
Track
AI Fundamentals
10 hr
Qwen3 is one of the most complete open-weight model suites released so far.
It comes from Alibaba’s Qwen team and includes models that scale up to research-grade performance as well as smaller versions that can be run locally on more modest hardware.
In this blog, I’ll give you a quick overview of the full Qwen3 suite, explain how the models were developed, walk through benchmark results, and show you how you can access and start using them.
We’ve also published tutorials on running Qwen3 locally with Ollama and on fine-tuning Qwen3.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
Qwen3 is the latest family of large language models from Alibaba’s Qwen team. All models in the lineup are open-weighted under the Apache 2.0 license.
What caught my eye immediately was the introduction of a thinking budget that users can control directly inside the Qwen app. This gives regular users granular control over the reasoning process, something that previously could only be done programmatically.
As we can see in the graphs below, increasing the thinking budgets significantly improves performance, especially for math, coding, and science.
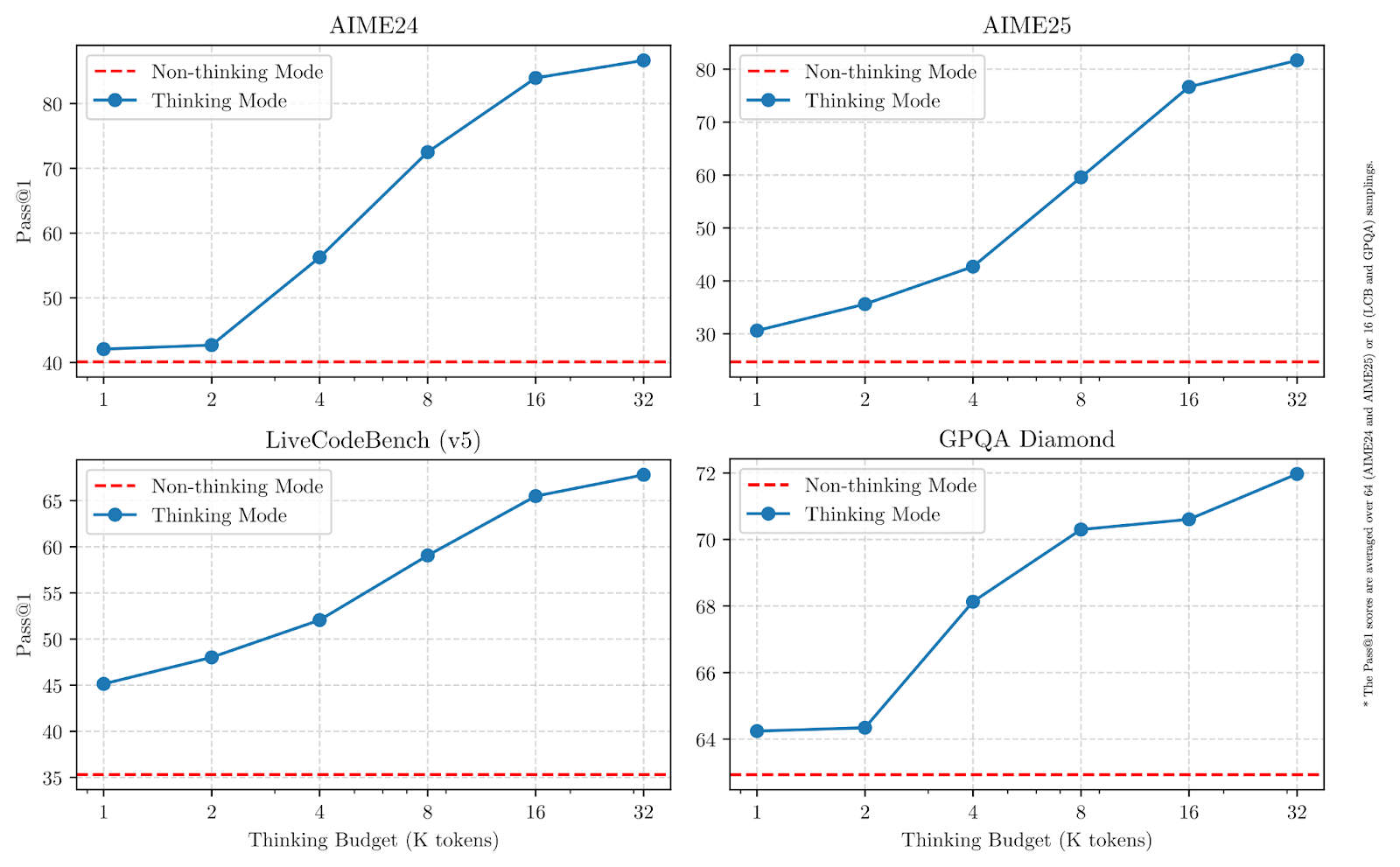
Source: Qwen
In benchmark tests, the flagship Qwen3-235B-A22B performs competitively against other top-tier models and shows stronger results than DeepSeek-R1 across coding, math, and general reasoning. Let’s quickly explore each model and understand what it’s designed for.
