
Kurs
MLOps-Konzepte
2 Std.
42.6K
Machine Learning Operations (MLOps) hat sich zu einem der angesagtesten Bereiche in der Tech-Branche entwickelt. Da Datenteams immer öfter Machine-Learning-Modelle in Produktionsumgebungen einsetzen, wird der Bedarf an MLOps-Fachkräften weiter steigen.
Wenn du eine Karriere als MLOps-Ingenieur anstrebst, helfen wir dir gerne dabei, diesen Sprung zu schaffen!
In diesem Artikel zeigen wir dir die wichtigsten MLOps-Interviewfragen mit ausführlichen Erklärungen und Antworten, damit du dich gut auf dein bevorstehendes Vorstellungsgespräch vorbereiten kannst.
MLOps, kurz für Machine Learning Operations, ist ein Bereich, der maschinelles Lernen mit DevOps-Praktiken kombiniert, um den Lebenszyklus von Modellen für maschinelles Lernen zu optimieren und zu automatisieren.
Das Hauptziel von MLOps ist es, die Lücke zwischen Datenwissenschaft und IT-Betrieb zu schließen und sicherzustellen, dass Machine-Learning-Modelle effektiv entwickelt, effizient in Produktionsumgebungen eingesetzt, überwacht und gewartet werden.
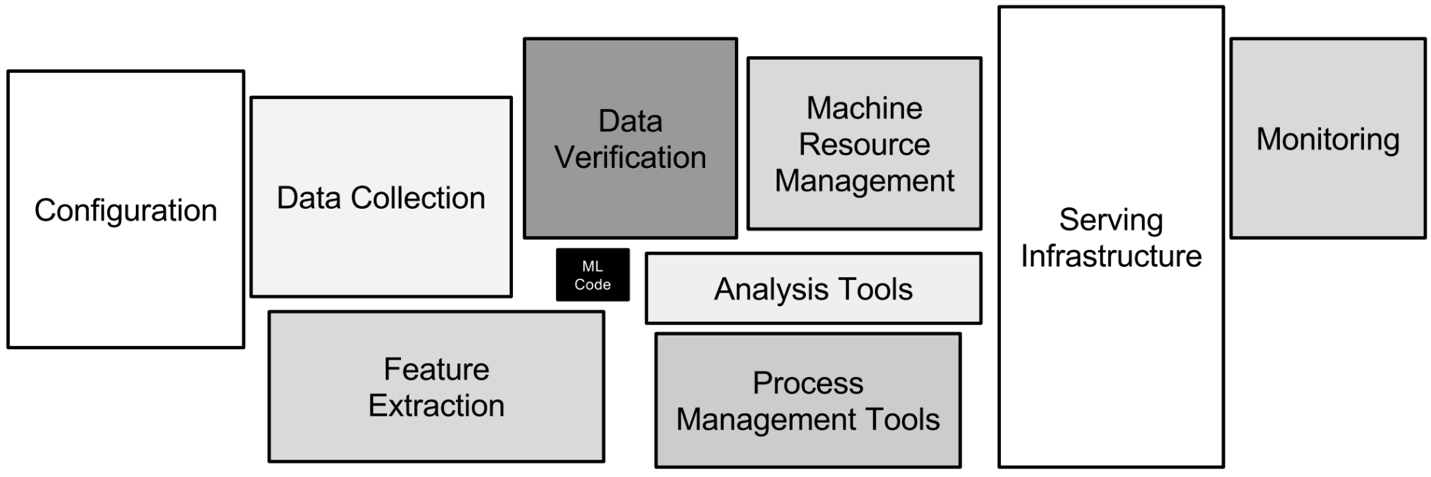
Die verschiedenen technischen Aspekte von MLOps. Bild vom Autor
Diese Aufgabe ist wichtig, weil sie es den Datenteams ermöglicht, Machine-Learning-Modelle in Produktionsumgebungen einzusetzen und gleichzeitig sicherzustellen, dass sie effektiv skaliert und gewartet werden können. Im Grunde genommen beschleunigt MLOps Innovationen, macht den Betrieb effizienter und hilft Firmen, das volle Potenzial ihrer datengesteuerten Initiativen auszuschöpfen.
Die für MLOps benötigten Fähigkeiten umfassen:
Ja, ein MLOps-Ingenieur ist wie ein Einhorn! Und genau deshalb sind sie so gefragt und kriegen immer höhere Gehälter.
In diesem Abschnitt schauen wir uns grundlegende MLOps-Interviewfragen an, die dein Verständnis der Kernkonzepte und -prinzipien testen. Diese Fragen sollen dein Wissen über die grundlegenden Aufgaben und Herausforderungen von MLOps und deine Fähigkeit, dein Wissen effektiv zu vermitteln, testen.
Mach dich mit diesen Fragen vertraut, um eine solide Grundlage für fortgeschrittenere Themen zu schaffen und deine Kompetenz in diesem Bereich zu zeigen.
Beschreibung: Diese Frage testet dein Verständnis der grundlegenden Unterschiede zwischen MLOps und DevOps, die oft verwechselt werden.
Antwort: MLOps und DevOps sind beide Strategien, bei denen Zusammenarbeit im Mittelpunkt steht, aber sie haben unterschiedliche Ziele. DevOps dreht sich um die Automatisierung der Entwicklung, des Testens und der Bereitstellung von Softwareanwendungen und standardisiert Umgebungen, um diese Prozesse zu optimieren.
Im Gegensatz dazu ist MLOps auf Machine-Learning-Workflows zugeschnitten und legt den Fokus auf die Verwaltung und Wartung von Datenpipelines und Modellen. Während DevOps darauf abzielt, Routineaufgaben zu automatisieren und die Anwendungsbereitstellung zu standardisieren, befasst sich MLOps mit dem experimentellen Charakter des maschinellen Lernens, einschließlich Aufgaben wie Datenvalidierung, Bewertung der Modellqualität und fortlaufende Modellvalidierung.
DevOps und MLOps vergleichen und gegenüberstellen. Bild vom Autor mit napkin.ai erstellt
Beschreibung: Diese Interviewfrage checkt, wie gut du weißt, wie sich Datenänderungen auf die Genauigkeit von Modellen auswirken und wie wichtig es ist, Modelle zu überwachen und zu aktualisieren.
Antwort: Modelldrift und Konzeptdrift sind Veränderungen in der Leistung von Modellen für maschinelles Lernen, die im Laufe der Zeit durch sich verändernde Datenmuster und zugrunde liegende Beziehungen entstehen:
Beschreibung: Diese Interviewfrage checkt, wie gut du dich mit Testverfahren auskennst, um sicherzustellen, dass ein Machine-Learning-Modell zuverlässig ist und gut funktioniert, bevor es in einer Produktionsumgebung eingesetzt wird.
