pour gérer et suivre les différentes versions des modèles. Chaque version se voit attribuer un identifiant unique, et une documentation détaillée est fournie pour chaque mise à jour afin de garantir que les membres de l'équipe comprennent les modifications apportées.
De plus, je m'assure que les nouveaux modèles sont minutieusement testés dans un environnement de préproduction avant d'être déployés en production, ce qui contribue à éviter les perturbations et à maintenir les performances des modèles.
Description : Cette question évalue votre capacité à collaborer efficacement avec différentes équipes, telles que les scientifiques de données, les ingénieurs et les chefs de produit, ainsi que votre aptitude à gérer et à résoudre les défis dans un environnement interfonctionnel.
Exemple de réponse : Une situation complexe a nécessité la coordination entre des scientifiques des données, des ingénieurs et des chefs de produit afin de déployer un nouveau modèle présentant des dépendances complexes. La clé d'une collaboration efficace était d'établir dès le départ des canaux de communication clairs.
Des réunions régulières ont été organisées afin de s'accorder sur les objectifs, de suivre le cursus et de surmonter les obstacles éventuels. Afin de combler les lacunes en matière de connaissances, j'ai organisé des séances de partage des connaissances au cours desquelles les membres de l'équipe ont pu discuter de leurs domaines d'expertise respectifs.
De plus, l'utilisation d'outils de gestion de projet pour suivre les tâches et les étapes importantes a permis à tous les participants de rester informés de l'avancement du projet. Cette approche a permis de garantir que la contribution de chaque membre de l'équipe soit prise en compte et que nous travaillions ensemble pour assurer le succès du déploiement.
Description : Cette question examine vos stratégies pour adapter les modèles d'apprentissage automatique à la demande croissante, en évaluant votre compréhension des aspects techniques et opérationnels de l'évolutivité.
Exemple de réponse : L'adaptation des modèles d'apprentissage automatique pour gérer une charge utilisateur accrue implique plusieurs étapes essentielles.
Tout d'abord, j'analyserais les indicateurs de performance du modèle actuel afin d'identifier les éventuels goulots d'étranglement. Pour répondre à l'augmentation de la demande, je mettrais à profit des solutions d'auto-scaling basées sur le cloud afin d'ajuster les ressources de manière dynamique en fonction du trafic.
De plus, l'optimisation du modèle lui-même grâce à des techniques telles que la quantification ou l'élagage peut contribuer à réduire sa consommation de ressources sans compromettre ses performances.
Je mettrais également en œuvre des tests de charge afin de simuler un trafic plus important et de garantir la robustesse du système.
Enfin, je mettrais en place un suivi continu afin de rester informé des performances des modèles, ce qui me permettrait d'ajuster l'allocation des ressources selon les besoins et de maintenir les performances sous des charges variables.
Description : Cette question évalue votre capacité à gérer la communication et les attentes lorsqu'un modèle ne produit pas les résultats escomptés.
Exemple de réponse : Lorsque les performances du modèle ne répondent pas aux attentes, je privilégie une communication transparente avec les parties prenantes. Je présente les limites du modèle et les raisons de ses performances, qu'elles soient liées à des problèmes de qualité des données, à un surajustement ou à des attentes initiales irréalistes.
Je collabore ensuite avec eux pour définir des objectifs plus réalistes, fournir des informations basées sur des données et proposer des améliorations, telles que la collecte de davantage de données d'entraînement ou l'ajustement de l'architecture du modèle.
Description : Cette question évalue votre capacité à établir des priorités entre le maintien de la qualité du code à long terme et le respect des délais à court terme des projets.
Exemple de réponse : Il y a eu une période où nous avions un délai très court pour déployer un modèle pour une nouvelle fonctionnalité de produit. Nous avons donné la priorité à une livraison rapide en omettant certaines parties non essentielles du code, telles que la documentation complète et les tests non indispensables.
Après la sortie, nous avons consacré du temps à revoir le code source et à résoudre ces problèmes, afin de minimiser la dette technique après le lancement. Cela nous a permis de respecter les délais tout en garantissant la stabilité à long terme du projet.
La préparation à un entretien MLOps implique une combinaison de connaissances techniques, une bonne compréhension de l'environnement de l'entreprise et une communication claire de vos expériences passées. Voici quelques conseils essentiels pour vous aider à vous préparer :
Veuillez vous assurer de bien maîtriser les concepts fondamentaux du MLOps. Veuillez vous familiariser avec les outils et plateformes couramment utilisés dans le domaine du MLOps, tels que MLflow, Kubernetes et les services cloud comme AWS SageMaker ou Google AI Platform.
Le cursus de compétences MLOps constitue une ressource idéale, car il comprend quatre cours pertinents qui vous permettent de vous tenir informé des concepts et des pratiques MLOps.
Veuillez vous renseigner sur les technologies et les outils spécifiques utilisés par l'entreprise dans laquelle vous postulez. Comprendre leur infrastructure technologique vous aidera à adapter vos réponses à leur environnement et à démontrer que vous correspondez parfaitement au profil recherché. Veuillez examiner leurs services cloud préférés, leurs systèmes de contrôle de version et leurs pratiques de gestion des modèles afin de démontrer que vous êtes prêt à vous intégrer de manière transparente dans leur flux de travail.
Soyez prêt à discuter de projets ou d'expériences spécifiques dans lesquels vous avez appliqué les pratiques MLOps. Veuillez préparer des exemples qui mettent en évidence vos compétences en matière de résolution de problèmes, votre capacité à travailler avec des équipes interfonctionnelles et votre expérience en matière de déploiement et de mise à l'échelle de modèles (si possible). Veuillez utiliser ces exemples pour illustrer vos connaissances pratiques et la manière dont vous avez relevé avec succès les défis rencontrés dans vos fonctions précédentes.
Pratiquez régulièrement des exercices de codage liés au MLOps, tels que la rédaction de scripts pour le déploiement de modèles, l'automatisation de workflows ou le développement de pipelines de données.
Le domaine du MLOps évolue rapidement, il est donc essentiel de se tenir informé des dernières tendances, des nouveaux outils et des meilleures pratiques. Suivez les blogs spécialisés, participez à des forums ou à des webinaires pertinents et engagez-vous auprès de la communauté MLOps afin de maintenir vos connaissances à jour et pertinentes.
Le MLOps est un domaine qui comble le fossé entre la science des données et les opérations, en garantissant que les modèles d'apprentissage automatique sont déployés, maintenus et adaptés de manière efficace.
Tout au long de cet article, nous avons abordé une série de questions d'entretien couvrant les concepts généraux du MLOps, les aspects techniques, les considérations relatives au cloud et à l'infrastructure, ainsi que les compétences comportementales en matière de résolution de problèmes. En vous entraînant à répondre à ces questions, vous augmenterez considérablement vos chances de réussite lors de vos entretiens et vous aurez plus de possibilités d'obtenir le poste.
Veuillez consulter les ressources suivantes pour approfondir vos connaissances :
Veuillez approfondir vos connaissances sur le MLOps grâce à ces cours.
Cours
Cours
Cours