This is the largest model in the Qwen3 lineup. It uses a mixture-of-experts (MoE) architecture with 235 billion total parameters and 22 billion active per generation step.
In a MoE model, only a small subset of parameters is activated at each step, which makes it faster and cheaper to run compared to dense models (like GPT-4o), where all parameters are always used.
The model performs well across math, reasoning, and coding tasks, and in benchmark comparisons it outpaces models like DeepSeek-R1.
Qwen3-30B-A3B is a smaller MoE model with 30 billion total parameters and just 3 billion active at each step. Despite the low active count, it performs comparably to much larger dense models like QwQ-32B. It’s a practical choice for users who want a mix of reasoning capability and lower inference costs. Like the 235B model, it supports a 128K context window and is available under Apache 2.0.
The six dense models in the Qwen3 release follow a more traditional architecture where all parameters are active at every step. They cover a wide range of use cases:
Qwen3-32B, 14B, 8B support 128K context windows, while Qwen3-4B, 1.7B, 0.6B support 32K. All are open-weighted and licensed under Apache 2.0. Smaller models in this group are well-suited for lightweight deployments, while the larger ones are closer to general-purpose LLMs.
Qwen3 offers different models depending on how much reasoning depth, speed, and computational cost you need. Here’s a quick overview:
|
Model |
Type |
Context Length |
Best For |
|
Qwen3-235B-A22B |
MoE |
128K |
Research tasks, agent workflows, long reasoning chains |
|
Qwen3-30B-A3B |
MoE |
128K |
Balanced reasoning at lower inference cost |
|
Qwen3-32B |
Dense |
128K |
High-end general-purpose deployments |
|
Qwen3-14B |
Dense |
128K |
Mid-range apps needing strong reasoning |
|
Qwen3-8B |
Dense |
128K |
Lightweight reasoning tasks |
|
Qwen3-4B |
Dense |
32K |
Smaller applications, faster inference |
|
Qwen3-1.7B |
Dense |
32K |
Mobile and embedded use cases |
|
Qwen3-0.6B |
Dense |
32K |
Very lightweight or constrained settings |
If you’re working on tasks that need deeper reasoning, agent tool use, or long context handling, Qwen3-235B-A22B will give you the most flexibility.
For cases where you want to keep inference faster and cheaper while still handling moderately complex tasks, Qwen3-30B-A3B is a strong option.
The dense models offer simpler deployments and predictable latency, making them a better fit for smaller-scale applications.
Qwen3 models were built through a three-stage pretraining phase followed by a four-stage post-training pipeline.
Pretraining is where the model learns general patterns from massive amounts of data (language, logic, math, code) without being told exactly what to do. Post-training is where the model is fine-tuned to behave in specific ways, like reasoning carefully or following instructions.
I’ll walk through both parts in simple terms, without getting too deep into technical details.
Compared to Qwen2.5, the pretraining dataset for Qwen3 was significantly expanded. Around 36 trillion tokens were used, doubling the amount in the previous generation. The data included web content, extracted text from documents, and synthetic math and code examples generated by Qwen2.5 models .