Antwort: Bevor ein ML-Modell in der Produktion eingesetzt wird, muss man verschiedene Tests machen. Diese Tabelle gibt einen guten Überblick über die verschiedenen Testarten, ihre Ziele ( ), die verwendeten Tools und wann sie im Entwicklungszyklus des maschinellen Lernens eingesetzt werden sollten:
|
Testtyp |
Ziel |
Verwendete Tools |
Wann man es benutzt |
|
Komponententests |
Überprüfe einzelne Modellkomponenten, wie Vorverarbeitungsschritte und Merkmalsextraktionsfunktionen. |
PyTest, unittest, scikit-learn (für Transformationen) |
Während der Entwicklung, wenn du Modellkomponenten einsetzt oder aktualisierst. |
|
Integrationstests |
Stell sicher, dass das Modell in der Produktionsumgebung richtig mit anderen Systemkomponenten und Datenquellen zusammenarbeitet. |
Docker, Kubernetes, Jenkins, Apache Kafka |
Nach dem Unit-Testing, wenn das Modell in einer produktionsähnlichen Umgebung eingesetzt wird. |
|
Leistungstests |
Schau dir die Genauigkeit, Präzision, den Recall und andere wichtige Kennzahlen des Modells mit einem Validierungsdatensatz an. |
Scikit-learn, TensorFlow, PyTorch, MLflow |
Nach den Integrationstests, um sicherzustellen, dass das Modell die erwarteten Leistungsstandards erfüllt. |
|
Stresstest |
Schau mal, wie das Modell mit hohen Lasten und großen Datenmengen klarkommt, um die Skalierbarkeit sicherzustellen. |
Apache JMeter, Locust, Dask |
Bevor du in Umgebungen mit viel Datenvolumen einsetzt oder wenn Skalierbarkeit wichtig ist. |
|
A/B-Test |
Vergleiche die Leistung des Modells mit bestehenden Modellen oder Basiswerten in einer Live-Umgebung. |
Optimizely, SciPy, Google Optimize |
Nach der Bereitstellung, wenn du die Leistung des Modells in der Produktion checkst und die Modellversionen optimierst. |
|
Robustheitstest |
Stell sicher, dass das Modell robust gegenüber Datenanomalien und Randfällen ist. |
Bibliotheken für Robustheit gegenüber Angriffen (z. B. CleverHans), benutzerdefinierte Skripte |
Nach den Leistungstests, um die Zuverlässigkeit unter ungewöhnlichen oder unerwarteten Bedingungen zu checken. |
Beschreibung: Diese Interviewfrage checkt, wie gut du die Rolle und Bedeutung der Versionskontrolle in MLOps-Praktiken verstehst. Es geht darum, wie das Verwalten verschiedener Versionen von Modellen, Daten und Code zu einer effektiven Modellbereitstellung und -wartung beiträgt.
Antwort: Versionskontrolle ist in MLOps echt wichtig, weil sie dabei hilft, Änderungen an Machine-Learning-Modellen, Datensätzen und Code während ihres ganzen Lebenszyklus zu verwalten und zu verfolgen. Mit Versionskontrollsystemen wie Git für Code und Tools wie DVC (Data Version Control) für Datensätze und Modelle kann man sicherstellen, dass alle Änderungen dokumentiert und rückgängig gemacht werden können.
Diese Vorgehensweise hilft dabei, Ergebnisse wiederholbar zu machen, erleichtert die Zusammenarbeit im Team und macht es einfacher, bei Problemen auf frühere Versionen zurückzugreifen. Es sorgt für Konsistenz und Zuverlässigkeit bei der Modellleistung, was wichtig ist, um hochwertige Bereitstellungen zu gewährleisten.
Wenn du mehr über dieses Konzept wissen willst, schau dir den vollständigen Leitfaden zur Datenversionskontrolle (DVC) an. Es bereitet dich auf solche Fragen während deines Vorstellungsgesprächs vor!
Beschreibung: Diese Interviewfrage soll dein Wissen über verschiedene Methoden zum Verpacken von Machine-Learning-Modellen für den Einsatz checken. Es testet dein Verständnis dafür, wie man Modelle für die Integration in verschiedene Umgebungen und Anwendungen vorbereitet.
Antwort: Es gibt ein paar coole Möglichkeiten, Machine-Learning-Modelle zu packen:
Eine super Möglichkeit, mehr über Verpackungsmodelle zu erfahren, ist, sich mit Containerisierung zu beschäftigen. Docker ist ein wichtiges Tool, das jeder MLOps-Ingenieur kennen sollte. Um dein Wissen aufzufrischen, schau dir den Kurs „Einführung in Docker“ an.
Beschreibung: Diese Frage checkt, wie gut du dich mit Überwachungsmodellen in der Produktion auskennst und welche Metriken wichtig sind, um die Leistung und Zuverlässigkeit aufrechtzuerhalten.
Antwort: Überwachung ist bei MLOps super wichtig, damit die Modelle in der Produktion so laufen, wie man es erwartet. Zu den zu verfolgenden Kennzahlen gehören Genauigkeit, Präzision, Wiederauffindbarkeit und andere Leistungsindikatoren, um eine Verschlechterung des Modells zu erkennen.
Die Überwachung auf Datenabweichungen ist auch wichtig, weil Änderungen in den Datenmustern die Vorhersagen des Modells beeinflussen können. Außerdem helfen Infrastrukturkennzahlen wie Latenz und Ressourcennutzung (z. B. CPU, Speicher) dabei, dass das System skalierbar und reaktionsschnell bleibt.
Beschreibung: Diese Interviewfrage checkt, ob du potenzielle Hindernisse verstehst und wie man sie angeht, um eine erfolgreiche Modellimplementierung sicherzustellen.
Antwort: Häufige Probleme bei der Bereitstellung von ML-Modellen sind:
Alle Arbeitgeber suchen nach Leuten, die Probleme lösen können, vor allem wenn es um den Umgang mit Daten in einer Position wie MLOps geht. Um dich mit zwei super wichtigen Themen im Zeitalter des maschinellen Lernens vertraut zu machen, schau dir die Kurse „Einführung in die Datenqualität“ und „Einführung in die Datensicherheit“ an.
Beschreibung: Diese Interviewfrage checkt, ob du zwischen Canary- und Blue-Green-Bereitstellungsmethoden unterscheiden kannst und welche Vorteile sie für die Einführung neuer Änderungen haben.
Antwort: Canary- und Blue-Green-Bereitstellungsstrategien werden beide benutzt, um die Einführung von Updates zu verwalten, aber sie haben unterschiedliche Ansätze:
Beide Strategien wollen die Risiken bei der Bereitstellung und Ausfallzeiten reduzieren, aber Canary-Bereitstellungen konzentrieren sich auf inkrementelle Releases und schrittweise Freigabe, während Blue-Green-Bereitstellungen für einen nahtlosen Wechsel zwischen den Umgebungen sorgen.
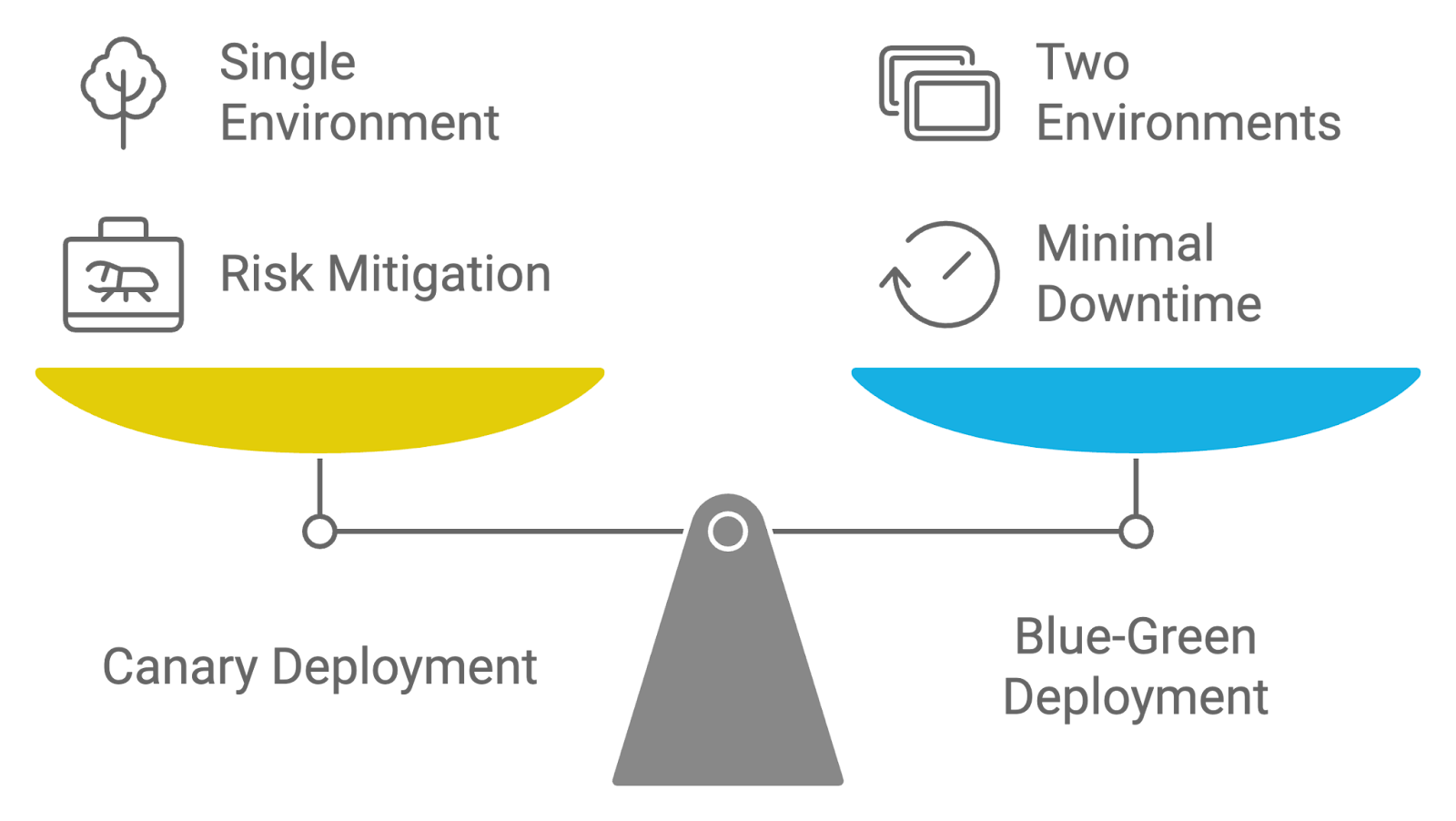
Vergleich von Bereitstellungsstrategien: Kanarienvogel gegen Blau-Grün. Bild vom Autor mit napkin.ai erstellt
Beschreibung: Diese Frage testet dein Wissen über die Strategien und Tools, die verwendet werden, um die Umschulung von Modellen für maschinelles Lernen zu automatisieren, wenn neue Daten verfügbar werden.
Antwort: Um das erneute Trainieren von Modellen in MLOps zu automatisieren, muss man eine Pipeline einrichten, die das erneute Trainieren startet, wenn bestimmte Bedingungen erfüllt sind, wie zum Beispiel eine Leistungsverschlechterung oder wenn neue Daten da sind.
Tools wie Airflow oder Kubeflow können diese Abläufe organisieren und Aufgaben wie Datenerfassung, Feature Engineering, Modelltraining und Bewertung automatisch erledigen. Eine ständige Überwachung ist wichtig, um sicherzustellen, dass das Modell vor dem Einsatz die Leistungsschwellenwerte erfüllt. Versionierungstools wie DVC helfen dabei, verschiedene Modellversionen während des erneuten Trainings zu verfolgen.
In diesem Abschnitt schauen wir uns technische MLOps-Interviewfragen an, die deine praktischen Fähigkeiten und dein Verständnis für fortgeschrittene Konzepte testen.
Diese Fragen drehen sich um die technischen Aspekte beim Einsatz, der Verwaltung und Optimierung von Modellen für maschinelles Lernen und sollen zeigen, wie gut du mit den Tools, Techniken und Best Practices in diesem Bereich klarkommst.
Beschreibung: Diese Frage testet dein Wissen über das Einrichten von CI/CD-Pipelines speziell für Machine-Learning-Workflows. Es checkt, wie gut du den Bereitstellungsprozess automatisieren und Modellaktualisierungen effizient verwalten kannst.
Antwort: Um CI/CD für Machine-Learning-Modelle einzusetzen, muss man Pipelines einrichten, die den Prozess von Codeänderungen bis zur Bereitstellung automatisch abwickeln.
Du kannst zum Beispiel Jenkins oder GitHub Actions nutzen, um Builds und Tests zu starten, wenn sich was am Modellcode oder an den Daten ändert. Die Pipeline umfasst Phasen wie:
Durch die Automatisierung dieser Schritte stellst du sicher, dass die Modelle mit minimalem manuellem Aufwand konsistent und zuverlässig aktualisiert werden.