The pretraining process followed three stages:
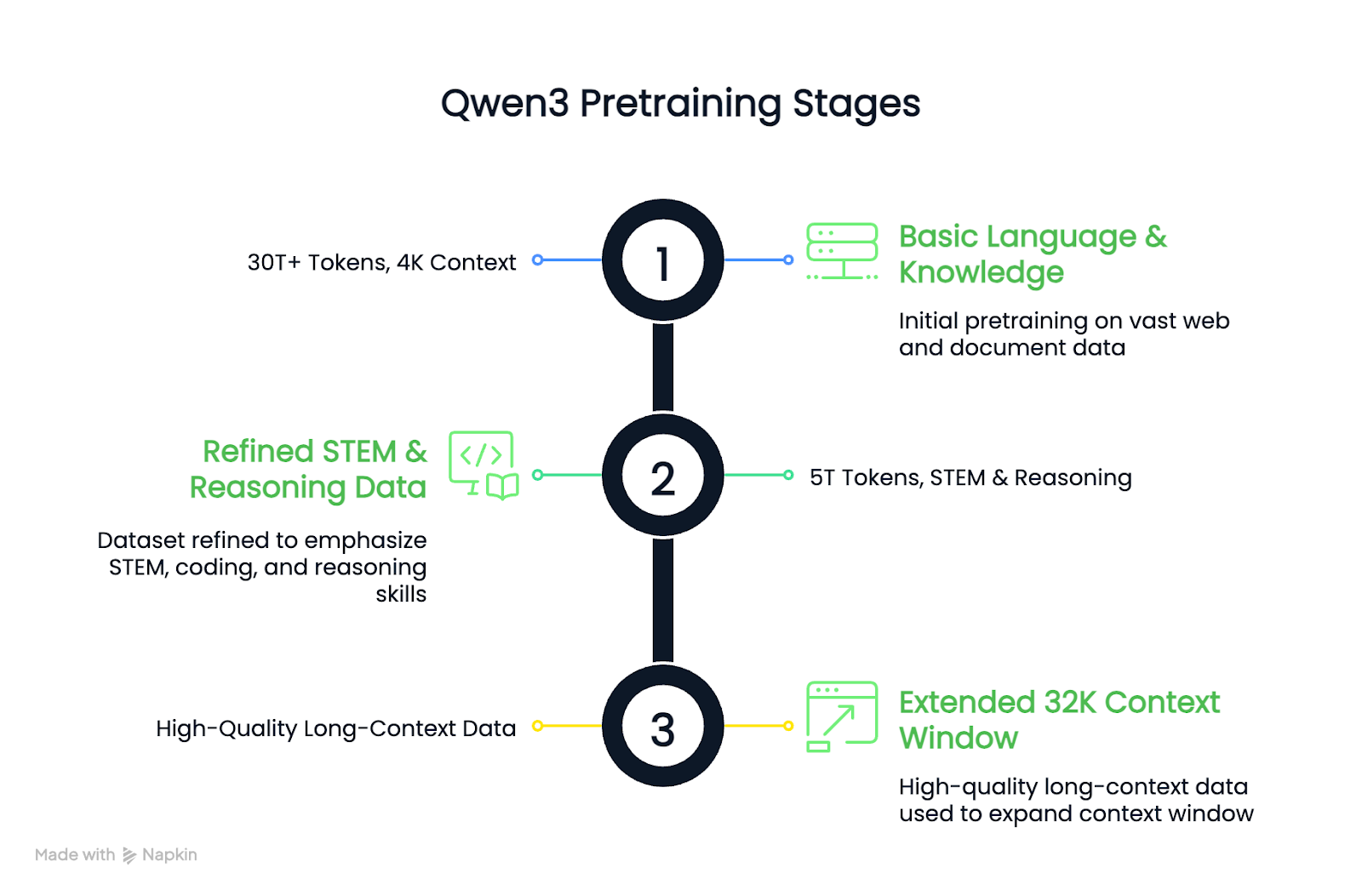
The result is that dense Qwen3 base models match or outperform larger Qwen2.5 base models while using fewer parameters, especially in STEM and reasoning tasks.