Wenn du deine CI/CD-Kenntnisse verbessern willst, mach den Kurs „CI/CD für maschinelles Lernen”. Damit wirst du im Vorstellungsgespräch glänzen!
Beschreibung: Diese Interviewfrage dreht sich um dein Verständnis von effektiven Datenmanagementpraktiken innerhalb von MLOps. Es checkt, wie gut du mit Datenqualität, Versionierung und Organisation klarkommst, um robuste und zuverlässige Machine-Learning-Workflows zu unterstützen.
Antwort: Zu den besten Methoden für die Datenverwaltung in MLOps gehören:
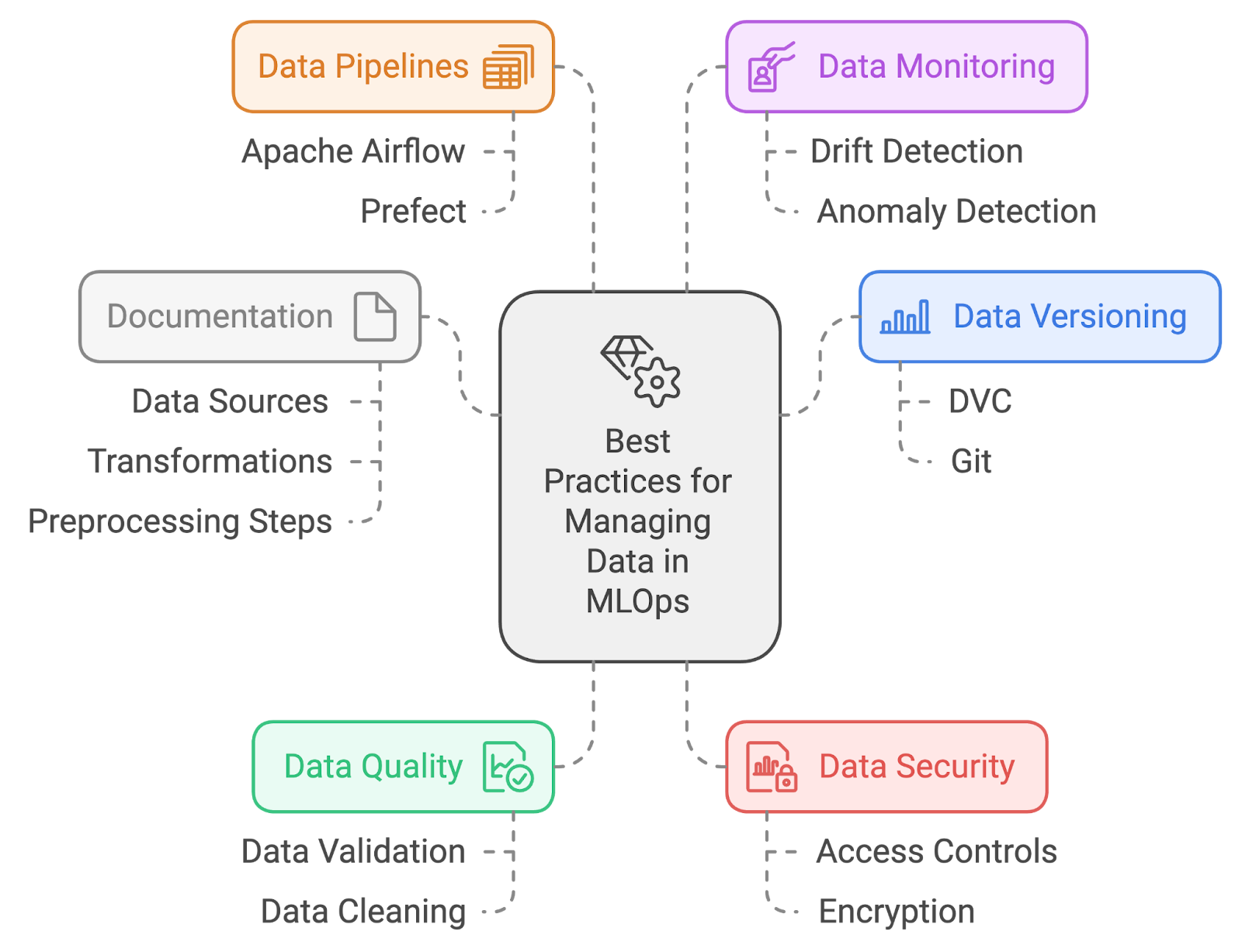
Die besten Methoden für die Datenverwaltung. Bild vom Autor mit napkin.ai erstellt
Beschreibung: Diese Frage schaut, wie du diese Prozesse in automatisierte Arbeitsabläufe einbaust.
Antwort: Bei der Feature-Engineering und Vorverarbeitung in einer MLOps-Pipeline geht's darum, diese Schritte zu automatisieren, damit alles konsistent und reproduzierbar bleibt. Du kannst Tools wie Apache Airflow oder Prefect nutzen, um Datenpipelines zu erstellen, die Aufgaben wie die folgenden erledigen:
Beschreibung: Diese Frage checkt, wie gut du verstehst, wie man die Leistung und Zuverlässigkeit des Modells im Auge behält und sicherstellt, einschließlich der Tools und Strategien, die du für eine effektive Überwachung einsetzen würdest.
Antwort: Um die Modellüberwachung in einer Produktionsumgebung einzurichten, braucht man ein paar Vorgehensweisen, damit das Modell wie erwartet funktioniert und auch später zuverlässig bleibt:
Der Kurs „Machine Learning Monitoring“ hilft dir dabei, solche Fragen genauer zu beantworten!
Beschreibung: Diese Frage geht darum, wie du sicherstellst, dass Experimente im Bereich maschinelles Lernen immer wieder gleich reproduziert werden können. Es checkt, wie gut du die Praktiken verstehst, die die Reproduzierbarkeit unterstützen.
Antwort: Die Reproduzierbarkeit von Machine-Learning-Experimenten sicherzustellen, bedeutet:
Beschreibung: Diese Frage checkt, wie gut du die besonderen Herausforderungen verstehst, die damit verbunden sind, wenn man Machine-Learning-Modelle von der Entwicklung in Produktionsumgebungen bringt.
Antwort: Die Umsetzung von Modellen für maschinelles Lernen bringt ein paar Herausforderungen mit sich. Eine der größten Herausforderungen ist es, die Konsistenz zwischen Entwicklungs- und Produktionsumgebungen sicherzustellen, was zu Problemen bei der Reproduzierbarkeit führen kann.
Ein weiteres Problem ist die Datenverschiebung, weil sich die Daten im Produktionsprozess mit der Zeit ändern können, was die Genauigkeit des Modells beeinträchtigt.
Außerdem ist es oft ziemlich kompliziert, Modelle in bestehende Systeme einzubauen, ihre Leistung zu checken und die Nachschulungsprozesse zu automatisieren. Das erfordert eine gute Zusammenarbeit zwischen den Teams für Datenwissenschaft und Technik.
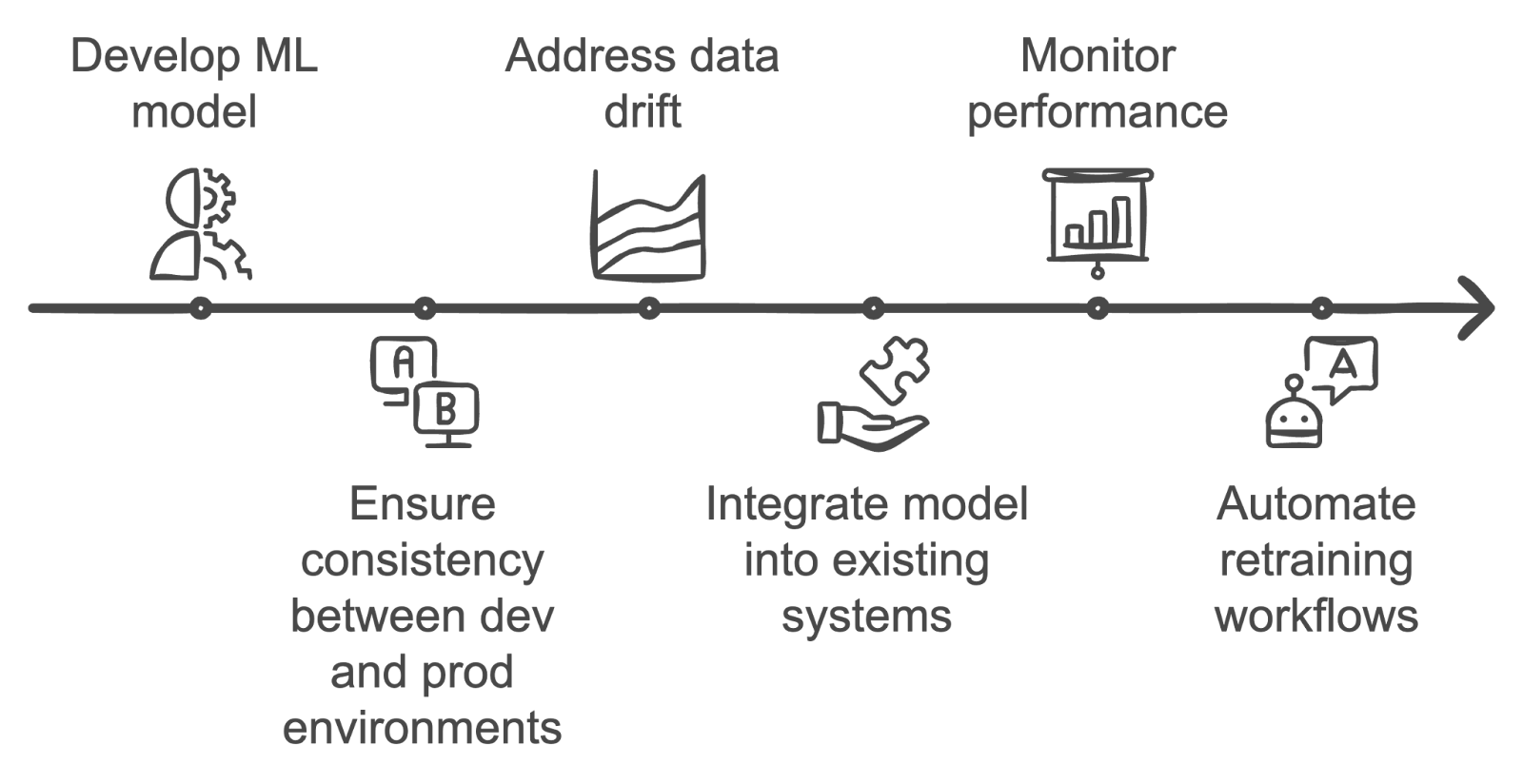
Herausforderungen bei der Umsetzung von ML-Modellen meistern. Bild vom Autor mit napkin.ai erstellt
Beschreibung: Diese Frage checkt, wie gut du verstehst, wie man das erneute Trainieren von Modellen automatisiert, wenn neue Daten da sind oder die Leistung des Modells nachlässt.
Antwort: Um automatisiertes Modell-Retraining einzurichten, muss man eine Pipeline aufbauen, die die Modellleistung und Datenabweichungen im Auge behält. Wenn die Genauigkeit des Modells unter einen Schwellenwert fällt oder neue Daten da sind, können Tools wie Apache Airflow oder Kubeflow ein erneutes Training starten.
Beim Retraining werden neue Daten geholt, vorverarbeitet, das Modell mit denselben oder aktualisierten Hyperparametern trainiert und das neue Modell validiert. Nach dem erneuten Training wird das aktualisierte Modell automatisch in der Produktion eingesetzt.
Beschreibung: Diese Frage testet dein Wissen über die Interpretierbarkeit von Modellen und wie du Transparenz bei Modellvorhersagen sicherstellst.
Antwort: Tools wie SHAP (SHapley Additive exPlanations) oder LIME (Local Interpretable Model-agnostic Explanations) sind echt beliebt, um Modelle verständlich zu machen.
Diese Tools helfen dabei, Modellvorhersagen aufzuschlüsseln, indem sie den Beitrag einzelner Merkmale zeigen. Erklärbarkeit ist bei MLOps echt wichtig, weil sie Vertrauen bei den Beteiligten schafft und sicherstellt, dass die Modelle den Vorschriften entsprechen, vor allem in Branchen wie dem Finanzwesen und dem Gesundheitswesen. Es hilft auch dabei, mögliche Verzerrungen oder datenbezogene Probleme innerhalb des Modells zu erkennen.
Dieser Abschnitt behandelt Interviewfragen, die sich auf Cloud- und Infrastrukturaspekte von MLOps konzentrieren. Diese Fragen checken, wie gut du dich mit dem Einsatz, der Verwaltung und der Skalierung von Machine-Learning-Modellen in Cloud-Umgebungen auskennst.
Beschreibung: Diese Frage checkt, wie gut du dich mit dem Einsatz von Machine-Learning-Modellen in einer Cloud-Umgebung auskennst. Es checkt, wie gut du Cloud-Plattformen, Bereitstellungsprozesse und Tools für die Verwaltung von Modellen in der Cloud verstehst.