Qwen3’s post-training pipeline focused on integrating deep reasoning and quick-response capabilities into a single model. Let’s first take a look at the diagram below, and then I’ll explain it step-by-step:
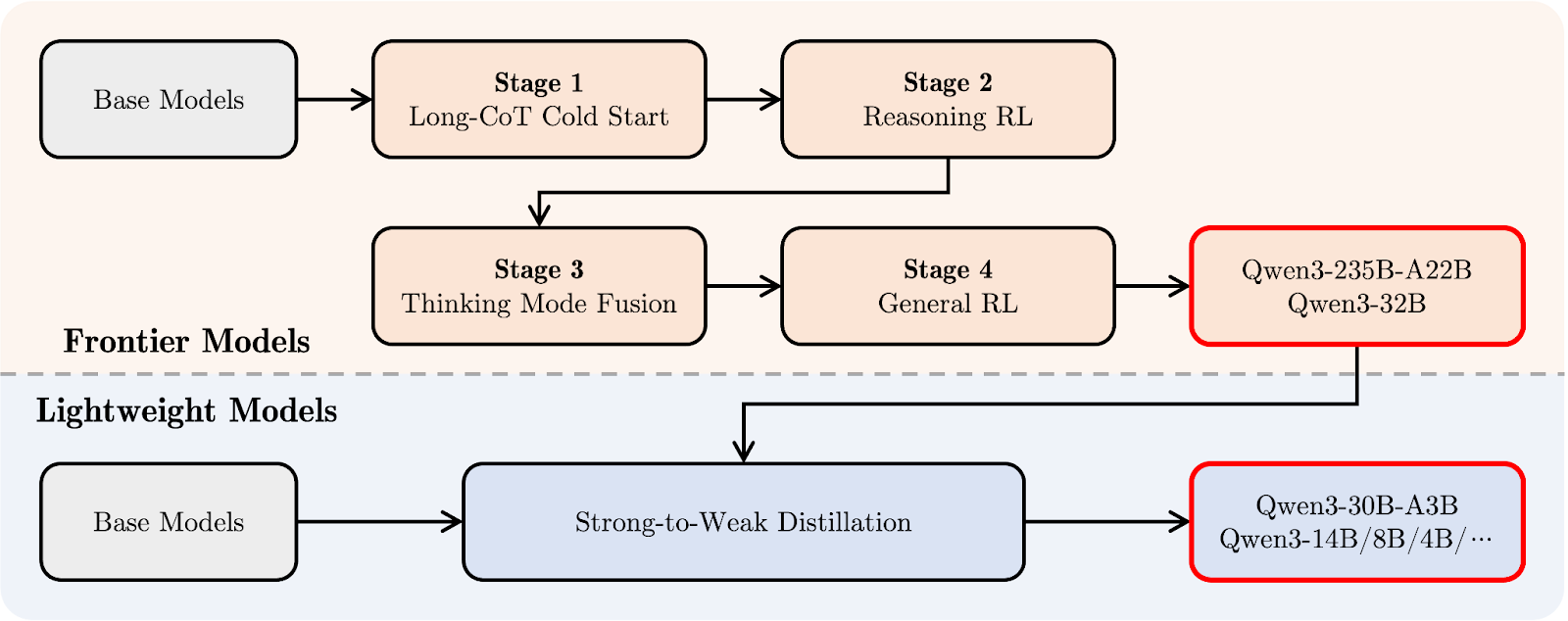
Qwen 3 post-training pipeline. Source: Qwen
At the top (in orange), you can see the development path for the larger “Frontier Models,” like Qwen3-235B-A22B and Qwen3-32B. It starts with a Long Chain-of-Thought Cold Start (stage 1), where the model learns to reason step-by-step on harder tasks.
That’s followed by Reasoning Reinforcement Learning (RL) (stage 2) to encourage better problem-solving strategies. In stage 3, called Thinking Mode Fusion, Qwen3 learns to balance slow, careful reasoning with faster responses. Finally, a General RL stage improves its behavior across a wide range of tasks, like instruction following and agentic use cases.
Below that (in light blue), you’ll see the path for the “Lightweight Models,” like Qwen3-30B-A3B and the smaller dense models. These models are trained using strong-to-weak distillation, a process where knowledge from the larger models is compressed into smaller, faster models without losing too much reasoning ability.
In simple terms: the big models were trained first, and then the lightweight ones were distilled from them. This way, the full Qwen3 family shares a similar style of thinking, even across very different model sizes.