Antwort: Um ML-Modelle auf der Cloud einzusetzen, musst du diese Schritte machen:
Beschreibung: Diese Frage geht darum, wie man Serverless Computing versteht und wie man es bei der Bereitstellung von ML-Modellen anwendet, und schaut, ob man die Vorteile gegen die Herausforderungen abwägen kann.
Antwort: Serverlose Architekturen haben ein paar Vorteile, wie zum Beispiel weniger Aufwand beim Betrieb, weil man sich nicht um die Server kümmern muss, und automatische Skalierung je nach Bedarf in Echtzeit, was zu Kostenersparnissen führen kann, weil die Gebühren auf der tatsächlichen Rechenleistung basieren.
Allerdings gibt es auch Probleme mit serverlosen Architekturen. Zum Beispiel gibt's Einschränkungen bei der Ausführungszeit und der Ressourcenzuteilung, die vielleicht nicht für alle Arten von ML-Modellen passen, vor allem nicht für die mit hohem Rechenaufwand.
Auch die Latenz bei Kaltstarts kann ein Problem sein, weil erste Anfragen nach einer längeren Pause zu Verzögerungen führen können. Trotz dieser Herausforderungen können serverlose Architekturen für bestimmte Workloads sehr effektiv sein, wenn diese Faktoren richtig gehandhabt werden.
Eine andere Möglichkeit, das zu zeigen, ist diese Tabelle, die die Vor- und Nachteile von serverlosen Architekturen anhand bestimmter Aspekte zusammenfasst:
|
Aspekt |
Vorteile von Serverless |
Nachteile von Serverless |
|
Betriebskosten |
Keine Serververwaltung nötig; weniger komplizierte Infrastruktur. |
Man braucht Kenntnisse über Cloud-Plattformen, um serverlose Umgebungen zu verwalten. |
|
Skalierung |
Die automatische Skalierung richtet sich nach dem Echtzeitbedarf, was zu Kosteneffizienz führt. |
Kann bei häufigen Skalierungen für die Budgetplanung unvorhersehbar sein. |
|
Kosteneffizienz |
Zahle nur für die Ressourcen, die du wirklich nutzt, und spare so vielleicht Kosten. |
Kann teuer werden, wenn viele Funktionen oft oder für längere Zeit genutzt werden. |
|
Ausführungslimits |
Perfekt für leichte oder kurze Aufgaben. |
Wegen der begrenzten Ausführungszeit und Ressourcenzuteilung kann es sein, dass ressourcenintensive ML-Modelle nicht gut funktionieren. |
|
Kaltstart |
Reduziert die Betriebskosten durch bedarfsgerechte Skalierung. |
Nach einer längeren Pause kann es zu Verzögerungen beim Kaltstart kommen, was sich auf Anwendungen auswirkt, die auf kurze Reaktionszeiten angewiesen sind. |
|
Eignung des ML-Modells |
Funktioniert gut für kleinere ML-Aufgaben, Inferenz oder Stapelverarbeitung. |
ML-Modelle, die viel Rechenleistung brauchen und lange laufen, sind nicht so gut geeignet. |
Beschreibung: Diese Frage checkt deine Strategien zur Optimierung und Verwaltung von Rechenressourcen beim Training von ML-Modellen in der Cloud. Es checkt, wie gut du Cloud-Ressourcen effizient nutzen kannst.
Antwort: Das Verwalten von Rechenressourcen umfasst:
Beschreibung: Diese Frage geht darum, wie man bei der Nutzung von ML-Modellen in Cloud-Umgebungen die Datensicherheit und Compliance sicherstellt, mit Fokus auf bewährte Verfahren und gesetzliche Anforderungen.
Antwort: Datensicherheit und Compliance sicherstellen bedeutet:
Sicherheit und Compliance sind vielleicht das Letzte, worüber ein Ingenieur nachdenken will, aber sie werden immer wichtiger. Der Kurs „Understanding GDPR“ (Die DSGVO verstehen) und die anderen Kurse, die in diesem Artikel vorgeschlagen werden, sollten dir helfen, dich schnell zurechtzufinden.
Beschreibung: Diese Frage geht um Strategien, wie man die Cloud-Kosten für das Training und die Bereitstellung von ML-Modellen verwalten und optimieren kann, und testet, wie gut du dich mit Kostenmanagementtechniken auskennst.
Antwort: Strategien zur Verwaltung von Cloud-Kosten umfassen:
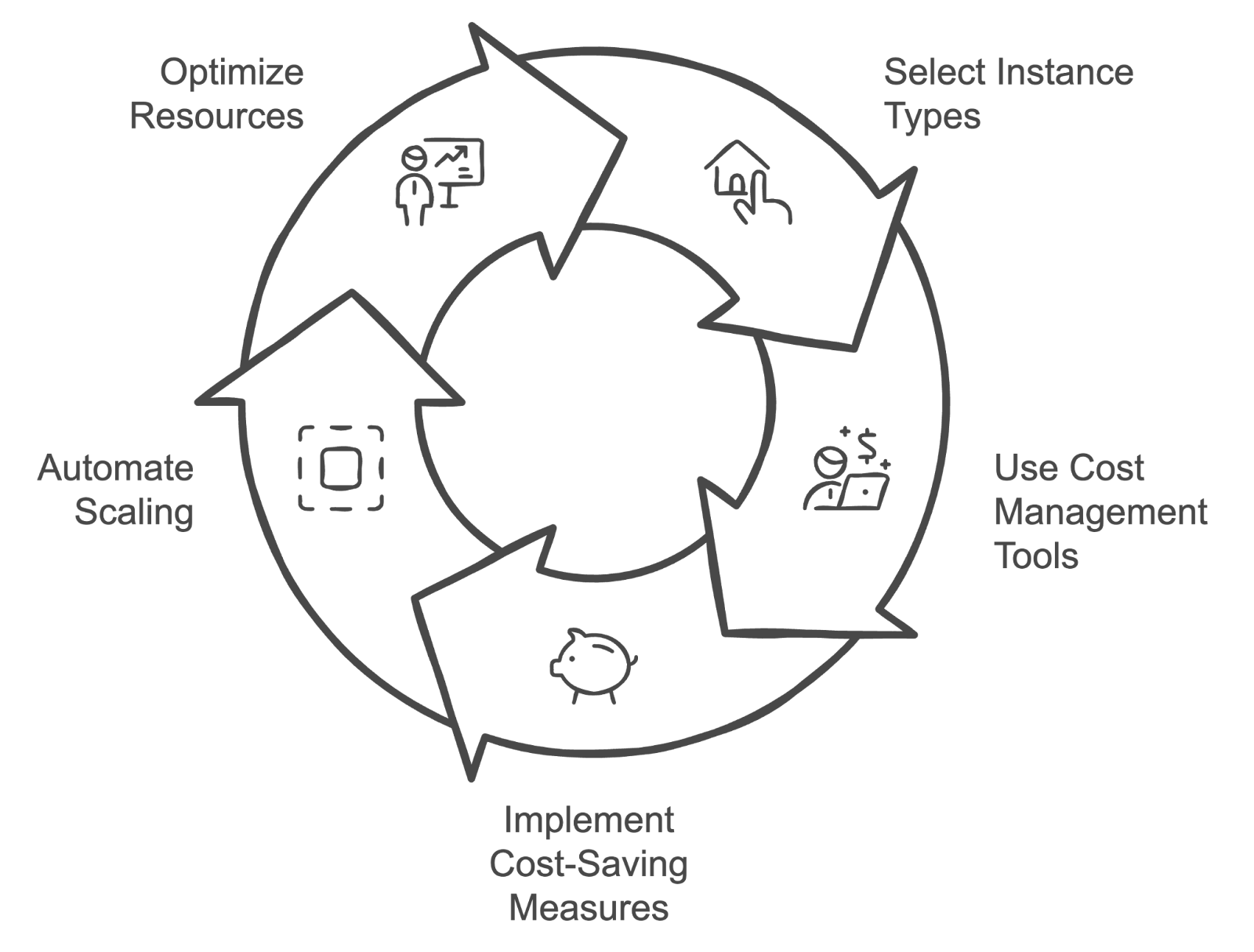
Cloud-Kostenmanagement-Zyklus. Bild vom Autor mit napkin.ai erstellt
Beschreibung: Diese Frage geht darum, wie du die Vor- und Nachteile von Modellen auf Edge-Geräten im Vergleich zur Cloud verstehst.