Qwen3 models were evaluated across a range of reasoning, coding, and general knowledge benchmarks. The results show that Qwen3-235B-A22B leads the lineup on most tasks, but the smaller Qwen3-30B-A3B and Qwen3-4B models also deliver good performance.
On most benchmarks, Qwen3-235B-A22B is among the top-performing models, though not always the leader.
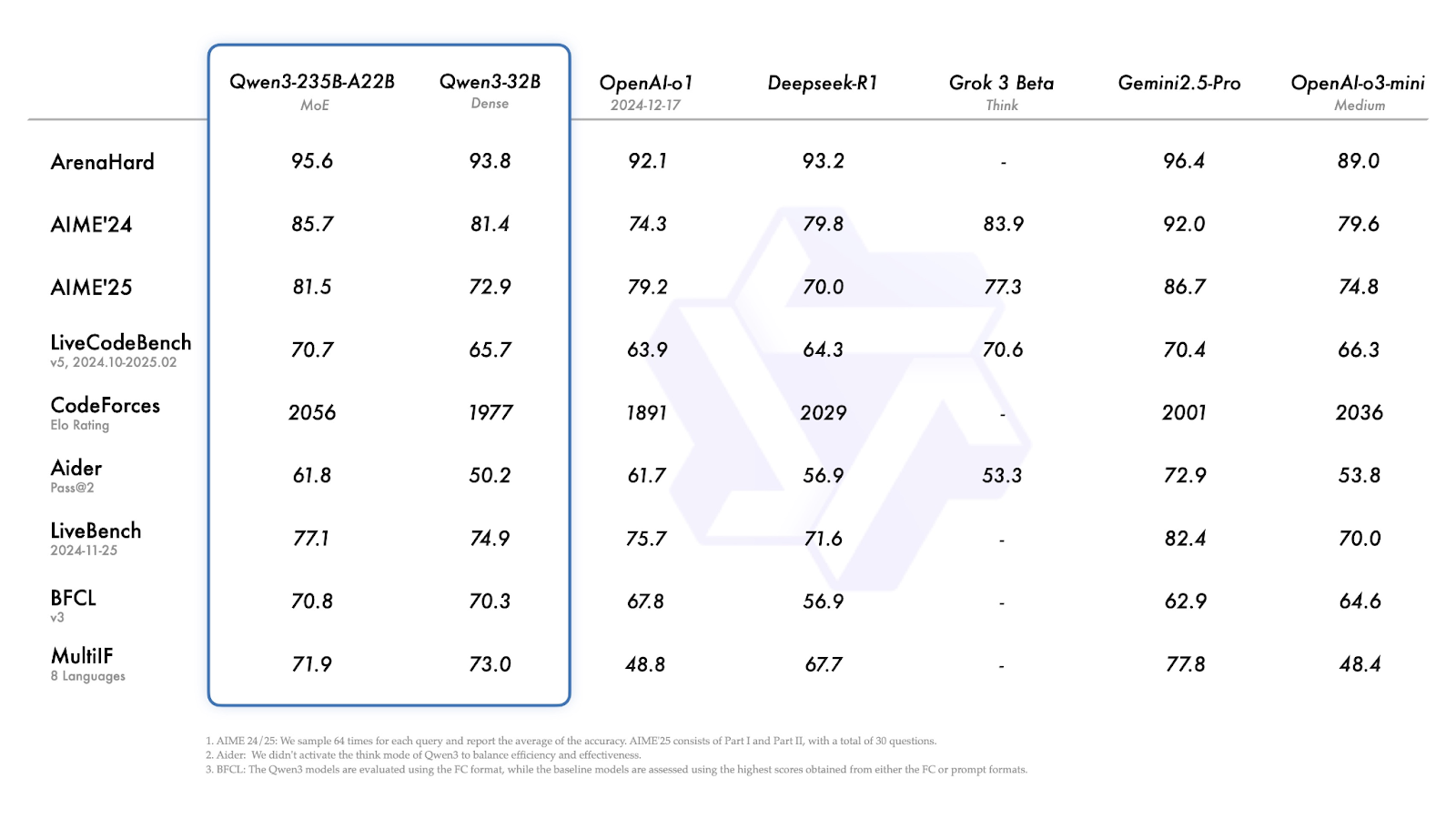
Source: Qwen
Let’s quickly explore the results above:
Qwen3-30B-A3B (the smaller MoE model) performs well across nearly all benchmarks, consistently matching or beating similar-sized dense models.
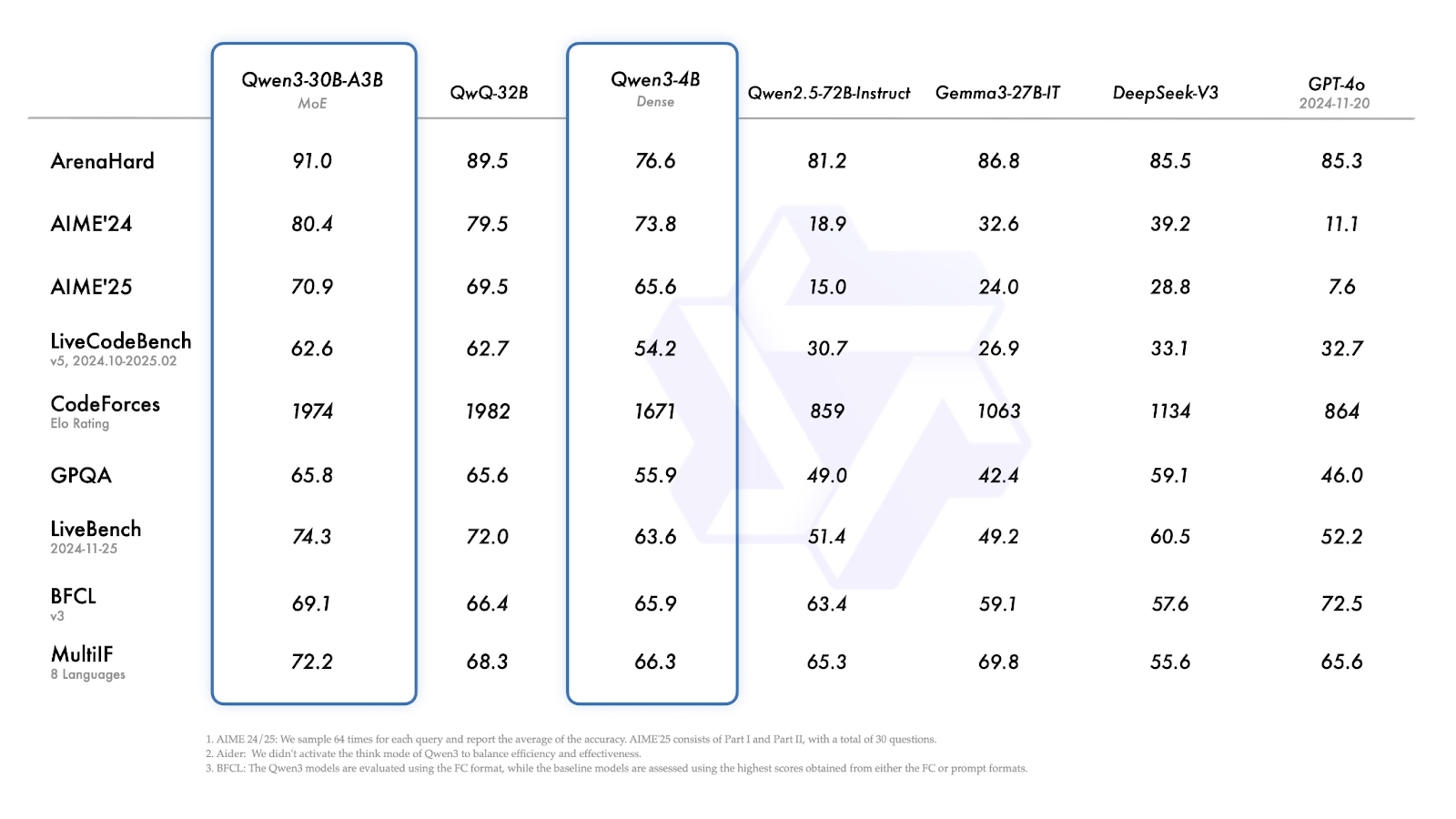
Source: Qwen
Qwen3-4B shows solid performance for its size:
Qwen3 models are publicly available and can be used on the chat app, via API, downloaded for local deployment, or integrated into custom setups.