Antwort: Bei der Cloud-Bereitstellung werden Modelle auf zentralen Servern ausgeführt, was Skalierbarkeit und einfachere Wartung bietet, aber auch potenzielle Latenzprobleme mit sich bringt.
Beim Edge-Deployment werden Modelle direkt auf Geräten wie Smartphones oder IoT-Geräten ausgeführt, was die Latenz reduziert und den Datenschutz verbessert, aber durch die Rechenressourcen eingeschränkt sein kann. Edge-Bereitstellung ist super für Echtzeit-Verarbeitungsanwendungen, während Cloud-Bereitstellung besser für Modelle ist, die viel Rechenleistung und Flexibilität brauchen.
Beschreibung: Diese Frage checkt, wie gut du dich mit dem Aufbau robuster Systeme für den Einsatz von Machine-Learning-Modellen auskennst.
Antwort: Um eine hohe Verfügbarkeit zu haben, muss man Modelle über mehrere Verfügbarkeitszonen oder Regionen verteilen und automatische Failover-Mechanismen einrichten.
Lastenausgleicher können den Datenverkehr verteilen, um Engpässe zu vermeiden. Für die Fehlertoleranz können regelmäßige Backups, Redundanz und Zustandsprüfungen Systemausfälle verhindern. Die Nutzung von Cloud-Diensten wie AWS Elastic Load Balancing und Autoscaling-Funktionen hilft auch dabei, sicherzustellen, dass bei Ausfall einer Instanz andere ohne Ausfallzeiten übernehmen können.
In diesem Abschnitt geht's um Verhaltensweisen und Problemlösungsansätze bei MLOps. Wir schauen uns an, wie die Kandidaten mit echten Herausforderungen umgehen, mit Teams zusammenarbeiten und verschiedene Probleme beim Einsatz und Management von Machine-Learning-Modellen lösen.
Beschreibung: Diese Frage checkt, wie gut du Probleme in echten Situationen lösen kannst.
Beispielantwort: Es gab mal eine Situation, wo ein Modell, das in der Produktion eingesetzt wurde, plötzlich einen deutlichen Leistungsabfall zeigte. Als Erstes haben wir die Protokolle und Metriken des Modells überprüft, um irgendwelche Probleme zu finden. Es wurde klar, dass die Datenpipeline Daten einspeiste, deren Struktur sich durch die letzten Updates in den Quellsystemen geändert hatte.
Als Nächstes haben wir die Daten mit den erwarteten Eingaben des Modells abgeglichen und nach Abweichungen gesucht. Nachdem ich das Datenproblem bestätigt hatte, habe ich mich mit dem Datenentwicklungsteam abgestimmt, um die Datenpipeline zu reparieren. Dann hab ich einen Hotfix rausgebracht, um das Modell mit der korrigierten Eingabeverarbeitung zu aktualisieren.
Schließlich habe ich das Modell nach der Bereitstellung genau beobachtet, um sicherzustellen, dass die Leistung wieder auf das erwartete Niveau zurückkehrte, und habe die Ergebnisse und die Lösung an die Beteiligten weitergegeben.
Beschreibung: Diese Frage checkt, wie du mit verschiedenen Versionen von Machine-Learning-Modellen umgehst, wenn du in einem Team arbeitest.
Beispielantwort: „Ich nutze Versionskontrollsysteme wie MLflow oder DVC, um verschiedene Modellversionen zu verwalten und zu verfolgen. Jede Version kriegt eine eigene Kennung und es gibt eine ausführliche Dokumentation für jedes Update, damit die Teammitglieder die Änderungen verstehen.
Außerdem stelle ich sicher, dass neue Modelle in einer Testumgebung gründlich geprüft werden, bevor sie in der Produktion eingesetzt werden. So kann man Störungen vermeiden und die Modellleistung aufrechterhalten.
Beschreibung: Diese Frage checkt, wie gut du mit verschiedenen Teams wie Datenwissenschaftlern, Ingenieuren und Produktmanagern zusammenarbeiten kannst und wie du Herausforderungen in einem funktionsübergreifenden Umfeld meisterst und löst.
Beispielantwort: Eine schwierige Situation war die Koordination zwischen Datenwissenschaftlern, Ingenieuren und Produktmanagern, um ein neues Modell mit komplizierten Abhängigkeiten einzusetzen. Der Schlüssel für eine gute Zusammenarbeit war, von Anfang an klare Kommunikationswege zu haben.
Es wurden regelmäßige Treffen geplant, um die Ziele abzustimmen, den Fortschritt zu verfolgen und eventuelle Hindernisse anzugehen. Um Wissenslücken zu schließen, habe ich Wissensaustausch-Sitzungen organisiert, in denen die Teammitglieder über ihre jeweiligen Fachgebiete reden konnten.