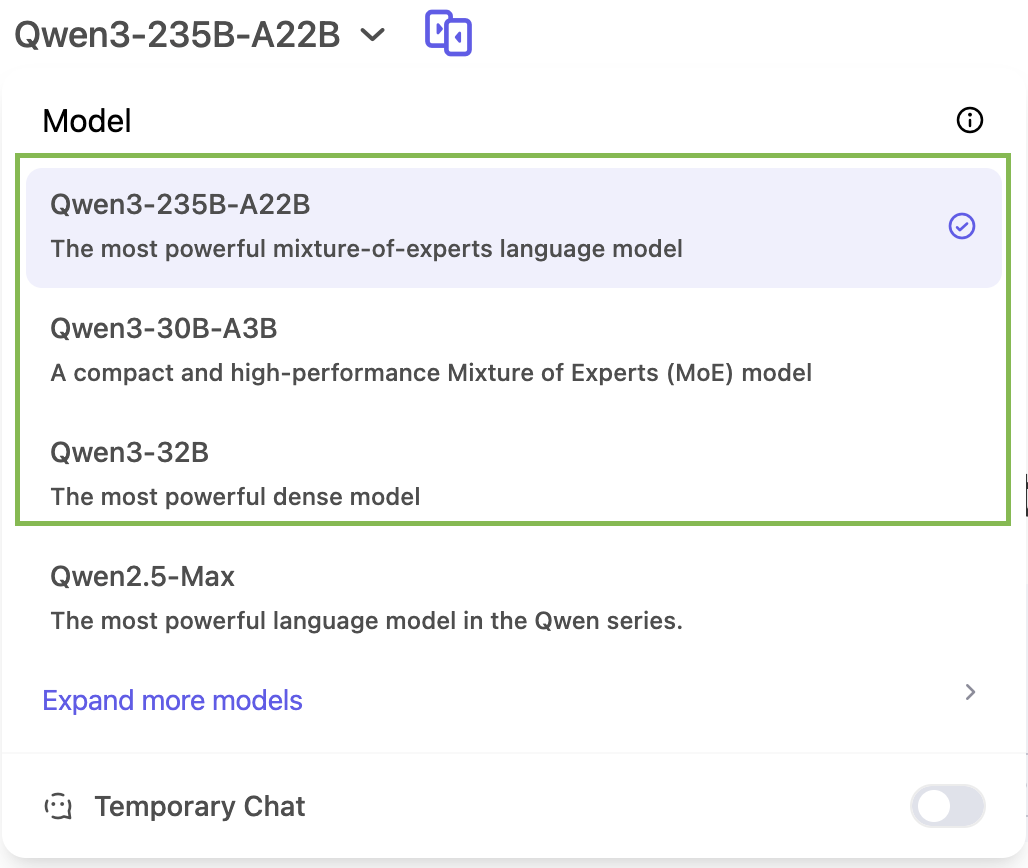
You can try Qwen3 directly at chat.qwen.ai.
You’ll only be able to access three models from the Qwen 3 family in the chat app: Qwen3-235B, Qwen3-30B, and Qwen3-32B:
Qwen3 works with OpenAI-compatible API formats through providers like ModelScope or DashScope. Tools like vLLM and SGLang offer efficient serving for local or self-hosted deployment. The official Qwen 3 blog has more details about this.
All Qwen3 models—both MoE and dense—are released under the Apache 2.0 license. They’re available on:
You can also run Qwen3 locally using:
Qwen3 is one of the most complete open-weight model suites released so far.
The flagship 235B MoE model performs well across reasoning, math, and coding tasks, while the 30B and 4B versions offer practical alternatives for smaller-scale or budget-conscious deployments. The ability to adjust the model’s thinking budget adds an extra layer of flexibility for regular users.
As it stands, Qwen3 is a well-rounded release that covers a wide range of use cases and is ready to use in both research and production settings.
Learn AI with these courses!
Track
Track
Track
blog
Alex Olteanu
6 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
François Aubry
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min