Außerdem hat die Verwendung von Projektmanagement-Tools zur Verfolgung von Aufgaben und Meilensteinen dazu beigetragen, dass alle über den Projektstatus auf dem Laufenden blieben. Dieser Ansatz hat dafür gesorgt, dass die Ideen von jedem Teammitglied berücksichtigt wurden und wir gemeinsam auf eine erfolgreiche Umsetzung hingearbeitet haben.
Beschreibung: Diese Frage geht um deine Strategien, wie du Machine-Learning-Modelle an wachsende Anforderungen anpasst, und checkt, wie gut du die technischen und operativen Aspekte der Skalierbarkeit verstehst.
Beispielantwort: Um ML-Modelle für mehr Nutzer zu skalieren, musst du ein paar wichtige Schritte machen.
Zuerst würde ich die Leistungskennzahlen des aktuellen Modells anschauen, um mögliche Engpässe zu finden. Um mit der steigenden Nachfrage klarzukommen, würde ich Cloud-basierte Auto-Scaling-Lösungen nutzen, um die Ressourcen je nach Traffic dynamisch anzupassen.
Außerdem kann die Optimierung des Modells selbst durch Techniken wie Quantisierung oder Pruning dazu beitragen, den Ressourcenverbrauch zu senken, ohne die Leistung zu beeinträchtigen.
Ich würde auch Lasttests machen, um mehr Traffic zu simulieren und sicherzustellen, dass das System robust ist.
Und zu guter Letzt würde ich eine ständige Überwachung einrichten, um immer auf dem Laufenden zu bleiben, wie die Modelle laufen, damit ich die Ressourcenzuteilung nach Bedarf anpassen und die Leistung bei unterschiedlichen Auslastungen aufrechterhalten kann.
Beschreibung: Diese Frage checkt, wie du mit Kommunikation und Erwartungen umgehst, wenn ein Modell nicht die erwarteten Ergebnisse liefert.
Beispielantwort: Wenn die Leistung des Modells nicht so läuft, wie man es sich vorstellt, setze ich voll auf offene Kommunikation mit allen Beteiligten. Ich erkläre die Einschränkungen des Modells und warum es so funktioniert, egal ob es an der Datenqualität, Überanpassung oder unrealistischen Erwartungen liegt.
Dann arbeite ich mit ihnen zusammen, um realistischere Ziele zu setzen, datengestützte Erkenntnisse zu liefern und Verbesserungen vorzuschlagen, wie zum Beispiel mehr Trainingsdaten zu sammeln oder die Modellarchitektur anzupassen.
Beschreibung: Diese Frage checkt, wie gut du Prioritäten setzen kannst, um die langfristige Codequalität zu sichern und kurzfristige Projekttermine einzuhalten.
Beispielantwort: Es gab mal eine Zeit, in der wir unter großem Zeitdruck standen, um ein Modell für eine neue Produktfunktion einzusetzen. Wir haben uns auf eine schnelle Lieferung konzentriert, indem wir ein paar nicht so wichtige Teile des Codes, wie zum Beispiel eine ausführliche Dokumentation und nicht unbedingt notwendige Tests, weggelassen haben.
Nach der Veröffentlichung haben wir uns Zeit genommen, um den Code nochmal zu checken und diese Probleme zu beheben, damit die technischen Schulden nach dem Start so gering wie möglich bleiben. So konnten wir den Termin einhalten und gleichzeitig die langfristige Stabilität des Projekts sichern.
Die Vorbereitung auf ein MLOps-Vorstellungsgespräch braucht eine Mischung aus technischem Wissen, Verständnis für die Unternehmensumgebung und einer klaren Darstellung deiner bisherigen Erfahrungen. Hier sind ein paar wichtige Tipps, die dir bei der Vorbereitung helfen:
Stell sicher, dass du die wichtigsten MLOps-Konzepte gut verstehst. Mach dich mit den gängigen Tools und Plattformen für MLOps vertraut, wie MLflow, Kubernetes und Cloud-basierten Diensten wie AWS SageMaker oder Google AI Platform.
Der MLOps-Lernpfad ist echt super, weil er vier coole Kurse hat, die dich über die neuesten MLOps-Konzepte und -Praktiken auf dem Laufenden halten.
Schau dir die spezifischen Technologien und Tools an, die das Unternehmen, bei dem du dich vorstellst, nutzt. Wenn du ihre Tech-Stack verstehst, kannst du deine Antworten besser auf ihre Umgebung abstimmen und zeigen, dass du gut zu ihnen passt. Schau dir ihre bevorzugten Cloud-Dienste, Versionskontrollsysteme und Modellmanagementpraktiken an, um zu zeigen, dass du bereit bist, dich nahtlos in ihren Arbeitsablauf zu integrieren.
Sei bereit, über konkrete Projekte oder Erfahrungen zu reden, bei denen du MLOps-Praktiken angewendet hast. Bereite Beispiele vor, die deine Fähigkeiten zur Problemlösung, deine Fähigkeit zur Zusammenarbeit mit funktionsübergreifenden Teams und deine Erfahrung mit der Bereitstellung und Skalierung von Modellen (wenn möglich) hervorheben. Nutze diese Beispiele, um dein praktisches Wissen zu zeigen und wie du in früheren Jobs Herausforderungen erfolgreich gemeistert hast.
Mach regelmäßig Programmierübungen zu MLOps, wie zum Beispiel Skripte für die Modellbereitstellung schreiben, Workflows automatisieren oder Datenpipelines entwickeln.
Der Bereich MLOps entwickelt sich schnell weiter, deshalb ist es wichtig, immer über die neuesten Trends, Tools und Best Practices auf dem Laufenden zu bleiben. Folge Branchenblogs, mach bei relevanten Foren oder Webinaren mit und tausche dich mit der MLOps-Community aus, um dein Wissen aktuell und relevant zu halten.
MLOps ist ein Bereich, der die Lücke zwischen Datenwissenschaft und Betrieb schließt und dafür sorgt, dass Machine-Learning-Modelle effektiv eingesetzt, gewartet und skaliert werden.
In diesem Beitrag haben wir eine Reihe von Interviewfragen behandelt, die allgemeine MLOps-Konzepte, technische Aspekte, Überlegungen zu Cloud und Infrastruktur sowie Verhaltenskompetenzen zur Problemlösung abdecken. Wenn du diese Fragen übst, steigert das deine Chancen auf Erfolg bei deinen Vorstellungsgesprächen erheblich und erhöht deine Chancen, den Job zu bekommen!
Schau dir die folgenden Ressourcen an, um weiterzulernen:
Lerne mit diesen Kursen mehr über MLOps!
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog